Transformation functions in Power Query for data wrangling
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data Wrangling in Azure Data Factory allows you to do code-free agile data preparation and wrangling at cloud scale by translating Power Query M scripts into Data Flow script. ADF integrates with Power Query Online and makes Power Query M functions available for data wrangling via Spark execution using the data flow Spark infrastructure.
Currently not all Power Query M functions are supported for data wrangling despite being available during authoring. While building your mash-ups, you'll be prompted with the following error message if a function isn't supported:
UserQuery : Expression.Error: The transformation logic is not supported as it requires dynamic access to rows of data, which cannot be scaled out.
Below is a list of supported Power Query M functions.
Column Management
- Selection: Table.SelectColumns
- Removal: Table.RemoveColumns
- Renaming: Table.RenameColumns, Table.PrefixColumns, Table.TransformColumnNames
- Reordering: Table.ReorderColumns
Row Filtering
Use M function Table.SelectRows to filter on the following conditions:
- Equality and inequality
- Numeric, text, and date comparisons (but not DateTime)
- Numeric information such as Number.IsEven/Odd
- Text containment using Text.Contains, Text.StartsWith, or Text.EndsWith
- Date ranges including all the 'IsIn' Date functions)
- Combinations of these using and, or, or not conditions
Adding and Transforming Columns
The following M functions add or transform columns: Table.AddColumn, Table.TransformColumns, Table.ReplaceValue, Table.DuplicateColumn. Below are the supported transformation functions.
- Numeric arithmetic
- Text concatenation
- Date and Time Arithmetic (Arithmetic operators, Date.AddDays, Date.AddMonths, Date.AddQuarters, Date.AddWeeks, Date.AddYears)
- Durations can be used for date and time arithmetic, but must be transformed into another type before written to a sink (Arithmetic operators, #duration, Duration.Days, Duration.Hours, Duration.Minutes, Duration.Seconds, Duration.TotalDays, Duration.TotalHours, Duration.TotalMinutes, Duration.TotalSeconds)
- Most standard, scientific, and trigonometric numeric functions (All functions under Operations, Rounding, and Trigonometry except Number.Factorial, Number.Permutations, and Number.Combinations)
- Replacement (Replacer.ReplaceText, Replacer.ReplaceValue, Text.Replace, Text.Remove)
- Positional text extraction (Text.PositionOf, Text.Length, Text.Start, Text.End, Text.Middle, Text.ReplaceRange, Text.RemoveRange)
- Basic text formatting (Text.Lower, Text.Upper, Text.Trim/Start/End, Text.PadStart/End, Text.Reverse)
- Date/Time Functions (Date.Day, Date.Month, Date.Year Time.Hour, Time.Minute, Time.Second, Date.DayOfWeek, Date.DayOfYear, Date.DaysInMonth)
- If expressions (but branches must have matching types)
- Row filters as a logical column
- Number, text, logical, date, and datetime constants
Merging/Joining tables
- Power Query will generate a nested join (Table.NestedJoin; users can also manually write Table.AddJoinColumn). Users must then expand the nested join column into a non-nested join (Table.ExpandTableColumn, not supported in any other context).
- The M function Table.Join can be written directly to avoid the need for an additional expansion step, but the user must ensure that there are no duplicate column names among the joined tables
- Supported Join Kinds: Inner, LeftOuter, RightOuter, FullOuter
- Both Value.Equals and Value.NullableEquals are supported as key equality comparers
Group by
Use Table.Group to aggregate values.
- Must be used with an aggregation function
- Supported aggregation functions: List.Sum, List.Count, List.Average, List.Min, List.Max, List.StandardDeviation, List.First, List.Last
Sorting
Use Table.Sort to sort values.
Reducing Rows
Keep and Remove Top, Keep Range (corresponding M functions, only supporting counts, not conditions: Table.FirstN, Table.Skip, Table.RemoveFirstN, Table.Range, Table.MinN, Table.MaxN)
Known unsupported functions
| Function | Status |
|---|---|
| Table.PromoteHeaders | Not supported. The same result can be achieved by setting "First row as header" in the dataset. |
| Table.CombineColumns | This is a common scenario that isn't directly supported but can be achieved by adding a new column that concatenates two given columns. For example, Table.AddColumn(RemoveEmailColumn, "Name", each [FirstName] & " " & [LastName]) |
| Table.TransformColumnTypes | This is supported in most cases. The following scenarios are unsupported: transforming string to currency type, transforming string to time type, transforming string to Percentage type and transforming with locale. |
| Table.NestedJoin | Just doing a join will result in a validation error. The columns must be expanded for it to work. |
| Table.RemoveLastN | Remove bottom rows isn't supported. |
| Table.RowCount | Not supported, but can be achieved by adding a custom column containing the value 1, then aggregating that column with List.Sum. Table.Group is supported. |
| Row level error handling | Row level error handling is currently not supported. For example, to filter out non-numeric values from a column, one approach would be to transform the text column to a number. Every cell, which fails to transform will be in an error state and need to be filtered. This scenario isn't possible in scaled-out M. |
| Table.Transpose | Not supported |
M script workarounds
SplitColumn
An alternate for split by length and by position is listed below
- Table.AddColumn(Source, "First characters", each Text.Start([Email], 7), type text)
- Table.AddColumn(#"Inserted first characters", "Text range", each Text.Middle([Email], 4, 9), type text)
This option is accessible from the Extract option in the ribbon

Table.CombineColumns
- Table.AddColumn(RemoveEmailColumn, "Name", each [FirstName] & " " & [LastName])
Pivots
- Select Pivot transformation from the PQ editor and select your pivot column
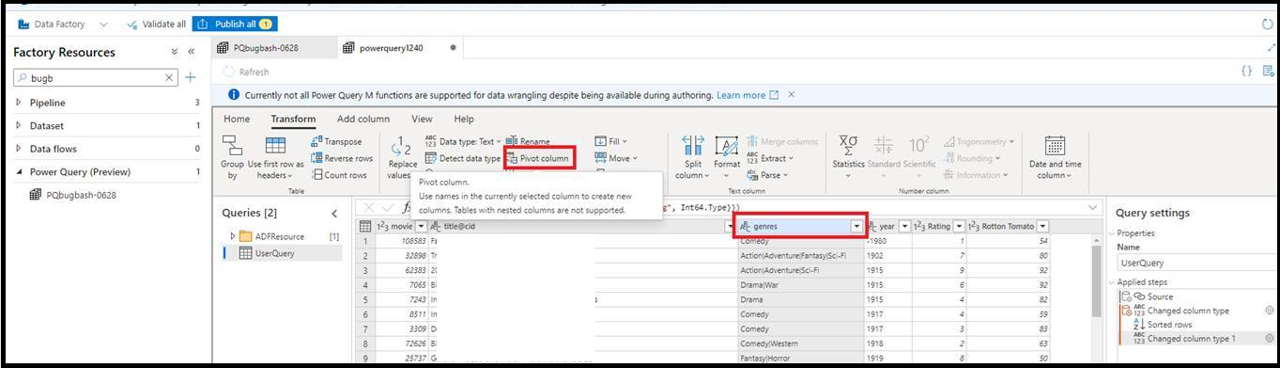
- Next, select the value column and the aggregate function
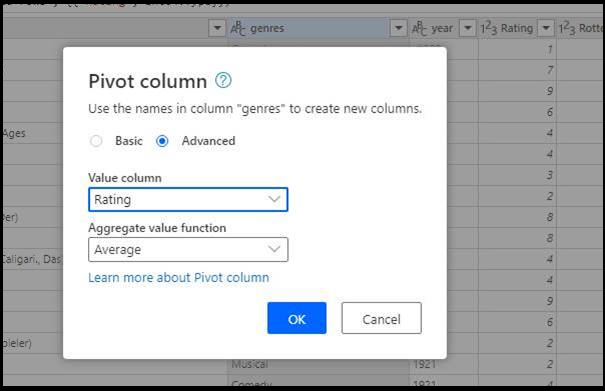
- When you click OK, you'll see the data in the editor updated with the pivoted values
- You'll also see a warning message that the transformation may be unsupported
- To fix this warning, expand the pivoted list manually using the PQ editor
- Select Advanced Editor option from the ribbon
- Expand the list of pivoted values manually
- Replace List.Distinct() with the list of values like this:
#"Pivoted column" = Table.Pivot(Table.TransformColumnTypes(#"Changed column type 1", {{"genres", type text}}), {"Drama", "Horror", "Comedy", "Musical", "Documentary"}, "genres", "Rating", List.Average)
in
#"Pivoted column"
Formatting date/time columns
To set the date/time format when using Power Query ADF, please follow these sets to set the format.
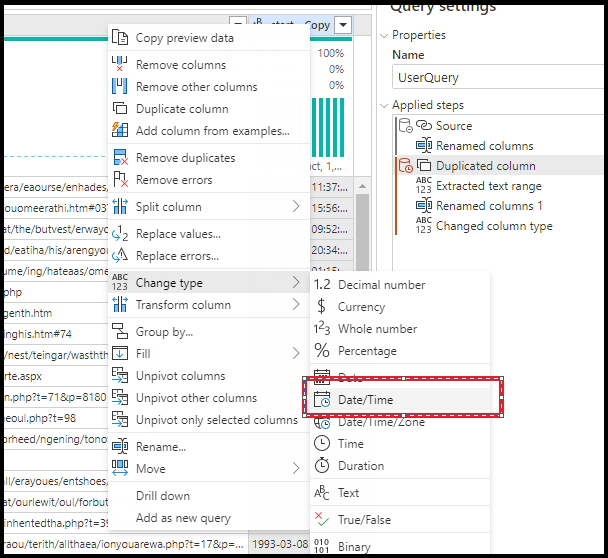
- Select the column in the Power Query UI and choose Change Type > Date/Time
- You'll see a warning message
- Open Advanced Editor and change
TransformColumnTypestoTransformColumns. Specify the format and culture based on the input data.

#"Changed column type 1" = Table.TransformColumns(#"Duplicated column", {{"start - Copy", each DateTime.FromText(_, [Format = "yyyy-MM-dd HH:mm:ss", Culture = "en-us"]), type datetime}})
Related content
Learn how to create a data wrangling Power Query in ADF.