Plan, scale, and maintain a business-critical gateway solution
This article is intended for anyone planning to deploy an on-premises data gateway in a business-critical scenario. An on-premises data gateway is business-critical if it's vital to the normal operation of your business and handles business-critical data.
If business-critical gateways aren't managed properly, you might experience failed queries or slow performance. When you properly plan, scale, and maintain your business-critical gateway solution, the likelihood of a business-impacting issue can be minimized.
Terminology
The following important terms are used throughout this article:
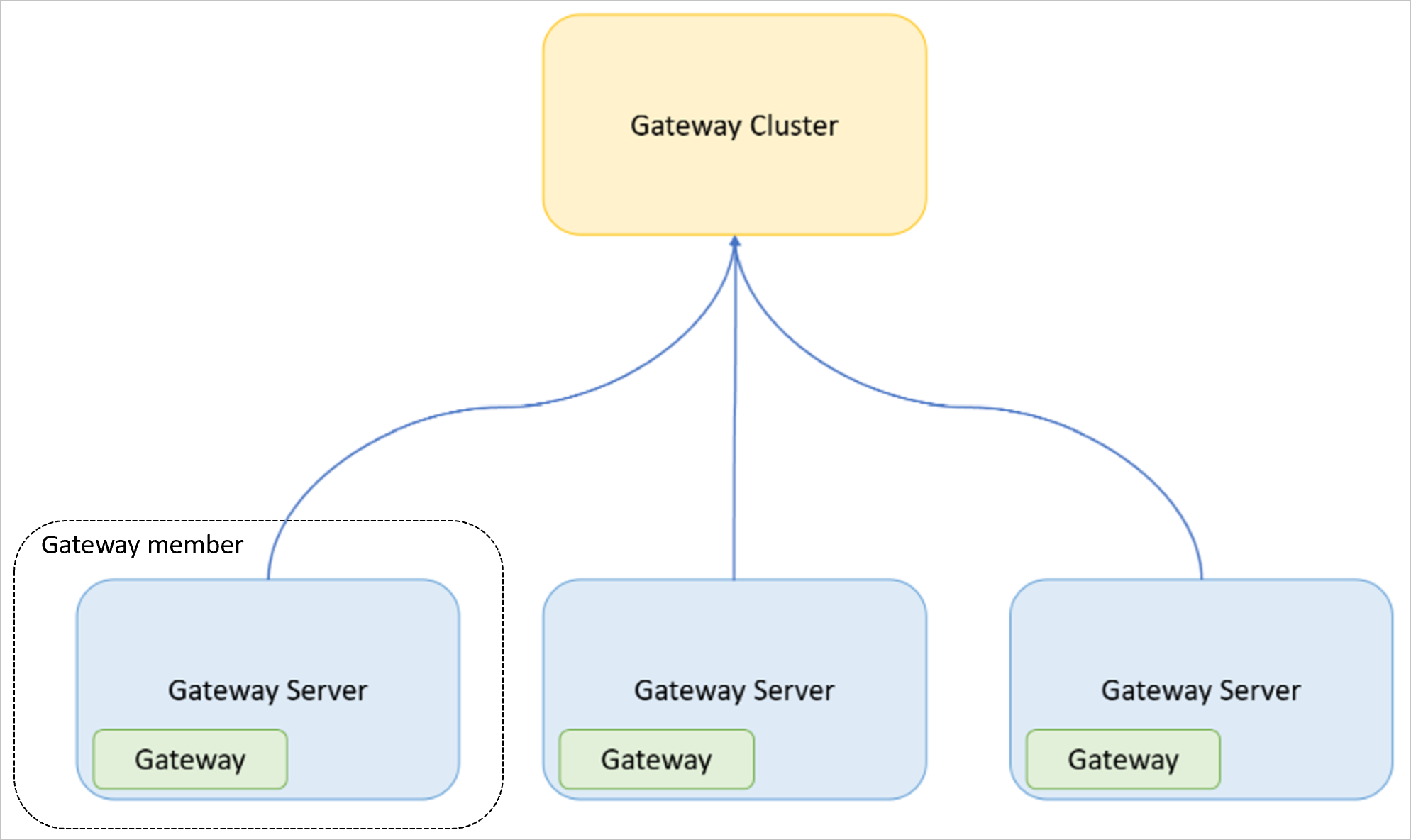
- Gateway: The on-premises data gateway application that's installed on a computer.
- Gateway server: A Windows computer (virtual machine or physical computer/server) that has the on-premises data gateway application installed.
- Gateway cluster: A set of gateways that work together (and might be load balanced).
- Gateway member: A gateway that's a part of a gateway cluster.
The following image demonstrates the relationship between the concepts defined above.
Recommendations for business-critical gateways
For business-critical gateways, the gateways need to be deployed and managed properly to ensure high availability, good performance, and maintainable scalability. Deploying gateways incorrectly might result in poor performance, failed queries, and difficulty in diagnosing potential issues. It might also impede your ability to scale the gateways up and out as usage grows.
To ensure optimal scalability, performance, and throughput, follow the recommendations in the next sections.
Know all your gateway recovery keys
Ensure that all gateway recovery keys are known and kept in a safe place. Without a recovery key, gateways can't be recovered or downgraded. This limitation is by design. If you lose your recovery keys, the only option is to create new gateways and recreate the data sources. Also, you can't add new gateways to the cluster without the recovery key, which would limit future scalability.
Store your recovery keys in a secure place just as you would store administrative credentials, such as a password safe, which can be accessed only by authorized administrators.
If you currently don't know all your gateway recovery keys, this is a significant business risk. Immediately create new gateway clusters and start migrating workloads to the gateway clusters.
Development workloads and business-critical workloads
Separate development workloads from business-critical ones by setting up one or more development gateway clusters and one or more production gateway clusters as described below.
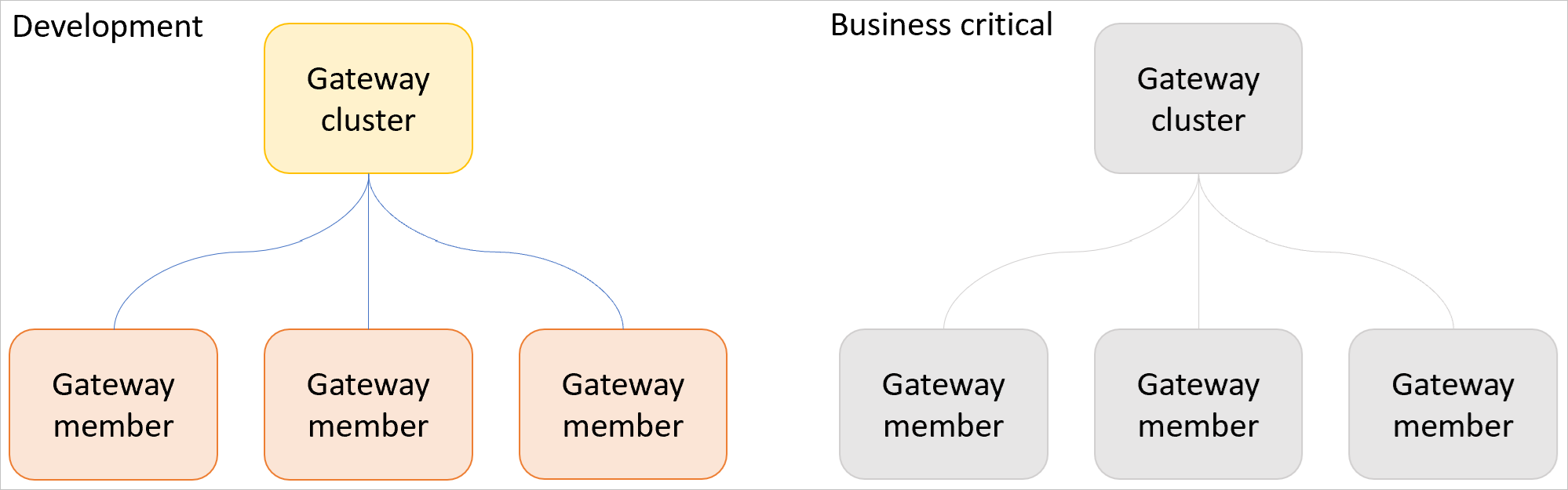
Use a development gateway cluster to test out new semantic models, reports, queries, and so on. Once a new workload has been verified, migrate it to a business-critical gateway cluster. This process prevents new, untested, or experimental workloads from having performance impacts on productions workloads.
Also use your development gateway cluster(s) to test new gateway updates before applying updates to your business-critical gateway clusters. New gateway updates should be deployed for a minimum of 24 hours in the development gateway cluster(s) before being used on business-critical gateway cluster(s).
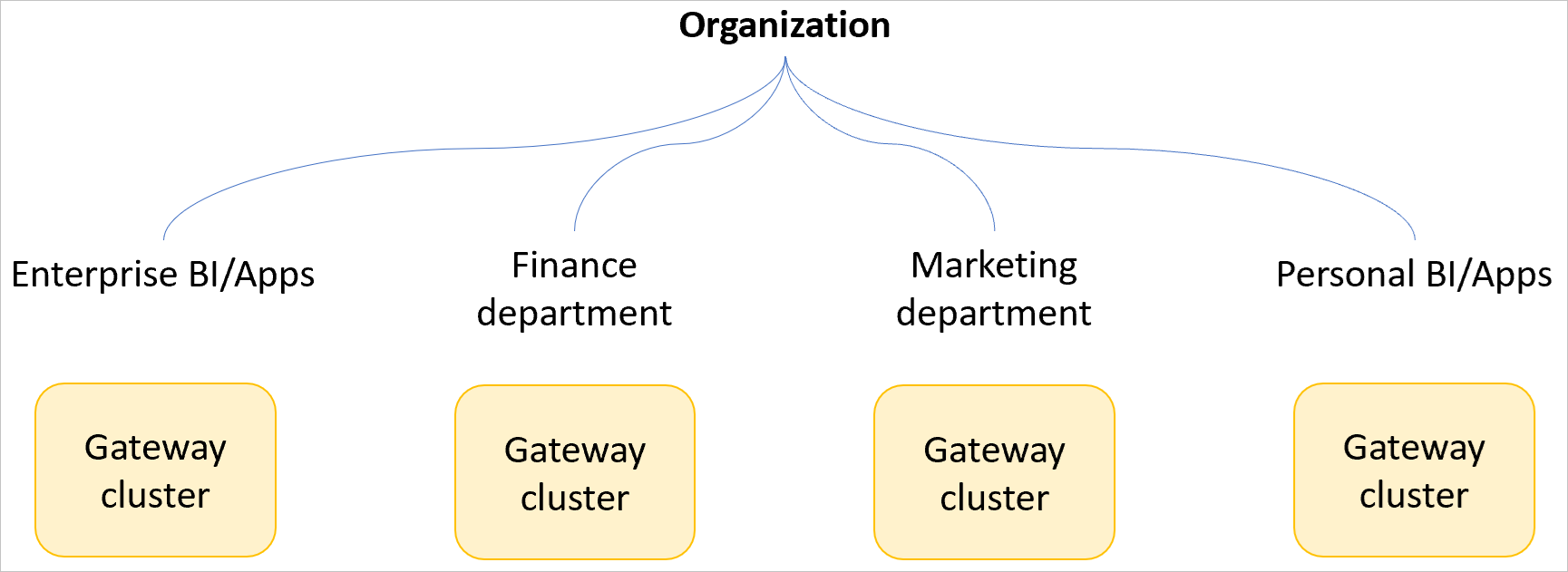
Use multiple gateway clusters
If you're creating a gateway cluster for a large number of users in your organization, you need to create multiple gateway clusters based on business units or smaller to limit any potential performance impact to a small subset of users.
We don't recommend that a single business-critical gateway cluster be used for an entire company (unless the company is small). In a single gateway cluster scenario, one user could conceivably send a query that causes a significant performance impact to all traffic across the gateway. If the gateway is used across the entire company, the performance impact could affect the entire company. Also, when a gateway cluster is used across an entire company, it might be more difficult for you to identify which query might be causing a performance problem when using the gateway performance monitoring feature.
Use the gateway high availability and load balancing features
Always use the gateway high availability and load balancing features for any business-critical gateway cluster.
- High availability: Eliminates having a single point of failure.
- Load balancing: Automatically distributes the workload across all gateway servers in the cluster.
Set up a minimum of two gateways per gateway cluster in case a gateway goes offline for any reason. This setup ensures that a single gateway failure doesn't cause the entire gateway cluster to fail. Additionally, CPU, memory, concurrency limits can be enabled on the gateways to better distribute the load across the gateway cluster.
Plan and maintain gateway cluster scalability
Setting up a gateway cluster using our recommended hardware and software guidelines ensures the cluster runs with good performance. Gateways that aren't scaled properly might result in poor performance. There are many factors you must consider to have good performance on your gateway cluster.
Determine gateway server hardware specifications
Gateway server specifications (CPU, memory, disk, and so on) are an important factor, as in most cases, the Power Query transformations are applied to the data on the gateway server. As such, a gateway server needs to have enough resources, memory, and processing power to handle all the data transformations.
When you need to choose a server size, there are two metrics that are most important: Memory and CPU. You need both ample memory and CPU power to process the Power Query data transformation steps on the gateway. It's important that your gateway server is powerful enough to process the highest workload that you have. If the gateway server isn't able to handle the workload, your direct query or data refresh will fail. It's also important to understand how many queries are executed at the same time.
These different query options have a different effect on your gateway server.
| Query Type | Limit Factor |
|---|---|
| Import | Memory |
| DirectQuery | CPU |
| LiveConnect | CPU |
During an import, the entire set of data needs to be queried and processed, which is a memory heavy task. This importation often takes a longer time as well. DirectQueries and LiveConnections are commonly CPU heavy. In most cases, direct queries are executed many times to process only a small portion of the data. Since only a small portion of the data is processed, these direct queries aren't normally a memory heavy task. However, because the queries get executed many times on demand, this can be CPU intensive.
Depending on your workload, consider optimizing your gateway server for memory or CPU.
When to scale a gateway cluster
Scaling is an important aspect of a business-critical gateway cluster. As your usage with the gateway cluster grows, the gateway cluster needs to be scaled up and/or scaled out to ensure good performance. We recommend that you start scaling out a gateway cluster if you've previously scaled up the gateways in the cluster.
Scaling and distributing traffic load across individual nodes within a cluster is a complex process that varies depending on each individual scenario. While there's no definitive model to ensure that all gateway traffic will be predictably serviced, the limits listed below indicate a scaling need. In general, we recommend scaling out (adding nodes to the cluster) preferentially to scaling up (increasing CPU, RAM, or disk space on individual nodes). Scaling out tends to be more effective overall in the ability of the system as a whole to handle extra traffic. Scaling out also has a positive impact on total bandwidth the cluster can process, whereas scaling up generally doesn't. When one or more gateway nodes show indications of reaching the thresholds described below, scaling out the cluster should be strongly considered.
CPU: CPU is above 80% for extended periods of time, however occasional short (under 5 minutes) spikes that max out CPUs aren't abnormal.
RAM: Available memory dips below 20% regularly.
Disk: Free disk space dips below 5 GB frequently. This dip could also indicate a need to configure caching or spooling directories more strategically.
Concurrency: Running more than 40 queries simultaneously on a single node.
Since refreshes and queries distributed across gateway nodes can have vastly different profiles, we also recommend extra scrutiny be placed on long-running or memory-intensive jobs. Query optimization in such cases can have a huge impact on performance and scalability, not only for the individual reports and refreshes, but on the system as a whole. We recommend isolating refreshes in question to a single dedicated gateway cluster to evaluate performance characteristics and perform optimization using query plan diagnostics, folding indicators, and all other published performance recommendations. This isolation minimizes the amount of data retrieved and the amount of post-processing required. This isolation can also be used as a long-term strategy to sequester long-running ETL jobs to a dedicated gateway cluster in order to reduce contention with other typical refreshes across the organization.
Scaling up a gateway cluster
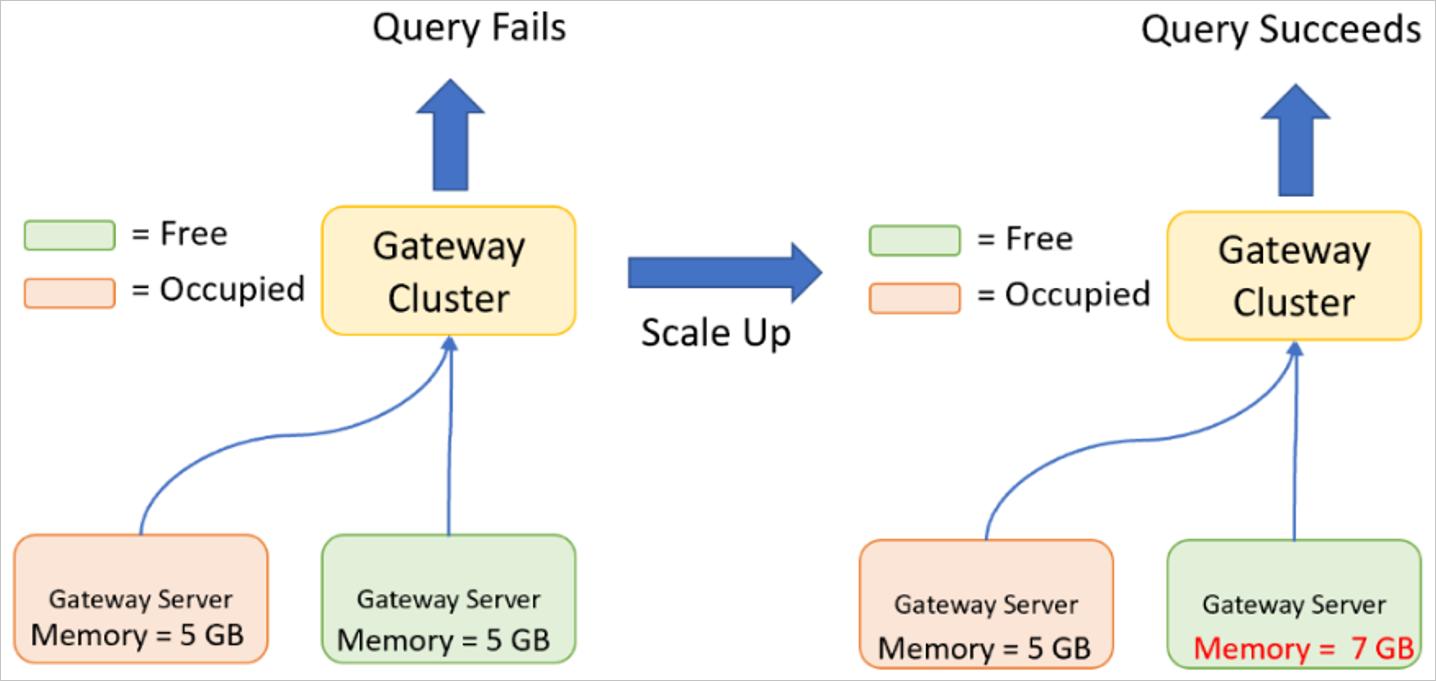
Scaling up is when you increase the specifications (CPU, memory, disk, and so on) of your gateway servers.
Scaling up might be required if the maximum CPU or memory is reached when the gateway executes one or more queries. A query can only be executed on one gateway server, which is why the gateway server must have enough resources available to process the entire query along with the resulting data.
Scaling out a gateway cluster
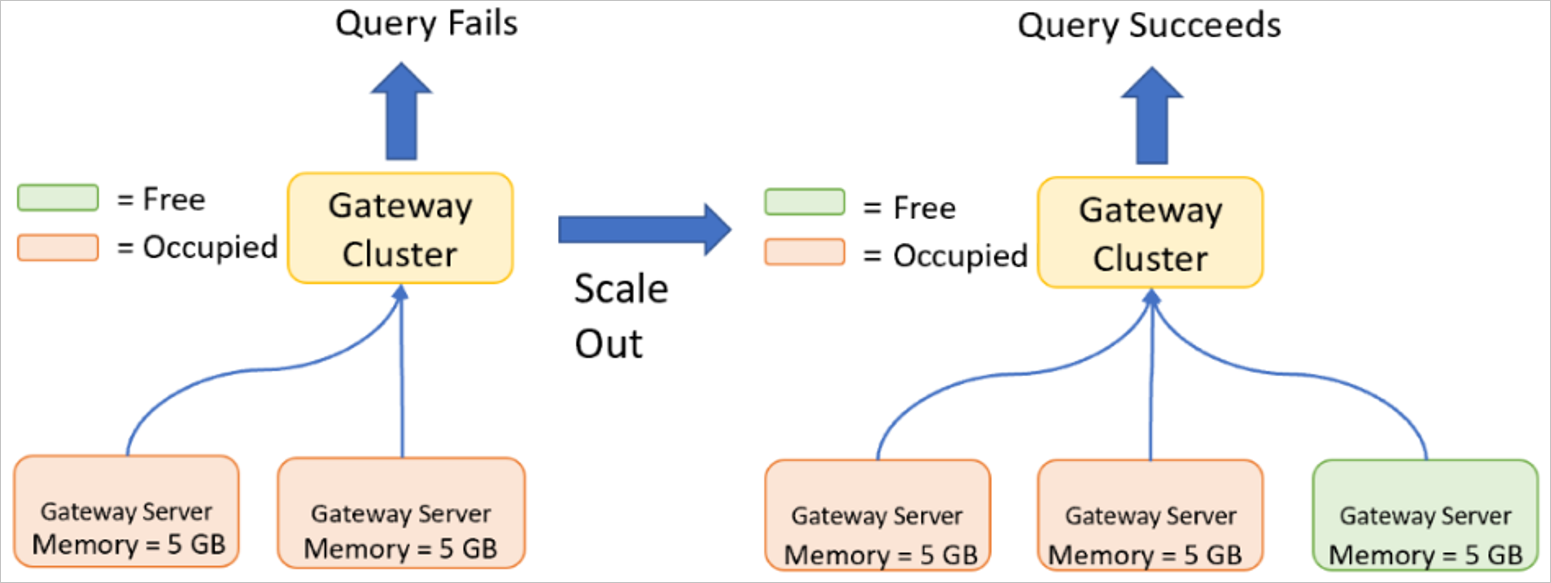
Scaling out is required if the gateway server already has high specifications (in other words, the gateway server has been scaling up already), or you've reached the limits of what a single gateway server can manage because of the number of concurrent queries being executed. Broad-based load increase across the entire gateway member set is a good indication that scaling a cluster by adding nodes is the correct course of action. When to scale a gateway cluster provides specific thresholds that indicate when it's time to scale. For more information about scaling out, go to Use the gateway high availability and load balancing features.
Scaling by creating new gateway clusters
If the resource usage of your gateway cluster is high or an exceptionally large number of users rely on a gateway cluster, a new gateway cluster can be created. A subset of the workload can then be migrated to the new gateway cluster. When a large number of users rely on a single gateway cluster, the likelihood a user could send a query that causes a significant performance impact across the entire gateway cluster increases significantly.
An exceptionally large number of users relying on a single gateway cluster is an indicator that a new gateway cluster should be created.
Monitoring and troubleshooting gateway performance
It's important to monitor the overall performance of business-critical gateways using the gateway performance monitoring feature. You can also use this feature to troubleshoot performance problems, identify bottlenecks, and identify queries that are impacting overall gateway performance. This feature is also an important tool in helping you determine when to scale a gateway cluster.
If you identify a query as having a heavy impact on the gateway resulting in poor overall performance, you might be able to rewrite the query to be more efficient and minimize the performance impact.
If Microsoft identifies poor performance caused by a gateway or a gateway-related component, such as a Power BI Premium Capacity that's overloaded, the overloaded component must be remedied by scaling or reducing load. Microsoft doesn't investigate poor performance when a gateway or a gateway-related component is overloaded.