Copy data from Cassandra using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the Copy Activity in an Azure Data Factory or Synapse Analytics pipeline to copy data from a Cassandra database. It builds on the copy activity overview article that presents a general overview of copy activity.
Supported capabilities
This Cassandra connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources/sinks, see the Supported data stores table.
Specifically, this Cassandra connector supports:
- Cassandra versions 2.x and 3.x.
- Copying data using Basic or Anonymous authentication.
Note
For activity running on Self-hosted Integration Runtime, Cassandra 3.x is supported since IR version 3.7 and above.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allow list.
You can also use the managed virtual network integration runtime feature in Azure Data Factory to access the on-premises network without installing and configuring a self-hosted integration runtime.
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
The Integration Runtime provides a built-in Cassandra driver, therefore you don't need to manually install any driver when copying data from/to Cassandra.
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service to Cassandra using UI
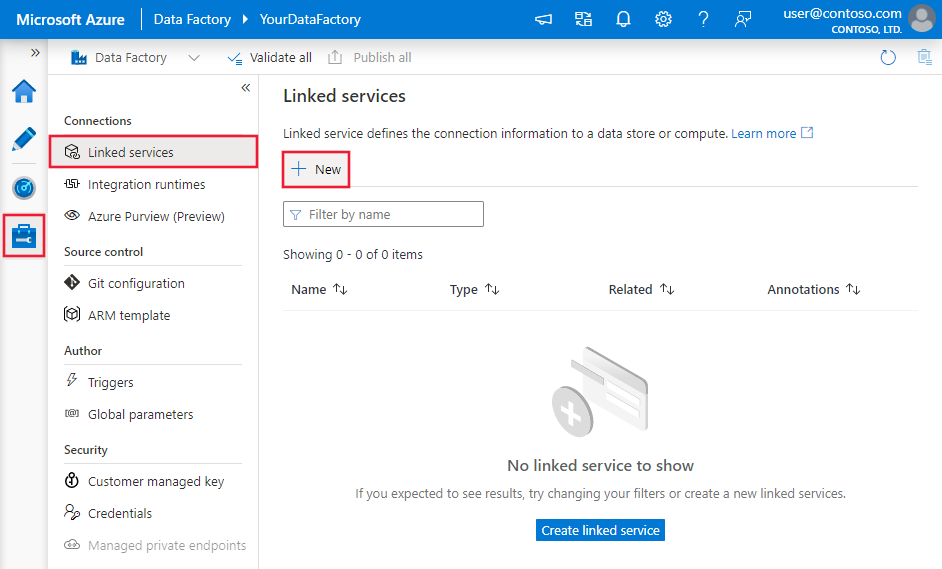
Use the following steps to create a linked service to Cassandra in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Cassandra and select the Cassandra connector.
Configure the service details, test the connection, and create the new linked service.

Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to Cassandra connector.
Linked service properties
The following properties are supported for Cassandra linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to: Cassandra | Yes |
| host | One or more IP addresses or host names of Cassandra servers. Specify a comma-separated list of IP addresses or host names to connect to all servers concurrently. |
Yes |
| port | The TCP port that the Cassandra server uses to listen for client connections. | No (default is 9042) |
| authenticationType | Type of authentication used to connect to the Cassandra database. Allowed values are: Basic, and Anonymous. |
Yes |
| username | Specify user name for the user account. | Yes, if authenticationType is set to Basic. |
| password | Specify password for the user account. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. | Yes, if authenticationType is set to Basic. |
| connectVia | The Integration Runtime to be used to connect to the data store. Learn more from Prerequisites section. If not specified, it uses the default Azure Integration Runtime. | No |
Note
Currently connection to Cassandra using TLS is not supported.
Example:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the datasets article. This section provides a list of properties supported by Cassandra dataset.
To copy data from Cassandra, set the type property of the dataset to CassandraTable. The following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to: CassandraTable | Yes |
| keyspace | Name of the keyspace or schema in Cassandra database. | No (if "query" for "CassandraSource" is specified) |
| tableName | Name of the table in Cassandra database. | No (if "query" for "CassandraSource" is specified) |
Example:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by Cassandra source.
Cassandra as source
To copy data from Cassandra, set the source type in the copy activity to CassandraSource. The following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to: CassandraSource | Yes |
| query | Use the custom query to read data. SQL-92 query or CQL query. See CQL reference. When using SQL query, specify keyspace name.table name to represent the table you want to query. |
No (if "tableName" and "keyspace" in dataset are specified). |
| consistencyLevel | The consistency level specifies how many replicas must respond to a read request before returning data to the client application. Cassandra checks the specified number of replicas for data to satisfy the read request. See Configuring data consistency for details. Allowed values are: ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM, and LOCAL_ONE. |
No (default is ONE) |
Example:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Data type mapping for Cassandra
When copying data from Cassandra, the following mappings are used from Cassandra data types to interim data types used internally within the service. See Schema and data type mappings to learn about how copy activity maps the source schema and data type to the sink.
| Cassandra data type | Interim service data type |
|---|---|
| ASCII | String |
| BIGINT | Int64 |
| BLOB | Byte[] |
| BOOLEAN | Boolean |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Single |
| INET | String |
| INT | Int32 |
| TEXT | String |
| TIMESTAMP | DateTime |
| TIMEUUID | Guid |
| UUID | Guid |
| VARCHAR | String |
| VARINT | Decimal |
Note
For collection types (map, set, list, etc.), refer to Work with Cassandra collection types using virtual table section.
User-defined types are not supported.
The length of Binary Column and String Column lengths cannot be greater than 4000.
Work with collections using virtual table
The service uses a built-in ODBC driver to connect to and copy data from your Cassandra database. For collection types including map, set and list, the driver renormalizes the data into corresponding virtual tables. Specifically, if a table contains any collection columns, the driver generates the following virtual tables:
- A base table, which contains the same data as the real table except for the collection columns. The base table uses the same name as the real table that it represents.
- A virtual table for each collection column, which expands the nested data. The virtual tables that represent collections are named using the name of the real table, a separator "vt" and the name of the column.
Virtual tables refer to the data in the real table, enabling the driver to access the de-normalized data. See Example section for details. You can access the content of Cassandra collections by querying and joining the virtual tables.
Example
For example, the following "ExampleTable" is a Cassandra database table that contains an integer primary key column named "pk_int", a text column named value, a list column, a map column, and a set column (named "StringSet").
| pk_int | Value | List | Map | StringSet |
|---|---|---|---|---|
| 1 | "sample value 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "sample value 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
The driver would generate multiple virtual tables to represent this single table. The foreign key columns in the virtual tables reference the primary key columns in the real table, and indicate which real table row the virtual table row corresponds to.
The first virtual table is the base table named "ExampleTable" is shown in the following table:
| pk_int | Value |
|---|---|
| 1 | "sample value 1" |
| 3 | "sample value 3" |
The base table contains the same data as the original database table except for the collections, which are omitted from this table and expanded in other virtual tables.
The following tables show the virtual tables that renormalize the data from the List, Map, and StringSet columns. The columns with names that end with "_index" or "_key" indicate the position of the data within the original list or map. The columns with names that end with "_value" contain the expanded data from the collection.
Table "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Table "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | A |
| 1 | S2 | b |
| 3 | S1 | t |
Table "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | A |
| 1 | B |
| 1 | C |
| 3 | A |
| 3 | E |
Lookup activity properties
To learn details about the properties, check Lookup activity.
Related content
For a list of data stores supported as sources and sinks by the copy activity, see supported data stores.