Specify jobs in your pipeline
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
You can organize your pipeline into jobs. Every pipeline has at least one job. A job is a series of steps that run sequentially as a unit. In other words, a job is the smallest unit of work that can be scheduled to run.
To learn about the key concepts and components that make up a pipeline, see Key concepts for new Azure Pipelines users.
Azure Pipelines does not support job priority for YAML pipelines. To control when jobs run, you can specify conditions and dependencies.
Define a single job
In the simplest case, a pipeline has a single job. In that case, you don't have to explicitly use the job keyword unless you're using a template. You can directly specify the steps in your YAML file.
This YAML file has a job that runs on a Microsoft-hosted agent and outputs Hello world.
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
You might want to specify more properties on that job. In that case, you can use the job keyword.
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Your pipeline could have multiple jobs. In that case, use the jobs keyword.
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
Your pipeline may have multiple stages, each with multiple jobs. In that case, use the stages keyword.
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
The full syntax to specify a job is:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
The full syntax to specify a job is:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
If the primary intent of your job is to deploy your app (as opposed to build or test your app), then you can use a special type of job called deployment job.
The syntax for a deployment job is:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Although you can add steps for deployment tasks in a job, we recommend that you instead use a deployment job. A deployment job has a few benefits. For example, you can deploy to an environment, which includes benefits such as being able to see the history of what you've deployed.

Types of jobs
Jobs can be of different types, depending on where they run.
- Agent pool jobs run on an agent in an agent pool.
- Server jobs run on the Azure DevOps Server.
- Container jobs run in a container on an agent in an agent pool. For more information about choosing containers, see Define container jobs.
Agent pool jobs
These are the most common type of jobs and they run on an agent in an agent pool.
- When using Microsoft-hosted agents, each job in a pipeline gets a fresh agent.
- Use demands with self-hosted agents to specify what capabilities an agent must have to run your job. You may get the same agent for consecutive jobs, depending on whether there's more than one agent in your agent pool that matches your pipeline's demands. If there's only one agent in your pool that matches the pipeline's demands, the pipeline waits until this agent is available.
Note
Demands and capabilities are designed for use with self-hosted agents so that jobs can be matched with an agent that meets the requirements of the job. When using Microsoft-hosted agents, you select an image for the agent that matches the requirements of the job, so although it is possible to add capabilities to a Microsoft-hosted agent, you don't need to use capabilities with Microsoft-hosted agents.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
Or multiple demands:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Learn more about agent capabilities.
Server jobs
Tasks in a server job are orchestrated by and executed on the server (Azure Pipelines or TFS). A server job doesn't require an agent or any target computers. Only a few tasks are supported in a server job now. The maximum time for a server job is 30 days.
Agentless jobs supported tasks
Currently, only the following tasks are supported out of the box for agentless jobs:
- Delay task
- Invoke Azure Function task
- Invoke REST API task
- Manual Validation task
- Publish To Azure Service Bus task
- Query Azure Monitor Alerts task
- Query Work Items task
Because tasks are extensible, you can add more agentless tasks by using extensions. The default timeout for agentless jobs is 60 minutes.
The full syntax to specify a server job is:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
You can also use the simplified syntax:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Dependencies
When you define multiple jobs in a single stage, you can specify dependencies between them. Pipelines must contain at least one job with no dependencies. By default Azure DevOps YAML pipeline jobs run in parallel unless the dependsOn value is set.
Note
Each agent can run only one job at a time. To run multiple jobs in parallel you must configure multiple agents. You also need sufficient parallel jobs.
The syntax for defining multiple jobs and their dependencies is:
jobs:
- job: string
dependsOn: string
condition: string
Example jobs that build sequentially:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Example jobs that build in parallel (no dependencies):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Example of fan out:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Example of fan-in:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
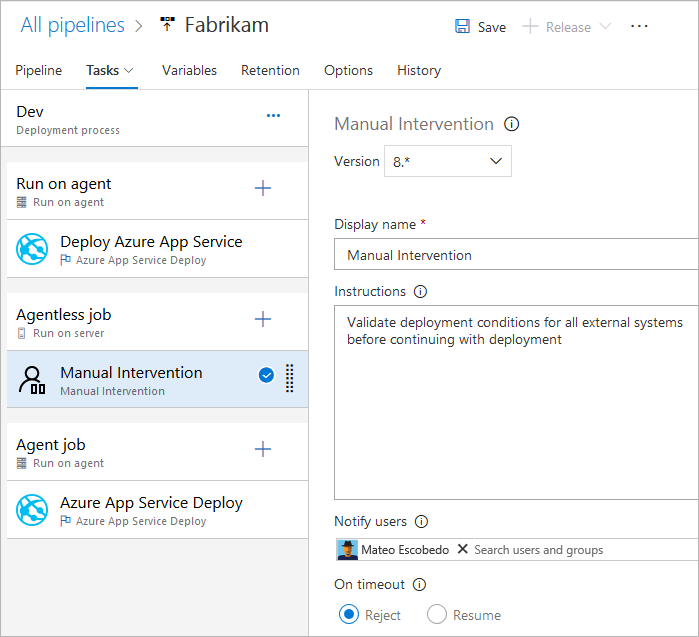
Conditions
You can specify the conditions under which each job runs. By default, a job runs if it doesn't depend on any other job, or if all of the jobs that it depends on have completed and succeeded. You can customize this behavior by forcing a job to run even if a previous job fails or by specifying a custom condition.
Example to run a job based upon the status of running a previous job:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Example of using a custom condition:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
You can specify that a job run based on the value of an output variable set in a previous job. In this case, you can only use variables set in directly dependent jobs:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Timeouts
To avoid taking up resources when your job is unresponsive or waiting too long, it's a good idea to set a limit on how long your job is allowed to run. Use the job timeout setting to specify the limit in minutes for running the job. Setting the value to zero means that the job can run:
- Forever on self-hosted agents
- For 360 minutes (6 hours) on Microsoft-hosted agents with a public project and public repository
- For 60 minutes on Microsoft-hosted agents with a private project or private repository (unless additional capacity is paid for)
The timeout period begins when the job starts running. It doesn't include the time the job is queued or is waiting for an agent.
The timeoutInMinutes allows a limit to be set for the job execution time. When not specified, the default is 60 minutes. When 0 is specified, the maximum limit is used (described above).
The cancelTimeoutInMinutes allows a limit to be set for the job cancel time when the deployment task is set to keep running if a previous task failed. When not specified, the default is 5 minutes. The value should be in range from 1 to 35790 minutes.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Timeouts have the following level of precedence.
- On Microsoft-hosted agents, jobs are limited in how long they can run based on project type and whether they're run using a paid parallel job. When the Microsoft-hosted job timeout interval elapses, the job is terminated. On Microsoft-hosted agents, jobs can't run longer than this interval, regardless of any job level timeouts specified in the job.
- The timeout configured at the job level specifies the maximum duration for the job to run. When the job level timeout interval elapses, the job is terminated. If the job is run on a Microsoft-hosted agent, setting the job level timeout to an interval greater than the built-in Microsoft-hosted job level timeout has no effect and the Microsoft-hosted job timeout is used.
- You can also set the timeout for each task individually - see task control options. If the job level timeout interval elapses before the task completes, the running job is terminated, even if the task is configured with a longer timeout interval.
Multi-job configuration
From a single job you author, you can run multiple jobs on multiple agents in parallel. Some examples include:
Multi-configuration builds: You can build multiple configurations in parallel. For example, you could build a Visual C++ app for both
debugandreleaseconfigurations on bothx86andx64platforms. For more information, see Visual Studio Build - multiple configurations for multiple platforms.Multi-configuration deployments: You can run multiple deployments in parallel, for example, to different geographic regions.
Multi-configuration testing: You can run test multiple configurations in parallel.
Multi-configuration will always generate at least one job, even if a multi-configuration variable is empty.
The matrix strategy enables a job to be dispatched multiple times, with different variable sets. The maxParallel tag restricts the amount of parallelism. The following job is dispatched three times with the values of Location and Browser set as specified. However, only two jobs run at the same time.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Note
Matrix configuration names (like US_IE above) must contain only basic Latin alphabet letters (A-Z, a-z), numbers, and underscores (_).
They must start with a letter.
Also, they must be 100 characters or less.
It's also possible to use output variables to generate a matrix. This can be handy if you need to generate the matrix using a script.
matrix accepts a runtime expression containing a stringified JSON object.
That JSON object, when expanded, must match the matrixing syntax.
In the example below, we've hard-coded the JSON string, but it could be generated by a scripting language or command-line program.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Slicing
An agent job can be used to run a suite of tests in parallel. For example, you can run a large suite of 1000 tests on a single agent. Or, you can use two agents and run 500 tests on each one in parallel.
To apply slicing, the tasks in the job should be smart enough to understand the slice they belong to.
The Visual Studio Test task is one such task that supports test slicing. If you installed multiple agents, you can specify how the Visual Studio Test task runs in parallel on these agents.
The parallel strategy enables a job to be duplicated many times.
Variables System.JobPositionInPhase and System.TotalJobsInPhase are added to each job. The variables can then be used within your scripts to divide work among the jobs.
See Parallel and multiple execution using agent jobs.
The following job is dispatched five times with the values of System.JobPositionInPhase and System.TotalJobsInPhase set appropriately.
jobs:
- job: Test
strategy:
parallel: 5
Job variables
If you're using YAML, variables can be specified on the job. The variables can be passed to task inputs using the macro syntax $(variableName), or accessed within a script using the stage variable.
Here's an example of defining variables in a job and using them within tasks.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
For information about using a condition, see Specify conditions.
Workspace
When you run an agent pool job, it creates a workspace on the agent. The workspace is a directory in which it downloads the source, runs steps, and produces outputs. The workspace directory can be referenced in your job using Pipeline.Workspace variable. Under this, various subdirectories are created:
Build.SourcesDirectoryis where tasks download the application's source code.Build.ArtifactStagingDirectoryis where tasks download artifacts needed for the pipeline or upload artifacts before they're published.Build.BinariesDirectoryis where tasks write their outputs.Common.TestResultsDirectoryis where tasks upload their test results.
The $(Build.ArtifactStagingDirectory) and $(Common.TestResultsDirectory) are always deleted and recreated prior to every build.
When you run a pipeline on a self-hosted agent, by default, none of the subdirectories other than $(Build.ArtifactStagingDirectory) and $(Common.TestResultsDirectory) are cleaned in between two consecutive runs. As a result, you can do incremental builds and deployments, provided that tasks are implemented to make use of that. You can override this behavior using the workspace setting on the job.
Important
The workspace clean options are applicable only for self-hosted agents. Jobs are always run on a new agent with Microsoft-hosted agents.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
When you specify one of the clean options, they're interpreted as follows:
outputs: DeleteBuild.BinariesDirectorybefore running a new job.resources: DeleteBuild.SourcesDirectorybefore running a new job.all: Delete the entirePipeline.Workspacedirectory before running a new job.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Note
Depending on your agent capabilities and pipeline demands, each job may be routed to a different agent in your self-hosted pool. As a result, you may get a new agent for subsequent pipeline runs (or stages or jobs in the same pipeline), so not cleaning is not a guarantee that subsequent runs, jobs, or stages will be able to access outputs from previous runs, jobs, or stages. You can configure agent capabilities and pipeline demands to specify which agents are used to run a pipeline job, but unless there is only a single agent in the pool that meets the demands, there is no guarantee that subsequent jobs will use the same agent as previous jobs. For more information, see Specify demands.
In addition to workspace clean, you can also configure cleaning by configuring the Clean setting in the pipeline settings UI. When the Clean setting is true, which is also its default value, it's equivalent to specifying clean: true for every checkout step in your pipeline. When you specify clean: true, you'll run git clean -ffdx followed by git reset --hard HEAD before git fetching. To configure the Clean setting:
Edit your pipeline, choose ..., and select Triggers.
Select YAML, Get sources, and configure your desired Clean setting. The default is true.
Artifact download
This example YAML file publishes the artifact WebSite and then downloads the artifact to $(Pipeline.Workspace). The Deploy job only runs if the Build job is successful.
# test and upload my code as an artifact named WebSite
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishBuildArtifacts@1
inputs:
pathtoPublish: '$(System.DefaultWorkingDirectory)'
artifactName: WebSite
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadBuildArtifacts@0
displayName: 'Download Build Artifacts'
inputs:
artifactName: WebSite
downloadPath: $(Pipeline.Workspace)
dependsOn: Build
condition: succeeded()
For information about using dependsOn and condition, see Specify conditions.
Access to OAuth token
You can allow scripts running in a job to access the current Azure Pipelines or TFS OAuth security token. The token can be used to authenticate to the Azure Pipelines REST API.
The OAuth token is always available to YAML pipelines.
It must be explicitly mapped into the task or step using env.
Here's an example:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)