Povežite se s tabelami skupnega podatkovnega modela v Azure Data Lake Storage
opomba,
Azure Active Directory je zdaj Microsoft Entra ID. Nauči se več
Vnesite podatke v Dynamics 365 Customer Insights - Data s svojim Azure Data Lake Storage računom s tabelami Common Data Model. Vnos podatkov je lahko polni ali postopen.
Zahteve
V Azure Data Lake Storage računu mora biti omogočen imenski prostor hierarhičen. Podatki morajo biti shranjeni v obliki mape hierarhičen, ki določa korensko mapo in ima podmape za vsako tabelo. Podmape imajo lahko polne podatke ali mape z inkrementalnimi podatki.
Za preverjanje pristnosti z Microsoft Entra principalom storitve se prepričajte, da je konfiguriran v vašem najemniku. Za več informacij glejte Povežite se z Azure Data Lake Storage računom z Microsoft Entra načelnikom storitve.
Azure Data Lake Storage , s katerim se želite povezati in prenesti podatke, mora biti v isti regiji Azure kot Dynamics 365 Customer Insights okolje, naročnine pa morajo biti v istem najemniku. Povezave do mape Common Data Model iz jezera podatkov v drugi regiji Azure niso podprte. Če želite izvedeti območje okolja Azure, pojdite na Nastavitve>Sistem>Vizitka v Customer Insights - Data.
Podatki, shranjeni v spletnih storitvah, so lahko shranjeni na drugem mestu kot tam, kjer se podatki obdelujejo ali shranjujejo. Z uvozom ali povezovanjem s podatki, shranjenimi v spletnih storitvah, se strinjate, da se podatki lahko prenašajo. Več o tem v Microsoftovem središču zaupanja.
Voditelj Customer Insights - Data storitve mora imeti eno od naslednjih vlog za dostop do računa za shranjevanje. Za več informacij glejte Dodelitev dovoljenj glavnemu servisu za dostop do računa za shranjevanje.
- Bralnik podatkov shrambe zbirke dvojiških podatkov
- Lastnik podatkov shrambe zbirke dvojiških podatkov
- Sodelujoči v shrambi zbirke dvojiških podatkov
Pri povezovanju z vašo shrambo Azure z možnostjo naročnine na Azure uporabnik, ki vzpostavi povezavo vir podatkov, potrebuje vsaj dovoljenja sodelavec za podatke o zbirki podatkov za shranjevanje na računu za shranjevanje.
Ko se povezujete s shrambo Azure z možnostjo Azure resource , potrebuje uporabnik, ki nastavi povezavo vir podatkov, vsaj dovoljenje za Microsoft .Storage/storageAccounts/read dejanje na računu za shranjevanje. Vgrajena vloga Azure , ki vključuje to dejanje, je Uporabnik z dovoljenjem za branje vloga. Če želite omejiti dostop samo na potrebna dejanja, ustvarite vlogo Azure po meri ki vključuje samo to dejanje.
Za optimalno delovanje mora biti velikost particije 1 GB ali manj, število particijskih datotek v mapi pa ne sme presegati 1000.
Podatki v vašem Data Lake Storageu morajo slediti standardu skupnega podatkovnega modela za shranjevanje vaših podatkov in imeti manifest skupnega podatkovnega modela, ki predstavlja shemo podatkovnih datotek (*.csv ali *.parquet). Manifest mora vsebovati podrobnosti o tabelah, kot so stolpci tabele in tipi podatkov ter lokacija in vrsta podatkovne datoteke. Za več informacij glejte Manifest skupnega podatkovnega modela. Če manifest ni prisoten, lahko skrbniški uporabniki z dostopom lastnika podatkov bloba shrambe ali podatkov bloba shranjevanja sodelavec določijo shemo pri vnosu podatkov.
opomba,
Če ima katero od polj v datotekah .parquet tip podatkov Int96, podatki morda ne bodo prikazani na strani Tabele . Priporočamo uporabo standardnih tipov podatkov, kot je format časovnega žiga Unix (ki predstavlja čas kot število sekund od 1. januarja 1970 ob polnoči UTC).
Omejitve
- Customer Insights - Data ne podpira stolpcev decimalnega tipa z natančnostjo, večjo od 16.
Vzpostavljanje povezave s storitvijo Azure Data Lake Storage
Pojdite na Podatki>Viri podatkov.
Izberite Dodaj vir podatkov.
Izberite Tabele skupnega podatkovnega modela Azure Data Lake.

Vnesite vir podatkov ime in neobvezen Opis. Ime je navedeno v nadaljnjih procesih in ga po ustvarjanju vir podatkov ni mogoče spremeniti.
Izberite eno od naslednjih možnosti za Povežite svojo shrambo z uporabo. Za več informacij glejte Povežite se z Azure Data Lake Storage računom z Microsoft Entra načelnikom storitve.
- Vir Azure: Vnesite ID vira. (private-link.md).
- Naročnina Azure: Izberite Naročnino in nato skupino virov in Račun za shranjevanje.
opomba,
Za ustvarjanje vir podatkov potrebujete eno od naslednjih vlog za vsebnik:
- Storage Blob Data Uporabnik z dovoljenjem za branje zadostuje za branje iz računa za shranjevanje in vnos podatkov v Customer Insights - Data.
- Če želite urejati datoteke manifesta neposredno v Customer Insights - Data, potrebujete podatke bloba za shranjevanje sodelavec ali lastnika.
Če imate vlogo na računu za shranjevanje, boste zagotovili enako vlogo na vseh njegovih vsebnikih.
Po želji, če želite prenesti podatke iz računa za shranjevanje prek zasebne povezave Azure, izberite Omogoči zasebno povezavo. Za več informacij glejte Zasebne povezave.
Izberite ime vsebnika , ki vsebuje podatke in shemo (datoteka model.json ali manifest.json), iz katerega želite uvoziti podatke, in izberite Naprej.
opomba,
Vsaka datoteka model.json ali manifest.json, povezana z drugim virom podatkov v okolju, ne bo prikazana na seznamu. Vendar pa je isto datoteko model.json ali ali manifest.json mogoče uporabiti za vire podatkov v več okoljih.
Če želite ustvariti novo shemo, pojdite na Ustvari novo datoteko sheme.
Če želite uporabiti obstoječo shemo, se pomaknite do mape, ki vsebuje datoteko model.json ali manifest.cdm.json. Datoteko lahko poiščete v imeniku.
Izberite datoteko json in izberite Naprej. Prikaže se seznam razpoložljivih tabel.

Izberite tabele, ki jih želite vključiti.

Nasvet
Če želite urediti tabelo v vmesniku za urejanje JSON, izberite tabelo in nato Uredi datoteko sheme. Spremenite in izberite Shrani.
Za izbrane tabele, ki zahtevajo postopno zaužitje, Zahtevano se prikaže pod Postopno osveževanje. Za vsako od teh tabel glejte Konfigurirajte inkrementalno osvežitev za vire podatkov Azure Data Lake.
Za izbrane tabele, kjer primarni ključ ni bil definiran, Zahtevano se prikaže pod Primarni ključ. Za vsako od teh tabel:
- Izberite Obvezno. Prikaže se plošča Urejanje tabele .
- Izberite Primarni ključ. Primarni ključ je edinstven atribut tabele. Atribut je veljaven primarni ključ samo v primeru, če ne vsebuje podvojenih vrednosti, manjkajočih vrednosti ali ničelnih vrednosti. Kot primarni ključi so podprti atributi podatkovnega tipa niz, celo število in GUID.
- Po želji spremenite vzorec particije.
- Izberite Zapri , da shranite in zaprete ploščo.
Izberite število stolpcev za vsako vključeno tabelo. Prikaže se stran Upravljanje atributov .

- Ustvarite nove stolpce, uredite ali izbrišite obstoječe stolpce. Spremenite lahko ime, obliko zapisa podatkov ali dodate semantično vrsto.
- Če želite omogočiti analitiko in druge zmožnosti, izberite Profiliranje podatkov za celotno tabelo ali za določene stolpce. Privzeto nobena tabela ni omogočena za profiliranje podatkov.
- Izberite Dokončano.
Izberite možnost Shrani. Odpre se stran Viri podatkov , ki prikazuje novo stanje vir podatkov v Osveževanje .
Nasvet
Obstajajo statusi za naloge in procese. Večina procesov je odvisnih od drugih predhodnih procesov, kot so viri podatkov in profiliranje podatkov osvežitve.
Izberite stanje, da odprete podokno Podrobnosti o napredku in si ogledate napredek opravil. Če želite preklicati opravilo, izberite Prekliči opravilo na dnu podokna.
Pod vsakim opravilom lahko izberete Ogled podrobnosti za več informacij o napredku, kot so čas obdelave, zadnji datum obdelave in morebitne veljavne napake in opozorila, povezana z opravilom ali postopkom. Izberite Ogled statusa sistema na dnu plošče, da vidite druge procese v sistemu.

Nalaganje podatkov lahko traja nekaj časa. Po uspešni osvežitvi lahko vnesene podatke pregledate na strani Tabele .
Ustvari novo datoteko sheme
Izberite Ustvari datoteko sheme.
Vnesite ime datoteke in izberite Shrani.
Izberite Nova tabela. Prikaže se plošča Nova tabela .
Vnesite ime tabele in izberite Lokacijo podatkovnih datotek.
- Več datotek .csv ali .parquet: poiščite korensko mapo, izberite vrsto vzorca in vnesite izraz.
- Posamezne datoteke .csv ali .parquet: poiščite datoteko .csv ali .parquet in jo izberite.
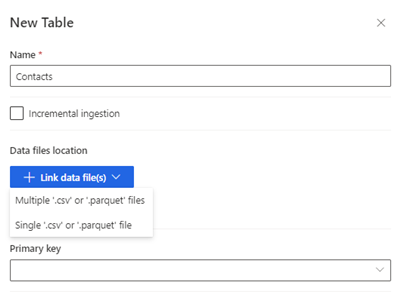
Izberite možnost Shrani.

Izberite definiraj atribute , če želite ročno dodati atribute, ali izberite jih samodejno ustvari. Če želite definirati atribute, vnesite ime, izberite obliko zapisa podatkov in izbirni semantični tip. Za samodejno ustvarjene atribute:
Ko so atributi samodejno ustvarjeni, izberite Pregled atributov. Prikaže se stran Upravljanje atributov .
Prepričajte se, da je oblika podatkov pravilna za vsak atribut.
Če želite omogočiti analitiko in druge zmožnosti, izberite Profiliranje podatkov za celotno tabelo ali za določene stolpce. Privzeto nobena tabela ni omogočena za profiliranje podatkov.
Izberite Dokončano. Prikaže se stran Izberi tabele .
Nadaljujte z dodajanjem tabel in stolpcev, če je primerno.
Ko dodate vse tabele, izberite Vključi , da vključite tabele v vir podatkov vnos.
Za izbrane tabele, ki zahtevajo postopno zaužitje, Zahtevano se prikaže pod Postopno osveževanje. Za vsako od teh tabel glejte Konfigurirajte inkrementalno osvežitev za vire podatkov Azure Data Lake.
Za izbrane tabele, kjer primarni ključ ni bil definiran, Zahtevano se prikaže pod Primarni ključ. Za vsako od teh tabel:
- Izberite Obvezno. Prikaže se plošča Urejanje tabele .
- Izberite Primarni ključ. Primarni ključ je edinstven atribut tabele. Atribut je veljaven primarni ključ samo v primeru, če ne vsebuje podvojenih vrednosti, manjkajočih vrednosti ali ničelnih vrednosti. Kot primarni ključi so podprti atributi podatkovnega tipa niz, celo število in GUID.
- Po želji spremenite vzorec particije.
- Izberite Zapri , da shranite in zaprete ploščo.
Izberite možnost Shrani. Odpre se stran Viri podatkov , ki prikazuje novo stanje vir podatkov v Osveževanje .
Nasvet
Obstajajo statusi za naloge in procese. Večina procesov je odvisnih od drugih predhodnih procesov, kot so viri podatkov in profiliranje podatkov osvežitve.
Izberite stanje, da odprete podokno Podrobnosti o napredku in si ogledate napredek opravil. Če želite preklicati opravilo, izberite Prekliči opravilo na dnu podokna.
Pod vsakim opravilom lahko izberete Ogled podrobnosti za več informacij o napredku, kot so čas obdelave, zadnji datum obdelave in morebitne veljavne napake in opozorila, povezana z opravilom ali postopkom. Izberite Ogled statusa sistema na dnu plošče, da vidite druge procese v sistemu.
Nalaganje podatkov lahko traja nekaj časa. Po uspešni osvežitvi lahko vnesene podatke pregledate na strani Podatkovne>tabele .
Uredite Azure Data Lake Storage vir podatkov
Posodobite lahko možnost Poveži se z računom za shranjevanje z uporabo možnosti. Za več informacij glejte Povežite se z Azure Data Lake Storage računom z Microsoft Entra načelnikom storitve. Če se želite povezati z drugim vsebnikom iz vašega računa za shranjevanje ali spremeniti ime računa, ustvarite novo vir podatkov povezavo.
Pojdite na Podatki>Viri podatkov. Zraven vir podatkov, ki ga želite posodobiti, izberite Uredi.
Spremenite katerega koli od naslednjih podatkov:
Opis
Povežite svojo shrambo z in informacijami o povezavi. Pri posodabljanju povezave ne morete spremeniti Informacij o vsebniku .
opomba,
Računu za shranjevanje ali vsebniku mora biti dodeljena ena od naslednjih vlog:
- Bralnik podatkov shrambe zbirke dvojiških podatkov
- Lastnik podatkov shrambe zbirke dvojiških podatkov
- Sodelujoči v shrambi zbirke dvojiških podatkov
Uporabite upravljane identitete za Azure z vašim Azure Data Lake Storage ???
Omogočite zasebno povezavo če želite prenesti podatke iz računa za shranjevanje prek zasebne povezave Azure. Za več informacij glejte Zasebne povezave.
Izberite Naprej.
Spremenite kar koli od naslednjega:
Pomaknite se do druge datoteke model.json ali manifest.json z drugačnim nizom tabel iz vsebnika.
Če želite dodati dodatne tabele za vnos, izberite Nova tabela.
Če želite odstraniti že izbrane tabele, če ni odvisnosti, izberite tabelo in Izbriši.
Pomembno
Če obstajajo odvisnosti od obstoječe datoteke model.json ali manifest.json in niza tabel, boste videli sporočilo o napaki in ne boste mogli izbrati druge datoteke model.json ali manifest.json. Odstranite te odvisnosti, preden spremenite datoteko model.json ali manifest.json oziroma ustvarite nov vir podatkov z datoteko model.json ali manifest.json, ki jo želite uporabiti, da se izognete odstranjevanju odvisnosti.
Če želite spremeniti lokacijo podatkovne datoteke ali primarni ključ, izberite Uredi.
Če želite spremeniti inkrementalne podatke o vstavitvi, glejte Konfigurirajte inkrementalno osvežitev za vire podatkov Azure Data Lake.
Spremenite samo ime tabele, da se bo ujemalo z imenom tabele v datoteki .json.
opomba,
Po zaužitju naj bo ime tabele vedno enako imenu tabele v datoteki model.json ali manifest.json. Customer Insights - Data preveri vsa imena tabel z model.json ali manifest.json med vsako osvežitvijo sistema. Če se ime tabele spremeni, pride do napake, ker Customer Insights - Data ne najde novega imena tabele v datoteki .json. Če je bilo ime zaužite tabele pomotoma spremenjeno, uredite ime tabele, da se bo ujemalo z imenom v datoteki .json.
Izberite Stolpci , da jih dodate ali spremenite ali omogočite profiliranje podatkov. Nato izberite Končano.
IzberiteShrani , da uveljavite svoje spremembe in se vrnete na stran Viri podatkov .
Nasvet
Obstajajo statusi za naloge in procese. Večina procesov je odvisnih od drugih predhodnih procesov, kot so viri podatkov in profiliranje podatkov osvežitve.
Izberite stanje, da odprete podokno Podrobnosti o napredku in si ogledate napredek opravil. Če želite preklicati opravilo, izberite Prekliči opravilo na dnu podokna.
Pod vsakim opravilom lahko izberete Ogled podrobnosti za več informacij o napredku, kot so čas obdelave, zadnji datum obdelave in morebitne veljavne napake in opozorila, povezana z opravilom ali postopkom. Izberite Ogled statusa sistema na dnu plošče, da vidite druge procese v sistemu.