Techniky znižovania objemu údajov na modelovanie importu.
Tento článok sa zameriava na modelárov údajov aplikácie Power BI Desktop, ktorí vyvíjajú a publikujú sémantické modely služby Power BI. Konkrétne popisuje rôzne techniky, ktoré pomáhajú znížiť načítanie údajov do importovaných modelov.
Modely importu sa načítavajú s údajmi, ktoré sa komprimujú a optimalizujú a následne sa uložia na disk pomocou nástroja úložiska VertiPaq. Pri načítavaní zdrojových údajov do pamäte je možné dosiahnuť 10-násobnú kompresiu, preto je rozumné očakávať, že 10 GB zdrojových údajov sa môže skomprimovať na veľkosť približne 1 GB. Okrem toho je možné dosiahnuť ďalších 20 % zníženia na disku.
Napriek efektivite, ktorú dosiahol nástroj úložiska VertiPaq, by ste sa mali snažiť minimalizovať údaje načítané do vašich modelov. Platí to najmä pre veľké modely alebo modely, od ktorými očakávate, že sa budú zväčšovať a časom sa stanú veľkými. Medzi štyri presvedčivé dôvody patrí:
- Veľkosť väčších modelov nemusí byť podporovaná vašou kapacitou. Zdieľaná kapacita môže hostiť modely s veľkosťou až 1 GB, zatiaľ čo kapacity Premium môžu hosťovať väčšie modely v závislosti od jednotky SKU. Ďalšie informácie nájdete veľkých sémantických modelov v aplikácii Power BI Premium.
- Menšie veľkosti modelov znižujú konflikt v zdrojoch kapacity, najmä pamäti. Mnoho menších modelov v kapacite sa môže súbežne načítať dlhší čas, čo má za následok nižšie miery vyradenia.
- Menšie veľkosti modelov dosahujú rýchlejšie obnovenie údajov, čo má za následok nižšie časové oneskorenie vytvárania zostáv, vyššiu priepustnosť obnovenia sémantického modelu a menší tlak na zdrojový systém a zdroje kapacity.
- Menšie počty riadkov tabuľky môžu viesť k rýchlejšiemu vyhodnocovaniu výpočtov, čo má za následok lepší celkový výkon dotazu.
Dôležité
V čase, keď sa tento článok týka služby Power BI Premium alebo jej predplatných kapacity (skladové jednotky SKU P). Spoločnosť Microsoft v súčasnosti konsoliduje možnosti nákupu a vyradí skladové jednotky SKU služby Power BI Premium na kapacitu. Noví a existujúci zákazníci by namiesto toho mali zvážiť zakúpenie predplatného kapacity služby Fabric (skladové jednotky F SKU).
Ďalšie informácie nájdete v téme Dôležitá aktualizácia pre licencie Power BI Premium a Power BI Premium: najčastejšie otázky.
Odstránenie nepotrebných stĺpcov,
Stĺpce tabuľky modelu majú dva hlavné účely:
- vytváranie zostávna dosiahnutie návrhov zostáv, ktoré vhodným spôsobom filtrujú, zoskupujú a sumarizujú údaje modelu.
- štruktúra modeluprostredníctvom podpory modelových vzťahov, výpočtov modelu, rolí zabezpečenia a dokonca aj formátovania farieb údajov.
Pravdepodobne môžete odstrániť ľubovoľný stĺpec, ktorý neslúži na niektorý z týchto účelov. Odstránenie stĺpca z tabuľky sa niekedy označuje ako zvislé filtrovanie.
Odporúčame vám navrhnúť modely s tým správnym počtom stĺpcov na základe vašich známych požiadaviek na vytváranie zostáv. Vaše požiadavky sa môžu v priebehu času meniť, ale majte na pamäti, že je jednoduchšie pridať stĺpce neskôr, ako ich potom odstrániť. Odstránením stĺpcov sa môžu prerušiť zostavy alebo štruktúra modelu.
Odstránenie nepotrebných riadkov
Mali by ste načítať tabuľky modelu s čo najmenším počtom riadkov. To môžete dosiahnuť načítaním filtrovanej množiny riadkov do tabuliek modelov z dvoch rôznych dôvodov: filtrovať podľa času alebo podľa entity. Odstránenie riadkov sa niekedy označuje ako vodorovné filtrovanie.
- Filtrovanie podľa času zahŕňa obmedzenie množstva histórie údajov načítaných do tabuliek faktov (a obmedzenie riadkov dátumov načítaných do tabuliek dátumov modelu). Odporúčame, aby ste predvolene nenačítali celú dostupnú históriu, pokiaľ nejde o známu požiadavku na vytváranie zostáv. Filtre Power Query založené na čase môžete implementovať s parametrami a dokonca ich nastaviť tak, aby používali relatívne časové obdobia (v porovnaní s dátumom obnovenia – napríklad za posledných päť rokov). Majte tiež na pamäti, že retrospektívna zmena časového filtra nepreruší zostavy. To bude mať za následok len menej (alebo viac) histórie údajov dostupných v zostavách.
- Filtrovanie podľa entity zahŕňa načítanie podmnožiny zdrojových údajov do modelu. Napríklad namiesto načítania faktov o predaji pre všetky oblasti predaja sa načítajú len fakty pre jednu oblasť. Tento prístup k návrhu má za následok mnoho menších modelov a môže tiež eliminovať potrebu definovať zabezpečenia na úrovni riadkov– ale vyžaduje sa udelenie konkrétnych povolení sémantického modelu v službe Power BI a vytváranie duplicitných zostáv, ktoré sa pripájajú ku každému sémantickému modelu. Na zjednodušenie spravovania a publikovania môžete použiť parametre doplnku Power Query a súbory šablón služby Power BI. Ďalšie informácie nájdete Vytváranie a používanie šablón zostáv v aplikácii Power BI Desktop.
Spôsob zoskupenia a zhrnutie
Asi najúčinnejšou technikou na zmenšenie veľkosti modelu je načítanie vopred zhrnutých údajov. Pomocou tejto techniky môžete zvýšiť množstvo tabuliek faktov. Je tu však zreteľné trade-off, čo má za následok stratu podrobností.
Zoberme si príklad, kde tabuľka zdrojových faktov predaja ukladá jeden riadok na riadok objednávky. Významné zníženie údajov sa dá dosiahnuť zhrnutím všetkých metrík predaja a zoskupovaním podľa dátumu, zákazníka a produktu. Ešte výraznejšie zníženie údajov je možné dosiahnuť zoskupením podľa dátumu na úrovni mesiaca. Hoci by sa tým mohlo dosiahnuť zmenšenie modelu o 99%, vytváranie zostáv na dennej úrovni alebo na úrovni jednotlivých riadkov objednávok už nie je možné. Pri rozhodovaní o zhrnutí údajov faktov sa vždy vyžaduje kompromisy. Kompromis by mohol byť zmiernený návrhom modelu, ktorý zahŕňa niektoré tabuľky v režime úložiska DirectQuery, čo je popísané ďalej v tomto článku.
Optimalizácia typov údajov v stĺpcoch
Nástroj úložiska VertiPaq používa pre každý stĺpec samostatné interné štruktúry údajov. Podľa návrhu tieto štruktúry údajov dosahujú najvyššie optimalizácie pre číselné stĺpce údajov, ktoré používajú hodnotu kódovania. Text a iné nečíselné údaje však používajú kódovanie hash. Kódovanie Hash vyžaduje, aby nástroj na ukladanie priradil numerický identifikátor ku každej jedinečnej hodnote obsiahnutej v stĺpci. Ide o numerický identifikátor, ktorý sa potom uloží v štruktúre údajov a počas ukladania a dotazovania vyžaduje vyhľadávanie hash.
V niektorých konkrétnych prípadoch môžete skonvertovať zdrojové textové údaje na číselné hodnoty. Napríklad číslo predajnej objednávky môže byť konzistentne dané textovou hodnotou (napríklad SO123456). V tomto prípade možno predponu SO odstrániť a hodnota čísla poradia sa konvertuje na celé číslo. V prípade veľkých tabuliek môže dôjsť k významnému zníženiu objemu údajov, najmä ak stĺpec obsahuje jedinečné hodnoty alebo hodnoty s vysokou kardinalitou.
V tomto príklade odporúčame nastaviť predvolenú vlastnosť súhrnu stĺpca na Do Not Summarize. Pomáha to vyhnúť sa nevhodnej sumarizácie číselných hodnôt objednávok.
Preferencie pre vlastné stĺpce
Nástroj úložiska VertiPaq ukladá model vypočítaných stĺpcov (definovaných v jazyku DAX) rovnako ako bežné stĺpce zo zdrojov Power Query. Interné štruktúry údajov sa však ukladajú mierne odlišne a zvyčajne dosahujú menej účinnú kompresiu. Štruktúry údajov sa tiež zostavia po načítaní všetkých tabuliek Power Query, čo môže viesť k predĺženiu časov obnovenia údajov. Preto je menej efektívne pridať stĺpce tabuľky ako vypočítané stĺpce ako vypočítané stĺpce Power Query (definované v M).
Vždy, keď je to možné, uprednostníte vytváranie vlastných stĺpcov v doplnku Power Query. Keď je zdrojom databáza, môžete dosiahnuť vyššiu efektivitu načítania dvomi spôsobmi: Výpočet možno definovať v príkaze SQL (pomocou jazyka natívneho dotazu poskytovateľa) alebo sa môže uskutočniť ako stĺpec v zdroji údajov.
V niektorých inštanciách však možno lepšie vybrať model vypočítaných stĺpcov. Je to tak, keď vzorec zahŕňa vyhodnocovanie mierok, alebo si vyžaduje konkrétnu funkciu modelovania podporovanú len vo funkciách DAX. Informácie o jednom z takýchto príkladov nájdete Pochopenie funkcií pre hierarchiu typu nadradený-podriadený v jazyku DAX.
Zakázanie načítania dotazu Power Query
Dotazy Power Query, ktoré sú určené na podporu integrácie údajov s inými dotazmi, by sa nemali načítať do modelu. Ak sa chcete vyhnúť načítavaniu týchto dotazov do modelu, uistite sa, že v týchto inštanciách zakážete načítanie dotazov.
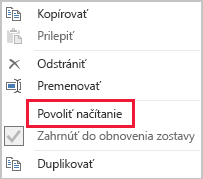
Vypnutie automatického dátumu a času
Power BI Desktop obsahuje možnosť s názvom Automatický dátum a čas. Ak je povolená, vytvorí pre každý stĺpec dátumov v modeli skryté tabuľky automatického dátumu a času. Táto možnosť podporuje autorov zostáv pri konfigurácii filtrov, zoskupovaní a akcií prechodu na detaily pre časové obdobia kalendára. Skryté tabuľky sú v skutočnosti vypočítané tabuľky, ktoré zvyšujú veľkosť modelu.
Ďalšie informácie nájdete Pokyny pre automatický dátum a čas v aplikácii Power BI Desktop.
Používanie režimu úložiska DirectQuery
Režim úložiska DirectQuery je alternatívou režimu úložiska Import. Tabuľky modelu DirectQuery neimportujú údaje. Namiesto toho pozostávajú iba z metaúdajov definujúcich štruktúru tabuľky. Pri dotazovaní tabuľky sa na načítanie údajov zo základného zdroja údajov používajú natívne dotazy. Keď skombinujete tabuľky režimu úložiska importu a DirectQuery v jednom modeli, označuje sa ako zložený model.
Efektívna technika na zmenšenie veľkosti modelu je nastavenie režimu úložiska pre väčšie tabuľky faktov do režimu DirectQuery. Zoberme si, že tento prístup k návrhu často dobre funguje s Zoskupovať podľa a zhrnúť predchádzajúcou technikou. Súhrnné údaje o predaji by sa napríklad mohli použiť na dosiahnutie vysokého výkonu súhrnných zostáv. Strana s podrobnou analýzou môže zobraziť podrobný predaj pre konkrétny (a úzky) kontext filtra, ktorý zobrazuje všetky predajné objednávky. V tomto príklade by strana s podrobnou analýzou mohla načítať údaje o predajných objednávkach vrátane vizuálov založených na tabuľke modelu DirectQuery.
Existujú však mnohé vplyvy zabezpečenia a výkonu súvisiace s režimom úložiska DirectQuery a zloženými modelmi. Ďalšie informácie nájdete Používanie zložených modelov v aplikácii Power BI Desktop.
Súvisiaci obsah
Ďalšie informácie súvisiace s týmto článkom nájdete v nasledujúcich článkoch:
- sémantických režimov modelu v službe Power BI
- Režim úložiska v aplikácii Power BI Desktop
- Máte nejaké otázky? Skúste sa spýtať na komunity Fabric
- Návrhy? prispievať nápadmi na zlepšenie v látkach