Kopiera och transformera data i Azure Database for MySQL med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här artikeln beskrivs hur du använder kopieringsaktivitet i Azure Data Factory- eller Synapse Analytics-pipelines för att kopiera data från och till Azure Database for MySQL och använda Data Flow för att transformera data i Azure Database for MySQL. Mer information finns i introduktionsartiklarna för Azure Data Factory och Synapse Analytics.
Den här anslutningsappen är specialiserad för
Om du vill kopiera data från en allmän MySQL-databas som finns lokalt eller i molnet använder du MySQL-anslutningsprogrammet.
Förutsättningar
Den här snabbstarten kräver följande resurser och konfiguration som nämns nedan som utgångspunkt:
- En befintlig Azure-databas för MySQL – enskild server eller MySQL – flexibel server med offentlig åtkomst eller privat slutpunkt.
- Aktivera Tillåt offentlig åtkomst från valfri Azure-tjänst i Azure till den här servern på nätverkssidan på MySQL-servern . På så sätt kan du använda Data Factory Studio.
Funktioner som stöds
Den här Azure Database for MySQL-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR | Hanterad privat slutpunkt |
|---|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) | ✓ |
| Mappa dataflöde (källa/mottagare) | (1) | ✓ |
| Sökningsaktivitet | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
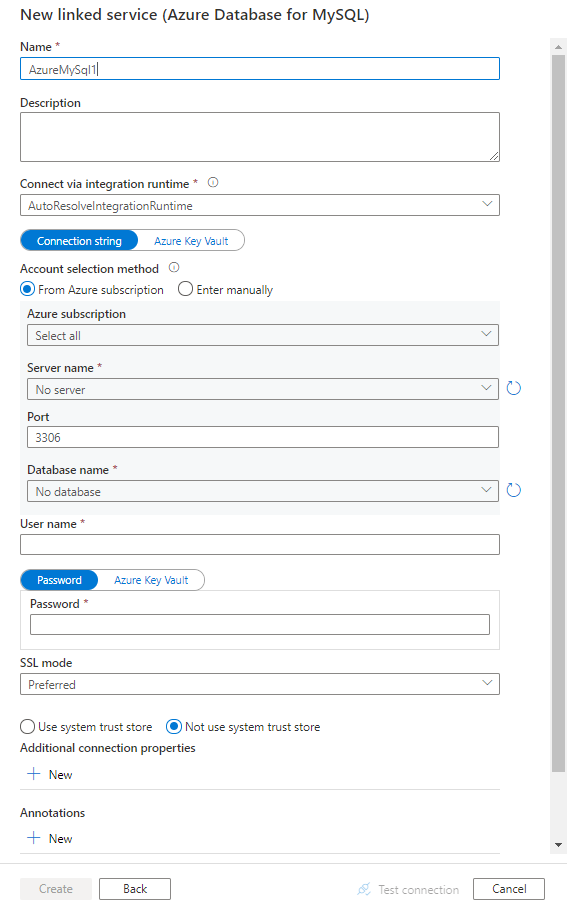
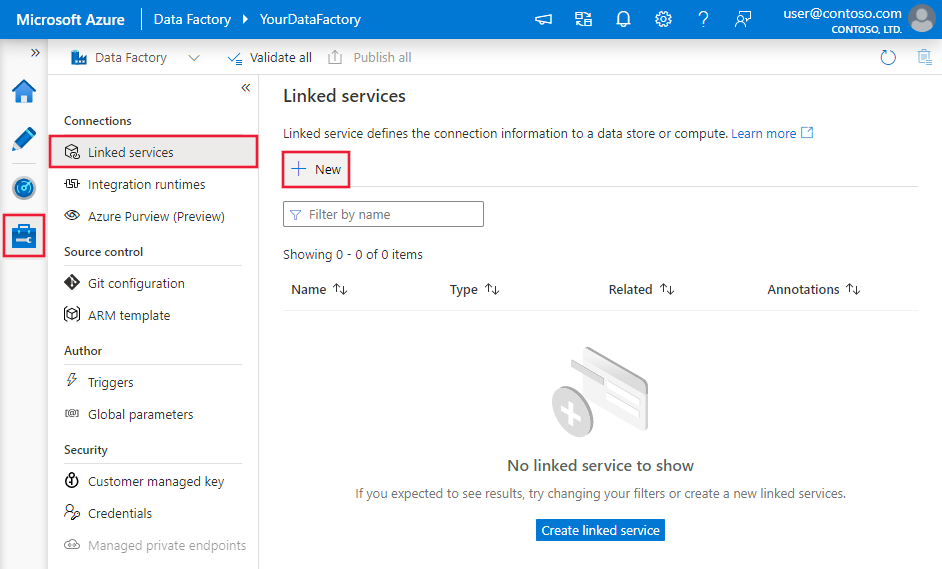
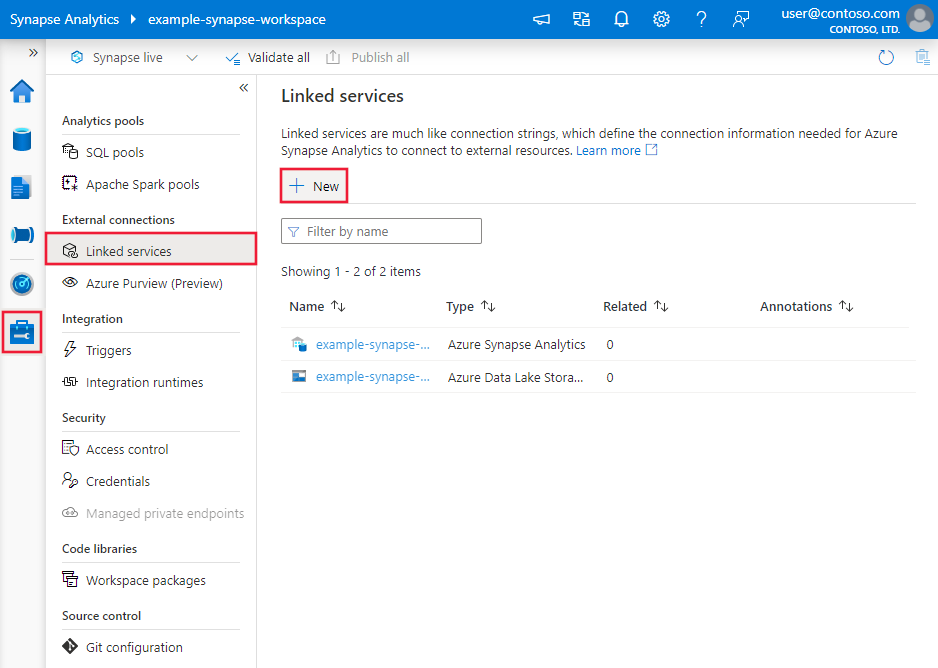
Skapa en länkad tjänst till Azure Database for MySQL med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Azure Database for MySQL i Azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter MySQL och välj Azure Database for MySQL-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Azure Database for MySQL-anslutningstjänsten.
Länkade tjänstegenskaper
Följande egenskaper stöds för länkad Azure Database for MySQL-tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: AzureMySql | Ja |
| connectionString | Ange information som behövs för att ansluta till Azure Database for MySQL-instansen. Du kan också lägga till lösenord i Azure Key Vault och hämta konfigurationen password från niska veze. Mer information finns i följande exempel och artikeln Lagra autentiseringsuppgifter i Azure Key Vault . |
Ja |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
En typisk niska veze är Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Fler egenskaper som du kan ange per ditt ärende:
| Property | beskrivning | Alternativ | Obligatoriskt |
|---|---|---|---|
| SSLMode | Det här alternativet anger om drivrutinen använder TLS-kryptering och verifiering vid anslutning till MySQL. T.ex. SSLMode=<0/1/2/3/4> |
INAKTIVERAD (0) / FÖREDRAGEN (1) (Standard) / KRÄVS (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | Nej |
| UseSystemTrustStore | Det här alternativet anger om du vill använda ett CA-certifikat från systemförtroendearkivet eller från en angiven PEM-fil. T.ex. UseSystemTrustStore=<0/1>; |
Aktiverad (1) /Inaktiverad (0) (standard) | Nej |
Exempel:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: Lagra lösenord i Azure Key Vault
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure Database for MySQL-datauppsättningen.
Om du vill kopiera data från Azure Database for MySQL anger du datauppsättningens typegenskap till AzureMySqlTable. Följande egenskaper stöds:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för datamängden måste anges till: AzureMySqlTable | Ja |
| tableName | Namnet på tabellen i MySQL-databasen. | Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure Database for MySQL-källa och mottagare.
Azure Database for MySQL som källa
Om du vill kopiera data från Azure Database for MySQL stöds följande egenskaper i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: AzureMySqlSource | Ja |
| query | Använd den anpassade SQL-frågan för att läsa data. Exempel: "SELECT * FROM MyTable". |
Nej (om "tableName" i datauppsättningen har angetts) |
| queryCommandTimeout | Väntetiden innan frågebegäran överskrider tidsgränsen. Standardvärdet är 120 minuter (02:00:00) | Nej |
Exempel:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for MySQL som mottagare
Om du vill kopiera data till Azure Database for MySQL stöds följande egenskaper i avsnittet kopieringsaktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till: AzureMySqlSink | Ja |
| preCopyScript | Ange en SQL-fråga för kopieringsaktiviteten som ska köras innan du skriver data till Azure Database for MySQL i varje körning. Du kan använda den här egenskapen för att rensa inlästa data. | Nej |
| writeBatchSize | Infogar data i Tabellen Azure Database for MySQL när buffertstorleken når writeBatchSize. Det tillåtna värdet är heltal som representerar antalet rader. |
Nej (standardvärdet är 10 000) |
| writeBatchTimeout | Vänta tills batchinfogningsåtgärden har slutförts innan tidsgränsen uppnås. Tillåtna värden är Tidsintervall. Ett exempel är 00:30:00 (30 minuter). |
Nej (standardvärdet är 00:00:30) |
Exempel:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Mappa dataflödesegenskaper
När du transformerar data i dataflödets mappning kan du läsa och skriva till tabeller från Azure Database for MySQL. Mer information finns i källtransformering och mottagartransformation i mappning av dataflöden. Du kan välja att använda en Azure Database for MySQL-datauppsättning eller en infogad datauppsättning som käll- och mottagartyp.
Källtransformering
I tabellen nedan visas de egenskaper som stöds av Azure Database for MySQL-källan. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Register | Om du väljer Tabell som indata hämtar dataflödet alla data från tabellen som anges i datauppsättningen. | Nej | - | (endast för infogad datamängd) tableName |
| Fråga | Om du väljer Fråga som indata anger du en SQL-fråga för att hämta data från källan, vilket åsidosätter alla tabeller som du anger i datauppsättningen. Att använda frågor är ett bra sätt att minska antalet rader för testning eller sökningar. Order By-satsen stöds inte, men du kan ange en fullständig SELECT FROM-instruktion. Du kan också använda användardefinierade tabellfunktioner. select * from udfGetData() är en UDF i SQL som returnerar en tabell som du kan använda i dataflödet. Frågeexempel: select * from mytable where customerId > 1000 and customerId < 2000 eller select * from "MyTable". |
Nej | String | query |
| Lagrad procedur | Om du väljer Lagrad procedur som indata anger du ett namn på den lagrade proceduren för att läsa data från källtabellen eller väljer Uppdatera för att be tjänsten att identifiera procedurnamnen. | Ja (om du väljer Lagrad procedur som indata) | String | procedureName |
| Procedurparametrar | Om du väljer Lagrad procedur som indata anger du eventuella indataparametrar för den lagrade proceduren i orderuppsättningen i proceduren eller väljer Importera för att importera alla procedureparametrar med hjälp av formuläret @paraName. |
Nej | Matris | Ingångar |
| Batchstorlek | Ange en batchstorlek för att segmentera stora data i batchar. | Nej | Integer | batchSize |
| Isoleringsnivå | Välj någon av följande isoleringsnivåer: - Läs bekräftad – Läs ej genererad (standard) – Repeterbar läsning -Serialiseras – Ingen (ignorera isoleringsnivå) |
Nej | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALISERAS INGET |
isolationLevel |
Exempel på Azure Database for MySQL-källskript
När du använder Azure Database for MySQL som källtyp är det associerade dataflödesskriptet:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Transformering av mottagare
I tabellen nedan visas de egenskaper som stöds av Azure Database for MySQL-mottagare. Du kan redigera dessa egenskaper på fliken Alternativ för mottagare.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Uppdatera metod | Ange vilka åtgärder som tillåts på databasmålet. Standardvärdet är att endast tillåta infogningar. För att uppdatera, öka eller ta bort rader krävs en Alter row-transformering för att tagga rader för dessa åtgärder. |
Ja | true eller false |
kan tas bort infogningsbar kan uppdateras upsertable |
| Nyckelkolumner | För uppdateringar, upserts och borttagningar måste nyckelkolumner anges för att avgöra vilken rad som ska ändras. Kolumnnamnet som du väljer som nyckel används som en del av den efterföljande uppdateringen, upsert, delete. Därför måste du välja en kolumn som finns i mappningen mottagare. |
Nej | Matris | keys |
| Hoppa över att skriva nyckelkolumner | Om du inte vill skriva värdet till nyckelkolumnen väljer du "Hoppa över att skriva nyckelkolumner". | Nej | true eller false |
skipKeyWrites |
| Tabellåtgärd | Avgör om du vill återskapa eller ta bort alla rader från måltabellen innan du skriver. - Ingen: Ingen åtgärd utförs i tabellen. - Återskapa: Tabellen tas bort och återskapas. Krävs om du skapar en ny tabell dynamiskt. - Trunkera: Alla rader från måltabellen tas bort. |
Nej | true eller false |
återskapa trunkera |
| Batchstorlek | Ange hur många rader som skrivs i varje batch. Större batchstorlekar förbättrar komprimering och minnesoptimering, men riskerar att få slut på minnesfel vid cachelagring av data. | Nej | Integer | batchSize |
| Pre- och Post SQL-skript | Ange sql-skript med flera rader som ska köras före (förbearbetning) och efter att (efterbearbetning) data har skrivits till mottagardatabasen. | Nej | String | preSQLs postSQLs |
Dricks
- Vi rekommenderar att du bryter enskilda batchskript med flera kommandon i flera batchar.
- Det går endast att köra instruktioner av typen Data Definition Language (DDL) och Data Manipulation Language (DML), som returnerar ett enda uppdateringsvärde, som del av en batch. Läs mer om att utföra batchåtgärder
Aktivera inkrementell extrahering: Använd det här alternativet för att be ADF att endast bearbeta rader som har ändrats sedan den senaste gången pipelinen kördes.
Inkrementell kolumn: När du använder funktionen för inkrementell extrahering måste du välja den datum/tid eller numeriska kolumn som du vill använda som vattenstämpel i källtabellen.
Börja läsa från början: Om du anger det här alternativet med inkrementellt extrahering instrueras ADF att läsa alla rader vid första körningen av en pipeline med inkrementellt extrahering aktiverat.
Exempel på Azure Database for MySQL-mottagarskript
När du använder Azure Database for MySQL som mottagartyp är det associerade dataflödesskriptet:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Datatypsmappning för Azure Database for MySQL
När du kopierar data från Azure Database for MySQL används följande mappningar från MySQL-datatyper till mellanliggande datatyper som används internt i tjänsten. Se Schema- och datatypmappningar för att lära dig mer om hur kopieringsaktivitet mappar källschemat och datatypen till mottagaren.
| Azure Database for MySQL-datatyp | Datatyp för interimstjänst |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.