Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Tento dokument popisuje prístup tímu služby Fabric k udržiavania spoľahlivej, výkonnej a škálovateľnej služby pre zákazníkov. Popisuje stav služby, zmierňovanie incidentov a opatrenia na základe nevyhnutných vylepšení. Ďalšie dôležité prevádzkové aspekty, ako je správa zabezpečenia a vydania, sú mimo rozsahu tohto dokumentu. Tento dokument bol vytvorený na zdieľanie vedomostí s našimi zákazníkmi, ktorí často vyvolávajú otázky týkajúce sa inžinierskych postupov na spoľahlivosť lokality. Zámerom je ponúknuť transparentnosť v tom, ako spoločnosť Fabric minimalizuje narušenie služieb prostredníctvom bezpečného nasadenia, nepretržitého monitorovania a rýchlej reakcie na incidenty. Techniky popísané tu tiež poskytujú plán pre tímy, ktoré sú hostiteľmi riešení založených na službe na budovanie základných dynamických procesov lokality, ktoré sú efektívne a účinné vo väčšom meradle.
Prečo sa incidenty vyskytujú a ako s nimi žiť
Tím služby Fabric sa každý týždeň vydáva s aktualizáciami funkcií služby a cielenými opravami na požiadanie na riešenie problémov s kvalitou služieb. Proces vydania zahŕňa komplexnú sadu brán kvality vrátane komplexných revízií kódov, testovania ad hoc, automatizovaných testov založených na súčastiach a scenárových testov, letových funkcií a bezpečného nasadenia na regionálnej úrovni. Aj pri týchto bezpečnostných opatreniach však incidenty na živých lokalitách môžu a môžu sa stať.
Incidenty na dynamických lokalitách možno rozdeliť do niekoľkých kategórií:
Problémy závislé od služby, ako sú Azure AD, Azure SQL, Storage, množina mierky virtuálneho počítača, služba Service Fabric.
Výpadok infraštruktúry, ako napríklad zlyhanie hardvéru, zlyhanie údajového centra.
Problémy s konfiguráciou prostredia tkaniny, ako napríklad nedostatočná kapacita.
Regresie kódu služby tkaniny
Nesprávna konfigurácia zákazníka, ako sú napríklad nedostatočné zdroje a zlé dotazy alebo zostavy.
Zníženie objemu incidentov je jedným zo spôsobov, ako znížiť záťaž na živom mieste a zlepšiť spokojnosť zákazníkov. Nie je to však vždy možné vzhľadom na to, že niektoré kategórie incidentov sú mimo priamej kontroly tímu. Navyše, keďže nároky služby sa rozširujú tak, aby podporovali rast v používaní, pravdepodobnosť incidentu, ku ktorému dôjde v dôsledku externých faktorov, sa zvyšuje. Vysoký počet incidentov môže nastať aj v prípadoch, keď služba Fabric má minimálnu regresiu kódu služby a splnila alebo prekročila svoj cieľ úrovne služieb (SLO) pre celkovú spoľahlivosť 99,95%, čo viedlo tím služby Fabric k tomu, aby venoval značné zdroje na zníženie vplyvu incidentov.
Proces incidentu na dynamickej lokalite
Pri skúmaní incidentov na živej lokalite sleduje tím služby Fabric štandardný operačný proces, ktorý je bežný v spoločnosti Microsoft a odvetví. Nasledujúci obrázok obsahuje súhrn štandardného životného cyklu incidentu na dynamickej lokalite.
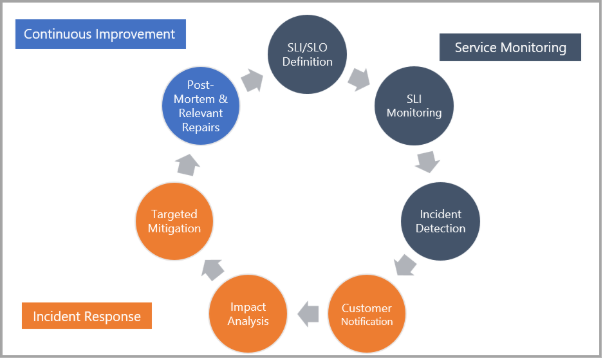
fázy 1: Monitorovanie služieb tím SRE spolupracuje s inžiniermi, správcami programov a tímom hlavného vedenia pri definovaní ukazovateľov úrovne služieb (SLA) a cieľov na úrovni služieb (SLA) pre hlavné aj menšie scenáre. Tieto ciele sa vzťahujú na rôzne metriky služby vrátane scenárov spoľahlivosti a súčastí, scenárov a súčastí výkonu (latencie) a spotreby zdrojov. Tím živej lokality a produktový tím potom vytvorte upozornenia, ktoré monitorujú indikátory úrovne služieb (SLI) v súvislosti s dohodnutými cieľmi. Keď sa zistia porušenia, aktivuje sa upozornenie na preskúmanie.
fázy 2: Odpoveď na incident – procesy sú štruktúrované, čím sa uľahčujú nasledujúce výsledky:
Rýchle a cieľové oznámenia o každom relevantnom vplyve pre zákazníkov
Analýza ovplyvnených súčastí služby a pracovných postupov
Cielené zmiernenie vplyvu incidentov
fázy 3: Priebežné zlepšovanie – Dokončenie príslušnej analýzy post-mortem a rozlíšenie všetkých identifikovaných procesov, monitorovania alebo konfigurácie alebo opráv kódu. Opravy sa potom uprednostnia pred všeobecnými technickými nevybavenými tímami na základe celkovej závažnosti a rizika opakovania.
Naše postupy pre monitorovanie služieb
Tím služby Fabric zdôrazňuje konzistentný prístup k operáciám na živých lokalitách, ktorý je riadený údajmi a orientovaný na zákazníkov. Definovanie indikátorov úrovne služby (SLI) a implementácia zodpovedajúcich upozornení na monitorovanie dynamickej lokality je súčasťou kritérií schválenia na povolenie akejkoľvek novej funkcie služby Fabric v produkcii. Inžinieri skupiny produktov zahŕňajú aj kroky na skúmanie a zmiernenie upozornení pri použití príručky na riešenie problémov so šablónami (TSG). Tieto doručenia sa potom predstavia tímu spoločnosti Site Reliability Engineering (SRE).
Jedným zo spôsobov, ako tím služby Fabric umožňuje exponenciálny rast služieb, je použitie tímu SRE. Títo jednotlivci majú kvalifikáciu so architektúrou služby, automatizáciou a postupmi spravovania incidentov a sú vložení do incidentov, aby mohli viesť k komplexnému riešeniu. Tento prístup je v kontraste s rotačným modelom, v ktorom vedúci pracovníci z produktovej skupiny preberajú rolu manažéra incidentov len niekoľko týždňov do roka. Tím SRE zabezpečuje, aby konzistentná skupina jednotlivcov bola zodpovedná za riadenie vylepšení dynamických lokalít a zabezpečenie toho, aby boli poznatky z predchádzajúcich incidentov začlenené do budúcich eskalácií. Tím SRE tiež pomáha s rozsiahlymi cvičeniami, ktoré testujú funkciu kontinuity obchodných činností a zotavenie po havárii (BCDR).
Členovia tímu SRE používajú svoju jedinečnú množinu zručností a značné množstvo živých skúseností na lokalite a tiež môžu spolupracovať s tímami zaoberania sa funkciami na vylepšenie rozhraní API a upozornení poskytovaných produktovým tímom mnohými spôsobmi. Medzi spôsoby, akými zlepšujú SLI, patria tieto:
upozornení na anomálie – V prípade výrazných odchýlok vyvíjajú monitory, ktoré považujú za typické vzory používania a prevádzky v rámci daného produkčného prostredia a upozorňujú. Príklad: Latencia obnovenia množín údajov sa zvyšuje o 50% v porovnaní s podobnými obdobiami používania.
Upozornenia zákazníka/Environment-Specific – msp rozvíjajú monitory, ktoré zisťujú, kedy sa konkrétni zákazníci, zriadené kapacity alebo nasadené klastre odchyľujú od očakávaného správania. príklad: Jedna kapacita vo vlastníctve zákazníka nenačítava množiny údajov pre dotazovanie.
Fine-Grained upozornenia – podniky sa domnievajú, že podmnožiny obyvateľstva sa môžu vyskytnúť problémy nezávisle od širšieho obyvateľstva. V takýchto prípadoch sa vytvárajú konkrétne upozornenia, aby sa zabezpečilo, že upozornenia sa v skutočnosti budú spúšťať, ak tieto menej bežné scenáre zlyhajú aj napriek nižšiemu objemu. príklad: Obnovenie množín údajov, ktoré používajú konektor GitHub, zlyháva
Upozornenia na vnímaná spoľahlivosť – so zobrazenými chybami sa zobrazia aj upozornenia týkajúce sa rozpoznávania prípadov, keď sú zákazníci neúspešní v dôsledku akéhokoľvek typu chyby. Môže to zahŕňať zlyhania chýb používateľov a indikovať potrebu vylepšenej dokumentácie alebo upraveného používateľského prostredia. Tieto upozornenia môžu tiež informovať inžinierov o neočakávaných systémových chybách, ktoré by inak mohli byť nesprávne klasifikované ako chyba používateľa. príklad: Obnovenie množiny údajov zlyhá v dôsledku nesprávnych poverení
Ďalšou dôležitou rolou tímu SRE je automatizácia akcií TSG v čo najväčšej miere prostredníctvom automatizácie Azure. V prípadoch, keď nie je možná úplná automatizácia, tím SRE definuje akcie na obohatenie upozornenia užitočnými diagnostickými informáciami, ktoré sa týkajú incidentov, čím urýchli následné skúmanie. Takéto obohatenie je spárované s normatívnym usmernením v zodpovedajúcom TSG, aby inžinieri dynamických lokalít mohli buď vykonať konkrétnu akciu na zmiernenie incidentu alebo rýchlo eskalovať na MSP, aby mohli vykonať ďalšie preskúmanie.
V dôsledku tohto úsilia je viac ako 82% incidentov zmiernených bez akejkoľvek ľudskej interakcie. Zostávajúce incidenty majú dostatok údajov o obohacovaní a podpornej dokumentácie na spracovanie bez účasti MSP v 99,7% prípadov.
Živé SREs lokality tiež vynútia kvalitu upozornení niekoľkými spôsobmi vrátane nasledujúcich:
zabezpečenie toho, aby skupiny TSGs zahŕňali analýzu vplyvu a politiku eskalácie,
Zabezpečenie spustenia upozornení pre absolútne najmenšie časové okno na rýchlejšie zisťovanie
Zabezpečenie toho, aby upozornenia používali prahové hodnoty spoľahlivosti namiesto absolútnych limitov na škálovanie klastrov s rôznou veľkosťou.
Naše postupy na odpoveď na incidenty
Keď pre službu Fabric vytvorí automatizovaný incident na dynamickej lokalite, jednou z prvých priorít je oznámiť zákazníkom potenciálny vplyv. Služba Azure má cieľový čas oznámenia 15 minút, čo je ťažké dosiahnuť, keď sú oznámenia manuálne uverejňované manažérmi incidentov po pripojení k hovoru. Komunikácia v takýchto prípadoch môže byť z dôvodu požadovaných manuálnych analýz oneskorená alebo nepresná. Azure Monitoring ponúka centralizované riešenia na monitorovanie a upozorňovanie, ktoré na základe určitých metrík v tomto časovom okne dokážu zistiť možný vplyv. Avšak, Fabric je ponuka SaaS so zložitými scenármi a používateľskými interakciami, ktoré nemožno jednoducho modelovať a sledovať pomocou takýchto výstražných systémov. Tím služby Fabric v reakcii na to vyvinul Time To Notify Zero (TTN0) službe oznámení.
Filozofia živej lokality spoločnosti Fabric zdôrazňuje automatizované rozlíšenie incidentov s cieľom zlepšiť celkovú škálovateľnosť a udržateľnosť tímu SRE. Dôraz na automatizáciu umožňuje zmiernenie vo väčšom meradle a potenciálne sa môže vyhnúť nákladným vráteniam alebo rizikovým urýchleným opravám produkčných systémov. Keď je potrebné manuálne skúmanie, fabric prijme stupňovitý prístup s počiatočným vyšetrovaním, ktoré vykonal špecializovaný tím SRE. Členovia tímu SRE sa stretávajú s spravovaním incidentov na živej lokalite, uľahčovaním komunikácie medzi tímami a zmierňovaním vplyvu. V prípadoch, keď úradujúci člen tímu SRE potrebuje viac kontextu na ovplyvnený scenár alebo súčasť, môže sa do tejto oblasti zapojiť odborník na danú oblasť a požiadať o usmernenie. Okrem toho tím MSP vykonáva simulácie zlyhaní systémových súčastí, aby porozumeli problémom a zmierniť ich pred aktívnym incidentom na živej lokalite.
Po určení postihnutej súčasti alebo scenára služby má tím služby Fabric viacero techník na rýchle zmiernenie vplyvu. Niektoré z nich sú:
Aktivovať infraštruktúru súbežného nasadenia – služba Fabric podporuje spúšťanie rozličných verzií vyťažení v tom istom klastri, čo umožňuje tímu spustiť novú (alebo predchádzajúcu) verziu špecifického vyťaženia pre niektorých zákazníkov bez toho, aby sa spustilo nasadenie (alebo vrátenie zmien v plnej mierke). Tento prístup môže skrátiť čas zmiernenia na 15 minút a znížiť celkové riziko nasadenia.
Execute Business Continuity/Disaster Recovery (BCDR) proces – umožňuje tímu zlyhať pri primárnom vyťažení v tomto alternatívnom prostredí za tri minúty, ak sa v novej verzii služby zistí závažný problém. BCDR možno použiť aj vtedy, keď faktory prostredia alebo závislé služby bránia normálnemu fungovaniu primárneho klastra alebo oblasti.
využiť odolnosť závislých služieb – fabric proaktívne hodnotí a investuje do úsilia o odolnosť a redundanciu vo všetkých závislých službách (ako sú SQL, Redis Cache, Key Vault). Odolnosť zahŕňa dostatočné monitorovanie komponentov na zisťovanie upstreamovej a následných regresií, ako aj lokálnej, zonalskej a regionálnej redundancie (ak je to možné). Investovanie do týchto funkcií zabezpečí, že sa budú používať nástroje na automatické alebo manuálne spúšťanie operácií obnovenia, ktoré zmiernia vplyv postihnutej závislosti.
Čas oznámenia nula
Time To Notify Zero, známou aj ako TTN0, je plne automatizovaná služba na oznamovanie incidentov, ktorá používa našu internú infraštruktúru upozornení na identifikáciu konkrétnych scenárov a zákazníkov, ktorých ovplyvnil novovytvorený incident. Tiež je integrovaná s externými monitorovacími agentmi mimo služby Azure na zisťovanie problémov s pripojením, ktoré by inak mohli nezostať bez povšimnutia. TTN0 umožňuje zákazníkom prijímať e-maily, keď TTN0 zistí prerušenie služby alebo pokles. S TTN0 môže tím služby Fabric odoslať spoľahlivé a cielené oznámenia do 10 minút od času začatia vplyvu (čo je o 33% rýchlejšie ako cieľ služby Azure). Keďže riešenie je plne automatizované, z ľudskej chyby alebo oneskorenia je minimálne riziko.
Naše postupy na priebežné vylepšovania
Tím služby Fabric kontroluje všetky incidenty, ktoré majú vplyv na zákazníka počas týždennej kontroly služby, pričom zastupuje všetky technické skupiny, ktoré prispievajú k službe Fabric. Preskúmanie šíri kľúčové poznatky z incidentu vedúcim predstaviteľom v celej organizácii a poskytuje príležitosť prispôsobiť naše procesy na preklenutie medzier a riešenie nedostatkov.
Pred preskúmaním tím SRE pripraví obsah post-mortem a identifikuje predbežné položky opravy pre živý tím lokality a tím pre vývoj produktov. Medzi položky môžu patriť opravy kódu, rozšírená telemetria alebo aktualizované upozornenia alebo upozornenia TSGs. Fabric SREs sú oboznámení s mnohými z týchto oblastí a často proaktívne vykonávať úpravy v reálnom čase, zatiaľ čo reagovať na aktívny incident. Pomáha to zabezpečiť, aby sa zmeny do systému zahrnuli včas, aby sa zistila opakovanosť podobného problému. V prípadoch, keď bol incident výsledkom eskalácie zákazníkov, tím SRE upraví existujúce automatizované upozorňovanie a SLI tak, aby odrážali očakávania zákazníkov. V prípade malého počtu incidentov, ktoré vyžadujú eskaláciu vplyvného scenára/súčasti, bude tím služby Fabric SRE revidovať spôsoby, ako by sa rovnaký incident (alebo podobné incidenty) mohol zvládnuť bez eskalácie v budúcnosti. Podrobná analýza tímu SRE pomáha tímu vývoja produktov navrhnúť odolnejší, škálovateľný a podporovaný produkt.
Okrem kontroly konkrétnych postmortems, tím SRE tiež generuje zostavy o agregovaných údajoch o incidentoch na identifikáciu príležitostí na zlepšenie služieb, ako je napríklad budúca automatizácia zmiernenia incidentov alebo opravy produktov. Vytváranie zostáv kombinuje údaje z viacerých zdrojov vrátane tímu podpory zákazníkov, automatizovaného upozorňovania a telemetrie služby. Konsolidované zobrazenie poskytuje prehľad o tých problémoch, ktoré najviac negatívne ovplyvňujú stav služby a tímu, a tím SRE potom uprednostňuje potenciálne vylepšenia na základe celkového prínosu so spoľahlivosťou služby. Ak napríklad určité upozornenie spúšťa príliš často alebo vytvára neprimeraný vplyv na spoľahlivosť služieb, tím SRE môže spolupracovať s tímom na vývoj produktov a investovať do príslušných vylepšení kvality. Dokončenie týchto pracovných položiek vedie k zlepšeniu metrík služieb a dynamických lokalít a priamo prispieva k kľúčovým výsledkom cieľov organizácie (OKR). V prípadoch, keď je služba SLI konzistentne splnená už dlhú dobu, tím SRE môže navrhnúť zvýšenie výkonu služby SLO s cieľom poskytnúť lepšie možnosti pre našich zákazníkov.
Meranie úspešnosti prostredníctvom objektívnych kľúčových výsledkov (OKR)
Tím služby Fabric má komplexný súbor objektívnych kľúčových výsledkov (OKR), ktoré sa používajú na zabezpečenie celkového stavu služieb a spokojnosti zákazníkov. Zoznamy okrs možno rozdeliť do dvoch kategórií:
Service Health OKRs – tieto zoznamy okrs priamo alebo nepriamo merajú stav scenárov alebo súčastí v službe a často sa sledujú monitorovaním alebo upozornením. príklad: Jedna kapacita vo vlastníctve zákazníka nenačítava množiny údajov pre dotazovanie.
LIVE Site Health OKRs – tieto okrs priamo alebo nepriamo merajú, ako efektívne a účinne živé operácie lokality riešia incidenty a výpadky služieb. príklad: Čas na upovedomenie zákazníkov (TTN) o vplyve incidentu.
Čas potrebný na to, aby tím služby Fabric reagoval na incidenty merané spoločnosťami TTN, TTA a TTM, výrazne prekračuje ciele. Automatizácia upozornení priamo koreluje so schopnosťou tímu udržať exponenciálny rast služby a zároveň naďalej dosahovať alebo prekročiť cieľové časy odozvy v súvislosti s upozornením na incident, oznámením a zmierňovaním.
Uvedené žiadosti o prijatie zmien OKR aktívne sleduje tím živej lokality služby Fabric a tím hlavného vedenia, aby sa zabezpečilo, že tím bude naďalej spĺňať alebo prekročiť základnú hodnotu potrebnú na podporu značného rastu služieb, zachovať udržateľné dynamické vyťaženie lokality a zabezpečiť vysokú spokojnosť zákazníkov.