Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Algoritmus vzorkovania v službe Power BI zlepšuje vizuálne prvky, ktoré vzorkujú údaje s vysokou hustotou. Môžete napríklad vytvoriť čiarový graf vašich výsledkov predaja v maloobchodných predajniach, pričom každá predajňa má ročné tržby vo výške viac ako 10 000. Čiarový graf takýchto informácií o predaji by vzorkovala údaje z údajov pre všetky predajne a vytvorila čiarový graf s viacerými sériami, čím predstavuje základné údaje. Nezabudnite vybrať zmysluplné vyjadrenie týchto údajov, aby ste znázorňujú, ako sa časom predaj mení. Táto prax je bežná pri vizualizácii údajov s vysokou hustotou. Podrobnosti o vzorkovaní s vysokou hustotou sú popísané v tomto článku.
Poznámka
Algoritmus vzorkovania s vysokou hustotou popísaný v tomto článku je k dispozícii v aplikácii Power BI Desktop aj v služba Power BI.
Ako funguje vzorkovanie s vysokou hustotou
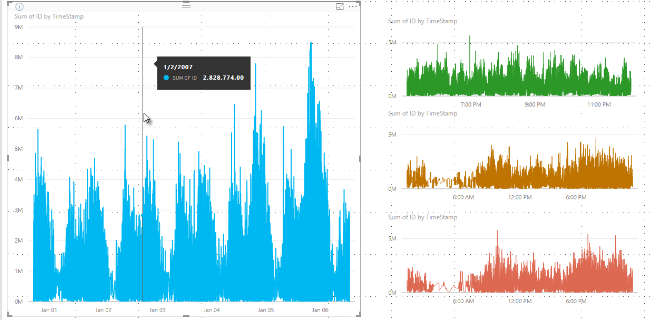
V minulosti služba Power BI vyberla kolekciu vzorových údajových bodov v plnom rozsahu základných údajov deterministickým spôsobom. Napríklad pri údajoch s vysokou hustotou vo vizuálnom prvku v rozmedzí jedného kalendárneho roka môže byť vo vizuálnom prvku zobrazených 350 vzorových údajových bodov, z ktorých každý bol vybraný tak, aby bola zabezpečená celá škála údajov vo vizuálnom prvku. Aby ste lepšie porozumeli tomu, ako sa to deje, predstavte si, že sme vykresľujú cenu akcií za obdobie jedného roka a vybrali 365 údajových bodov na vytvorenie vizuálneho grafu. To je jeden údajový bod pre každý deň.
V takejto situácii existuje veľa hodnôt ceny akcií v rámci každého dňa. Samozrejme, že môžu byť dni s vysokými a nízkymi hodnotami, ale tieto sa môžu vyskytnúť kedykoľvek počas dňa, keď je akciový trh otvorený. V prípade odberu vzoriek s vysokou hustotou, ak by bola základná dátová vzorka odobratá každý deň o 10:30 a 12:00, získate reprezentatívny snímok základných údajov, ako je napríklad cena o 10:30 a 12:00. Snímka však nemusí zaznamenať skutočnú vysokú a nízku cenu akcií pre tento reprezentatívny údajový bod v danom dni. V takejto aj v iných situáciách je odber vzoriek reprezentatívny pre základné údaje, ale nie vždy zachytí dôležité body, čo by v tomto prípade bolo denné vysoké a nízke ceny akcií.
Podľa definície sú údaje s vysokou hustotou vzorkované na čo najrýchlejšie vytvorenie vizualizácií, ktoré reagujú na interaktivitu. Príliš veľa údajových bodov na vizuáli ho môže spomaliť a môže znížiť viditeľnosť trendov. Spôsob vzorkovania údajov poháňa vytvorenie algoritmu vzorkovania s cieľom poskytnúť najlepšie vizualizačné skúsenosti. V aplikácii Power BI Desktop poskytuje algoritmus najlepšiu kombináciu odozvy, vyjadrenia a zachovania dôležitých bodov v každom časovom rýchlom filtri.
Ako funguje nový čiarový algoritmus vzorkovania
Algoritmus pre čiarové vzorkovanie údajov s vysokou hustotou je k dispozícii pre čiarový grafu a vizuálne prvky grafu so spojitou osou x.
Pre vizuálny prvok s vysokou hustotou služba Power BI inteligentne rozdelí vaše údaje na výseky s vysokým rozlíšením a potom vyberá dôležité body, ktoré reprezentujú každý kus. Tento proces rozdeľovania údajov s vysokým rozlíšením na výrezy je naladený tak, aby výsledný graf bol vizuálne nerozoznateľný od vykresľovania všetkých podkladových údajových bodov, ale bol rýchlejší a interaktívnejší.
Minimálne a maximálne hodnoty pre riadok s vizuálnymi prvkami s vysokou hustotou
Pre všetky vizualizácie platia nasledujúce obmedzenia:
Hodnota 3 500 je maximálny počet údajových bodov zobrazených na väčšine vizuálnych prvkov bez ohľadu na počet základných údajových bodov alebo radu. Výnimky nájdete v nasledujúcom zozname. Ak máte napríklad 10 radov s 350 údajovými bodmi, vizuál dosiahol maximálnu hodnotu obmedzenia celkového množstvo údajových bodov. Ak máte jeden rad, algoritmus sa domnieva, že môžete mať až 3 500 údajových bodov pre vzorkovanie základných bodov.
Existuje maximálne 60 radov pre všetky vizuálne prvky. Ak máte viac ako 60 radov, rozdeľte údaje a vytvorte rôzne vizuálne prvky maximálne do výšky 60 radov. Je vhodné použiť rýchly filter na zobrazenie len segmentov údajov, ale iba pre určité rady. Ak napríklad zobrazujete všetky podkategórie v legende, môžete použiť rýchly filter na filtrovanie celkovej kategórie na tej istej strane zostavy.
Maximálny počet obmedzení údajov je pri nasledujúcich typoch vizuálov vyšší, a teda pri obmedzení údajových bodov na hodnotu 3 500 ide o výnimky :
- Maximálna hodnota 150 000 údajových bodov pre vizuály R.
- 30 000 údajových bodov pre vizuály mapy Azure.
- Hodnota 10 000 údajových bodov pre niektoré konfigurácie bodového grafu (bodové grafy sú predvolene nastavené na hodnotu 3 500).
- Hodnotu 3 500 pre všetky ostatné vizuály, ktoré používajú vzorkovanie s vysokou hustotou. Niektoré iné vizuály môžu vizualizovať viac údajov, ale nebudú používať vzorkovanie.
Tieto parametre zabezpečujú, že vizuálne prvky v aplikácii Power BI Desktop sa vykreslia rýchlo, reagujú na interakciu s používateľmi a nevedú k neprimeraným výpočtovým nákladom v počítači, ktorý vykresľuje vizuálny prvok.
Vyhodnotenie reprezentatívnych údajových bodov pre čiarové vizuály s vysokou hustotou
Keď počet základných údajových bodov presahuje maximálny počet údajových bodov, ktoré môžu byť reprezentované vo vizuálnom prvku, začína sa proces nazývaný rozdelenie . Rozdelením sa základné údaje rozdelia do skupín, ktoré sa nazývajú priehradky , a potom ich opakovane dolaďuje.
Algoritmus vytvorí ľubovoľný počet priehradiek s cieľom vytvoriť najväčšiu granularitu vizuálneho prvku. V rámci každej priehradky nájde algoritmus minimálnu a maximálnu hodnotu údajov, aby zaistil, že dôležité a významné hodnoty, ako napríklad extrémy, budú zachytené a zobrazené vo vizuálnom prvku. Na základe výsledkov rozdeľovania a následného vyhodnotenia údajov službou Power BI sa určuje minimálne rozlíšenie pre os x vizuálneho prvku s cieľom zabezpečiť jeho maximálnu zrnitosť.
Ako už bolo spomenuté predtým, minimálna granularita pre každý rad je 350 bodov a maximálna hodnota pre väčšinu vizuálov je 3 500. Výnimky sú uvedené v predchádzajúcich odsekoch.
Každú priehradku reprezentujú dva údajové body, ktoré sa stávajú reprezentatívnymi údajovými bodmi priehradky vo vizuálnom prvku. Údajové body predstavujú vysokú a nízku hodnotu pre danú priehradku. Výberom položky Vysoká a Nízka proces rozdelenia zabezpečí zachytenie a vykreslenie každej dôležitej vysokej hodnoty alebo významnej nízkej hodnoty vo vizuálnom prvku.
Ak sa zdá, že zabezpečiť, aby príležitostný odchýlok bol zachytený a správne zobrazený vo vizuálnom prvku, je to naozaj tak. To je presný dôvod algoritmu a procesu rozdelenia.
Popisy a čiarové vzorkovanie údajov s vysokou hustotou
Je dôležité poznamenať, že tento proces rozdelenia s cieľom zachytenia a zobrazenia minimálnej a maximálnej hodnoty v danej priehradky môže mať vplyv spôsob zobrazenia popisov, keď sa pohybujete nad údajovými bodmi. Ak chcete pochopiť, ako a prečo k tomu dochádza, pozrite si náš príklad cien akcií.
Povedzme, že vytvárate vizuálny prvok založený na cene akcií a porovnávate dve rôzne akcie, pričom obe používajú vzorkovanie údajov s vysokou hustotou. Základné údaje pre každý rad majú veľa údajových bodov. Napríklad môžete zaznamenať cenu akcií každú sekundu dňa. Algoritmus čiarového vzorkovania údajov s vysokou hustotou vykonáva rozdelenie nezávisle v rámci každého radu.
Teraz povedzme, že cena prvej akcie vzrastie o 12:02 hod. Potom o 10 sekúnd znovu klesne. Ide o dôležitý údajový bod. Keď sa pre túto akciu uskutoční rozdelenie, vysoká hodnota o 12:02 hod. je reprezentatívnym údajovým bodom pre túto priehradku.
Druhá akcia však nemala ani vysokú ani nízku hodnotu v priehradky, ktorá obsahovala čas 12:02 hod. Pravdepodobne sa vysoká a nízka hodnota v priehradky s časom 12:02 vyskytla o tri minúty neskôr. V takejto situácii sa po vytvorení čiarového grafu ukázaním na hodnotu 12:02 zobrazí hodnota v popise prvej akcie. Dôvodom je, že vyskočila o 12:02 hod. a táto hodnota bola vybraná ako vysoký údajový bod tejto priehradky. Pre druhú akciu však v popise o 12:02 neuvidíte žiadnu hodnotu. Dôvodom je, že druhá akcia nemala vysokú ani nízku hodnotu pre priehradku, ktorá obsahovala hodnotu 12:02 hod. Preto k dispozícii nie sú žiadne údaje, ktoré by sa zobrazovali pre druhú akciu s dátumom 12:02, a preto sa nezobrazujú žiadne údaje popisu.
K tejto situácii často dochádza pri popisoch. Vysoké a nízke hodnoty pre konkrétnu priehradku sa pravdepodobne nebudú úplne zhodovať s bodmi hodnôt rovnomerne škálovaných na osi x a popis nezobrazuje hodnotu.
Ako zapnúť vzorkovanie s vysokou hustotou
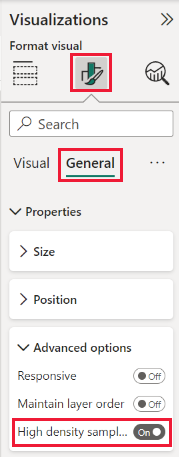
Algoritmus je predvolene nastavený na možnosť Zapnuté. Ak chcete zmeniť toto nastavenie, prejdite na tablu Formátovanie na karte Všeobecné a pozdĺž spodnej časti sa zobrazí jazdec vzorkovania s vysokou hustotou. Výberom jazdca prepnete možnosť Zapnúť alebo Vypnúť.
Dôležité informácie a obmedzenia
Algoritmus pre vzorkovanie s vysokou hustotou je dôležitým vylepšením služby Power BI, ale je potrebné vedieť niekoľko skutočností, ak chcete pracovať s hodnotami a údajmi s vysokou hustotou.
Z dôvodu zvýšenej granularity a rozdelenia môžu popisy zobrazovať hodnotu len v prípade, že sú reprezentatívne údaje zladené s vaším kurzorom. Ďalšie informácie nájdete v časti Popisy a čiarové vzorkovanie údajov s vysokou hustotou v tomto článku.
Keď je veľkosť celkového zdroja údajov príliš veľká, algoritmus vylúči rad (prvky legendy), aby vyhovoval maximálnemu obmedzeniu importu údajov.
- V takom prípade algoritmus abecedne zoradí legendy série a spustí zoznam prvkov legendy v abecednom poradí, kým dosiahne maximálnu hodnotu importu údajov a neimportuje ďalšie rady.
Ak má základná množina údajov viac ako 60 radov, maximálny počet radov algoritmus abecedne zoradí rad a eliminuje rady po 60. abecedne zoradenom rade.
Ak hodnoty v údajoch nie sú číselné alebo dátumové/časové, služba Power BI nebude používať algoritmus a obnoví predchádzajúci algoritmus vzorkovania bez vysokej hustoty.
Nastavenie Zobraziť položky bez údajov nie je podporované s algoritmom.
Tento algoritmus nie je podporovaný pri použití dynamického pripojenia k modelu hosťovanému v službe SQL Server Analysis Services vo verzii 2016 alebo novšej. Je podporovaný v modeloch hosťovaných v službe Power BI alebo Azure Analysis Services.