Umelá inteligencia s tokmi údajov
Tento článok popisuje, ako môžete používať umelú inteligenciu (AI) s tokmi údajov. Tento článok popisuje:
- Cognitive Services
- Automatizované strojové učenie
- Integrácia služieb Azure strojové učenie
Dôležité
Vytváranie modelov služby Power BI Automated strojové učenie (automatizované strojové učenia) pre toky údajov v1 sa prestalo a už nie je k dispozícii. Zákazníkom sa odporúča migrovať vaše riešenie do funkcie automatizovaného strojového učenia v službe Microsoft Fabric. Ďalšie informácie nájdete v oznámení o odchode do dôchodku.
Služby Cognitive Services v Power BI
So službami Cognitive Services v Power BI môžete použiť rôzne algoritmy zo služieb Azure Cognitive Services na obohatenie svojich údajov pri samoobslužnej príprave údajov pre Toky údajov.
Služby, ktoré sú dnes podporované, sú Analýza nálady, Extrakcia kľúčovej frázy, Zisťovanie jazyka a Označovanie obrázkov. Transformácie sa vykonávajú na služba Power BI a nevyžadujú predplatné služieb Azure Cognitive Services. Táto funkcia vyžaduje Power BI Premium.
Povolenie funkcií AI
Kognitívne služby sú podporované pre uzly kapacity Premium EM2, A2, P1 alebo F64 a iné uzly s viacerými zdrojmi. Kognitívne služby sú k dispozícii aj s licenciou Premium na používateľa. Na spustenie kognitívnych služieb sa používa samostatné vyťaženie umelej inteligencie v kapacite. Pred použitím kognitívnych služieb v Power BI je potrebné povoliť vyťaženie umelej inteligencie v nastaveniach kapacity portálu na správu. Vyťaženie umelej inteligencie môžete zapnúť v sekcii pracovného vyťaženia.

Začíname so službami Cognitive Services v Power BI
Transformácie v Cognitive Services sú súčasťou samoobslužnej prípravy údajov pre toky údajov. Ak chcete obohatiť svoje údaje so službami Cognitive Services, začnite s úpravou toku údajov.

Vyberte tlačidlo Prehľady UI na hornom páse s nástrojmi Editor Power Query.

V kontextovom okne vyberte funkciu, ktorú chcete použiť, a údaje, ktoré chcete transformovať. V tomto príklade sa hodnotí nálada stĺpca, ktorý obsahuje text recenzie.

LanguageISOCode je voliteľný vstup na určenie jazyka textu. Tento stĺpec očakáva kód ISO. Ako vstup pre LanguageISOCode môžete použiť stĺpec, alebo môžete použiť statický stĺpec. V tomto príklade je pre celý stĺpec jazyk zadaný ako angličtina (en). Ak tento stĺpec ponecháte prázdny, Power BI pred použitím funkcie automaticky zistí jazyk. V ďalšom kroku vyberte položku Vyvolať.

Po vyvolaní funkcie sa výsledok pridá ako nový stĺpec do tabuľky. Transformácia sa tiež pridá ako uplatnený krok v dotaze.

Ak funkcia vráti viacero výstupných stĺpcov, vyvolaním funkcie sa pridá nový stĺpec s riadkom viacerých výstupných stĺpcov.
Pomocou možnosti rozbalenia pridajte k svojim údajom jednu alebo obe hodnoty ako stĺpce.

Dostupné funkcie
Táto časť popisuje dostupné funkcie v službe Cognitive Services v Power BI.
Rozpoznať jazyk
Funkcia zisťovania jazyka vyhodnotí textový vstup a pre každý stĺpec vráti názov jazyka a identifikátor ISO. Táto funkcia je užitočná pre stĺpce údajov, ktoré zhromažďujú ľubovoľný text, kde je jazyk neznámy. Funkcia očakáva, že na vstupe budú údaje v textovom formáte.
Analýza textu dokáže rozlíšiť až 120 jazykov. Ďalšie informácie nájdete v téme Čo je zisťovanie jazyka v službe Azure Cognitive Service for Language.
Extrahovanie kľúčových fráz
Funkcia Extrakcia kľúčovej frázy vyhodnocuje neštruktúrovaný text a pre každý textový stĺpec vráti zoznam kľúčových fráz. Funkcia vyžaduje ako vstup textový stĺpec a akceptuje voliteľný vstup pre LanguageISOCode. Ďalšie informácie nájdete v téme Začíname.
Extrakcia kľúčovej frázy funguje najlepšie, keď jej dodáte väčšie kusy textu, s ktorými môže pracovať, na rozdiel od analýzy nálady. Analýza nálady funguje lepšie na menších blokoch textu. Ak chcete získať najlepšie výsledky z oboch operácií, zvážte zodpovedajúcim spôsobom zmeniť nastavenie vstupov.
Citové skóre
Funkcia Citové skóre vyhodnotí textový vstup a vráti citové skóre pre každý dokument v rozmedzí od 0 (negatívne) až 1 (pozitívne). Táto funkcia je užitočná na zisťovanie pozitívnej a negatívnej nálady v sociálnych sieťach, recenziách zákazníkov a diskusných fórach.
Analýza textu používa klasifikačný algoritmus strojového učenia na generovanie citového skóre od 0 po 1. Skóre bližšie k 1 označuje pozitívnu náladu. Skóre bližšie k 0 označuje negatívnu náladu. Model má vopred naučené rozsiahle množstvo textu, v rámci čoho má priradenia nálady. V súčasnosti nie je možné poskytnúť vlastné údaje na školenie. Model používa počas analýzy textu kombináciu techník vrátane spracovania textu, analýzy častí reči, umiestnenia slov a spojov medzi slovami. Ďalšie informácie o algoritme nájdete v téme strojové učenie a Analýza textu.
Analýza nálady sa vykonáva v celom vstupnom stĺpci, a nie extrakciou nálady pre konkrétnu tabuľku v texte. V praxi existuje tendencia pre zlepšenie presnosti hodnotenia, ak dokumenty obsahujú jednu alebo dve vety a nie veľký blok textu. Vo fáze hodnotenia objektívnosti model určuje, či je vstupný stĺpec ako celok objektívny alebo obsahuje nálady. Vstupný stĺpec, ktorý je väčšinou objektívny, nepostúpi do frázy zisťovania nálady, výsledkom čoho je skóre 0,50 bez ďalšieho spracovania. Pre vstupné stĺpce, ktoré pokračujú v kanáli, sa v ďalšej fáze vygeneruje skóre väčšie alebo menšie ako 0,50 v závislosti od stupňa nálady zistenej vo vstupnom stĺpci.
V súčasnosti funkcia Analýza nálady podporuje angličtinu, nemčinu, španielčinu a francúzštinu. Ostatné jazyky sú v režime ukážky. Ďalšie informácie nájdete v téme Čo je zisťovanie jazyka v službe Azure Cognitive Service for Language.
Označovanie obrázkov
Funkcia Označovanie obrázkov vráti značky na základe viac ako 2 000 rozpoznateľných objektov, živých bytostí, scenérií a akcií. Ak sú značky nejednoznačné alebo nie sú všeobecne známe, výstup poskytuje "tipy" na objasnenie významu značky v kontexte známeho prostredia. Značky nie sú usporiadané ako taxonómia a neexistujú žiadne hierarchie dedenia. Kolekcia obsahových značiek vytvára základ pre popis obrázka zobrazený ako jazyk čitateľný ľuďmi vo formáte celých viet.
Po nahraní obrázka alebo zadaní URL adresy obrázka algoritmy Computer Vision výstup značiek na základe objektov, živých bytostí a akcií identifikovaných na obrázku. Označovanie nie je obmedzené na hlavný predmet, ako je napríklad osoba v popredí, ale obsahuje aj prostredie (vnútorné alebo vonkajšie), nábytok, nástroje, rastliny, zvieratá, príslušenstvo, zariadenia a podobne.
Táto funkcia vyžaduje ako vstup URL adresu obrázka alebo stĺpec abase-64. V súčasnosti označovanie obrázkov podporuje angličtinu, španielčinu, japončinu, portugalčinu a zjednodušenú čínštinu. Ďalšie informácie nájdete v téme Rozhranie ComputerVision.
Automatizované strojové učenie v službe Power BI
Automatizované strojové učenie pre toky údajov umožňuje podnikových analytikom trénovať, overovať a vyvolávať modely strojového učenia priamo v službe Power BI. Ponúka jednoduchý zážitok z vytvárania nového modelu strojového učenia, v ktorom analytici môžu používať svoje toky údajov na zadávanie vstupných údajov na trénovaie modelu. Služba automaticky extrahuje najrelevantnejšie funkcie, vyberá vhodný algoritmus a ladí a overuje model strojového učenia. Power BI po natrénovaní modelu automaticky vygeneruje zostavu výkonu s výsledkami overenia. Model je potom možné vyvolať v prípade akýchkoľvek nových alebo aktualizovaných údajov v toku údajov.
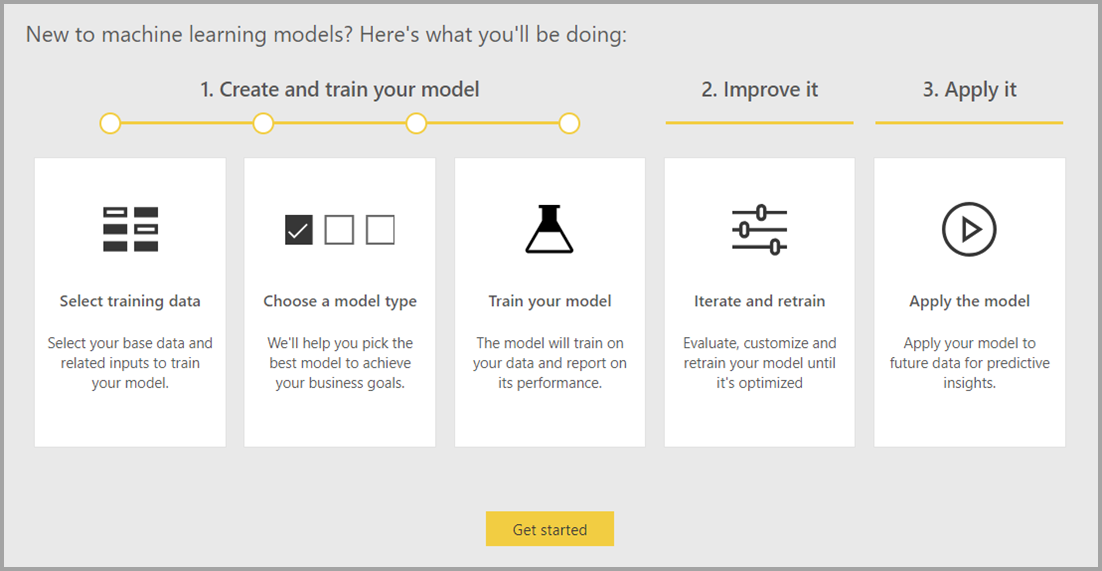
Automatizované strojové učenie je k dispozícii len pre toky údajov hosťované v kapacitách Premium a Embedded služby Power BI.
Práca s automatizovanému strojového učenia
Strojové učenie a umelá inteligencia sú svedkami bezprecedentného nárastu popularity zo strany priemyselných odvetví a oblastí vedeckého výskumu. Podniky tiež hľadajú spôsoby, ako integrovať tieto nové technológie do svojej prevádzky.
Toky údajov ponúkajú samoobslužnú prípravu údajov pre big data. Automatizované strojové učenie je integrované do tokov údajov a umožňuje vám využiť svoju prípravu údajov na vytváranie modelov strojového učenia priamo v službe Power BI.
Automatizované strojové učenie v službe Power BI umožňuje analytikom údajov používať toky údajov na vytváranie modelov strojového učenia v zjednodušenom prostredí, a to len pomocou zručností v službe Power BI. Power BI automatizuje väčšinu dátovej vedy, ktorá sa skrýva za tvorbou modelov strojového učenia. K jeho zabezpečeniu sú potrebné bezpečnostné prvky, ktoré zabezpečujú, že vytvorený model má dobrú kvalitu, a poskytuje prehľad o procese použitom na vytvorenie modelu strojového učenia.
Automatizácia strojového učenia podporuje pre toky údajov vytváranie binárnych predpovedí a klasifikácií a regresných modelov. Tieto funkcie sú typy techník strojového učenia pod dohľadom, čo znamená, že sa učia zo známych výsledkov minulých pozorovaní, aby mohli predpovedať výsledky ďalších pozorovaní. Vstupný sémantický model na trénovaie modelu automatizovaného strojového učenia je množina riadkov, ktoré sú označené známymi výsledkami.
Automatizované strojové učenie v službe Power BI integruje automatizované strojové učenie zo služby Azure strojové učenie, čím vám umožňuje vytvárať modely strojového učenia. Používanie automatizovaného strojového učenia v službe Power BI však predplatné služby Azure nevyžaduje. Služba Power BI úplne spravuje proces trénovania a hosťovania modelov strojového učenia.
Automatizované strojové učenie po natrénovaní modelu strojového učenia automaticky vygeneruje zostavu služby Power BI, ktorá vám objasní predpokladaný výkon vášho modelu strojového učenia. Automatizované strojové učenie zdôrazňuje zrozumiteľnosť tým, že medzi vstupmi, ktoré ovplyvňujú predpovede vrátené vaším modelom, zvýrazňuje kľúčové vplyvy. Zostava obsahuje aj kľúčové metriky pre model.
Ostatné strany vygenerovaných zostáv zobrazujú štatistický súhrn modelu a podrobnosti trénovania. Štatistický súhrn je zaujímavý pre používateľov, ktorí chcú vidieť štandardné mierky pre výkon modelu v rámci dátovej vedy. Podrobnosti trénovania prinášajú súhrn všetkých iterácií, ktoré boli spustené na vytvorenie modelu, so súvisiacimi parametrami modelovania. Popisuje tiež, ako sa každý vstup použil na vytvorenie modelu strojového učenia.
Potom môžete svoj model strojového učenia použiť na údaje na bodovanie. Po obnovení toku údajov sa údaje aktualizujú o predpovede z modelu strojového učenia. Power BI ponúka aj individuálne vysvetlenie každej konkrétnej predpovede, ktorú model strojového učenia prinesie.
Vytvorenie modelu strojového učenia
Táto časť sa venuje vytváraniu modelu automatizovaného strojového učenia.
Príprava údajov na vytvorenie modelu strojového učenia
Ak chcete vytvoriť model strojového učenia v službe Power BI, najskôr musíte vytvoriť tok údajov pre údaje obsahujúce informácie o historických výsledkoch, ktoré sa použijú na trénovanie modelu strojového učenia. Mali by ste tiež pridať vypočítané stĺpce pre všetky obchodné metriky, ktoré môžu byť silnými prediktormi pre výsledok, ktorý sa pokúšate predpovedať. Podrobnosti o konfigurácii toku údajov nájdete v téme Konfigurácia a používanie toku údajov.
Automatizované strojové učenie má špecifické požiadavky na údaje na trénovanie modelu strojového učenia. Tieto požiadavky sú popísané v nasledujúcich sekciách, a to podľa príslušných typov modelov.
Konfigurácia vstupov modelu strojového učenia
Ak chcete vytvoriť model automatizovaného strojového učenia, vyberte ikonu strojového učenia zo stĺpca Akcie tabuľky toku údajov a potom vyberte položku Pridať model strojového učenia.
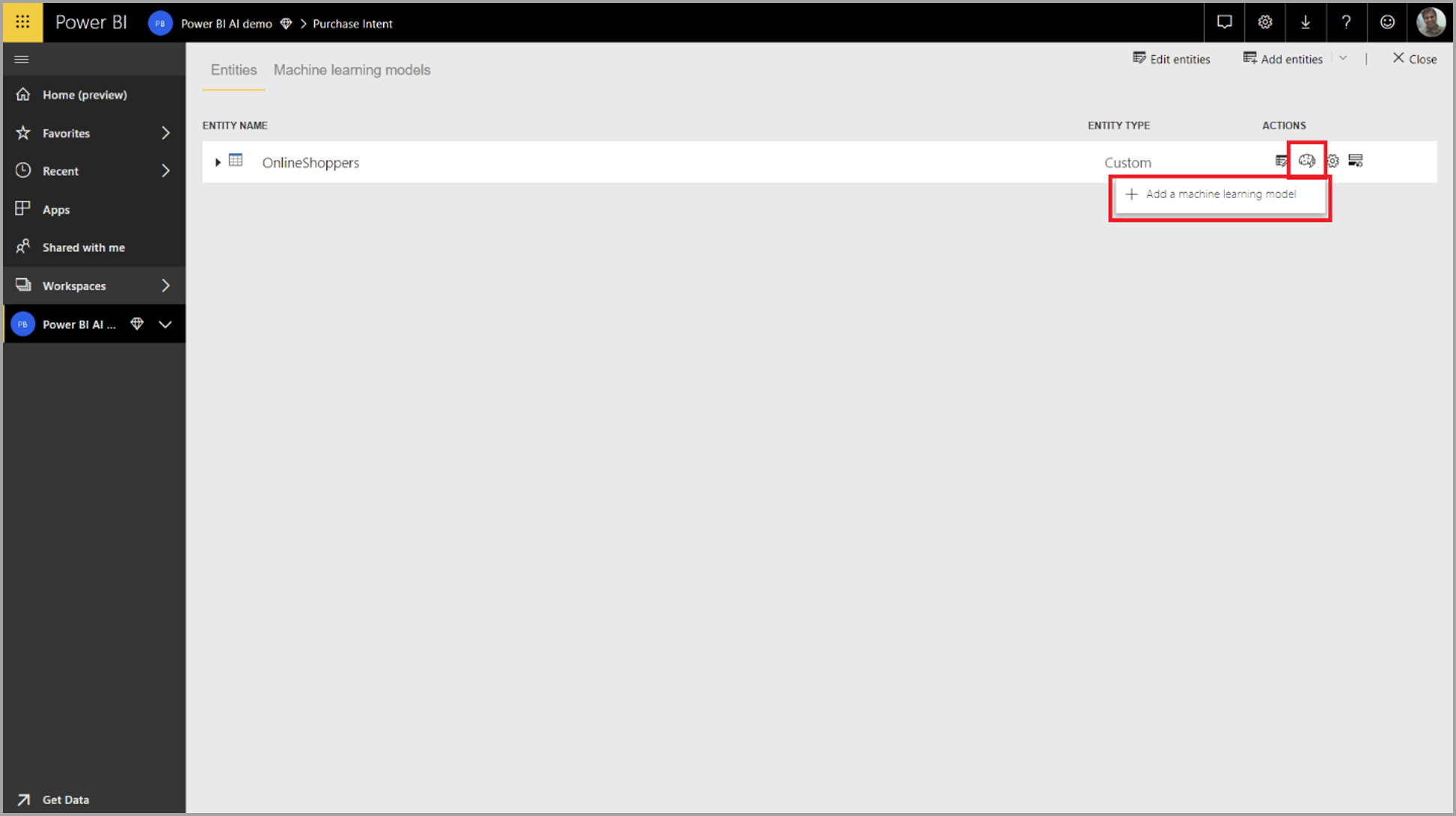
Spustí sa zjednodušené prostredie so sprievodcom, ktorý vás prevedie procesom vytvárania modelu strojového učenia. Sprievodca zahŕňa nasledujúce jednoduché kroky.
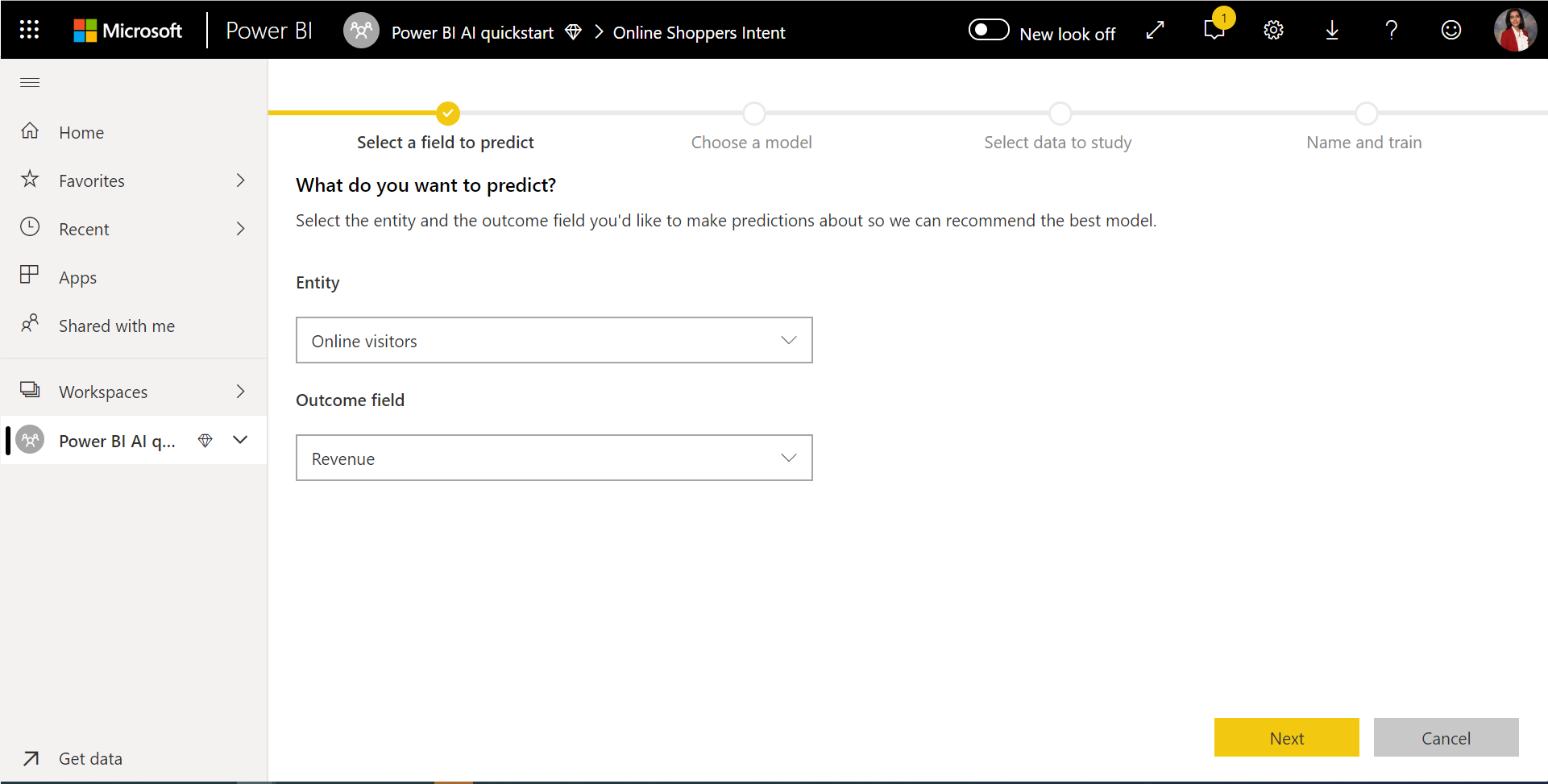
1. Vyberte tabuľku s historickými údajmi a vyberte stĺpec výsledku, pre ktorý chcete vytvoriť predpoveď.
Stĺpec výsledku identifikuje atribút označenia na trénovaie modelu strojového učenia, ako je to znázornené na nasledujúcom obrázku.
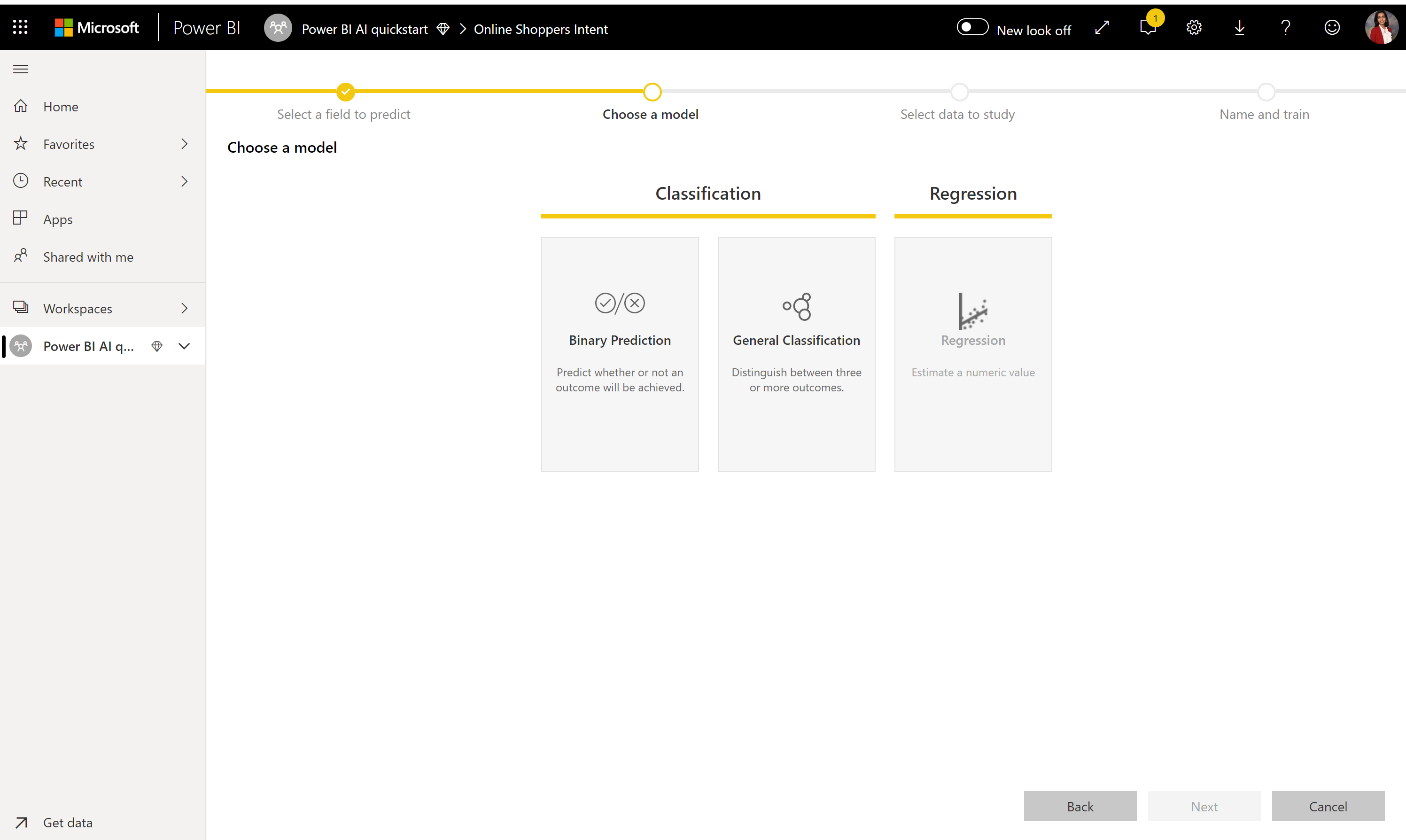
2. Vyberte typ modelu
Keď zadáte stĺpec výsledku, automatizované strojové učenie zanalyzuje údaje označenia, aby mohlo odporučiť najpravdepodobnejší typ modelu strojového učenia, ktorý možno natrénovať. Kliknutím na položku Vybrať model môžete vybrať iný typ modelu, ako je to znázornené na nasledujúcom obrázku.
Poznámka
Vybraté údaje nemusia podporovať niektoré typy modelov, a preto budú zakázané. V predchádzajúcom príklade je regresia zakázaná, pretože ako stĺpec výsledku je vybratý textový stĺpec.
3. Vyberte vstupy, ktoré má model používať ako prediktívne signály.
Automatizované strojové učenie analyzuje vzorku vybratej tabuľky, vďaka čomu môže navrhovať vstupy, ktoré možno použiť na trénovaie modelu strojového učenia. Vedľa stĺpcov, ktoré nie sú vybraté, sa poskytujú vysvetlenia. Ak má konkrétny stĺpec príliš veľa odlišných hodnôt, iba jednu hodnotu alebo nízku alebo vysokú koreláciu s výstupným stĺpcom, neodporúča sa.
Vstupy, ktoré závisia od stĺpca výsledku (alebo od stĺpca označenia), by sa nemali používať na trénovaie modelu strojového učenia, pretože ovplyvnia jeho výkon. Tieto stĺpce sú označené ako "podozrivo vysoká korelácia s výstupným stĺpcom". Použitie týchto stĺpcov v údajoch na trénovanie spôsobí použitie nesprávnych označení. Model bude totiž dobre fungovať pri overovaní alebo testovaní údajov, ale tento výkon nebude zodpovedať výkonu pri použití modelu na tvorbu skóre. Únik označení by mohol predstavovať možný problém v modeloch automatizovaného strojového učenia, keď je výkon trénovaného modelu príliš dobrý na to, aby bol pravdivý.
Odporúčanie tejto funkcie je založené na vzorke údajov, preto by ste mali skontrolovať použité vstupy. Výbery môžete zmeniť tak, aby zahŕňali iba stĺpce, ktoré má model preskúmať. Môžete vybrať aj všetky stĺpce začiarknutím políčka vedľa názvu tabuľky.
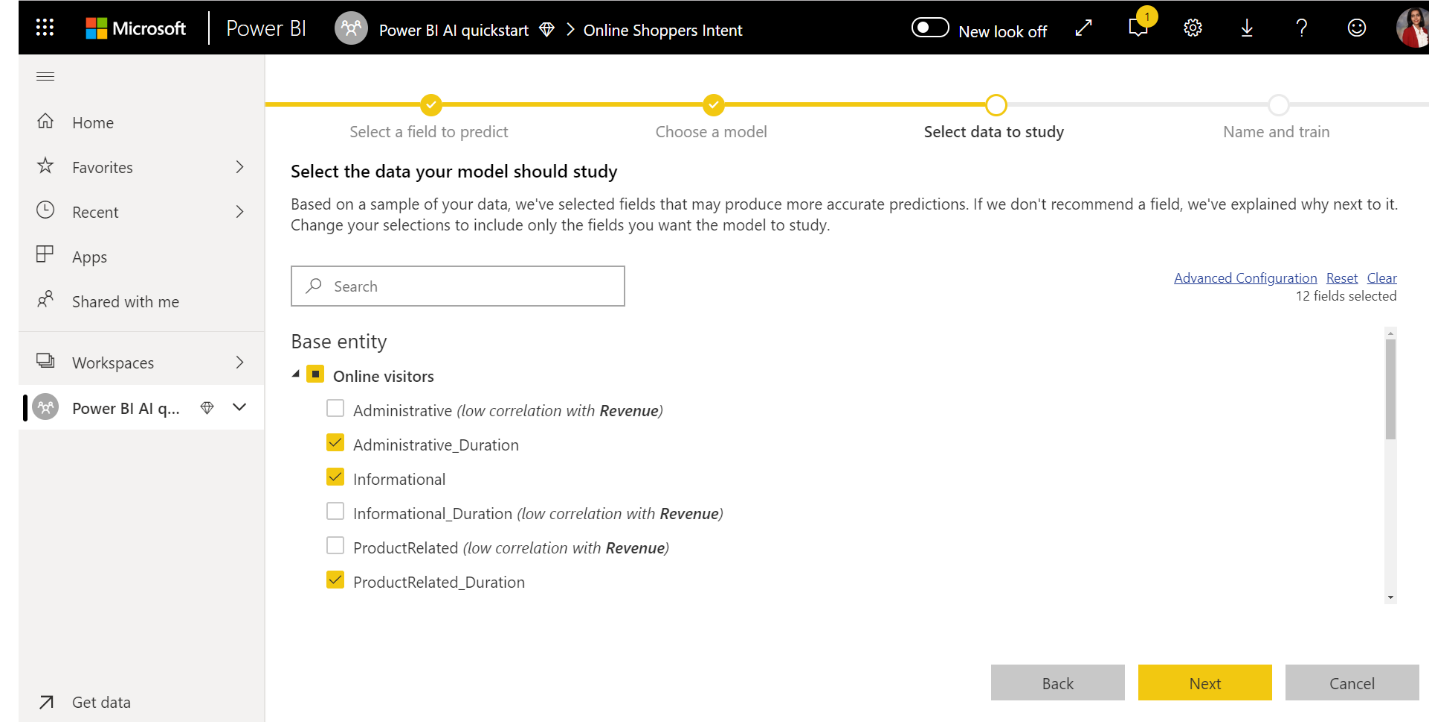
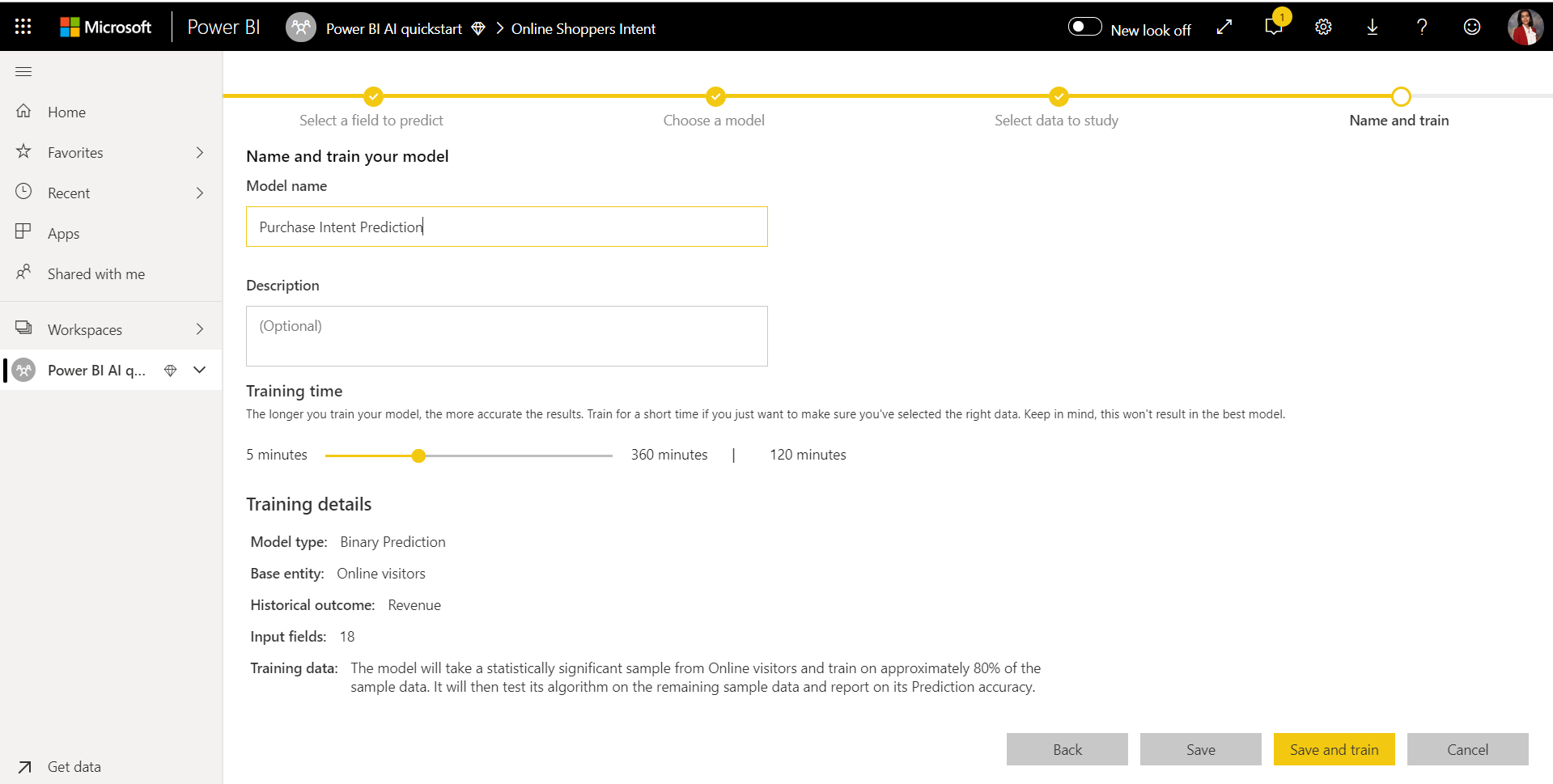
4. Pomenujte svoj model a uložte konfiguráciu.
V poslednom kroku môžete model pomenovať, vybrať položku Uložiť a vybrať, ktorá začne trénovať model strojového učenia. Môžete sa rozhodnúť skrátiť čas trénovania, aby ste mohli zobraziť rýchle výsledky, alebo zvýšiť čas strávený trénovaním, aby ste získali najlepší model.
Trénovaie modelu strojového učenia
Trénovanie modelov automatizovaného strojového učenia je súčasťou obnovenia toku údajov. Automatizované strojové učenia najskôr pripraví vaše údaje na trénovaie. Potom rozdelí vami poskytnutie historických údajov na trénovacie a testovacie sémantické modely. Testovací sémantický model predstavuje množinu podržanie, ktorá sa používa na overenie výkonu modelu po trénovaní. Tieto množiny môžu byť v toku údajov realizované ako tabuľky Trénovacie a testovacie . Automatizované strojové učenia používa na overenie modelu krížové overenie.
Potom sa analyzuje každý vstupný stĺpec a použije sa prisudzovanie, ktoré nahradí všetky chýbajúce hodnoty náhradnými hodnotami. Automatizované strojové učenia používa niekoľko stratégií prisudzovania. V prípade atribútov vstupov, ktoré sa považujú za číselné funkcie, sa na prisudzovanie použije priemer hodnôt stĺpcov. V prípade atribútov vstupov, ktoré sa považujú za funkcie kategórií, použije automatizované strojové učenia na prisudzovanie režim hodnôt stĺpcov. Architektúra automatizovaného strojového učenia vypočíta priemer a režim hodnôt používaných na prisudzovanie v sémantickom modeli trénovania podradeného strojového učenia.
Na vaše údaje sa potom použije podľa potreby vzorkovanie a normalizácia. V prípade klasifikovacích modelov automatizované strojové učenia spustí vstupné údaje prostredníctvom stratifikovaného vzorkovania a vyváži triedy, aby sa zabezpečilo, že počty riadkov sú rovnaké pre všetkých.
Automatizované strojové spracovanie uplatňuje niekoľko transformácií na každý vybratý vstupný stĺpec na základe jeho typu údajov a štatistických vlastností. Automatizované strojové učenie používa tieto transformácie na extrakciu funkcií, ktoré sa použijú pri trénovaní modelu strojového učenia.
Proces trénovania modelov automatizovaného strojového učenia pozostáva až z 50 iterácií s rôznymi algoritmami modelovania a nastaveniami hyperparametrov, vďaka čomu nájdete model s najlepším výkonom. Ak automatizované strojové strojové učenia spozoruje, že nedochádza k zlepšeniu výkonu, môže sa trénovanie skončiť skôr s menším počtom iterácií. Automatizované strojové učenia zhodnotí výkon jednotlivých modelov overením pomocou testovacieho sémantického modelu podržanie. Automatizované strojové učenia v rámci tohto kroku vytvorí niekoľko kanálov na trénovanie a overovanie týchto iterácií. Proces hodnotenia výkonu modelov môže v sprievodcovi trvať od niekoľkých minút až po niekoľko hodín– až po čas tréningu nakonfigurovaný v sprievodcovi. Tento čas závisí od veľkosti sémantického modelu a dostupných zdrojov kapacity.
V niektorých prípadoch môže konečný vygenerovaný model využiť súhrnné učenie, v rámci ktorého sa na dosiahnutie lepšieho výkonu pri predpovedaní používajú viaceré modely.
Zrozumiteľnosť modelu automatizovaného strojového učenia
Automatizované strojové učenia po natrénovaní modelu zanalyzuje vzťah medzi vstupnými funkciami a výstupom modelu. Zhodnotí veľkosť zmeny vo výstupe modelu pre test sémantického modelu podržanie každej vstupnej funkcie. Tento vzťah je známy ako dôležitosť funkcie. Táto analýza sa uskutoční v rámci obnovenia po dokončení tréningu. Obnovenie preto môže trvať dlhšie ako čas tréningu nakonfigurovaný v sprievodcovi.
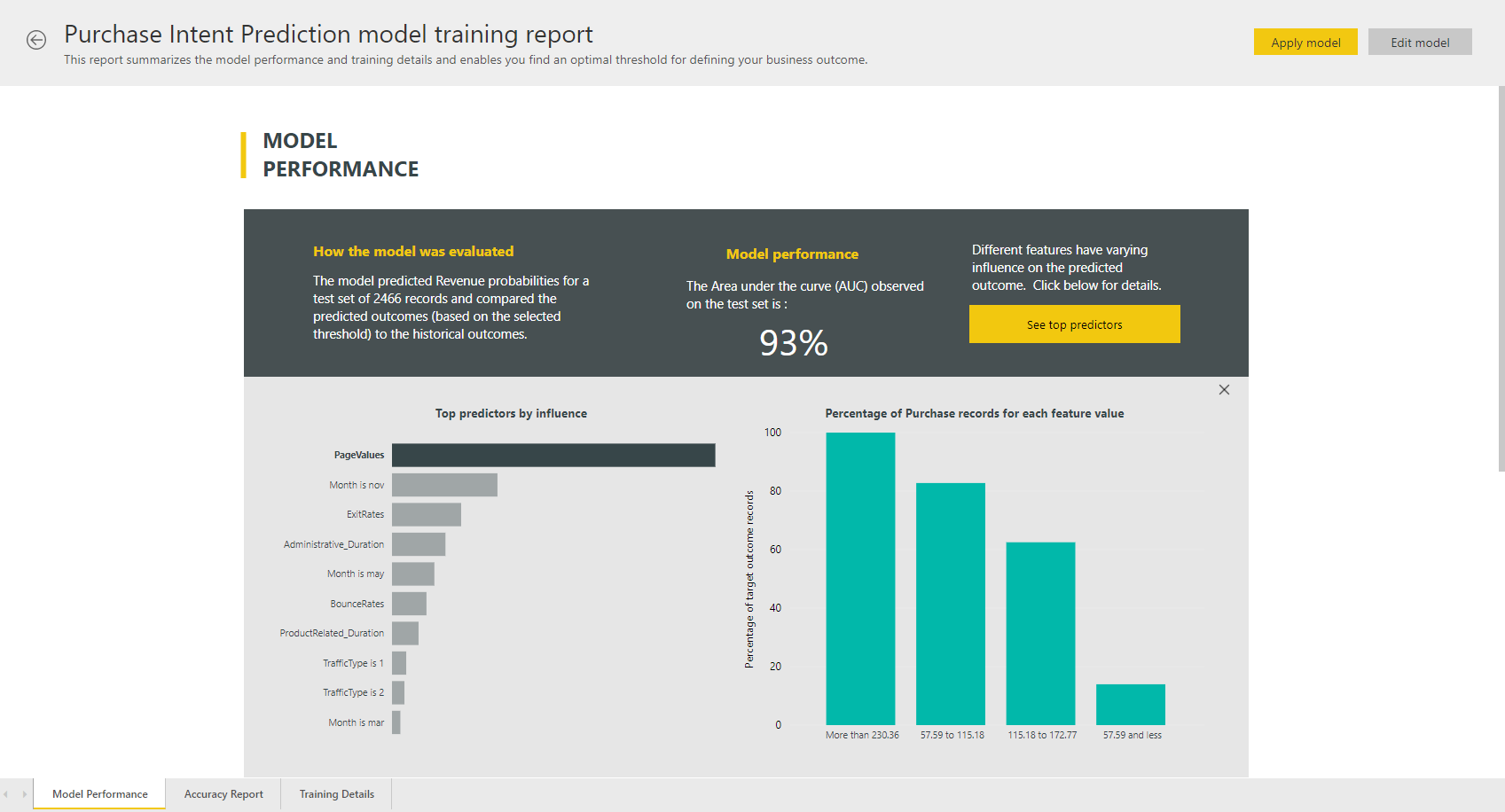
Zostava modelu automatizovaného strojového učenia
Automatizované strojové učenia vygeneruje zostavu služby Power BI, ktorá zosumarizuje výkon modelu počas overovania spolu s globálnou dôležitosťou funkcie. K tejto zostave je možné získať prístup na karte strojové učenie Modely po úspešnom obnovení toku údajov. Zostava sumarizuje výsledky z použitia modelu strojového učenia na testovacie údaje podržanie a porovnáva predpovede so známymi výsledkami.
Zostavu modelu si môžete prezrieť, aby ste pochopili jeho výkon. Môžete tiež overiť, či sú kľúčové vplyvy modelu v súlade s obchodnými prehľadmi o známych výsledkoch.
Grafy a mierky použité na popísanie výkonu modelu v zostave závisia od typu modelu. Tieto výkonnostné grafy a mierky sú popísané v nasledujúcich sekciách.
Iné strany zostavy môžu štatistické merania modelu popisovať z pohľadu dátovej vedy. Napríklad zostava binárnych predpovedí obsahuje graf zisku a krivku ROC modelu.
V zostavách sa tiež nachádza strana s podrobnosťami trénovania, ktorá obsahuje popis spôsobu, akým bol model natrénovaný, a graf popisujúci výkon modelu pri každom spustení iterácií.
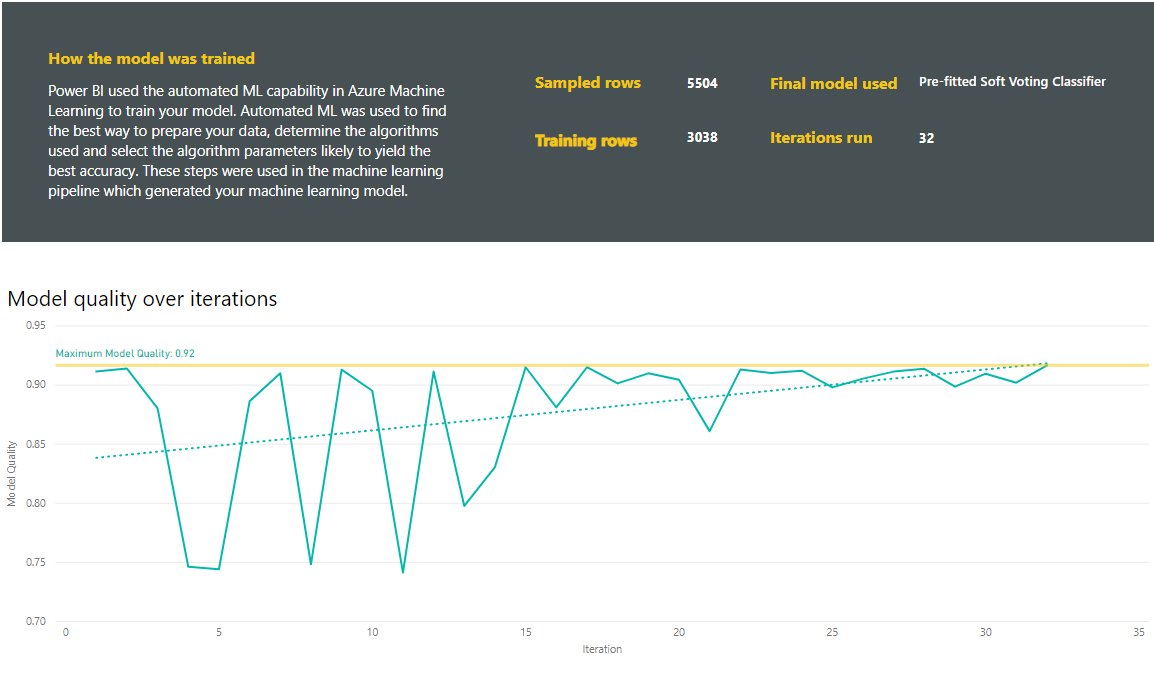
Ďalšia sekcia tejto stránky popisuje zistený typ vstupného stĺpca a metódu prisudzovania, ktorá sa používa na vyplnenie chýbajúcich hodnôt. Obsahuje aj parametre použité v konečnom modeli.
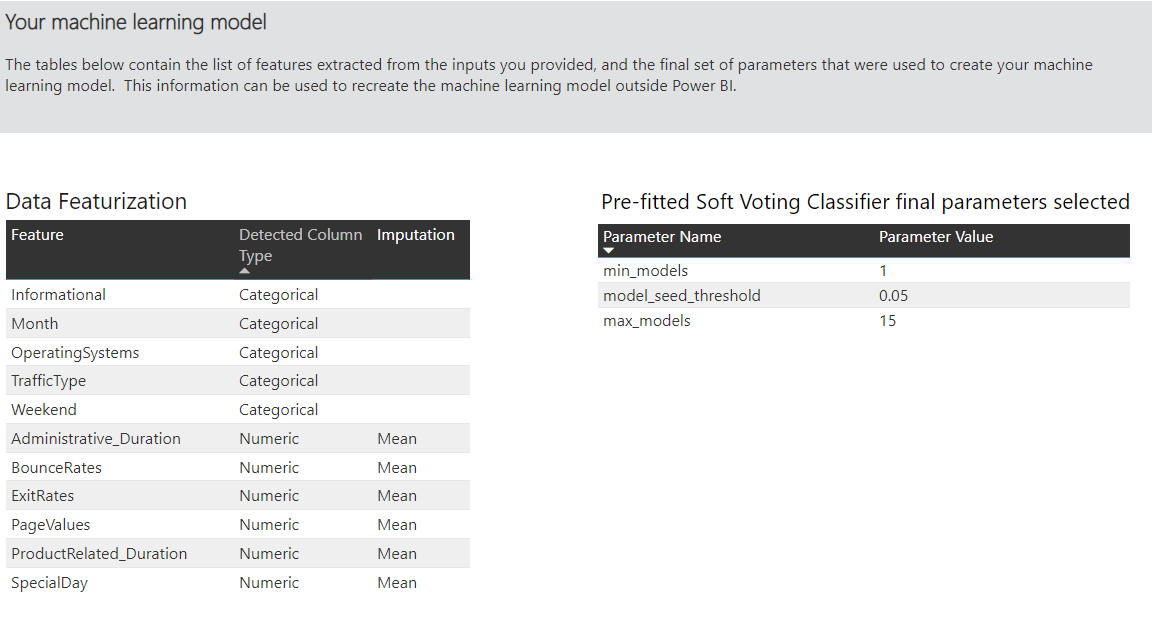
Ak vytvorený model využíva súhrnné učenie, stránka s podrobnosťami trénovania obsahuje aj graf s váhou jednotlivých zložkových modelov v súhrne a jeho parametrami.

Použitie modelu automatizovaného strojového učenia
Ak ste spokojní s výkonom vytvoreného modelu strojového učenia, môžete ho použiť na nové alebo aktualizované údaje po obnovení toku údajov. V zostave modelu vyberte tlačidlo Použiť v pravom hornom rohu alebo tlačidlo Použiť model strojového učenia v časti akcie na karte strojové učenie Modely.
Ak chcete použiť model strojového učenia, musíte zadať názov tabuľky, na ktorú sa má použiť, a predponu stĺpcov, ktoré sa majú pridať do tejto tabuľky, aby výstup modelu. Predvolenou predponou názvov stĺpcov je názov modelu. Funkcia Použiť môže obsahovať viac parametrov špecifických pre daný typ modelu.
Použitím modelu strojového učenia vytvoríte dve nové tabuľky toku údajov, ktoré budú obsahovať predpovede a individuálne vysvetlenia každého riadka, ktorý je skóre vo výstupnej tabuľke. Ak napríklad model PurchaseIntent použijete na tabuľku OnlineShoppers, výstup vygeneruje tabuľky OnlineShoppers enriched PurchaseIntent (OnlineShoppers – obohatené o príponu PurchaseIntent) a OnlineShoppers enriched PurchaseIntent explanations (OnlineShoppers – obohatené o vysvetlenia PurchaseIntent). Pre každý riadok v obohatenej tabuľke sa vysvetlenia rozdelia v tabuľke obohatenej o vysvetlenia do viacerých riadkov na základe vstupnej funkcie. ExplanationIndex pomáha priraďovať riadky z tabuľky obohatenej o vysvetlenia k riadku v obohatenej tabuľke.
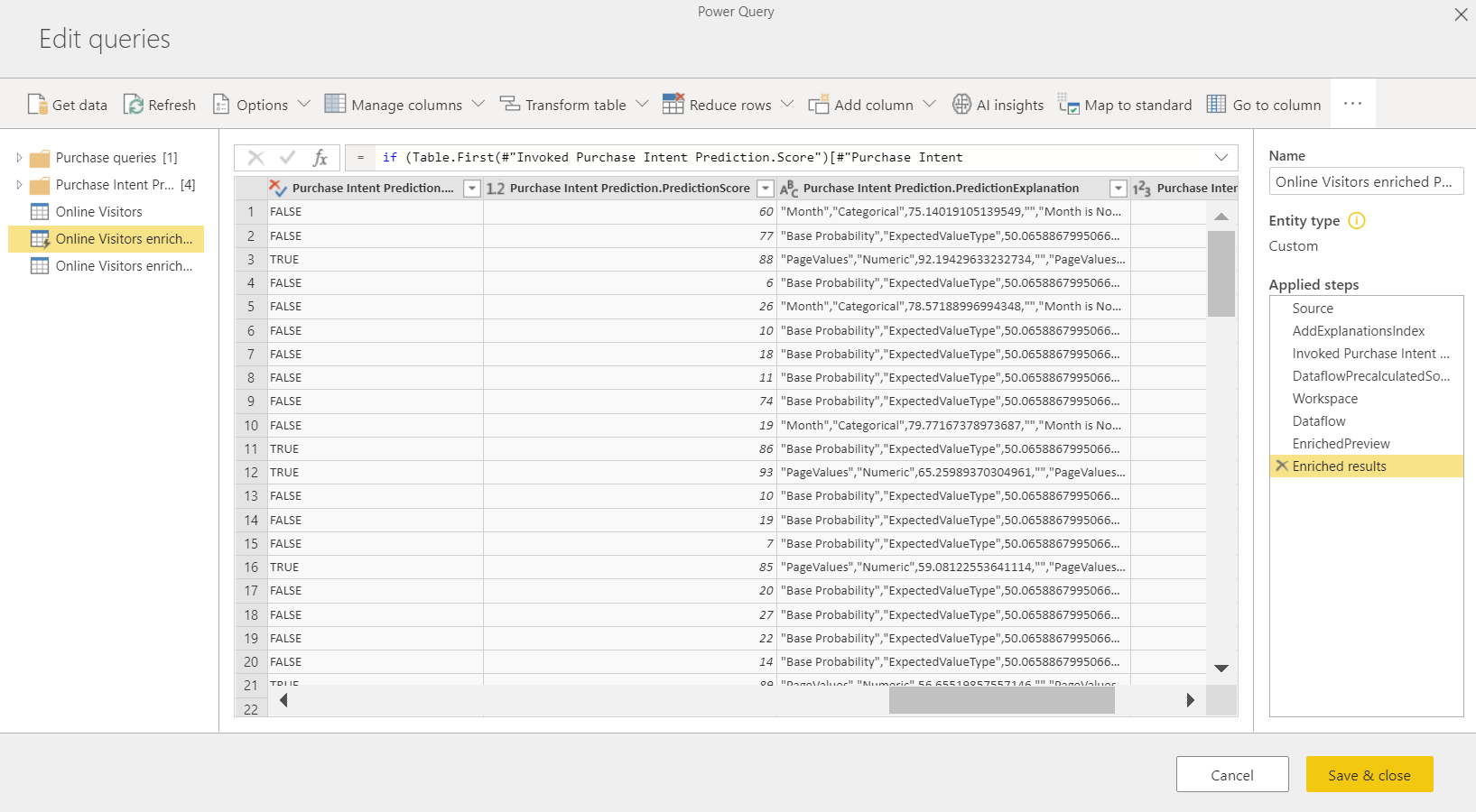
Ľubovoľný model automatizovaného strojového učenia Power BI môžete použiť aj na tabuľky v ľubovoľnom toku údajov v tom istom pracovnom priestore pomocou Prehľady UI v prehliadači funkcie PQO. Týmto spôsobom môžete použiť modely vytvorené inými osobami v tom istom pracovnom priestore bez toho, aby ste nevyhnutne boli vlastníkom toku údajov v modeli. Power Query zistí všetky modely strojového učenia Power BI v pracovnom priestore a zobrazí ich ako dynamické funkcie Power Query. Tieto funkcie môžete vyvolať tak, že k nim získate prístup prostredníctvom pása s nástrojmi v Editor Power Query alebo priamym vyvolaním funkcie strojového učenia. Táto funkcia je v súčasnosti podporovaná len pre toky údajov služby Power BI a pre Power Query Online v službe služba Power BI. Tento proces sa líši od použitia modelov strojového učenia v toku údajov pomocou sprievodcu automatizovaného strojového učenia. Neexistuje žiadna tabuľka vysvetlení vytvorená pomocou tejto metódy. Ak nie ste vlastníkom toku údajov, nemôžete získať prístup k zostave trénovania modelu ani model znova natrénovať. Okrem toho, ak sa zdrojový model upraví pridaním alebo odstránením vstupných stĺpcov alebo odstránením toku údajov modelu alebo zdroja, tento závislý tok údajov sa preruší.

Keď model použijete, automatizované strojové meno vaše predpovede vždy po obnovení toku údajov aktualizuje.
Ak chcete používať prehľady a predpovede z modelu strojového učenia v zostave Power BI, môžete sa pripojiť k výstupnej tabuľke z aplikácie Power BI Desktop pomocou konektora tokov údajov.
Modely binárnych predpovedí
Modely binárnych predpovedí, oficiálne známe ako modely binárnej klasifikácie, sa používajú na rozdelenie sémantického modelu do dvoch skupín. Používajú sa na predpovedanie udalostí, ktoré môžu mať binárny výsledok. Napríklad na prevod predajnej príležitosti, či zákazník odíde, či bude faktúra zaplatená včas, či je transakcia podvodná a tak ďalej.
Výstupom modelu binárnych predpovedí je skóre pravdepodobnosti, ktoré stanovuje pravdepodobnosť, že sa dosiahne cieľový výsledok.
Trénovať model binárnych predpovedí
Pre-predpoklady:
- Každá trieda výsledkov vyžaduje minimálne 20 riadkov historických údajov.
Vytváranie modelu binárnych predpovedí má rovnaké kroky ako tvorba ostatných modelov automatizovaného strojového učenia, ktorá je popísaná v predchádzajúcej časti Konfigurácia vstupov modelu strojového učenia. Jediný rozdiel je v kroku Vybrať model , kde môžete vybrať hodnotu cieľového výsledku, ktorá vás najviac zaujíma. Môžete tiež zadať popisné označenia výsledkov, ktoré sa majú použiť v automaticky generovanej zostave sumarizuacej výsledky overenia modelu.
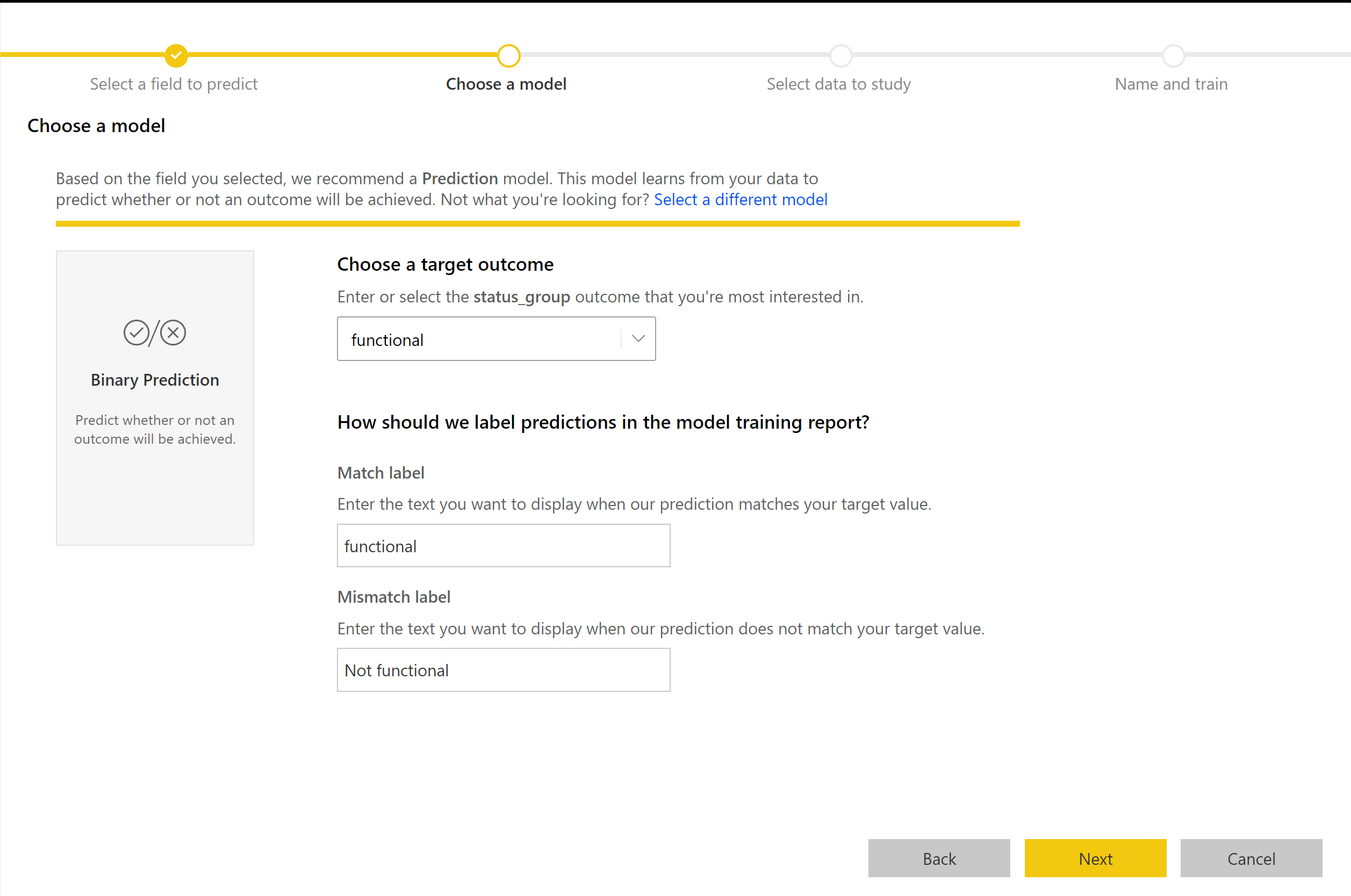
Zostava modelu binárnych predpovedí
Výstupom modelu binárnych predpovedí je pravdepodobnosť, že riadok dosiahne cieľový výsledok. Zostava obsahuje rýchly filter pre prahovú hodnotu pravdepodobnosti, ktorý ovplyvňuje spôsob, akým sa bude interpretovať skóre väčšie a menšie ako prahová hodnota pravdepodobnosti.
Zostava definuje výkon modelu ako skutočne pozitívny, falošne pozitívny, skutočne negatívny a falošne negatívny. Skutočne pozitívne a skutočne negatívne výsledky sú správne predpovedané výsledky dvoch tried v údajoch výsledkov. Falošne pozitívne sú riadky, pri ktorých sa predpovedalo, že budú mať cieľový výsledok, ale v skutočnosti nie. Falošne negatívne sú zase riadky, ktoré mali cieľové výsledky, ale predpovedané neboli.
Mierky, ako napríklad presnosť a úplnosť, popisujú vplyv prahovej hodnoty pravdepodobnosti na predpokladané výsledky. Rýchly filter prahovej hodnoty pravdepodobnosti môžete použiť na výber prahovej hodnoty, ktorá dosiahne vyvážený kompromis medzi presnosťou a úplnosťou.

Zostava obsahuje aj nástroj na analýzu nákladov a prínosov, ktorý pomáha identifikovať podmnožinu obyvateľstva, ktorá by mala byť zameraná na to, aby prinášala najvyšší zisk. Vzhľadom na odhadované jednotkové náklady na zacielenie a jednotkové výhody z dosiahnutia cieľového výsledku sa analýza nákladov a prínosov pokúša maximalizovať zisk. Tento nástroj môžete použiť na využitie prahu pravdepodobnosti na základe maximálneho bodu v grafe, aby ste dosiahli maximálny zisk. Graf môžete použiť aj na výpočet zisku alebo nákladov pre prah pravdepodobnosti, ktorý ste si vybrali.
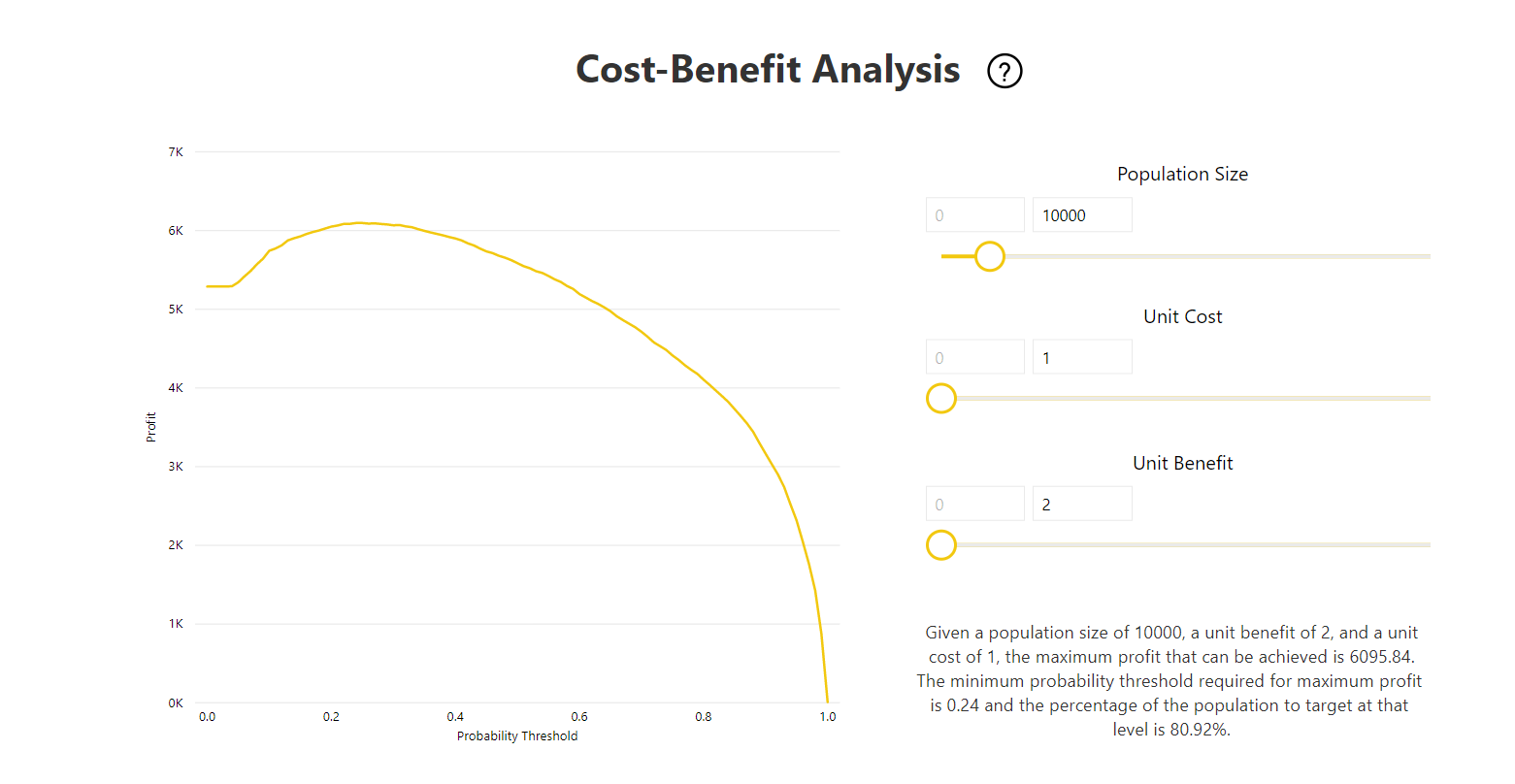
Stránka zostavy presnosti zostavy modelu obsahuje graf kumulatívnych ziskov a krivku ROC modelu. Tieto údaje poskytujú štatistické merania výkonu modelu. Zostavy obsahujú popisy zobrazených grafov.
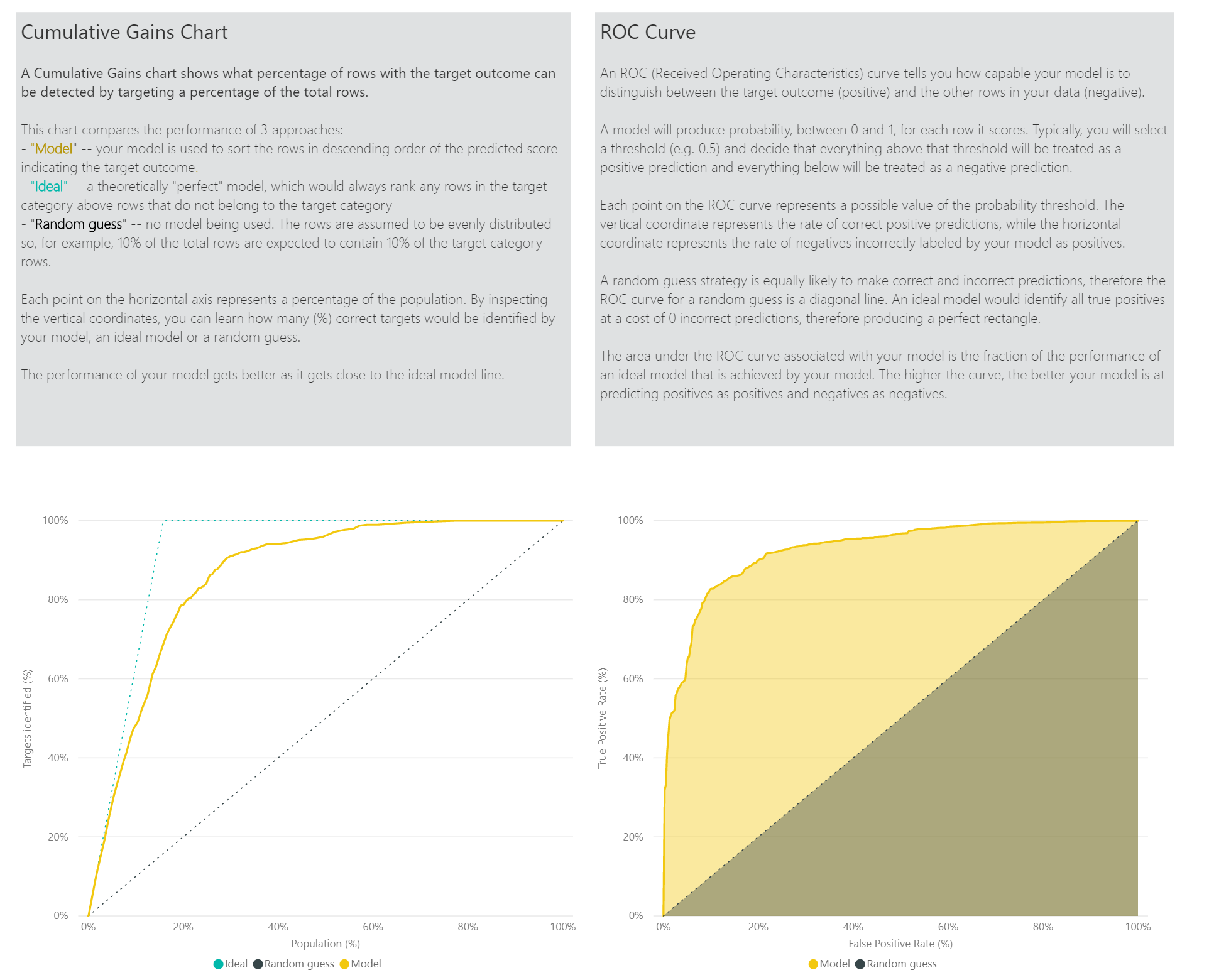
Použitie modelu binárnych predpovedí
Ak chcete použiť model binárnych predpovedí, musíte zadať tabuľku s údajmi, na ktoré chcete predpovede z modelu strojového učenia použiť. Medzi ďalšie parametre patrí predpona názvu výstupného stĺpca a prahová hodnota pravdepodobnosti na klasifikáciu predpokladaného výsledku.
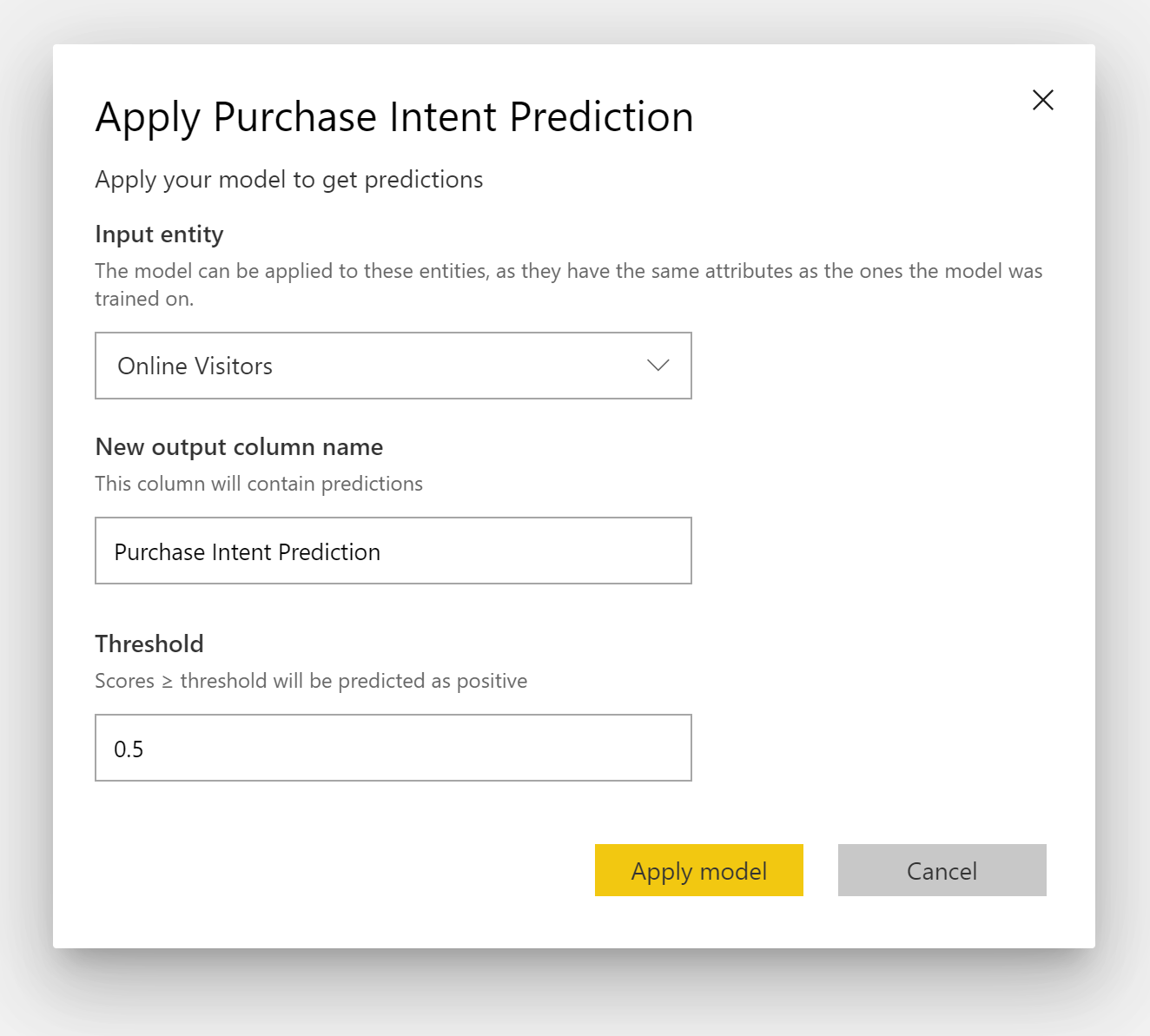
Po použití modelu binárnych predpovedí sa do obohatenej výstupnej tabuľky pridajú štyri výstupné stĺpce: Outcome, PredictionScore, PredictionExplanation a ExplanationIndex. Názvy stĺpcov v tabuľke majú pri použití modelu zadanú predponu.
PredictionScore predstavuje percentuálnu pravdepodobnosť toho, že sa dosiahne cieľový výsledok.
Stĺpec Outcome obsahuje označenie predpokladaného výsledku. Pri záznamoch s pravdepodobnosťami, ktoré presahujú prahovú hodnotu, je pravdepodobné, že cieľový výsledok dosiahnu. Pri záznamoch, ktoré sú menšie ako prahová hodnota, je nepravdepodobné, že výsledok dosiahnu. Sú označené ako False.
Stĺpec PredictionExplanation obsahuje vysvetlenie predpovede s konkrétnym vplyvom, ktorý vstupné funkcie mali na stĺpec PredictionScore.
Modely klasifikácie
Modely klasifikácie sa používajú na klasifikáciu sémantického modelu do viacerých skupín alebo tried. Používajú sa na predpovedanie udalostí, ktoré môžu mať jeden z viacerých možných výsledkov. Napríklad na to, či bude mať zákazník pravdepodobne vysokú, strednú alebo nízku hodnotu životnosti. Môžu tiež predpovedať, či je riziko predvoleného nastavenia vysoké, stredné, nízke a tak ďalej.
Výstupom modelu klasifikácie je skóre pravdepodobnosti, ktoré stanovuje pravdepodobnosť, že riadok splní kritériá danej triedy.
Trénovanie modelu klasifikácie
Vstupná tabuľka obsahujúca vaše údaje na trénovanie modelu klasifikácie musí ako stĺpec výsledkov obsahovať reťazec alebo stĺpec s celým číslom, ktorý identifikuje predchádzajúce známe výsledky.
Pre-predpoklady:
- Každá trieda výsledkov vyžaduje minimálne 20 riadkov historických údajov.
Vytváranie modelu klasifikácie má rovnaké kroky ako tvorba ostatných modelov automatizovaného strojového učenia, ktorá je popísaná v predchádzajúcej časti Konfigurácia vstupov modelu strojového učenia.
Zostava modelu klasifikácie
Power BI vytvorí zostavu modelu klasifikácie použitím modelu strojového učenia na testovacie údaje podržte. Potom porovná predpokladanú triedu pre riadok so skutočnou známou triedou.
Zostava modelu obsahuje graf, ktorý obsahuje rozpis správne a nesprávne klasifikovaných riadkov každej známej triedy.
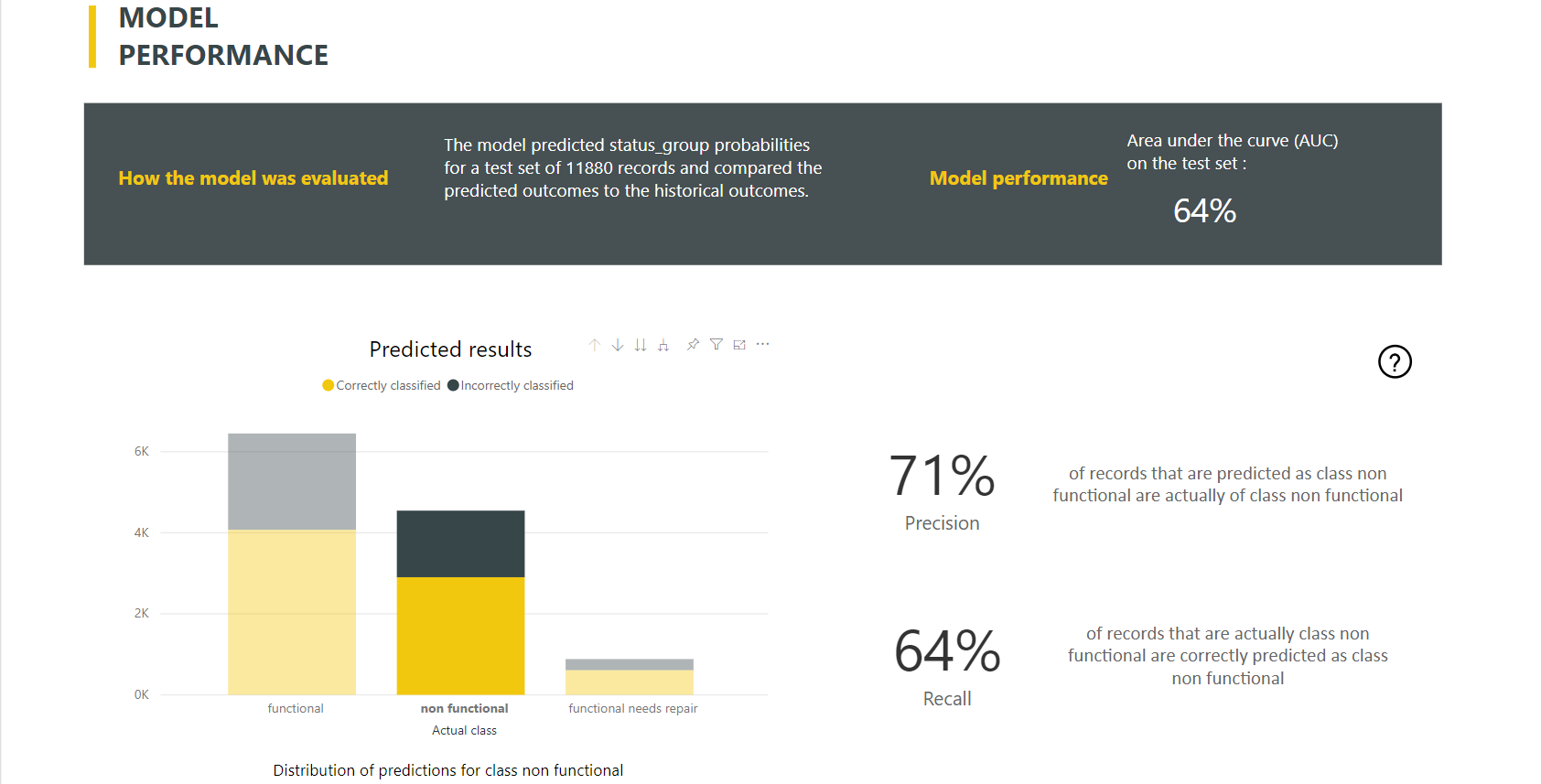
Ďalšia akcia prechodu na detaily špecifická pre jednotlivé triedy umožňuje analyzovať spôsob, akým sa predpovede pre známu triedu distribuujú. Táto analýza ukazuje ďalšie triedy, pri ktorých je pravdepodobné, že sa riadky tejto známej triedy klasifikujú nesprávne.
Vysvetlenie modelu v zostave zahŕňa aj top prediktory pre každú triedu.
Zostava modelu klasifikácie obsahuje aj stránku s podrobnosťami trénovania, ktorá sa podobá na stránky iných typov modelov, ako je to popísané vyššie v zostave modelu automatizovaného strojového učenia.
Použitie modelu klasifikácie
Ak chcete použiť model klasifikácie strojového učenia, musíte k tabuľke pridať vstupné údaje a predponu názvu výstupného stĺpca.
Po použití modelu klasifikácie sa do obohatenej výstupnej tabuľky pridá päť výstupných stĺpcov. ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities a ExplanationIndex. Názvy stĺpcov v tabuľke majú pri použití modelu zadanú predponu.
Stĺpec ClassProbabilities obsahuje zoznam skóre pravdepodobnosti pre riadok pre všetky možné triedy.
Tabuľka ClassificationScore stanovuje percentuálnu pravdepodobnosť toho, že riadok splní kritériá danej triedy.
Stĺpec ClassificationResult obsahuje triedu, ktorá má najväčšiu šancu byť predpovedaná pre riadok.
Stĺpec ClassificationExplanation obsahuje vysvetlenie s konkrétnym vplyvom, ktorý vstupné funkcie mali na stĺpec ClassificationScore.
Regresné modely
Regresné modely sa používajú na predpovedanie číselnej hodnoty a možno ich použiť v scenároch, ako je napríklad určovanie:
- Pravdepodobné výnosy z predajnej zmluvy.
- Hodnota životnosti konta.
- Suma faktúry v pohľadávky, ktorá bude pravdepodobne vyplatená
- Dátum zaplatenia faktúry a podobne.
Výstupom regresného modelu je predpovedaná hodnota.
Trénovanie regresného modelu
Vstupná tabuľka obsahujúca údaje na trénovanie regresného modelu musí ako stĺpec výsledku obsahovať číselný stĺpec, ktorý identifikuje známe hodnoty výsledkov.
Pre-predpoklady:
- Regresný model vyžaduje minimálne 100 riadkov historických údajov.
Vytváranie regresného modelu má rovnaké kroky ako tvorba ostatných modelov automatizovaného strojového učenia, ktorá je popísaná v predchádzajúcej časti Konfigurácia vstupov modelu strojového učenia.
Zostava regresných modelov
Podobne ako ostatné zostavy modelov automatizovaného strojového učenia, tak aj regresná zostava je založená na výsledkoch z používania modelu na testovacích údajoch podržanie.
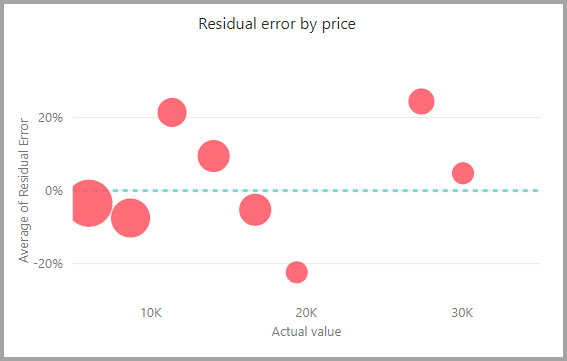
Zostava modelu obsahuje graf, ktorý porovnáva predpokladané hodnoty so skutočnými hodnotami. V tomto grafe vzdialenosť od diagonálnej čiary znázorňuje chybu v predpovedi.
V grafe zostatkovej chybovosti je zobrazené rozdelenie percentuálnej hodnoty priemernej chyby pre rôzne hodnoty v testovacom sémantickom modeli podržanie. Vodorovná os predstavuje strednú hodnotu skutočnej hodnoty skupiny. Veľkosť bubliny zobrazuje frekvenciu alebo počet hodnôt v danom rozsahu. Zvislá os predstavuje priemernú zostatkovú chybu.
Zostava regresného modelu obsahuje aj stránku s podrobnosťami trénovania, ako zostavy pre iné typy modelov, ako sa uvádza v predchádzajúcej časti Zostava modelu automatizovaného strojového učenia.
Použitie regresného modelu
Ak chcete použiť regresný model strojového učenia, musíte tabuľku zadať so vstupnými údajmi a predponou názvu výstupného stĺpca.
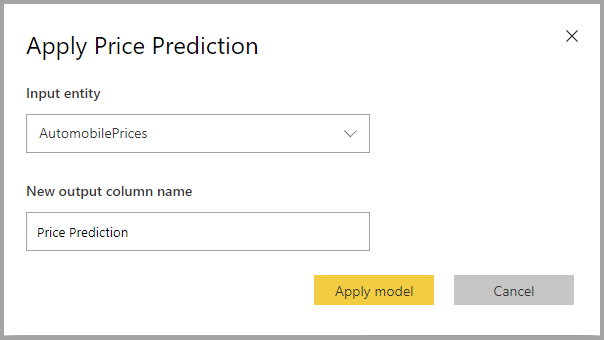
Po použití regresného modelu sa do obohatenej výstupnej tabuľky pridajú tri výstupné stĺpce. RegressionResult, RegressionExplanation a ExplanationIndex. Názvy stĺpcov v tabuľke majú pri použití modelu zadanú predponu.
Stĺpec RegressionResult obsahuje predpokladanú hodnotu riadka vychádzajúcu zo vstupných stĺpcov. Stĺpec RegressionExplanation obsahuje vysvetlenie s konkrétnym vplyvom, ktorý vstupné funkcie mali na stĺpec RegressionResult.
Integrácia služby Azure strojové učenie v službe Power BI
Mnohé organizácie používajú modely strojového učenia na zlepšenie prehľadov a predpovedí týkajúcich sa ich podnikania. Ak chcete získať tieto prehľady, môžete používať strojové učenie so zostavami, tabuľami a inými analýzami. Možnosť vizualizácie a vyvolania prehľadov z týchto modelov môže pomôcť so šírením týchto prehľadov podnikových používateľov, ktorí ich potrebujú najviac. Služba Power BI teraz umožňuje pomocou jednoduchých gest typu "bod-a-kliknutie" zahrnúť prehľady z modelov hosťovaných v službe Azure strojové učenie.
Ak chcete využiť túto funkciu, odborník v používaní údajov môže analytikovi služby BI poskytnúť prístup k modelu služby Azure strojové učenie prostredníctvom portálu Azure. Potom na začiatku každej relácie služba Power Query zistí všetky modely služby Azure strojové učenie, ku ktorým má používateľ prístup, a zobrazí ich ako dynamické funkcie služby Power Query. Používateľ môže vyvolať dané funkcie tak, že k nim pristupuje na páse s nástrojmi v Editor Power Query alebo priamym vyvolaním funkcie strojového učenia. Pri vyvolávaní modelu služby Azure strojové učenie služba Power BI automaticky dávkuje požiadavky na prístup pre množinu riadkov na dosiahnutie lepšieho výkonu.
Táto funkcia je v súčasnosti podporovaná len pre toky údajov služby Power BI a pre online službu Power Query v služba Power BI.
Ďalšie informácie o tokoch údajov nájdete v téme Úvodné informácie o tokoch údajov a samoobslužná príprava údajov.
Ďalšie informácie o strojové učenie Azure nájdete v téme:
- Prehľad: Čo je služba Azure strojové učenie?
- Príručky pre rýchly začiatok a kurzy pre službu Azure strojové učenie: Dokumentácia k azure strojové učenie
Poskytnutie prístupu k modelu služby Azure strojové učenie používateľovi služby Power BI
Na prístup k modelu služby Azure strojové učenie zo služby Power BI musí mať používateľ prístup na čítanie k predplatnému služby Azure a pracovnému priestoru strojové učenie.
Kroky v tomto článku popisujú poskytnutie prístupu používateľovi služby Power BI k modelu hosťovanému v službe Azure strojové učenie na prístup k tomuto modelu ako k funkcii Power Query. Ďalšie informácie nájdete v časti Priradenie rolí Azure pomocou portálu Azure.
Prihláste sa do portálu Azurel.
Prejdite na stránku Predplatné . Stránku Predplatné môžete nájsť pomocou zoznamu Všetky služby na navigačnej table portálu Azure.

Vyberte predplatné.

Vyberte položku Riadenie prístupu (IAM) a potom vyberte tlačidlo Pridať .

Ako rolu vyberte možnosť Čitateľ . Potom vyberte používateľa služby Power BI, ktorému chcete udeliť prístup k modelu služby Azure strojové učenie.

Vyberte položku Uložiť.
Zopakujte kroky tri až šesť a udeľte používateľovi prístup Čitateľa ku konkrétnemu pracovnému priestoru strojového učenia hosťujúcemu model.




Zisťovanie schémy modelov strojového učenia
Vedci pracujúci s údajmi používajú na vývoj, a dokonca nasadenie modelov strojového učenia pre strojové učenie predovšetkým jazyk Python. Odborník na údaje musí výslovne vygenerovať súbor schémy pomocou jazyka Python.
Tento súbor schémy musí byť súčasťou nasadenej webovej služby pre modely strojového učenia. Ak chcete automaticky vygenerovať schému pre webovú službu, musíte zadať ukážku vstupu/výstupu do vstupného skriptu nasadzovaného modelu. Ďalšie informácie nájdete v téme Nasadenie a skóre modelu strojového učenia pomocou online koncového bodu. Prepojenie obsahuje príklad vstupného skriptu s príkazmi na generovanie schémy.
Konkrétne funkcie @input_schema a @output_schema vo vstupnom skripte odkazujú na vzorové formáty vstupu a výstupu v premenných input_sample a output_sample. Tieto funkcie používajú tieto ukážky na generovanie špecifikácie OpenAPI (Swagger) pre webovú službu počas nasadenia.
Tieto pokyny na generovanie schémy aktualizáciou vstupného skriptu je potrebné použiť aj na modely vytvorené pomocou pokusov s automatizovaným strojovým učením s súpravou Azure strojové učenie SDK.
Poznámka
Modely vytvorené pomocou grafického používateľského rozhrania služby Azure strojové učenie v súčasnosti nepodporujú generovanie schémy, v na nasledujúcich vydaniach však už budú.
Vyvolanie modelu strojové učenie Azure v službe Power BI
Akýkoľvek model služby Azure strojové učenie, ku ktorému ste získali prístup, môžete vyvolať priamo z Editor Power Query vo svojom toku údajov. Ak chcete získať prístup k modelom Azure strojové učenie, vyberte tlačidlo Upraviť tabuľku pre tabuľku, ktorú chcete obohatiť prehľadmi zo svojho modelu strojové učenie Azure, ako je to znázornené na nasledujúcom obrázku.

Výberom tlačidla Upraviť tabuľku sa otvorí Editor Power Query pre tabuľky vo vašom toku údajov.

Na páse s nástrojmi vyberte tlačidlo Prehľady UI a potom v ponuke navigačnej tably vyberte priečinok Modely strojové učenie Azure. Všetky modely služby Azure strojové učenie, ku ktorým máte prístup, sú uvedené ako funkcie služby Power Query. Vstupné parametre pre model Azure strojové učenie sú tiež automaticky mapované ako parametre zodpovedajúcej funkcie Power Query.
Model služby Azure strojové učenie môžete vyvolať určením ktoréhokoľvek stĺpca vybratej tabuľky ako vstupu z rozbaľovacieho zoznamu. Môžete tiež zadať konštantnú hodnotu, ktorá sa má použiť ako vstup, a to tak, že prepnete ikonu stĺpca na ľavej strane dialógového okna vstupu.

Výberom položky Vyvolať zobrazíte ukážku výstupu modelu služby Azure strojové učenie vo forme nového stĺpca v tabuľke. Vyvolanie modelu sa zobrazí ako uplatnený krok pre dotaz.

Ak model vráti viacero výstupných parametrov, zoskupia sa vo výstupnom stĺpci ako riadok. Stĺpec môžete rozbaliť a vytvoriť tak jednotlivé výstupné parametre v samostatných stĺpcoch.

Keď uložíte tok údajov, model sa automaticky vyvolá po obnovení toku údajov, a to v prípade akýchkoľvek nových alebo aktualizovaných riadkov v tabuľke.
Dôležité informácie a obmedzenia
- Toky údajov Gen2 sa v súčasnosti neintegrujú s automatizovaným strojovým učením.
- Prehľady UI (služby Cognitive Services a modely azure strojové učenie) nie sú podporované v počítačoch s nastavením overenia serverom proxy.
- Modely služby Azure strojové učenie nie sú pre hosťovských používateľov podporované.
- Pri používaní brány s automatizáciou strojového učenia a službami Cognitive Services sa vyskytli známe problémy. Ak potrebujete použiť bránu, odporúčame najskôr vytvoriť tok údajov, ktorý importuje potrebné údaje cez bránu. Potom vytvorte ďalší tok údajov, ktorý odkazuje na prvý tok údajov, na vytvorenie alebo použitie týchto modelov a funkcií umelej inteligencie.
- Ak vaša AI práca s tokmi údajov zlyhá, pri používaní umelej inteligencie s tokmi údajov možno budete musieť povoliť Rýchlu kombináciu. Po importovaní tabuľky a pred začatím pridávania funkcií AI vyberte na páse s nástrojmi Domov položku Možnosti a v okne, ktoré sa zobrazí, začiarknite políčko vedľa položky Povoliť kombinovanie údajov z viacerých zdrojov . Potom výberom položky OK uložte výber. Potom môžete do toku údajov pridať funkcie AI.
Súvisiaci obsah
Tento článok poskytol prehľad automatizovaného strojové učenie pre toky údajov v služba Power BI. Nasledujúce články môžu byť tiež užitočné.
- Kurz: Vytvorenie modelu strojové učenie v službe Power BI
- Kurz: Používanie služieb Cognitive Services v Power BI
V nasledujúcich článkoch nájdete ďalšie informácie o tokoch údajov a službe Power BI:
- Úvodné informácie o tokoch údajov a samoobslužná príprava údajov
- Vytvorenie toku údajov
- Konfigurácia a používanie toku údajov
- Konfigurácia úložiska toku údajov na používanie úložiska Azure Data Lake Gen2
- Prémiové funkcie tokov údajov
- Dôležité informácie a obmedzenia týkajúce sa tokov údajov
- Najvhodnejšie postupy pre toky údajov