Extrahera text och information från bilder i AI-berikning
Med AI-berikning ger Azure AI Search flera alternativ för att skapa och extrahera sökbar text från bilder, bland annat:
- OCR för optisk teckenigenkänning av text och siffror
- Bildanalys som beskriver bilder via visuella funktioner
- Anpassade kunskaper för att anropa alla externa bildbearbetningar som du vill tillhandahålla
Via OCR kan du extrahera text från foton eller bilder som innehåller alfanumerisk text, till exempel ordet "STOP" i ett stopptecken. Genom bildanalys kan du generera en textrepresentation av en bild, till exempel "maskros" för ett foto av en maskros eller färgen "gul". Du kan också extrahera metadata om bilden, till exempel dess storlek.
Den här artikeln beskriver grunderna i att arbeta med bilder och beskriver även flera vanliga scenarier, till exempel att arbeta med inbäddade bilder, anpassade kunskaper och överlägg visualiseringar på ursprungliga bilder.
Om du vill arbeta med bildinnehåll i en kompetensuppsättning behöver du:
- Källfiler som innehåller bilder
- En sökindexerare, konfigurerad för bildåtgärder
- En kompetensuppsättning med inbyggda eller anpassade kunskaper som anropar OCR eller bildanalys
- Ett sökindex med fält för att ta emot de analyserade textutdata, plus mappningar av utdatafält i indexeraren som upprättar associationen.
Du kan också definiera projektioner för att acceptera bildanalyserade utdata i ett kunskapslager för datautvinningsscenarier.
Konfigurera källfiler
Bildbearbetningen är indexerdriven, vilket innebär att rådataindata måste finnas i en datakälla som stöds.
- Bildanalys stöder JPEG, PNG, GIF och BMP
- OCR stöder JPEG, PNG, BMP och TIF
Bilder är antingen fristående binära filer eller inbäddade i dokument (PDF, RTF och Microsoft-programfiler). Högst 1 000 bilder kan extraheras från ett visst dokument. Om det finns fler än 1 000 bilder i ett dokument extraheras de första 1 000 och sedan genereras en varning.
Azure Blob Storage är det vanligaste lagringsutrymmet för bildbearbetning i Azure AI Search. Det finns tre huvudsakliga uppgifter som rör hämtning av avbildningar från en blobcontainer:
Aktivera åtkomst till innehåll i containern. Om du använder en fullständig åtkomst anslutningssträng som innehåller en nyckel ger nyckeln dig behörighet till innehållet. Du kan också autentisera med hjälp av Microsoft Entra-ID eller ansluta som en betrodd tjänst.
Skapa en datakälla av typen "azureblob" som ansluter till blobcontainern som lagrar dina filer.
Granska gränserna för tjänstnivå för att se till att dina källdata är under maximal storlek och kvantitetsgränser för indexerare och berikning.
Konfigurera indexerare för bildbearbetning
När källfilerna har konfigurerats aktiverar du avbildningsnormalisering genom att ange parametern imageAction i indexerarens konfiguration. Bildnormalisering hjälper till att göra bilderna mer enhetliga för nedströmsbearbetning. Bildnormalisering innehåller följande åtgärder:
- Stora bilder ändras till en maximal höjd och bredd för att göra dem enhetliga.
- För bilder som har metadata vid orientering justeras bildrotationen för vertikal inläsning.
Metadatajusteringar registreras i en komplex typ som skapats för varje bild. Du kan inte välja bort kravet på bildnormalisering. Kunskaper som itererar över bilder, till exempel OCR och bildanalys, förväntar sig normaliserade bilder.
Skapa eller uppdatera en indexerare för att ange konfigurationsegenskaperna:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Ange
dataToExtracttillcontentAndMetadata(krävs).Kontrollera att är inställt på
parsingModestandard (krävs).Den här parametern avgör kornigheten för sökdokument som skapats i indexet. Standardläget konfigurerar en en-till-en-korrespondens så att en blob resulterar i ett sökdokument. Om dokumenten är stora, eller om färdigheter kräver mindre textsegment, kan du lägga till kunskaper om textdelning som delar upp ett dokument i växling för bearbetningsändamål. Men för sökscenarier krävs en blob per dokument om berikning omfattar bildbearbetning.
Ange
imageActionför att aktivera normalized_images noden i ett berikande träd (krävs):generateNormalizedImagesför att generera en matris med normaliserade bilder som en del av dokumentsprickor.generateNormalizedImagePerPage(gäller endast PDF) för att generera en matris med normaliserade bilder där varje sida i PDF-filen återges till en utdatabild. För icke-PDF-filer liknar den här parameterns beteende som om du hade angett "generateNormalizedImages". Observera dock att inställningen "generateNormalizedImagePerPage" kan göra indexeringsåtgärden mindre högpresterande (särskilt för stora dokument) eftersom flera bilder måste genereras.
Du kan också justera bredden eller höjden på de genererade normaliserade bilderna:
normalizedImageMaxWidth(i bildpunkter). Standardvärdet är 2000. Maximalt värde är 10000.normalizedImageMaxHeight(i bildpunkter). Standardvärdet är 2000. Maximalt värde är 10000.
Standardvärdet på 2 000 bildpunkter för normaliserade bilders maximala bredd och höjd baseras på de maximala storlekar som stöds av OCR-skickligheten och bildanalysens skicklighet. OCR-färdigheten stöder en maximal bredd och höjd på 4200 för icke-engelska språk och 10000 för engelska. Om du ökar de maximala gränserna kan bearbetningen misslyckas på större bilder beroende på din kompetensuppsättningsdefinition och dokumentens språk.
Du kan också ange kriterier för filtyp om arbetsbelastningen är avsedd för en viss filtyp. Blob Indexer-konfigurationen innehåller inställningar för filinkludering och undantag. Du kan filtrera bort filer som du inte vill ha.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Om normaliserade bilder
När imageAction är inställt på ett annat värde än "ingen" innehåller det nya fältet normalized_images en matris med bilder. Varje bild är en komplex typ som har följande medlemmar:
| Bildmedlem | beskrivning |
|---|---|
| data | BASE64-kodad sträng för den normaliserade bilden i JPEG-format. |
| width | Bredden på den normaliserade bilden i bildpunkter. |
| height | Höjden på den normaliserade bilden i bildpunkter. |
| originalWidth | Bildens ursprungliga bredd före normalisering. |
| originalHeight | Bildens ursprungliga höjd före normalisering. |
| rotationFromOriginal | Motsols rotation i grader som uppstod för att skapa den normaliserade avbildningen. Ett värde mellan 0 grader och 360 grader. Det här steget läser metadata från bilden som genereras av en kamera eller skanner. Vanligtvis en multipel av 90 grader. |
| contentOffset | Teckenförskjutningen i innehållsfältet där bilden extraherades från. Det här fältet gäller endast för filer med inbäddade bilder. ContentOffset för bilder som extraherats från PDF-dokument finns alltid i slutet av texten på sidan som den extraherades från i dokumentet. Det innebär att bilder visas efter all text på den sidan, oavsett bildens ursprungliga plats på sidan. |
| Pagenumber | Om bilden extraherades eller renderades från en PDF innehåller det här fältet sidnumret i PDF-filen som den extraherades eller renderades från, från och med 1. Om avbildningen inte är från en PDF-fil är det här fältet 0. |
Exempelvärde för normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definiera kompetensuppsättningar för bildbearbetning
Det här avsnittet kompletterar kunskapsreferensartiklarna genom att ge sammanhang för att arbeta med kunskapsindata, utdata och mönster, eftersom de relaterar till bildbearbetning.
Skapa eller uppdatera en kompetensuppsättning för att lägga till färdigheter.
Lägg till mallar för OCR och bildanalys från portalen eller kopiera definitionerna från dokumentationen för kunskapsreferensen. Infoga dem i kompetensmatrisen för din kompetensuppsättningsdefinition.
Om det behövs ska du inkludera nyckel för flera tjänster i azure AI-tjänsteegenskapen för kompetensuppsättningen. Azure AI Search anropar en fakturerbar Azure AI-tjänstresurs för OCR och bildanalys för transaktioner som överskrider den kostnadsfria gränsen (20 per indexerare per dag). Azure AI-tjänster måste finnas i samma region som din söktjänst.
Om originalbilderna är inbäddade i PDF- eller programfiler som PPTX eller DOCX måste du lägga till en färdighet för sammanslagning av text om du vill ha bildutdata och textutdata tillsammans. I den här artikeln beskrivs hur du arbetar med inbäddade avbildningar.
När det grundläggande ramverket för din kompetensuppsättning har skapats och Azure AI-tjänster har konfigurerats kan du fokusera på varje enskild bildfärdighet, definiera indata och källkontext och mappa utdata till fält i ett index- eller kunskapslager.
Kommentar
Se REST-självstudie: Använd REST och AI för att generera sökbart innehåll från Azure-blobbar för en exempelkompetensuppsättning som kombinerar bildbearbetning med nedströms bearbetning av naturligt språk. Den visar hur du matar ut kunskapsavbildning i entitetsigenkänning och extrahering av nyckelfraser.
Om indata för bildbearbetning
Som nämnts extraheras bilder under dokumentsprickor och normaliseras sedan som ett preliminärt steg. De normaliserade bilderna är indata för alla kunskaper i bildbearbetning och representeras alltid i ett berikat dokumentträd på något av två sätt:
/document/normalized_images/*gäller för dokument som bearbetas helt./document/normalized_images/*/pagesär för dokument som bearbetas i segment (sidor).
Oavsett om du använder OCR och bildanalys på samma sätt har indata praktiskt taget samma konstruktion:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Mappa utdata till sökfält
I en kompetensuppsättning är bildanalys och OCR-kunskapsutdata alltid text. Utdatatext representeras som noder i ett internt berikat dokumentträd, och varje nod måste mappas till fält i ett sökindex, eller till projektioner i ett kunskapslager, för att göra innehållet tillgängligt i din app.
I kunskapsuppsättningen går du igenom
outputsavsnittet för varje färdighet för att avgöra vilka noder som finns i det berikade dokumentet:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Skapa eller uppdatera ett sökindex för att lägga till fält för att acceptera kunskapsutdata.
I följande exempel på fältsamling är "innehåll" blobinnehåll. "Metadata_storage_name" innehåller namnet på filen (kontrollera att den är "hämtningsbar"). "Metadata_storage_path" är blobens unika sökväg och är standarddokumentnyckeln. "Merged_content" är utdata från sammanslagning av text (användbart när bilder är inbäddade).
"Text" och "layoutText" är OCR-kunskapsutdata och måste vara en strängsamling för att samla in alla OCR-genererade utdata för hela dokumentet.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Uppdatera indexeraren för att mappa kunskapsuppsättningsutdata (noder i ett berikningsträd) till indexfält.
Berikade dokument är interna. Om du vill externalisera noderna i ett berikat dokumentträd konfigurerar du en mappning av utdatafält som anger vilket indexfält som tar emot nodinnehåll. Berikade data nås av din app via ett indexfält. I följande exempel visas en "textnod" (OCR-utdata) i ett berikat dokument som mappas till ett textfält i ett sökindex.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Kör indexeraren för att anropa källdokumenthämtning, bildbearbetning och indexering.
Verifiera resultat
Kör en fråga mot indexet för att kontrollera resultatet av bildbearbetningen. Använd Search Explorer som en sökklient eller något verktyg som skickar HTTP-begäranden. Följande fråga väljer fält som innehåller utdata från bildbearbetningen.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR identifierar text i bildfiler. Det innebär att OCR-fält ("text" och "layoutText") är tomma om källdokument är ren text eller rena bilder. På samma sätt är bildanalysfälten ("imageCaption" och "imageTags") tomma om källdokumentindata är strikt text. Indexerarens körning avger varningar om indata för avbildning är tomma. Sådana varningar kan förväntas när noder inte fylls i i det berikade dokumentet. Kom ihåg att blobindexering gör att du kan inkludera eller exkludera filtyper om du vill arbeta med innehållstyper isolerat. Du kan använda den här inställningen för att minska bruset under indexeringskörningar.
En alternativ fråga för att kontrollera resultaten kan innehålla fälten "innehåll" och "merged_content". Observera att fälten innehåller innehåll för alla blobfiler, även de där ingen bildbearbetning utfördes.
Om kunskapsutdata
Kunskapsutdata inkluderar "text" (OCR), "layoutText" (OCR), "merged_content", "bildtext s" (bildanalys), "taggar" (bildanalys):
"text" lagrar OCR-genererade utdata. Den här noden ska mappas till fältet av typen
Collection(Edm.String). Det finns ett textfält per sökdokument som består av kommaavgränsade strängar för dokument som innehåller flera bilder. Följande bild visar OCR-utdata för tre dokument. Först är ett dokument som innehåller en fil utan bilder. Det andra är ett dokument (bildfil) som innehåller ett ord, "Microsoft". Det tredje är ett dokument som innehåller flera bilder, vissa utan text ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]"layoutText" lagrar OCR-genererad information om textplats på sidan, som beskrivs i termer av avgränsningsrutor och koordinater för den normaliserade bilden. Den här noden ska mappas till fältet av typen
Collection(Edm.String). Det finns ett "layoutText"-fält per sökdokument som består av kommaavgränsade strängar."merged_content" lagrar utdata från en textsammanslagningsfärdighet, och det bör vara ett stort fält av typen
Edm.Stringsom innehåller rå text från källdokumentet, med inbäddad "text" i stället för en bild. Om filer endast är text har OCR och bildanalys inget att göra, och "merged_content" är samma som "innehåll" (en blobegenskap som innehåller innehållet i bloben)."imageCaption" innehåller en beskrivning av en bild som enskilda taggar och en längre textbeskrivning.
"imageTags" lagrar taggar om en bild som en samling nyckelord, en samling för alla bilder i källdokumentet.
Följande skärmbild är en bild av en PDF som innehåller text och inbäddade bilder. Dokumentsprickor upptäckte tre inbäddade bilder: flock med måsar, karta, örn. Annan text i exemplet (inklusive rubriker, rubriker och brödtext) extraherades som text och exkluderades från bildbearbetning.
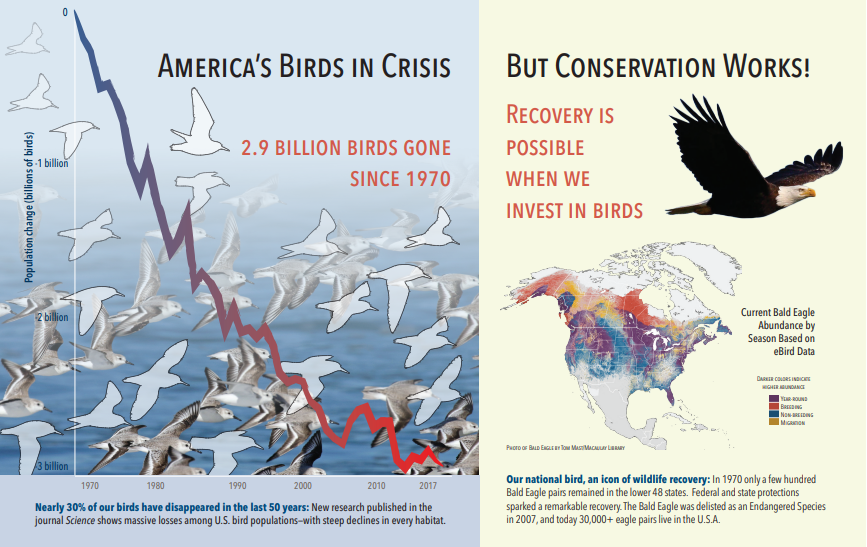
Bildanalysutdata illustreras i JSON nedan (sökresultat). Med kunskapsdefinitionen kan du ange vilka visuella funktioner som är av intresse. I det här exemplet producerades taggar och beskrivningar, men det finns fler utdata att välja mellan.
"imageCaption"-utdata är en matris med beskrivningar, en per bild, som anges av "taggar" som består av enkla ord och längre fraser som beskriver bilden. Lägg märke till taggarna som består av "en flock måsar simmar i vattnet" eller "en närbild av en fågel".
"imageTags"-utdata är en matris med enskilda taggar som anges i skapandeordningen. Observera att taggarna upprepas. Det finns ingen aggregering eller gruppering.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scenario: Inbäddade avbildningar i PDF-filer
När bilderna som du vill bearbeta är inbäddade i andra filer, till exempel PDF eller DOCX, extraherar berikande pipelinen bara bilderna och skickar dem sedan till OCR eller bildanalys för bearbetning. Bildextrahering sker under dokumentets sprickfas, och när bilderna har separerats förblir de separata om du inte uttryckligen sammanfogar de bearbetade utdata tillbaka till källtexten.
Textsammanslagning används för att föra tillbaka bildbearbetningsutdata till dokumentet. Även om sammanslagning av text inte är ett hårt krav anropas det ofta så att bildutdata (OCR-text, OCR layoutText, bildtaggar, bildtext) kan återinföras i dokumentet. Beroende på färdigheten ersätter bildens utdata en inbäddad binär bild med en motsvarande text på plats. Bildanalysutdata kan sammanfogas på bildplatsen. OCR-utdata visas alltid i slutet av varje sida.
Följande arbetsflöde beskriver processen för bildextrahering, analys, sammanslagning och hur du utökar pipelinen för att skicka bildbearbetade utdata till andra textbaserade kunskaper som entitetsigenkänning eller textöversättning.
När du har anslutit till datakällan läser indexeraren in och spricker källdokument, extraherar bilder och text och köar varje innehållstyp för bearbetning. Ett berikat dokument som endast består av en rotnod (
"document") skapas.Bilder i kön normaliseras och skickas till berikade dokument som en
"document/normalized_images"nod.Bildberikningar körs med indata
"/document/normalized_images".Bildutdata skickas till det berikade dokumentträdet, med varje utdata som en separat nod. Utdata varierar beroende på skicklighet (text och layoutText för OCR, taggar och bildtext för bildanalys).
Valfritt men rekommenderas om du vill att sökdokument ska inkludera både text och bild-ursprung text tillsammans, textsammanslagning körs, kombinera textrepresentationen av dessa bilder med den råa text som extraheras från filen. Textsegment konsolideras till en enda stor sträng, där texten först infogas i strängen och sedan OCR-textutdata eller bildtaggar och bildtext.
Utdata från Sammanslagning av text är nu den slutgiltiga text som ska analyseras för eventuella underordnade kunskaper som utför textbearbetning. Om din kompetensuppsättning till exempel innehåller både OCR och Entitetsigenkänning ska indata till Entitetsigenkänning vara
"document/merged_text"(målnamnet för kunskapsutdata för textsammanslagning).När alla kunskaper har körts är det berikade dokumentet slutfört. I det sista steget refererar indexerare till utdatafältmappningar för att skicka berikat innehåll till enskilda fält i sökindexet.
I följande exempeluppsättning skapas ett "merged_text" fält som innehåller den ursprungliga texten i dokumentet med inbäddad OCRed-text i stället för inbäddade bilder. Den innehåller också en entitetsigenkänningsfärdighet som använder "merged_text" som indata.
Syntax för begärandetext
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Nu när du har ett merged_text fält kan du mappa det som ett sökbart fält i indexerarens definition. Allt innehåll i dina filer, inklusive texten i bilderna, kommer att vara sökbart.
Scenario: Visualisera avgränsningsrutor
Ett annat vanligt scenario är att visualisera layoutinformation för sökresultat. Du kanske till exempel vill markera var en textdel hittades i en bild som en del av sökresultaten.
Eftersom OCR-steget utförs på de normaliserade bilderna finns layoutkoordinaterna i det normaliserade bildutrymmet, men om du behöver visa den ursprungliga bilden konverterar du koordinatpunkter i layouten till det ursprungliga bildkoordinatsystemet.
Följande algoritm illustrerar mönstret:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scenario: Anpassade avbildningskunskaper
Bilder kan också skickas till och returneras från anpassade kunskaper. En kunskapsuppsättning base64-kodar bilden som skickas till den anpassade färdigheten. Om du vill använda avbildningen inom den anpassade färdigheten anger du "/document/normalized_images/*/data" som indata till den anpassade färdigheten. I din anpassade färdighetskod, base64-avkoda strängen innan du konverterar den till en bild. Om du vill returnera en avbildning till kompetensuppsättningen, base64-koda bilden innan du returnerar den till kompetensuppsättningen.
Bilden returneras som ett objekt med följande egenskaper.
{
"$type": "file",
"data": "base64String"
}
Azure Search Python-exempellagringsplatsen har ett fullständigt exempel implementerat i Python med en anpassad färdighet som berikar bilder.
Skicka bilder till anpassade kunskaper
För scenarier där du behöver en anpassad färdighet för att arbeta med bilder kan du skicka bilder till den anpassade färdigheten och få den att returnera text eller bilder. Följande kompetensuppsättning är från ett exempel.
Följande kunskapsuppsättning tar den normaliserade bilden (som erhålls under dokumentsprickor) och utdata sektorer av bilden.
Exempel på kompetensuppsättning
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Exempel på anpassad kompetens
Den anpassade färdigheten i sig är utanför kompetensuppsättningen. I det här fallet är det Python-kod som först loopar genom batchen med begärandeposter i det anpassade färdighetsformatet och sedan konverterar den base64-kodade strängen till en bild.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
På samma sätt returnerar du en base64-kodad sträng i ett JSON-objekt med egenskapen $typefile.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}