Multivariate Anomaly Detection
For general information about multivariate anomaly detection in Real-Time Intelligence, see Multivariate anomaly detection in Microsoft Fabric - overview. In this tutorial, you'll use sample data to train a multivariate anomaly detection model using the Spark engine in a Python notebook. You'll then predict anomalies by applying the trained model to new data using the Eventhouse engine. The first few steps set up your environments, and the following steps train the model and predict anomalies.
Prerequisites
- A workspace with a Microsoft Fabric-enabled capacity
- Role of Admin, Contributor, or Member in the workspace. This permission level is needed to create items such as an Environment.
- An eventhouse in your workspace with a database.
- Download the sample data from the GitHub repo
- Download the notebook from the GitHub repo
Part 1- Enable OneLake availability
OneLake availability must be enabled before you get data in the Eventhouse. This step is important, because it enables the data you ingest to become available in the OneLake. In a later step, you access this same data from your Spark Notebook to train the model.
Browse to your workspace homepage in Real-Time Intelligence.
Select the Eventhouse you created in the prerequisites. Choose the database where you want to store your data.
In the Database details tile, select the pencil icon next to OneLake availability
In the right pane, toggle the button to Active.
Select Done.

Part 2- Enable KQL Python plugin
In this step, you enable the python plugin in your Eventhouse. This step is required to run the predict anomalies Python code in the KQL queryset. It's important to choose the correct package that contains the time-series-anomaly-detector package.
In the Eventhouse screen, select your database, then select Manage > Plugins from the ribbon..
In the Plugins pane, toggle the Python language extension to to On.
Select Python 3.11.7 DL (preview).
Select Done.

Part 3- Create a Spark environment
In this step, you create a Spark environment to run the Python notebook that trains the multivariate anomaly detection model using the Spark engine. For more information on creating environments, see Create and manage environments.
In the experience switcher, choose Data Engineering. If you're already in the Data Engineering experience, browse to Home.
From Recommended items to create, Select Environments, and enter the name MVAD_ENV for the environment.

Under Libraries, select Public libraries.
Select Add from PyPI.
In the search box, enter time-series-anomaly-detector. The version automatically populates with the most recent version. This tutorial was created using version 0.2.7, which is the version included in the Kusto Python 3.11.7 DL.
Select Save.
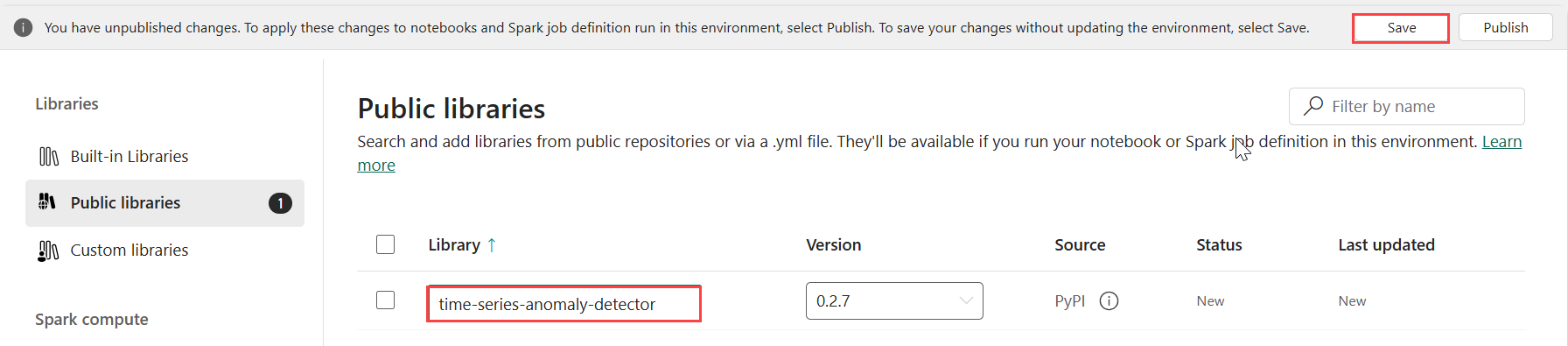
Select the Home tab in the environment.
Select the Publish icon from the ribbon.

Select Publish all. This step can take several minutes to complete.
Part 4- Get data into the Eventhouse
Hover over the KQL database where you want to store your data. Select the More menu [...] > Get data > Local file.

Select + New table and enter demo_stocks_change as the table name.
In the upload data dialog, select Browse for files and upload the sample data file that was downloaded in the Prerequisites
Select Next.
In the Inspect the data section, toggle First row is column header to On.
Select Finish.
When the data is uploaded, select Close.
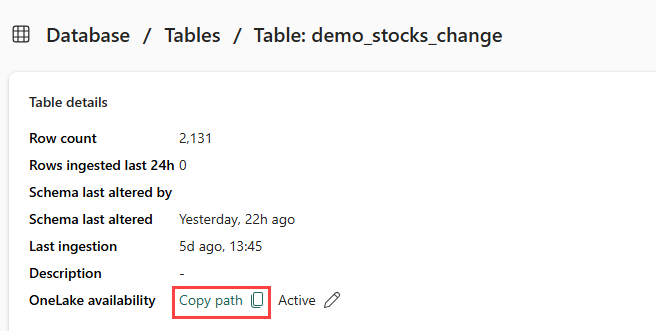
Part 5- Copy OneLake path to the table
Make sure you select the demo_stocks_change table. In the Table details tile, select Copy path to copy the OneLake path to your clipboard. Save this copied text in a text editor somewhere to be used in a later step.
Part 6- Prepare the notebook
In the experience switcher, choose Develop and select your workspace.
Select Import, Notebook, then From this computer.
Select Upload, and choose the notebook you downloaded in the prerequisites.
After the notebook is uploaded, you can find and open your notebook from your workspace.
From the top ribbon, select the Workspace default dropdown and select the environment you created in the previous step.

Part 7- Run the notebook
Import standard packages.
import numpy as np import pandas as pdSpark needs an ABFSS URI to securely connect to OneLake storage, so the next step defines this function to convert the OneLake URI to ABFSS URI.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriInput your OneLake URI copied from Part 5- Copy OneLake path to the table to load demo_stocks_change table into a pandas dataframe.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Run the following cells to prepare the training and prediction dataframes.
Note
The actual predictions will be run on data by the Eventhouse in part 9- Predict-anomalies-in-the-kql-queryset. In a production scenario, if you were streaming data into the eventhouse, the predictions would be made on the new streaming data. For the purpose of the tutorial, the dataset has been split by date into two sections for training and prediction. This is to simulate historical data and new streaming data.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Run the cells to train the model and save it in Fabric MLflow models registry.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )# Extract the registered model path to be used for prediction using Kusto Python sandbox mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Copy the model URI from the last cell output. You'll use this in a later next step.
Part 8- Set up your KQL queryset
For general information, see Create a KQL queryset.
- In the experience switcher, choose Real-Time Intelligence.
- Select your workspace.
- Select +New item > KQL Queryset. Enter the name MultivariateAnomalyDetectionTutorial.
- Select Create.
- In the OneLake data hub window, select the KQL database where you stored the data.
- Select Connect.
Part 9- Predict anomalies in the KQL queryset
Copy/paste and run the following '.create-or-alter function' query to define the
predict_fabric_mvad_fl()stored function:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Copy/paste the following prediction query.
- Replace the output model URI copied in the end of step 7.
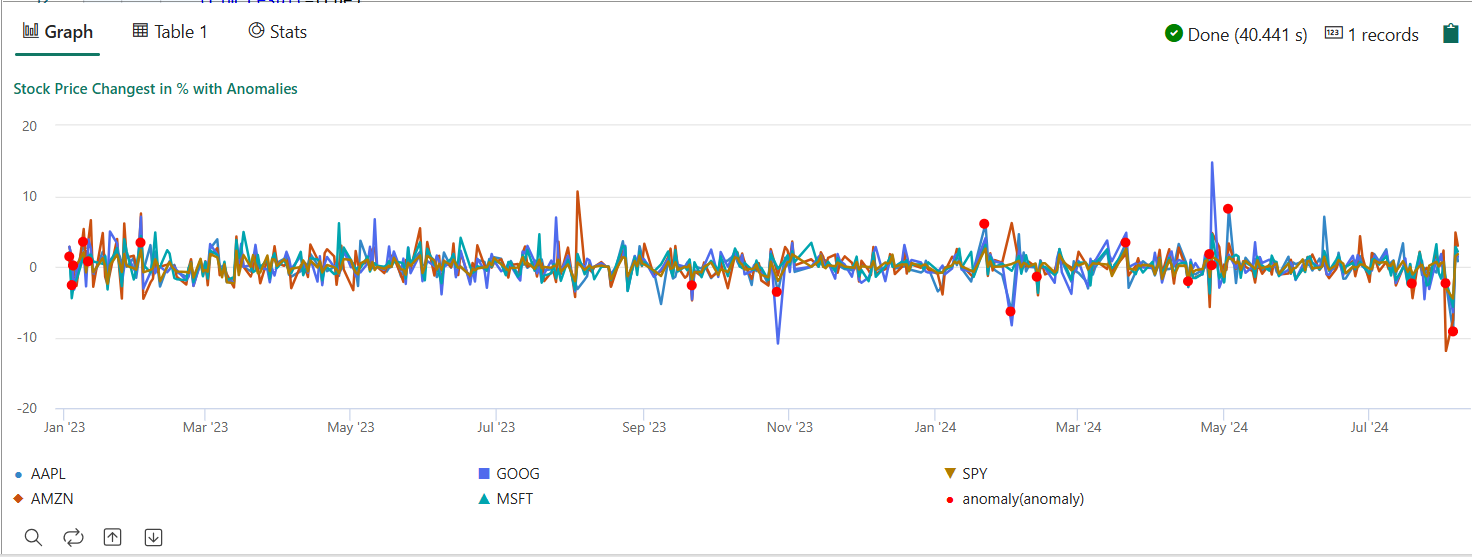
- Run the query. It detects multivariate anomalies on the five stocks, based on the trained model, and renders the results as
anomalychart. The anomalous points are rendered on the first stock (AAPL), though they represent multivariate anomalies (in other words, anomalies of the joint changes of the five stocks in the specific date).
let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
The resulting anomaly chart should look like the following image:
Clean up resources
When you finish the tutorial, you can delete the resources, you created to avoid incurring other costs. To delete the resources, follow these steps:
- Browse to your workspace homepage.
- Delete the environment created in this tutorial.
- Delete the notebook created in this tutorial.
- Delete the Eventhouse or database used in this tutorial.
- Delete the KQL queryset created in this tutorial.