Udalosti
31. 3., 23 - 2. 4., 23
Najväčšia vzdelávacia udalosť fabric, Power BI a SQL. 31. marec – 2. apríl. Pomocou kódu FABINSIDER ušetríte 400 USD.
Zaregistrujte saTento prehliadač už nie je podporovaný.
Inovujte na Microsoft Edge a využívajte najnovšie funkcie, aktualizácie zabezpečenia a technickú podporu.
Vzťahuje sa na:✅ koncový bod analýzy SQL a sklad v službe Microsoft Fabric
Načítanie údajov z dátového jazera je kľúčovou operáciou vstupu/výstupu (IO) s podstatným vplyvom na výkon dotazov. Sklad údajov služby Fabric využíva spresnené vzory prístupu na vylepšenie čítaných údajov z úložiska a zvýšenie rýchlosti spúšťania dotazov. Okrem toho inteligentne minimalizuje potrebu čítať zo vzdialeného ukladacieho priestoru využitím lokálnych vyrovnávacích pamätí.
Ukladanie do vyrovnávacej pamäte je technika, ktorá zlepšuje výkon aplikácií na spracovanie údajov znížením operácií IO. Ukladanie často prístupných údajov a metaúdajov do vyrovnávacej pamäte sa ukladá do rýchlejšieho ukladacieho priestoru, ako je napríklad lokálna pamäť alebo lokálny disk SSD, aby bolo možné nasledujúce požiadavky odosielať rýchlejšie priamo z vyrovnávacej pamäte. Ak dotaz predtým získal prístup k určitej množine údajov, všetky nasledujúce dotazy načítajú tieto údaje priamo z vyrovnávacej pamäte v pamäti. Tento prístup výrazne znižuje latenciu IO, pretože operácie lokálnej pamäte sú obzvlášť rýchlejšie v porovnaní s načítaním údajov zo vzdialeného úložiska.
Ukladanie do vyrovnávacej pamäte je pre používateľa plne priehľadné. Bez ohľadu na pôvod – či už ide o skladovú tabuľku, odkaz OneLake alebo dokonca odkaz oneLake, ktorý odkazuje na služby mimo služby Azure – dotaz ukladá všetky údaje, ku ktorým pristupuje.
Existujú dva typy vyrovnávacej pamäte, ktoré sú popísané ďalej v tomto článku:
Keď dotaz pristupuje k údajom a načíta údaje z úložiska, vykoná proces transformácie, ktorý prekóduje údaje z pôvodného formátu založeného na súbore do vysoko optimalizovaných štruktúr vo vyrovnávacej pamäti pamäte.

Údaje vo vyrovnávacej pamäti sú usporiadané v komprimovanom stĺpcovom formáte optimalizovanom pre analytické dotazy. Každý stĺpec údajov je uložený dohromady, oddelene od ostatných, čo umožňuje lepšiu kompresiu, pretože podobné hodnoty údajov sú uložené spolu, čo vedie k zníženiu nárokov na pamäť. Keď dotazy musia vykonávať operácie v konkrétnom stĺpci, ako sú agregáty alebo filtrovanie, nástroj môže pracovať efektívnejšie, pretože nemusí spracovávať nepotrebné údaje z iných stĺpcov.
Okrem toho je toto stĺpcové úložisko priaznivé aj pre paralelné spracovanie, čo môže vo veľkých množinách údajov výrazne urýchliť vykonávanie dotazov. Nástroj môže vykonávať operácie so viacerými stĺpcami súčasne, pričom využíva moderné viacjadrové procesory.
Tento prístup je užitočný najmä pri analytických vyťaženiach, pri ktorých dotazy zahŕňajú skenovanie veľkého množstva údajov na vykonanie agregácií, filtrovanie a ďalšiu manipuláciu s údajmi.
Niektoré množiny údajov sú príliš veľké na to, aby sa mohli ubytovať vo vyrovnávacej pamäti v pamäti. S cieľom udržať rýchly výkon dotazov v týchto množinách údajov využíva warehouse miesto na disku ako doplnkové rozšírenie vyrovnávacej pamäte v pamäti. Všetky informácie, ktoré sa načítajú do vyrovnávacej pamäte v pamäti, sa tiež serializujú do vyrovnávacej pamäte SSD.
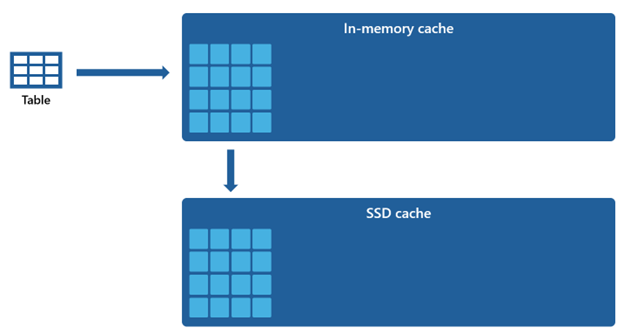
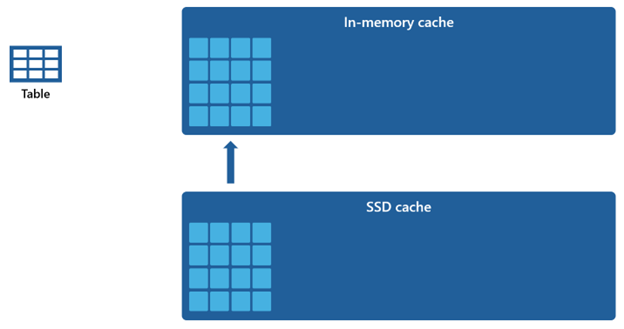
Vzhľadom na to, že vyrovnávacia pamäť v pamäti má v porovnaní s vyrovnávacou pamäťou SSD menšiu kapacitu, údaje, ktoré sa odstránia z príslušnej vyrovnávacej pamäte, zostanú na dlhší čas v vyrovnávacej pamäti SSD. Keď nasledujúci dotaz požaduje tieto údaje, načíta sa z vyrovnávacej pamäte SSD do vyrovnávacej pamäte v pamäti výrazne rýchlejšie než pri načítavaní zo vzdialeného úložiska, čo nakoniec poskytuje konzistentnejší výkon dotazu.
Ukladanie do vyrovnávacej pamäte zostáva konzistentne aktívne a bezproblémovo funguje v pozadí, čo si nevyžaduje žiadny zásah z vašej strany. Zakázanie ukladania do vyrovnávacej pamäte nie je potrebné, pretože by to nevyhnutne viedlo k výraznému zhoršeniu výkonu dotazov.
Mechanizmus ukladania do vyrovnávacej pamäte je koordinovaný a podporovaný samotnou službou Microsoft Fabric a neponúka používateľom možnosť manuálne vymazať vyrovnávaciu pamäť.
Úplná konzistencia transakcií vyrovnávacej pamäte zaisťuje, že akékoľvek úpravy údajov v úložisku, ako napríklad prostredníctvom operácií jazyka DML (Data Manipulation Language), po prvom načítaní do vyrovnávacej pamäte v pamäti, budú mať za následok konzistentné údaje.
Keď vyrovnávacia pamäť dosiahne prahovú hodnotu kapacity a nové údaje sa čítajú prvýkrát, objekty, ktoré zostali nepoužívané počas najdlhšieho trvania, sa z vyrovnávacej pamäte odstránia. Tento proces je prijatý na vytvorenie priestoru pre prílev nových údajov a udržanie optimálnej stratégie využitia vyrovnávacej pamäte.
Udalosti
31. 3., 23 - 2. 4., 23
Najväčšia vzdelávacia udalosť fabric, Power BI a SQL. 31. marec – 2. apríl. Pomocou kódu FABINSIDER ušetríte 400 USD.
Zaregistrujte saŠkolenie
Modul
Caching and performance in Azure storage disks - Training
Learn about Azure VM disk performance and how to enable caching to help optimize read and write access to storage.
Certifikácia
Microsoft Certified: Fabric Data Engineer Associate - Certifications
As a Fabric Data Engineer, you should have subject matter expertise with data loading patterns, data architectures, and orchestration processes.
Dokumentácia
Pokyny na výkon skladu - Microsoft Fabric
Tento článok obsahuje zoznam pokynov na výkon pre sklad.
Naučte sa používať štatistické funkcie.
Inteligentná vyrovnávacia pamäť v službe Microsoft Fabric - Microsoft Fabric
Získajte informácie o inteligentnej funkcii vyrovnávacej pamäte v službe Fabric vrátane toho, kedy ju používať a ako ju povoliť a zakázať v relácii.