Lakehouse tutorial: Ingest data into the lakehouse
In this tutorial, you ingest more dimensional and fact tables from the Wide World Importers (WWI) into the lakehouse.
Prerequisites
- If you don't have a lakehouse, you must create a lakehouse.
Ingest data
In this section, you use the Copy data activity of the Data Factory pipeline to ingest sample data from an Azure storage account to the Files section of the lakehouse you created earlier.
Select Workspaces in the left navigation pane, and then select your new workspace from the Workspaces menu. The items view of your workspace appears.
From the +New menu item in the workspace ribbon, select Data pipeline.
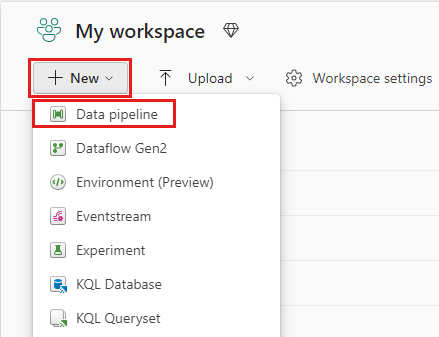
In the New pipeline dialog box, specify the name as IngestDataFromSourceToLakehouse and select Create. A new data factory pipeline is created and opened.
Next, set up an HTTP connection to import the sample World Wide Importers data into the Lakehouse. From the list of New sources, select View more, search for Http and select it.
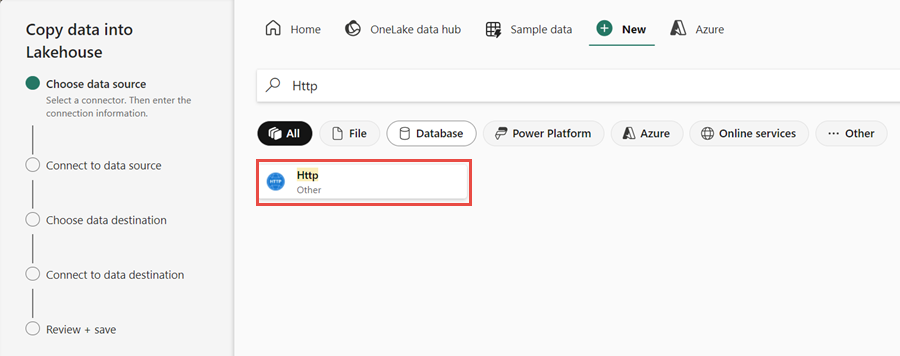
In the Connect to data source window, enter the details from the table below and select Next.
Property Value URL https://assetsprod.microsoft.com/en-us/wwi-sample-dataset.zipConnection Create a new connection Connection name wwisampledata Data gateway None Authentication kind Anonymous 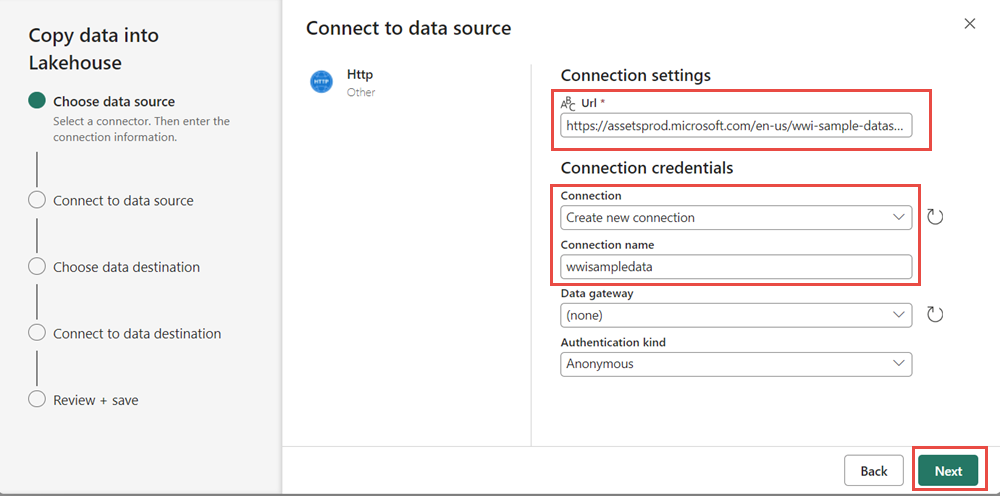
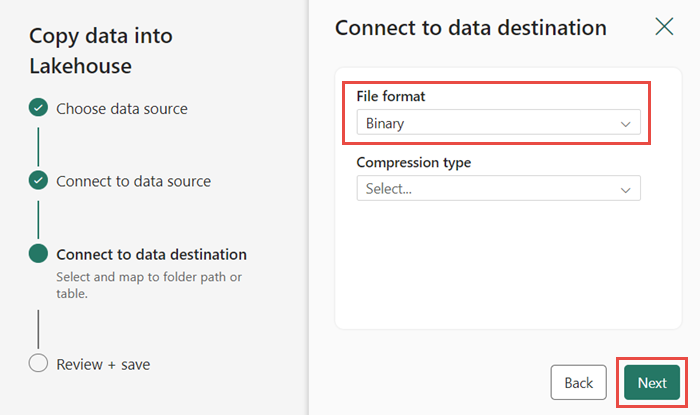
In the next step, enable the Binary copy and choose ZipDeflate (.zip) as the Compression type since the source is a .zip file. Keep the other fields at their default values and click Next.
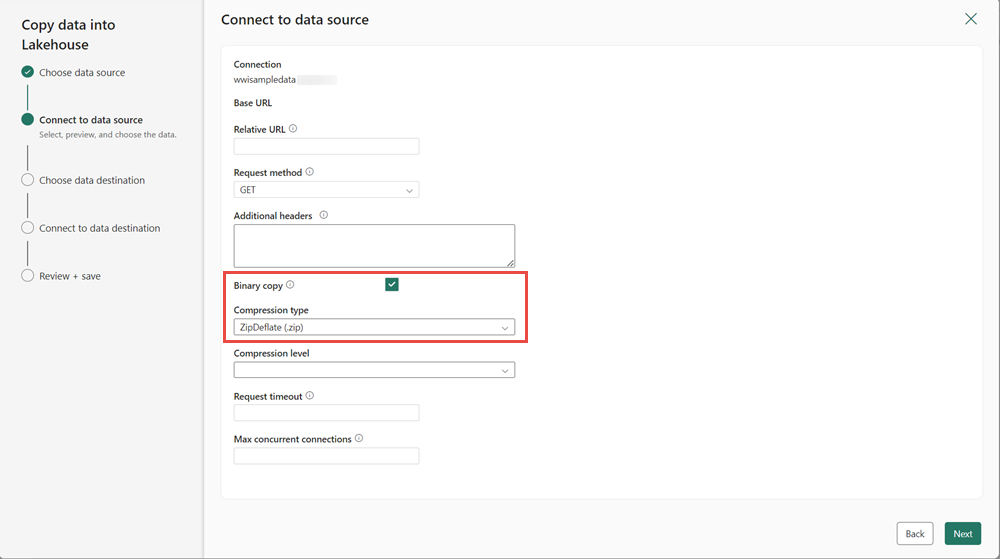
In the Connect to data destination window, specify the Root folder as Files and click Next. This will write the data to the Files section of the lakehouse.
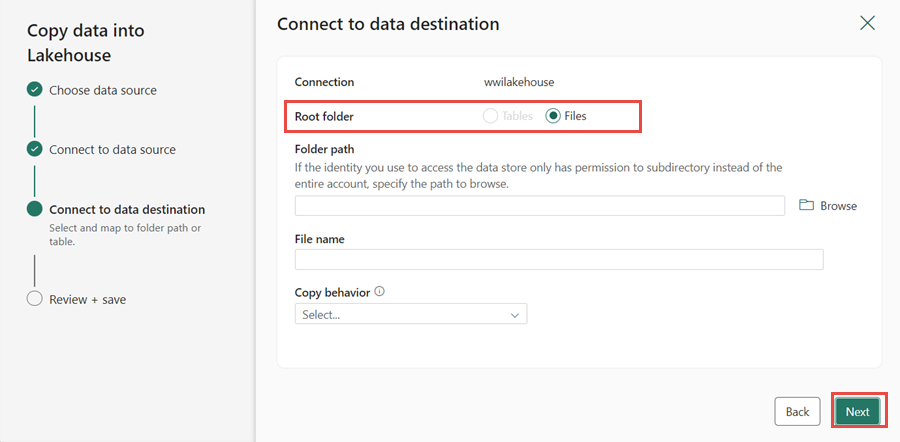
Choose the File format as Binary for the destination. Click Next and then Save+Run. You can schedule pipelines to refresh data periodically. In this tutorial, we only run the pipeline once. The data copy process takes approximately 10-15 minutes to complete.
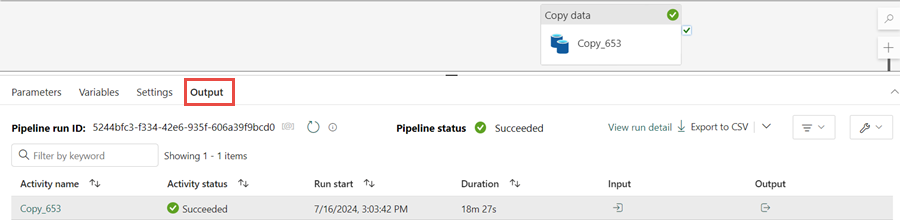
You can monitor the pipeline execution and activity in the Output tab. You can also view detailed data transfer information by selecting the glasses icon next to the pipeline name, which appears when you hover over the name.
After the successful execution of the pipeline, go to your lakehouse (wwilakehouse) and open the explorer to see the imported data.
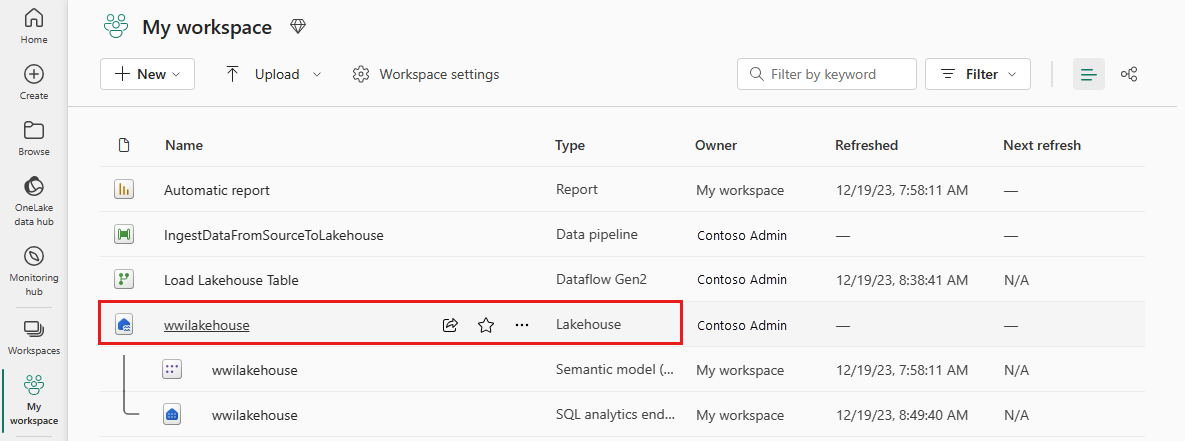
Verify that the folder WideWorldImportersDW is present in the Explorer view and contains data for all tables.
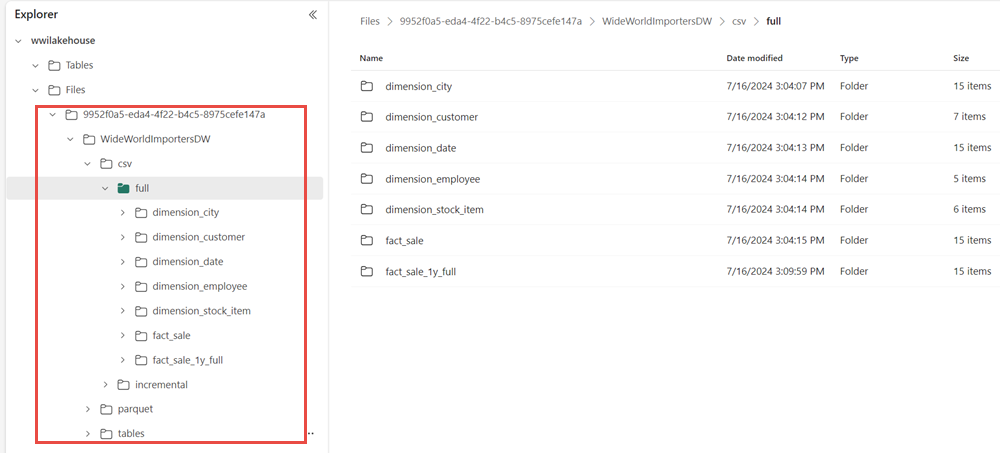
The data is created under the Files section of the lakehouse explorer. A new folder with GUID contains all the needed data. Rename the GUID to wwi-raw-data
To load incremental data into a lakehouse, see Incrementally load data from a data warehouse to a lakehouse.
Next step
Povratne informacije
Kmalu na voljo: V letu 2024 bomo ukinili storitev Težave v storitvi GitHub kot mehanizem za povratne informacije za vsebino in jo zamenjali z novim sistemom za povratne informacije. Za več informacij si oglejte: https://aka.ms/ContentUserFeedback.
Pošlji in prikaži povratne informacije za