Upgrade availability group replicas
Applies to: ![]() SQL Server
SQL Server
When upgrading a SQL Server instance that hosts an Always On availability group (AG) to a new SQL Server version, to a new SQL Server service pack or cumulative update, or when installing to a new Windows service pack or cumulative update, you can reduce downtime for the primary replica to only a single manual failover by performing a rolling upgrade (or two manual failovers if failing back to the original primary).
During the upgrade process, a secondary replica won't be available for failover or for read-only operations, and after the upgrade, it may take some time for the secondary replica to catch up with the primary replica node depending upon the volume of activity on the primary replica node (so expect high network traffic).
Also be aware that after the initial failover to a secondary replica running a newer version of SQL Server, the databases in that AG will run through an upgrade process to bring them to the latest version. During this time, there will be no readable replicas for any of these databases. Downtime after the initial failover will depend on the number of databases in the AG. If you plan on failing back to the original primary, this step won't be repeated when you fail back.
Note
This article limits the discussion to the upgrade of SQL Server itself. It does not cover upgrading the operating system containing the Windows Server Failover Cluster (WSFC). Upgrading the Windows operating system hosting the failover cluster is not supported for operating systems before Windows Server 2012 R2. To upgrade a cluster node running on Windows Server 2012 R2, see Cluster Operating System Rolling Upgrade.
Prerequisites
Before you begin, review the following important information:
Supported version and edition upgrades: Verify that you can upgrade to the latest version of SQL Server from your version of the Windows operating system and version of SQL Server. For example, if you upgrade directly from a SQL Server 2005 instance, your database compatibility level will be upgraded.
Choose a database engine upgrade method: To upgrade in the correct order, select the appropriate upgrade method and steps based on your review of supported version and edition upgrades, and also based on other components installed in your environment.
Plan and test the database engine upgrade plan: Review the release notes and known upgrade issues, the pre-upgrade checklist, and develop and test the upgrade plan.
Hardware and software requirements for installing SQL Server: Review the software requirements for installing SQL Server. If additional software is required, install it on each node before you begin the upgrade process to minimize any downtime.
Check if change data capture or replication is used for any AG databases: If any databases in the AG are enabled for change data capture (CDC), complete these instructions.
Note
Mixing versions of SQL Server instances in the same AG is not supported outside of a rolling upgrade and should not exist in that state for extended periods of time as the upgrade should take place quickly. The other option for upgrading SQL Server 2016 (13.x) and later versions is through the use of a distributed availability group.
Note
Using the Cluster-Aware Updating (CAU) Windows feature to update Always On availability groups is not supported.
Rolling upgrade basics for availability groups
Observe the following guidelines when performing server upgrades or updates in order to minimize downtime and data loss for your AGs:
Before you start the rolling upgrade:
Perform a practice manual failover on at least one of your synchronous-commit replica instances
Protect your data by performing a full database backup on every availability database
Run
DBCC CHECKDBon every availability database
Always upgrade the remote secondary replica instances first, then local secondary replica instances next, and the primary replica instance last.
Backups can't occur on a database that is in the process of being upgraded. Prior to upgrading the secondary replicas, configure the automated backup preference to run backups only on the primary replica. During a version upgrade, no replicas are readable or available for backups. During a non-version upgrade, you can configure automated backups to run on secondary replicas prior to upgrading the primary replica.
During a version upgrade, readable secondaries can't be read after an upgrade of the readable secondary and before either the primary replica is failed over to an upgraded secondary, or the primary replica is upgraded.
To prevent the AG from unintended failovers during the upgrade process, remove availability failover from all synchronous-commit replicas before you begin.
Don't upgrade the primary replica instance before failing over the AG to an upgraded instance with a secondary replica first. Otherwise, client applications may suffer extended downtime during the upgrade on the primary replica instance.
Always fail over the AG to a synchronous-commit secondary replica instance. If you fail over to an asynchronous-commit secondary replica instance, the databases are vulnerable to data loss, and data movement is automatically suspended until you manually resume data movement.
Don't upgrade the primary replica instance before upgrading or updating any other secondary replica instance. An upgraded primary replica can no longer ship logs to any secondary replica whose SQL Server instance that hasn't yet been upgraded to the same version. When data movement to a secondary replica is suspended, no automatic failover can occur for that replica, and your availability databases are vulnerable to data loss. This also applies during a rolling upgrade where you manually failover from an old primary to a new primary. As such, after you upgrade the old primary, you may need to resume synchronization.
Before failing over an AG, verify that the synchronization state of the failover target is
SYNCHRONIZED.Warning
Installing a new instance or new version of SQL Server to a server that has an older version of SQL Server installed may inadvertently cause an outage for any availability group that is hosted by the older version of SQL Server. This is because during the installation of the instance or version of SQL Server, the SQL Server high availability module (RHS.EXE) gets upgraded. This results in a temporary interruption of your existing availability groups in the primary role on the server. Therefore, it is highly recommended that you do one of the following when installing a newer version of SQL Server to a system already hosting an older version of SQL Server with an availability group:
Install the new version of SQL Server during a maintenance window.
Fail over the availability group to the secondary replica so it is not primary during the installation of the new SQL Server instance.
Rolling upgrade process
In practice, the exact process depends on factors such as the deployment topology of your AGs and the commit mode of each replica. But in the simplest scenario, a rolling upgrade is a multi-stage process that in its simplest form involves the following steps:
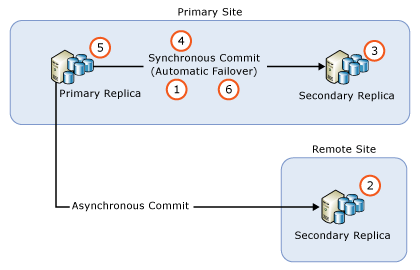
- Remove automatic failover on all synchronous-commit replicas
- Upgrade all asynchronous-commit secondary replica instances.
- Upgrade all remote synchronous-commit secondary replica instances.
- Upgrade all local synchronous-commit secondary replica instances.
- Manually fail over the AG to a (newly upgraded) local synchronous-commit secondary replica.
- Upgrade or update the local replica instance that formerly hosted the primary replica.
- Configure automatic failover partners as desired.
If necessary, you can perform an extra manual failover to return the AG to its original configuration.
Note
Upgrading a synchronous-commit replica and taking it offline will not delay transactions on the primary. Once the secondary replica is disconnected, transactions are committed on the primary without waiting for logs to harden on the secondary replica.
If REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT is set to either 1 or 2, the Primary replica may be unavailable for read/writes when a corresponding number of sync secondary replicas are not available during the update process.
Note
When you perform an in-place upgrade of a secondary replica to a newer version of SQL Server, the database inside the availability group remains in the Synchronizing / In recovery or Synchronized / In Recovery state until the availability group is manually failed over, which finishes the recovery and upgrades the database. An upgraded primary replica can no longer ship logs to any lower version secondary replica and data movement stops and no automatic failover can occur for that replica, and your availability databases are vulnerable to data loss. After you upgrade the old primary, you may need to resume synchronization. It is recommended to upgrade all secondary replicas before failing over to a replica with the new version. That way you have the option of doing a failover after the database(es) are upgraded to the new format.
AG with one remote secondary replica
If you have deployed an AG only for disaster recovery, you may need to fail over the AG to an asynchronous-commit secondary replica. Such configuration is illustrated by the following figure:
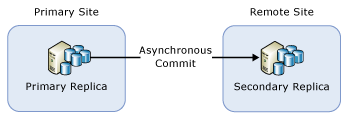
In this situation, you must fail over the AG to the asynchronous-commit secondary replica during the rolling upgrade. To prevent data loss, change the commit mode to synchronous commit, and wait for the secondary replica to be synchronized before you fail over the AG. Therefore, the rolling upgrade process may look as follows:
- Upgrade the secondary replica instance on the remote site
- Change the commit mode to synchronous commit
- Wait until synchronization state is
SYNCHRONIZED - Fail over the AG to the secondary replica on the remote site
- Upgrade or update the local (primary site) replica instance
- Fail over the AG back to the primary site
- Change the commit mode to asynchronous commit
Since the synchronous-commit mode isn't a recommended setting for data synchronization to a remote site, client applications may notice an immediate increase in database latency after the setting change. Moreover, performing a failover causes all unacknowledged log messages to be discarded. The number discarded log messages can be significant due to the high network latency between the two sites, causing clients to experience a high volume of transactional failure. You can minimize the effect on client applications by doing the following actions:
Carefully select a maintenance window during low client traffic
While upgrading or updating SQL Server on the primary site, change the availability mode back to asynchronous commit, then revert to synchronous commit when you are ready to fail over to the primary site again
AG with failover cluster instance nodes
If an AG contains failover cluster instance (FCI) nodes, you should upgrade the inactive nodes before you upgrade the active nodes. The following figure illustrates a common AG scenario with FCIs for local high availability and asynchronous commit between the FCIs for remote disaster recovery, and the upgrade sequence.
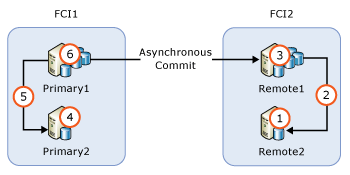
- Upgrade or update
REMOTE2 - Fail over FCI2 to
REMOTE2 - Upgrade or update
REMOTE1 - Upgrade or update
PRIMARY2 - Fail over FCI1 to
PRIMARY2 - Upgrade or update
PRIMARY1
Upgrade or update SQL Server instances with multiple AGs
If you are running multiple AGs with primary replicas on separate server nodes (an Active/Active configuration), the upgrade path involves more failover steps to preserve high availability in the process. Suppose you are running three AGs on three server nodes with all replicas in synchronous commit mode as shown in the following table:
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primary | ||
| AG2 | Primary | ||
| AG3 | Primary |
It may be appropriate in your situation to perform a load-balanced rolling upgrade in the following sequence:
- Fail over AG2 to
Node3(to free upNode2) - Upgrade or update
Node2 - Fail over AG1 to
Node2(to free upNode1) - Upgrade or update
Node1 - Fail over both AG2 and AG3 to
Node1(to free upNode3) - Upgrade or update
Node3 - Fail over AG3 to
Node3
This upgrade sequence has an average downtime of fewer than two failovers per AG. The resulting configuration is shown in the following table.
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primary | ||
| AG2 | Primary | ||
| AG3 | Primary |
Based on your specific implementation, your upgrade path may vary, and the downtime that client applications experience may vary as well.
Note
In many cases, after the rolling upgrade is completed, you will fail back to the original primary replica.
Rolling upgrade of a distributed availability group
To perform a rolling upgrade of a distributed availability group, first upgrade all of the secondary replicas. Next, failover the forwarder, and upgrade the last remaining instance of the second availability group. Once all other replicas have been upgraded, failover the global primary, and upgrade the last remaining instance of the first availability group. A detailed diagram with steps is provided below.
Based on your specific implementation, your upgrade path may vary, and the downtime that client applications experience may vary as well.
Note
In many cases, after the rolling upgrade is completed, you will fail back to the original primary replicas.
General steps to upgrade a distributed availability group
- Back up all databases, including system databases, and those participating in the availability group.
- Upgrade and restart all secondary replicas of the second availability group (the downstream).
- Upgrade and restart all secondary replicas of the first availability group (the upstream).
- Fail over the forwarder primary to an upgraded secondary replica of the secondary availability group.
- Wait for data synchronization. The databases should show as synchronized on all synchronous-commit replicas, and the global primary should be synchronized with the forwarder.
- Upgrade and restart the last remaining instance of the secondary availability group.
- Fail over the global primary to an upgraded secondary of the first availability group.
- Upgrade the last remaining instance of the primary availability group.
- Restart the newly upgraded server.
- (optional) Fail both availability groups back to their original primary replicas.
Important
Verify synchronization between every step. Before proceeding to the next step, confirm that your synchronous-commit replicas are synchronized within the availability group, and that your global primary is synchronized with the forwarder in the distributed AG.
Recommendation: Every time you verify synchronization, refresh both the database node and the distributed AG node in SQL Server Management Studio. After everything is synchronized, save a screenshot of the states of each replica. This will help you keep track of what step you're on, provide evidence that everything was working correctly before the next step, and assist you with troubleshooting if anything goes wrong.
Diagram example for a rolling upgrade of a distributed availability group
| Availability group | Primary replica | Secondary Replica |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | AG1 (global) | AG2 (forwarder) |
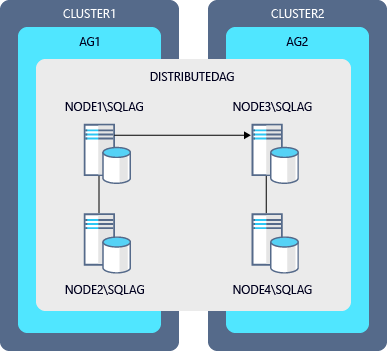
The steps to upgrade the instances in this diagram:
- Back up all databases, including system databases, and those participating in the availability group.
- Upgrade
NODE4\SQLAG(secondary of AG2) and restart the server. - Upgrade
NODE2\SQLAG(secondary of AG1) and restart the server. - Fail AG2 over from
NODE3\SQLAGtoNODE4\SQLAG. - Upgrade
NODE3\SQLAGand restart the server. - Fail AG1 over from
NODE1\SQLAGtoNODE2\SQLAG. - Upgrade
NODE1\SQLAGand restart the server. - (optional) Fail back to the original primary replicas.
- Fail AG2 over from
NODE4\SQLAGback toNODE3\SQLAG. - Fail AG1 over from
NODE2\SQLAGback toNODE1\SQLAG.
- Fail AG2 over from
If a third replica existed in each availability group, it would be upgraded before NODE3\SQLAG and NODE1\SQLAG.
Important
Verify synchronization between every step. Before proceeding to the next step, confirm that your synchronous-commit replicas are synchronized within the availability group, and that your global primary is synchronized with the forwarder in the distributed AG.
Recommendation: Every time you verify synchronization, refresh both the database node and the Distributed AG node in SQL Server Management Studio. If After everything is synchronized, then take a screenshot and save it. This will help you keep track of what step you're on, provide evidence that everything was working correctly before the next step, and assist you with troubleshooting if anything goes wrong.
Special steps for change data capture or replication
Depending on the update being applied, additional steps may be required for AG replica databases that are enabled for change data capture or replication. Refer to the release notes for the update to determine if the following steps are required:
Upgrade each secondary replica.
After all secondary replicas have been upgraded, fail over the AG to an upgraded instance.
Run the following Transact-SQL on the instance that hosts the primary replica:
EXECUTE [master].[sys].[sp_vupgrade_replication];Note
This command may take several minutes to run. Skip this step if you're on SQL Server 2019 CU1 or later. To learn more, review KB4530283
Upgrade the instance that was originally the primary replica.
For background information, see CDC functionality may break after upgrading to the latest CU.