Opomba
Dostop do te strani zahteva pooblastilo. Poskusite se vpisati alispremeniti imenike.
Dostop do te strani zahteva pooblastilo. Poskusite lahko spremeniti imenike.
[Ta članek je del predizdajne dokumentacije in se lahko spremeni.]
Novi optimizirani semantični model DirectLake vodi do hitrejše in pomnilniško učinkovitejše analize procesov. Z varčevanjem pomnilnika lahko analizirate večje procese in prihranite stroške z uporabo manjših zmogljivosti Fabric za izvajanje analiz. Poleg tega se uporablja bolj intuitivna Power BI semantična podatkovna struktura modela, ki vam omogoča, da se poglobite v vpoglede z manj časa in truda.
Pomembno
- To je funkcija predogleda.
- Poskusne funkcije niso za komercialno uporabo, njihovo delovanje je lahko omejeno. Te funkcije so na voljo še pred uradno izdajo, da lahko stranke predčasno dostopajo do njih in posredujejo povratne informacije.
- Za več informacij si oglejte naše pogoje predogleda .
Opis semantičnega modela
Ko je proces objavljen v delovnem prostoru Fabric, ustvari nov semantični model in ustrezno poročilo. Ta posnetek zaslona je primer strukture semantične modela, objavljene v storitvi Fabric.
Izberite povečevalno steklo v spodnjem desnem kotu slike, da jo povečate.

Relacije
Razmerja, potrebna za filtriranje in medsebojno povezljivost vizualnih elementov, so vnaprej določena v objavljenem podatkovnem modelu. Ni treba ročno ustvarjati dodatnih relacij, razen če so povezani drugi viri podatkov. V tem scenariju uporabite sestavljeni semantični model in na njem zgradite odnose. Power BI
Povzetek podatkovnega modela
Z logičnega vidika je podatkovni model sestavljen iz številnih podmnožic entitet, kot je prikazano v prvem odstavku tega razdelka.
- Procesni podatki: Vsi s procesom povezani podatki brez filtriranja in izračunanih meritev
- Podatki vizualnih elementov: Entitete, ki zagotavljajo vnaprej izračunane podatke, potrebne za prikaz vizualnih elementov po meri za rudarjenje procesov
- Pomagajoči subjekti: Drugi subjekti, ki jih potrebuje Power BI
Sledi kratek opis podmnožic in vključenih entitet.
Procesni podatki
Vsebina entitet procesnih podatkov se spreminja v določenih scenarijih.
- Ko se podatki modela procesa osvežijo
- Ko je ustvarjen nov pogled
- Ko je ustvarjena nova meritev po meri
- Ko uporabnik spremeni definicijo filtriranja v katerem koli pogledu procesa
Delo s temi subjekti vam omogoča:
- Dostop do surovih procesnih podatkov
- Procesni podatki, na katere vplivajo uporabljeni filtri
- Dostop do mer, izračunanih na podlagi uporabljenih filtrov
| Entity | Description |
|---|---|
| Primeri | Seznam vseh primerov in njihovih atributov v postopku. Vsak primer vsebuje edinstven prikaz ID-ja primera in vrednosti za vsak od atributov primera, kot je določeno v koraku nastavitve preslikave. Za pridobitev popolnih informacij o primeru združite z entiteto CaseMetrics . |
| Dogodki | Seznam vseh atributov dogodkov v procesu. Vsak dogodek ima edinstven indeks identifikatorja dogodka in vrednosti za vsak od atributov dogodka, kot je določeno v koraku nastavitve preslikave. Združite z entiteto ProcessMapMetrics , filtrirano po stolpcu Is_Node , da dobite popolne informacije o dogodku. |
| CaseMetrics | Entiteta vsebuje vse metrike na ravni primera, povezane z določeno kombinacijo primera in pogleda. Tej entiteti so dodane meritve po meri na ravni primera, določene v Power Automate namizni aplikaciji Process Mining. |
| AtributiMetapodatki | Entiteta vsebuje definicijo vseh atributov na ravni primera/dogodka, kot so opredeljeni pri uvozu podatkov dnevnika dogodkov v model procesa. Vključuje njegov podatkovni tip, tip atributa in raven atributa, ki je bodisi primer bodisi dogodek. |
| Atributi rudarjenja | Vsebuje vrednosti razpoložljivih atributov rudarjenja. Pogled na proces je mogoče nastaviti tako, da si proces ogledate z različnih zornih kotov glede na izbrani atribut rudarjenja. Če ni na voljo noben drug atribut rudarjenja, entiteta hrani vrednosti atributa Activity . |
| Ogledi | Seznam razpoložljivih (objavljenih) pogledov, ustvarjenih v namizni aplikaciji Process Mining. Power Automate V naboru podatkov so objavljeni samo javni pogledi procesov. Vnose je mogoče uporabiti za filtriranje poročila, strani poročila in vizualnega prikaza za vizualizacijo samo podatkov iz določenega pogleda procesa. |
| Različice | Entiteta vsebuje relacije med različicami in pogledi na proces. Zapis je vključen, če je določena različica vključena v pogled po upoštevanju meril filtriranja. |
Vizualni podatki
Vizualne podatkovne entitete se preračunajo le, če pride do osvežitve podatkov za model procesa.
| Entity | Description |
|---|---|
| Metrike zemljevida procesov | Združene mere za vsa vozlišča in prehode v modelu procesa, ki so potrebne za vizualizacijo v prilagojenem vizualnem elementu zemljevida procesa. Ta entiteta združuje informacije o dogodkih (vozliščih) in informacije o robovih (prehodih) – če želite dogodke ali robove uporabiti v drugih vizualnih elementih, filtrirajte po vrednosti v stolpcu Is_Node .
Tej entiteti so dodane meritve po meri na ravni dogodkov, določene v Power Automate namizni aplikaciji Process Mining. |
Drugi subjekti
| Entity | Description |
|---|---|
| Lokalizacijska tabela | Notranja tabela, ki se uporablja za lokalizacijo. |
Power BI sestavljeni model
Priporočamo, da uporabite sestavljeni model poleg semantičnega modela, ki ga je objavil Power BI Process Mining, in tam ustvarite potrebne spremembe za te scenarije: Power Automate
- Ustvariti morate več virov podatkov
- Ustvariti morate več entitet
- Ustvariti morate več odnosov
- Ustvariti morate več poizvedb DAX (izrazi za analizo podatkov) po meri
Pomembno
Semantični model je ustvarjen v načinu dostopa DirectLake, vendar je njegova možnost nastavljena na Samodejno. Ta nastavitev pomeni, da lahko uporaba neoptimalnih poizvedb DAX ali nepravilna nastavitev sestavljenega modela povzroči vrnitev v način DirectQuery. To pomeni, da vaše poročilo ne bo delovalo pravilno, vendar boste morda opazili slabšo učinkovitost delovanja.
Če želite izvedeti več o ustvarjanju Power BI sestavljeni podatkovni modeli na vrhu semantičnih modelov DirectLake, pojdite na: Gradnja sestavljenih modelov na semantičnem modelu ali modelu.
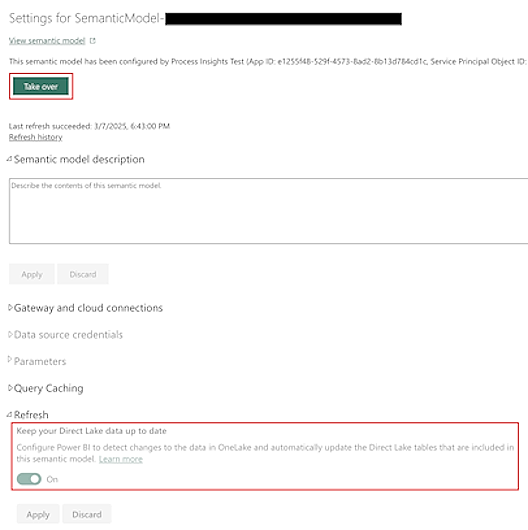
Osvežitev semantičnega modela
Privzeto semantični model, ki ga zagotavlja Power Automate Procesno rudarjenje se samodejno posodablja.
Pri velikih naborih podatkov lahko osvežitev podatkov osnovnih tabel v OneLake traja dlje. To lahko povzroči morebitne neskladnosti v poročilu. Čeprav na koncu osvežitve podatkov obstaja končna doslednost (semantični model se izrecno osveži), boste morda želeli odstraniti morebitne vmesne nedoslednosti tako, da na zaslonu z nastavitvami semantičnega modela izklopite zastavico Poskrbite za posodobljene podatke Direct Lake .
Preden posodobite ta zaslon, morate prevzeti odgovornost za semantični model tako, da na vrhu zaslona z nastavitvami izberete možnost Prevzemi.