Design a multi-tenant database using Azure Cosmos DB for PostgreSQL
APPLIES TO:
![]() Azure Cosmos DB for PostgreSQL (powered by the Citus database
extension to PostgreSQL)
Azure Cosmos DB for PostgreSQL (powered by the Citus database
extension to PostgreSQL)
In this tutorial, you use Azure Cosmos DB for PostgreSQL to learn how to:
- Create a cluster
- Use psql utility to create a schema
- Shard tables across nodes
- Ingest sample data
- Query tenant data
- Share data between tenants
- Customize the schema per-tenant
Prerequisites
If you don't have an Azure subscription, create a free account before you begin.
Create a cluster
Sign in to the Azure portal and follow these steps to create an Azure Cosmos DB for PostgreSQL cluster:
Go to Create an Azure Cosmos DB for PostgreSQL cluster in the Azure portal.



On the Create an Azure Cosmos DB for PostgreSQL cluster form:
Fill out the information on the Basics tab.

Most options are self-explanatory, but keep in mind:
- The cluster name determines the DNS name your applications use to connect, in the form
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - You can choose a major PostgreSQL version such as 15. Azure Cosmos DB for PostgreSQL always supports the latest Citus version for the selected major Postgres version.
- The admin username must be the value
citus. - You can leave database name at its default value 'citus' or define your only database name. You can't rename database after cluster provisioning.
- The cluster name determines the DNS name your applications use to connect, in the form
Select Next : Networking at the bottom of the screen.
On the Networking screen, select Allow public access from Azure services and resources within Azure to this cluster.
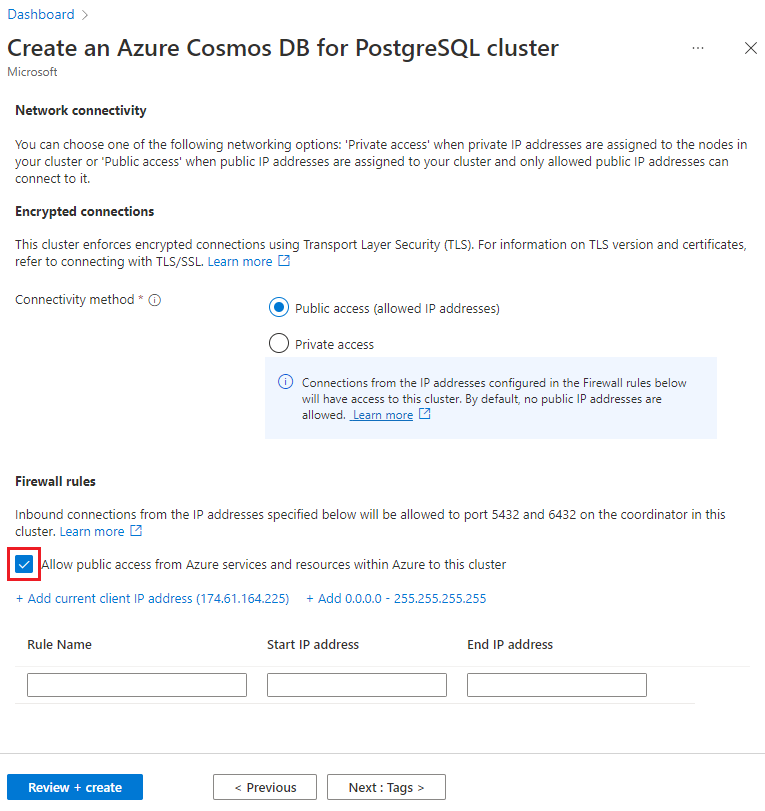
Select Review + create, and when validation passes, select Create to create the cluster.
Provisioning takes a few minutes. The page redirects to monitor deployment. When the status changes from Deployment is in progress to Your deployment is complete, select Go to resource.
Use psql utility to create a schema
Once connected to the Azure Cosmos DB for PostgreSQL using psql, you can complete some basic tasks. This tutorial walks you through creating a web app that allows advertisers to track their campaigns.
Multiple companies can use the app, so let's create a table to hold companies and another for their campaigns. In the psql console, run these commands:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Each campaign will pay to run ads. Add a table for ads too, by running the following code in psql after the code above:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Finally, we'll track statistics about clicks and impressions for each ad:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
You can see the newly created tables in the list of tables now in psql by running:
\dt
Multi-tenant applications can enforce uniqueness only per tenant, which is why all primary and foreign keys include the company ID.
Shard tables across nodes
A Azure Cosmos DB for PostgreSQL deployment stores table rows on different nodes based on the value of a user-designated column. This "distribution column" marks which tenant owns which rows.
Let's set the distribution column to be company_id, the tenant identifier. In psql, run these functions:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Important
Distributing tables or using schema-based sharding is necessary to take advantage of Azure Cosmos DB for PostgreSQL performance features. If you don't distribute tables or schemas then worker nodes can't help run queries involving their data.
Ingest sample data
Outside of psql now, in the normal command line, download sample data sets:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Back inside psql, bulk load the data. Be sure to run psql in the same directory where you downloaded the data files.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
This data will now be spread across worker nodes.
Query tenant data
When the application requests data for a single tenant, the database
can execute the query on a single worker node. Single-tenant queries
filter by a single tenant ID. For example, the following query
filters company_id = 5 for ads and impressions. Try running it in
psql to see the results.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Share data between tenants
Until now all tables have been distributed by company_id. However,
some data doesn't naturally "belong" to any tenant in particular,
and can be shared. For instance, all companies in the example ad
platform might want to get geographical information for their
audience based on IP addresses.
Create a table to hold shared geographic information. Run the following commands in psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Next make geo_ips a "reference table" to store a copy of the
table on every worker node.
SELECT create_reference_table('geo_ips');
Load it with example data. Remember to run this command in psql from inside the directory where you downloaded the dataset.
\copy geo_ips from 'geo_ips.csv' with csv
Joining the clicks table with geo_ips is efficient on all nodes. Here's a join to find the locations of everyone who clicked on ad 290. Try running the query in psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Customize the schema per-tenant
Each tenant may need to store special information not needed by others. However, all tenants share a common infrastructure with an identical database schema. Where can the extra data go?
One trick is to use an open-ended column type like PostgreSQL's
JSONB. Our schema has a JSONB field in clicks called user_data.
A company (say company five), can use the column to track whether
the user is on a mobile device.
Here's a query to find who clicks more: mobile, or traditional visitors.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
We can optimize this query for a single company by creating a partial index.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
More generally, we can create a GIN indices on every key and value within the column.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Clean up resources
In the preceding steps, you created Azure resources in a cluster. If you don't expect to need these resources in the future, delete the cluster. Select the Delete button in the Overview page for your cluster. When prompted on a pop-up page, confirm the name of the cluster and select the final Delete button.
Next steps
In this tutorial, you learned how to provision a cluster. You connected to it with psql, created a schema, and distributed data. You learned to query data both within and between tenants, and to customize the schema per tenant.
- Learn about cluster node types
- Determine the best initial size for your cluster