Avvikelseidentifiering i slutpunktsanalys
Obs!
Den här funktionen är tillgänglig som ett Intune-tillägg. Mer information finns i Intune-tillägg.
Den här artikeln förklarar hur avvikelseidentifiering i Slutpunktsanalys fungerar som ett system för tidig varning.
Avvikelseidentifiering övervakar hälsotillståndet för enheter i din organisation för användarupplevelse och produktivitetsregressioner efter konfigurationsändringar. När ett fel inträffar korrelerar avvikelser relevanta distributionsobjekt för att möjliggöra snabb felsökning, föreslå rotorsaker och reparation.
Administratörer kan förlita sig på avvikelseidentifiering för att lära sig mer om användarupplevelsen som påverkar problem innan de når dem via andra kanaler. Det första fokuset för avvikelseidentifiering är programlåsningar/krascher och omstarter av stoppfel.
Översikt
Med avvikelseidentifiering kan du identifiera potentiella problem i ett system innan de blir ett allvarligt problem. Traditionellt har supportteamen begränsad insyn i potentiella problem.
Ofta får de bara en delmängd av de problem som rapporteras/eskaleras via supportkanalen, vilket inte riktigt är representativt för allt som händer i din organisation.
De måste ägna otaliga timmar åt att granska anpassade instrumentpaneler för att identifiera rotorsaken, felsöka, skapa anpassade aviseringar, ändra tröskelvärden och justera parametrar.
Avvikelseidentifiering syftar till att åtgärda dessa problem genom att ge IT-administratörer viktig information.
Förutom att identifiera avvikelser kan du visa enhetskorrelationsgrupper för att utforska potentiella rotorsaker till avvikelser med medelhög och hög allvarlighetsgrad. Med de här enhetskohorterna kan du visa mönster som identifieras bland enheter. Vi har tagit en proaktiv metod för enhetshantering genom att även identifiera enheter som är "i riskzonen" i dessa kohorter. Det här är de enheter som omfattas av de identifierade mönstren med hög konfidens, men som ännu inte har sett dessa avvikelser.
Obs!
Enhetskohorter identifieras endast för avvikelser med medelhög och hög allvarlighetsgrad.
Förutsättningar
Licensiering/prenumerationer: De avancerade funktionerna i Slutpunktsanalys ingår som ett Intune-tillägg under Microsoft Intune Suite och kräver en extra kostnad för licensalternativen som inkluderar Microsoft Intune.
Behörigheter: Avvikelseidentifiering använder inbyggda rollbehörigheter
Fliken Avvikelser
Logga in på Microsoft Intune administrationscenter.
VäljÖversikt överrapportslutpunktsanalys>>.
Välj fliken Avvikelser . Fliken Avvikelser ger en snabb översikt över de avvikelser som har identifierats i din organisation.
I det här exemplet visar fliken Avvikelser en avvikelse med medelhög allvarlighetsgrad . Du kan lägga till filter för att förfina listan.
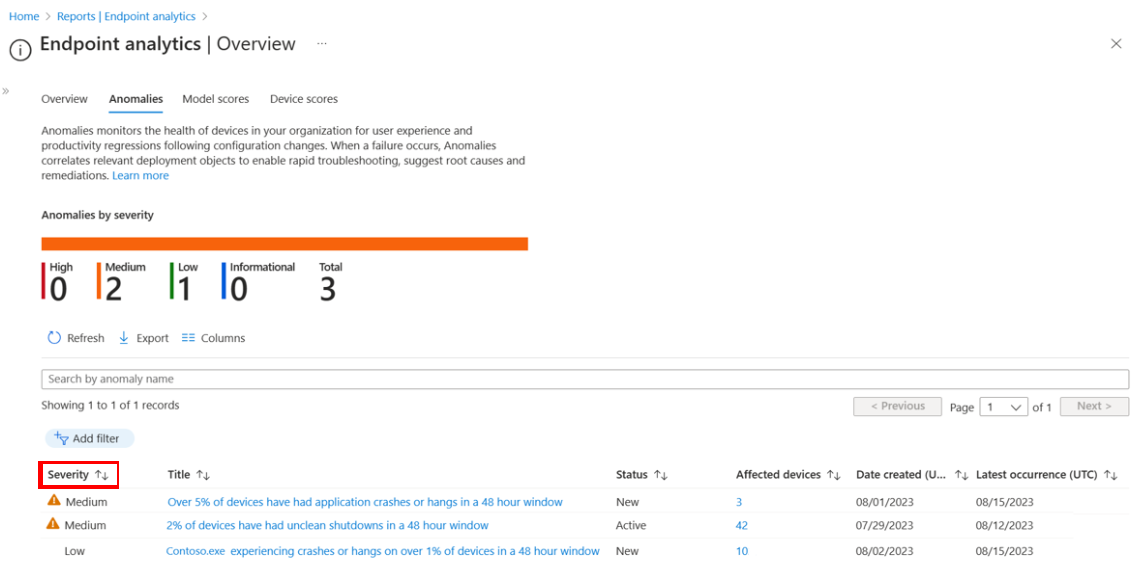
Om du vill se mer information om ett specifikt objekt väljer du det i listan. Du kan se information som namnet på appen, vilka enheter som påverkas, när problemet först upptäcktes och senast inträffade och eventuella enhetsgrupper som kan bidra till problemet.
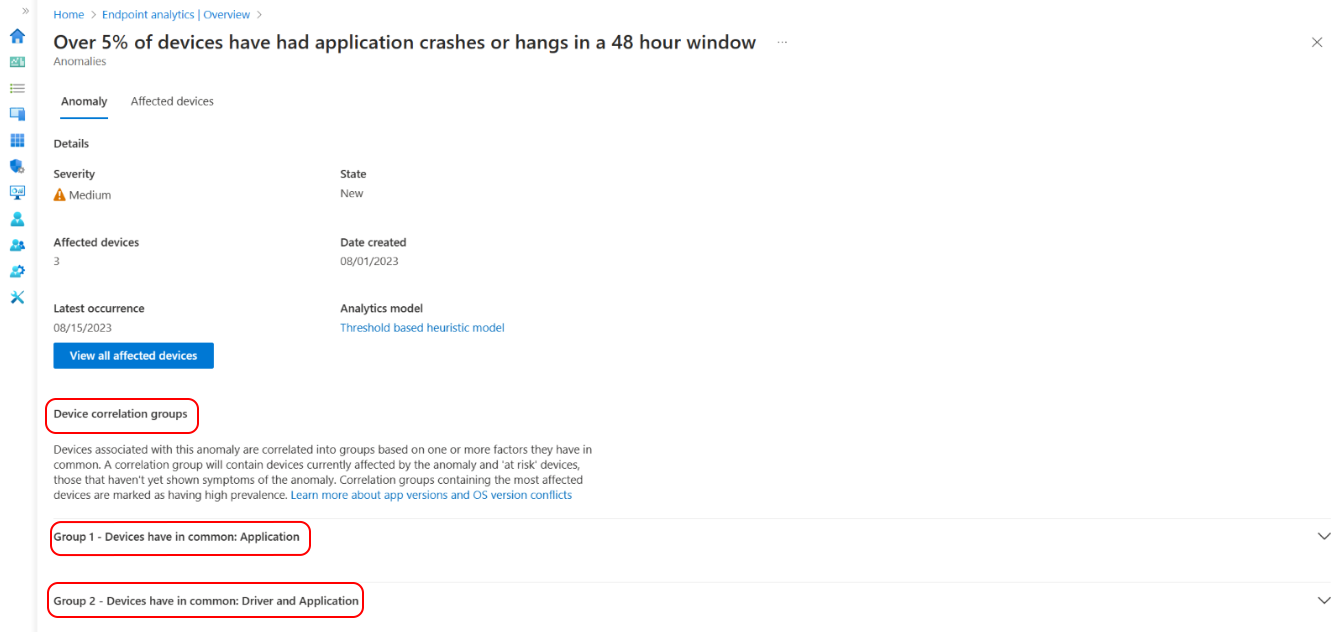
Välj en enhetskorrelationsgrupp i listan för en detaljerad vy över enheternas vanliga faktorer. Enheter korreleras baserat på ett eller flera delade attribut, till exempel appversion, drivrutinsuppdatering, operativsystemversion och enhetsmodell. Du kan se antalet enheter som för närvarande påverkas av avvikelsen och enheter som riskerar att uppleva avvikelsen. Prevalensfrekvensen visar också procentandelen berörda enheter från en avvikelse som är medlemmar i en korrelationsgrupp.

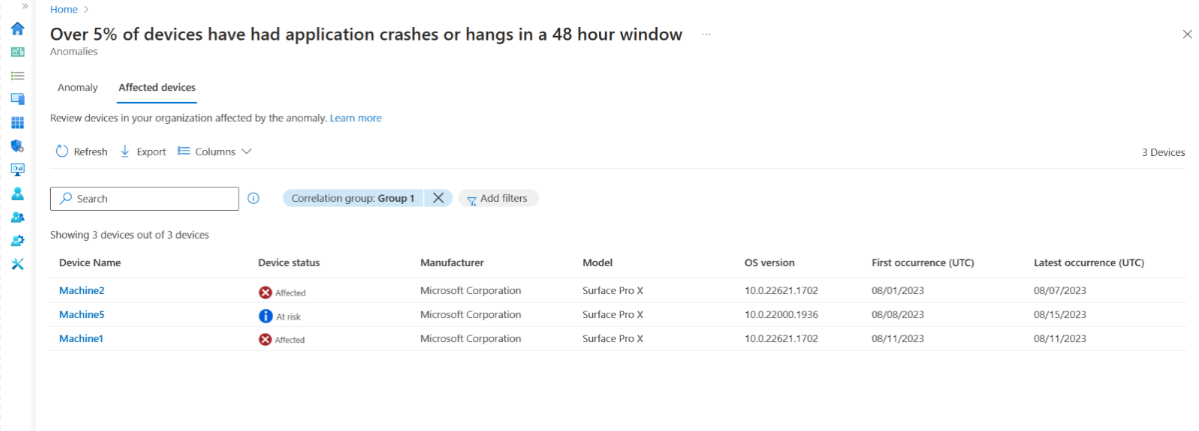
Välj Visa berörda enheter för att visa en lista över enheter med nyckelattribut som är relevanta för varje enhet. Du kan filtrera för att visa enheter i specifika korrelationsgrupper eller visa alla enheter som påverkas av den avvikelsen i din organisation. Dessutom visar enhetens tidslinje mer avvikande händelser.




Statistiska modeller för att fastställa avvikelser
Analysmodellen som skapats identifierar enhetskohorter som står inför avvikande uppsättning omstarter av stoppfel och programlåsningar/krascher som behöver administratörsuppmärksamhet för att minimera och lösa problem. Mönster som identifieras i våra sensortelemetri- och diagnostikloggar avgör dessa enhetskohorter
Tröskelbaserad heuristisk modell: Den heuristiska modellen omfattar att ange ett eller flera tröskelvärden för programlåsningar/krascher eller omstarter av stoppfel. Enheter flaggas som avvikande om det finns ett intrång i tröskelvärdet ovan. Modellen är enkel men effektiv. det passar för att visa framträdande eller statiska problem med enheter eller deras appar. För närvarande är tröskelvärdena förutbestämda utan möjlighet att anpassa.
Parad t-testmodell: Parade t-tester är en matematisk metod som jämför par av observationer i en datamängd och letar efter ett statistiskt signifikant avstånd mellan deras medel. Tester används på datauppsättningar som består av observationer relaterade till varandra på något sätt. Till exempel antalet omstarter av stoppfel från samma enhet före och efter en principändring, eller så kraschar appen på en enhet efter en uppdatering av operativsystemet.
Population Z-poängmodell: Population Z-poängsbaserade statistiska modeller omfattar beräkning av standardavvikelsen och medelvärdet för en datamängd och använder sedan dessa värden för att avgöra vilka datapunkter som är avvikande. Standardavvikelse och medelvärde används för att beräkna Z-poängen för varje datapunkt, vilket representerar antalet standardavvikelser bort från medelvärdet. Datapunkter som ligger utanför ett visst intervall är avvikande. Den här modellen lämpar sig väl för att markera avvikande enheter eller appar från den bredare baslinjen, men kräver tillräckligt stora datauppsättningar för att vara korrekta.
Time Series Z-poängmodell: Tidsserie Z-poängmodeller är en variant av Z-poängmodellen som är utformad för att identifiera avvikelser i tidsseriedata. Tidsseriedata är en sekvens med datapunkter som samlas in med jämna mellanrum över tid, till exempel en mängd omstarter av stoppfel. Standardavvikelse och medelvärde beräknas för en glidande tidsperiod med hjälp av aggregerade mått. Med den här metoden kan modellen vara känslig för temporala mönster i data och anpassa sig till ändringar i fördelningen över tid.
Nästa steg
Mer information finns i:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för