Kopiera och transformera data i Microsoft Fabric Lakehouse med Hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Microsoft Fabric Lakehouse är en plattform för dataarkitektur för lagring, hantering och analys av strukturerade och ostrukturerade data på en enda plats. För att uppnå sömlös dataåtkomst för alla beräkningsmotorer i Microsoft Fabric går du till Lakehouse och Delta Tables för att lära dig mer. Som standard skrivs data till Lakehouse Table i V-Order och du kan gå till Delta Lake-tabelloptimering och V-Order för mer information.
Den här artikeln beskriver hur du använder kopieringsaktivitet för att kopiera data från och till Microsoft Fabric Lakehouse och använda Data Flow för att transformera data i Microsoft Fabric Lakehouse. Mer information finns i introduktionsartikeln för Azure Data Factory eller Azure Synapse Analytics.
Funktioner som stöds
Den här Microsoft Fabric Lakehouse-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) |
| Mappa dataflöde (källa/mottagare) | (1) |
| Sökningsaktivitet | (1) (2) |
| GetMetadata-aktivitet | (1) (2) |
| Ta bort aktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Kom igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad Microsoft Fabric Lakehouse-tjänst med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad Microsoft Fabric Lakehouse-tjänst i Användargränssnittet för Azure-portalen.
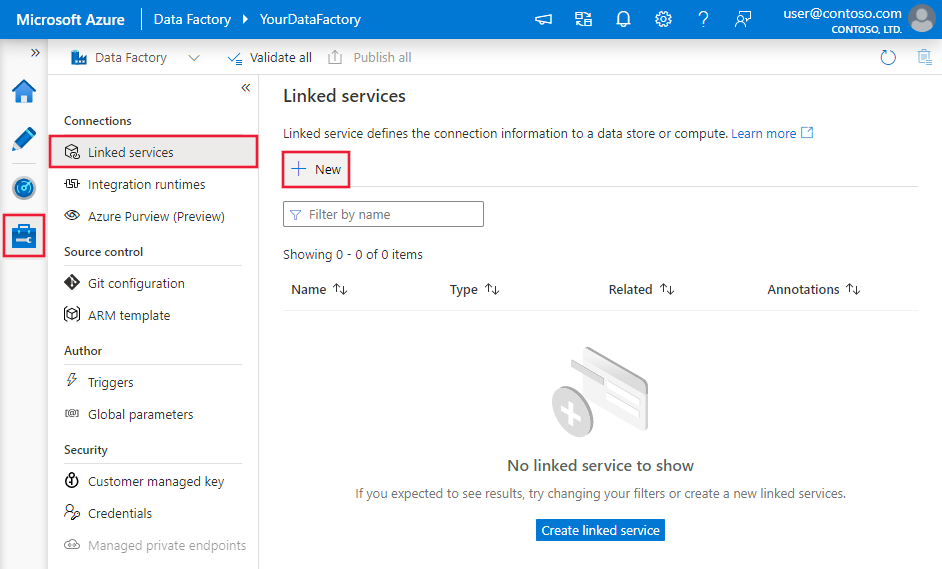
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och välj sedan Nytt:
Sök efter Microsoft Fabric Lakehouse och välj anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
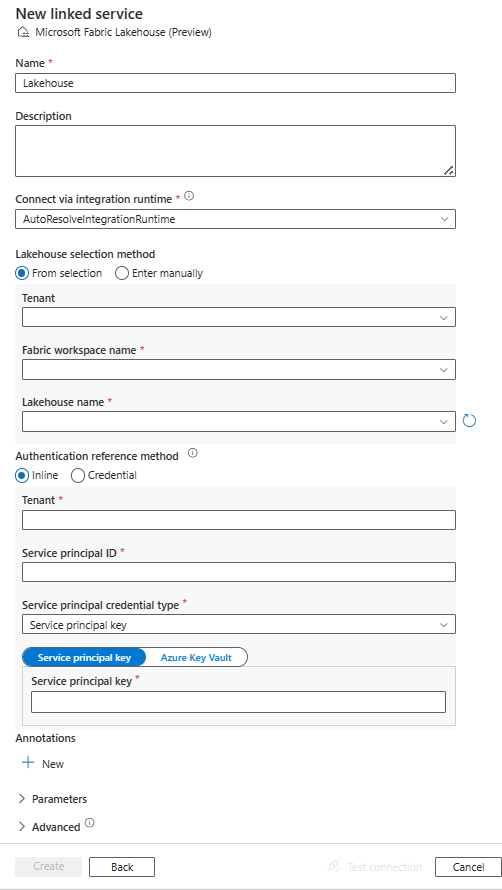
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Microsoft Fabric Lakehouse.
Länkade tjänstegenskaper
Microsoft Fabric Lakehouse-anslutningsappen stöder följande autentiseringstyper. Mer information finns i motsvarande avsnitt:
Tjänstens huvudautentisering
Följ dessa steg om du vill använda autentisering med tjänstens huvudnamn.
Registrera ett program med Microsoft Identity-plattformen och lägg till en klienthemlighet. Anteckna sedan dessa värden som du använder för att definiera den länkade tjänsten:
- Program-ID (klient) som är tjänstens huvudnamns-ID i den länkade tjänsten.
- Klienthemlighetsvärde, som är tjänstens huvudnyckel i den länkade tjänsten.
- Klientorganisations-ID
Bevilja tjänstens huvudnamn minst rollen Deltagare i Microsoft Fabric-arbetsytan. Följ de här stegen:
Gå till din Microsoft Fabric-arbetsyta och välj Hantera åtkomst i det övre fältet. Välj sedan Lägg till personer eller grupper.


I fönstret Lägg till personer anger du tjänstens huvudnamn och väljer tjänstens huvudnamn i listrutan.
Kommentar
Tjänstens huvudnamn visas inte i listan Lägg till personer om inte inställningarna för Power BI-klientorganisationen ger tjänstens huvudnamn åtkomst till Infrastruktur-API:er.
Ange rollen som deltagare eller högre (administratör, medlem) och välj sedan Lägg till.

Tjänstens huvudnamn visas i fönstret Hantera åtkomst .
Dessa egenskaper stöds för den länkade tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till Lakehouse. | Ja |
| workspaceId | Arbetsyte-ID:t för Microsoft Fabric. | Ja |
| artifactId | Objekt-ID:t för Microsoft Fabric Lakehouse. | Ja |
| klientorganisation | Ange klientinformationen (domännamn eller klient-ID) som programmet finns under. Hämta den genom att hovra musen i det övre högra hörnet i Azure-portalen. | Ja |
| servicePrincipalId | Ange programmets klient-ID. | Ja |
| servicePrincipalCredentialType | Den typ av autentiseringsuppgifter som ska användas för autentisering med tjänstens huvudnamn. Tillåtna värden är ServicePrincipalKey och ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Autentiseringsuppgifterna för tjänstens huvudnamn. När du använder ServicePrincipalKey som typ av autentiseringsuppgifter anger du programmets klienthemlighetsvärde. Markera det här fältet som SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. När du använder ServicePrincipalCert som autentiseringsuppgifter refererar du till ett certifikat i Azure Key Vault och kontrollerar att certifikatinnehållstypen är PKCS #12. |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning om ditt datalager finns i ett privat nätverk. Om det inte anges används standardkörningen för Azure-integrering. | Nej |
Exempel: använda nyckelautentisering för tjänstens huvudnamn
Du kan också lagra tjänstens huvudnamnsnyckel i Azure Key Vault.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
Microsoft Fabric Lakehouse-anslutningsappen har stöd för två typer av datauppsättningar, som är Microsoft Fabric Lakehouse Files-datauppsättning och Microsoft Fabric Lakehouse Table-datauppsättning. Mer information finns i motsvarande avsnitt.
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar.
Microsoft Fabric Lakehouse Files-datauppsättning
Microsoft Fabric Lakehouse-anslutningsappen stöder följande filformat. Se varje artikel för formatbaserade inställningar.
Följande egenskaper stöds under location inställningar i den formatbaserade datauppsättningen Microsoft Fabric Lakehouse Files:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under location i datamängden måste anges till LakehouseLocation. |
Ja |
| folderPath | Sökvägen till en mapp. Om du vill använda ett jokertecken för att filtrera mappar hoppar du över den här inställningen och anger den i aktivitetskällans inställningar. | Nej |
| fileName | Filnamnet under den angivna folderPath. Om du vill använda ett jokertecken för att filtrera filer hoppar du över den här inställningen och anger den i inställningarna för aktivitetskällan. | Nej |
Exempel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Microsoft Fabric Lakehouse Table-datauppsättning
Följande egenskaper stöds för Microsoft Fabric Lakehouse Table-datauppsättningen:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till LakehouseTable. | Ja |
| schema | Namnet på schemat. Om det inte anges är dbostandardvärdet . |
Nej |
| table | Namnet på tabellen. | Ja |
Exempel:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Kopiera egenskaper för aktivitet
Egenskaperna för kopieringsaktivitet för Microsoft Fabric Lakehouse Files-datauppsättningen och Microsoft Fabric Lakehouse Table-datauppsättningen skiljer sig åt. Mer information finns i motsvarande avsnitt.
- Microsoft Fabric Lakehouse-filer i kopieringsaktivitet
- Microsoft Fabric Lakehouse-tabell i kopieringsaktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i Kopiera aktivitetskonfigurationer och Pipelines och aktiviteter.
Microsoft Fabric Lakehouse-filer i kopieringsaktivitet
Om du vill använda datauppsättningstypen Microsoft Fabric Lakehouse Files som källa eller mottagare i kopieringsaktiviteten går du till följande avsnitt för de detaljerade konfigurationerna.
Microsoft Fabric Lakehouse Files som källtyp
Microsoft Fabric Lakehouse-anslutningsappen stöder följande filformat. Se varje artikel för formatbaserade inställningar.
Du har flera alternativ för att kopiera data från Microsoft Fabric Lakehouse med datauppsättningen Microsoft Fabric Lakehouse Files:
- Kopiera från den angivna sökvägen som anges i datauppsättningen.
- Jokerteckenfilter mot mappsökväg eller filnamn, se
wildcardFolderPathochwildcardFileName. - Kopiera filerna som definierats i en viss textfil som filuppsättning, se
fileListPath.
Följande egenskaper finns under storeSettings inställningar i formatbaserad kopieringskälla när du använder Datauppsättningen Microsoft Fabric Lakehouse Files:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under storeSettings måste anges till LakehouseReadSettings. |
Ja |
| Leta upp filerna som ska kopieras: | ||
| ALTERNATIV 1: statisk sökväg |
Kopiera från den mapp/filsökväg som anges i datauppsättningen. Om du vill kopiera alla filer från en mapp anger du wildcardFileName dessutom som *. |
|
| ALTERNATIV 2: jokertecken - jokerteckenFolderPath |
Mappsökvägen med jokertecken för att filtrera källmappar. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller ett enda tecken); använd ^ för att fly om ditt faktiska mappnamn har jokertecken eller detta escape-tecken inuti. Se fler exempel i exempel på mapp- och filfilter. |
Nej |
| ALTERNATIV 2: jokertecken - jokerteckenFileName |
Filnamnet med jokertecken under den angivna mappenPath/wildcardFolderPath för att filtrera källfiler. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enstaka tecken); använd ^ för att fly om ditt faktiska filnamn har jokertecken eller detta escape-tecken inuti. Se fler exempel i exempel på mapp- och filfilter. |
Ja |
| ALTERNATIV 3: en lista över filer – fileListPath |
Anger att en angiven filuppsättning ska kopieras. Peka på en textfil som innehåller en lista över filer som du vill kopiera, en fil per rad, vilket är den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. Ange inte filnamn i datauppsättningen när du använder det här alternativet. Se fler exempel i fillisteexempel. |
Nej |
| Ytterligare inställningar: | ||
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. När rekursiv är inställd på true och mottagaren är ett filbaserat arkiv kopieras eller skapas inte en tom mapp eller undermapp i mottagaren. Tillåtna värden är sanna (standard) och falska. Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| deleteFilesAfterCompletion | Anger om de binära filerna kommer att tas bort från källarkivet när de har flyttats till målarkivet. Filborttagningen sker per fil, så när kopieringsaktiviteten misslyckas ser du att vissa filer redan har kopierats till målet och tagits bort från källan, medan andra fortfarande finns kvar i källarkivet. Den här egenskapen är endast giltig i scenariot med kopiering av binära filer. Standardvärdet: false. |
Nej |
| modifiedDatetimeStart | Filfilter baserat på attributet: Senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet "2018-12-01T05:00:00Z". Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har datetime-värde men modifiedDatetimeEnd är NULL innebär det att de filer vars senast ändrade attribut är större än eller lika med datetime-värdet kommer att väljas. När modifiedDatetimeEnd har datetime-värde men modifiedDatetimeStart är NULL innebär det att de filer vars senast ändrade attribut är mindre än datetime-värdet väljs.Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| modifiedDatetimeEnd | Samma som ovan. | Nej |
| enablePartitionDiscovery | För filer som är partitionerade anger du om partitionerna ska parsas från filsökvägen och lägga till dem som en annan källkolumn. Tillåtna värden är false (standard) och true. |
Nej |
| partitionRootPath | När partitionsidentifiering är aktiverat anger du den absoluta rotsökvägen för att läsa partitionerade mappar som datakolumner. Om den inte har angetts, som standard, – När du använder filsökvägen i datauppsättningen eller listan över filer på källan är partitionsrotsökvägen den sökväg som konfigurerats i datauppsättningen. – När du använder mappfilter för jokertecken är partitionsrotsökvägen undersökvägen före det första jokertecknet. Anta till exempel att du konfigurerar sökvägen i datauppsättningen som "root/folder/year=2020/month=08/day=27": – Om du anger partitionsrotsökväg som "root/folder/year=2020" genererar kopieringsaktiviteten ytterligare två kolumner month och day med värdet "08" respektive "27", utöver kolumnerna i filerna.– Om partitionsrotsökvägen inte har angetts genereras ingen extra kolumn. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Files som en mottagartyp
Microsoft Fabric Lakehouse-anslutningsappen stöder följande filformat. Se varje artikel för formatbaserade inställningar.
Följande egenskaper finns under storeSettings inställningar i formatbaserad kopieringsmottagare när du använder Datauppsättningen Microsoft Fabric Lakehouse Files:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under storeSettings måste anges till LakehouseWriteSettings. |
Ja |
| copyBehavior | Definierar kopieringsbeteendet när källan är filer från ett filbaserat datalager. Tillåtna värden är: – PreserveHierarchy (standard): Bevarar filhierarkin i målmappen. Källfilens relativa sökväg till källmappen är identisk med målfilens relativa sökväg till målmappen. – FlattenHierarchy: Alla filer från källmappen finns på den första nivån i målmappen. Målfilerna har automatiskt genererade namn. – MergeFiles: Sammanfogar alla filer från källmappen till en fil. Om filnamnet anges är det kopplade filnamnet det angivna namnet. Annars är det ett automatiskt genererat filnamn. |
Nej |
| blockSizeInMB | Ange blockstorleken i MB som används för att skriva data till Microsoft Fabric Lakehouse. Läs mer om blockblobar. Det tillåtna värdet är mellan 4 MB och 100 MB. Som standard avgör ADF automatiskt blockstorleken baserat på källlagringstypen och data. För ickebinär kopia till Microsoft Fabric Lakehouse är standardblockstorleken 100 MB för att få plats med högst cirka 4,75 TB data. Det kanske inte är optimalt när dina data inte är stora, särskilt när du använder lokalt installerad integrationskörning med dåligt nätverk, vilket resulterar i timeout eller prestandaproblem. Du kan uttryckligen ange en blockstorlek, och se till att blockSizeInMB*50000 är tillräckligt stort för att lagra data, annars misslyckas kopieringsaktivitetskörningen. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
| metadata | Ange anpassade metadata när du kopierar till mottagare. Varje objekt under matrisen metadata representerar en extra kolumn. name Definierar namnet på metadatanyckeln value och anger nyckelns datavärde. Om funktionen bevara attribut används kommer angivna metadata att kopplas/skrivas över med källfilens metadata.Tillåtna datavärden är: - $$LASTMODIFIED: en reserverad variabel anger att källfilerna senast ändrades. Gäller endast för filbaserad källa med binärt format.-Uttryck - Statiskt värde |
Nej |
Exempel:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Exempel på mapp- och filfilter
I det här avsnittet beskrivs det resulterande beteendet för mappsökvägen och filnamnet med jokerteckenfilter.
| folderPath | fileName | rekursiv | Källmappens struktur och filterresultat (filer i fetstil hämtas) |
|---|---|---|---|
Folder* |
(Tom, använd standard) | falskt | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(Tom, använd standard) | true | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
falskt | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Exempel på fillista
I det här avsnittet beskrivs det resulterande beteendet för att använda sökvägen till fillistan i kopieringsaktivitetskällan.
Förutsatt att du har följande källmappstruktur och vill kopiera filerna i fetstil:
| Exempel på källstruktur | Innehåll i FileListToCopy.txt | ADF-konfiguration |
|---|---|---|
| filsystem MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Undermapp1/File3.csv Undermapp1/File5.csv |
I datauppsättning: – Mappsökväg: FolderAI kopieringsaktivitetskällan: – Sökväg till fillista: Metadata/FileListToCopy.txt Sökvägen till fillistan pekar på en textfil i samma datalager som innehåller en lista över filer som du vill kopiera, en fil per rad med den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. |
Några rekursiva och copyBehavior-exempel
I det här avsnittet beskrivs det resulterande beteendet för kopieringsåtgärden för olika kombinationer av rekursiva och copyBehavior-värden.
| rekursiv | copyBehavior | Källmappsstruktur | Resulterande mål |
|---|---|---|---|
| true | preserveHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med samma struktur som källan: Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
| true | flatHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med följande struktur: Mapp1 autogenererat namn för File1 autogenererat namn för File2 autogenererat namn för File3 autogenererat namn för File4 autogenererat namn för File5 |
| true | mergeFiles | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med följande struktur: Mapp1 File1 + File2 + File3 + File4 + File5-innehåll sammanfogas i en fil med ett automatiskt genererat filnamn. |
| falskt | preserveHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med följande struktur: Mapp1 Fil1 Fil 2 Undermapp1 med File3, File4 och File5 hämtas inte. |
| falskt | flatHierarchy | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med följande struktur: Mapp1 autogenererat namn för File1 autogenererat namn för File2 Undermapp1 med File3, File4 och File5 hämtas inte. |
| falskt | mergeFiles | Mapp1 Fil1 Fil 2 Undermapp1 Fil 3 Fil 4 Fil5 |
Målmapp1 skapas med följande struktur: Mapp1 Fil1 + Fil2-innehåll sammanfogas i en fil med ett automatiskt genererat filnamn. autogenererat namn för File1 Undermapp1 med File3, File4 och File5 hämtas inte. |
Microsoft Fabric Lakehouse-tabell i kopieringsaktivitet
Om du vill använda Microsoft Fabric Lakehouse Table-datauppsättningen som en käll- eller mottagardatauppsättning i kopieringsaktiviteten går du till följande avsnitt för detaljerade konfigurationer.
Microsoft Fabric Lakehouse-tabell som källtyp
Om du vill kopiera data från Microsoft Fabric Lakehouse med datauppsättningen Microsoft Fabric Lakehouse Table anger du typegenskapen i kopieringsaktivitetskällan till LakehouseTableSource. Följande egenskaper stöds i avsnittet Kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till LakehouseTableSource. | Ja |
| timestampAsOf | Tidsstämpeln för att fråga en äldre ögonblicksbild. | Nej |
| versionAsOf | Versionen för att köra frågor mot en äldre ögonblicksbild. | Nej |
Exempel:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Table som mottagartyp
Om du vill kopiera data till Microsoft Fabric Lakehouse med datauppsättningen Microsoft Fabric Lakehouse Table anger du typegenskapen i mottagaren Kopiera aktivitet till LakehouseTableSink. Följande egenskaper stöds i avsnittet Kopiera aktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till LakehouseTableSink. | Ja |
Kommentar
Data skrivs till Lakehouse Table i V-Order som standard. Mer information finns i Delta Lake-tabelloptimering och V-Order.
Exempel:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Mappa dataflödesegenskaper
När du transformerar data i dataflödets mappning kan du läsa och skriva till filer eller tabeller i Microsoft Fabric Lakehouse. Mer information finns i motsvarande avsnitt.
- Microsoft Fabric Lakehouse Files i mappning av dataflöde
- Microsoft Fabric Lakehouse-tabell i mappning av dataflöde
Mer information finns i källtransformering och mottagartransformation i mappning av dataflöden.
Microsoft Fabric Lakehouse Files i mappning av dataflöde
Om du vill använda Datauppsättningen Microsoft Fabric Lakehouse Files som källa eller mottagare i dataflödet för mappning går du till följande avsnitt för de detaljerade konfigurationerna.
Microsoft Fabric Lakehouse Files som käll- eller mottagartyp
Microsoft Fabric Lakehouse-anslutningsappen stöder följande filformat. Se varje artikel för formatbaserade inställningar.
Om du vill använda Fabric Lakehouse-filbaserad anslutningsapp i infogad datamängdstyp måste du välja rätt typ av infogad datamängd för dina data. Du kan använda DelimitedText, Avro, JSON, ORC eller Parquet beroende på ditt dataformat.
Microsoft Fabric Lakehouse-tabell i mappning av dataflöde
Om du vill använda Microsoft Fabric Lakehouse Table-datauppsättningen som en käll- eller mottagardatauppsättning i dataflödet för mappning går du till följande avsnitt för detaljerade konfigurationer.
Microsoft Fabric Lakehouse-tabell som källtyp
Det finns inga konfigurerbara egenskaper under källalternativ.
Kommentar
CDC-stöd för Lakehouse-tabellkällan är för närvarande inte tillgängligt.
Microsoft Fabric Lakehouse Table som mottagartyp
Följande egenskaper stöds i avsnittet Mappa dataflöden mottagare:
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Uppdatera metod | När du väljer "Tillåt infoga" ensam eller när du skriver till en ny deltatabell tar målet emot alla inkommande rader oavsett radprinciperna som angetts. Om dina data innehåller rader med andra radprinciper måste de undantas med hjälp av en tidigare filtertransformering. När alla uppdateringsmetoder har valts utförs en Sammanslagning, där rader infogas/tas bort/upserted/uppdateras enligt radprinciperna som angetts med hjälp av en föregående Alter Row-transformering. |
ja | true eller false |
infogningsbar kan tas bort upsertable kan uppdateras |
| Optimerad skrivning | Uppnå högre dataflöde för skrivåtgärder via optimering av intern blandning i Spark-köre. Därför kan du märka färre partitioner och filer som är av större storlek | nej | true eller false |
optimizedWrite: true |
| Automatisk komprimering | När en skrivåtgärd har slutförts kör OPTIMIZE Spark automatiskt kommandot för att organisera om data, vilket resulterar i fler partitioner om det behövs, för bättre läsprestanda i framtiden |
nej | true eller false |
autoCompact: true |
| Sammanslagningsschema | Alternativet Sammanslagningsschema tillåter schemautveckling, d.v.s. alla kolumner som finns i den aktuella inkommande strömmen men inte i deltatabellen som mål läggs till automatiskt i schemat. Det här alternativet stöds för alla uppdateringsmetoder. | nej | true eller false |
mergeSchema: true |
Exempel: Microsoft Fabric Lakehouse Table Sink
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
För Fabric Lakehouse-tabellbaserad anslutningsapp i infogad datamängdstyp behöver du bara använda Delta som datamängdstyp. På så sätt kan du läsa och skriva data från Fabric Lakehouse-tabeller.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Egenskaper för GetMetadata-aktivitet
Mer information om egenskaperna finns i GetMetadata-aktivitet
Ta bort aktivitetsegenskaper
Information om egenskaperna finns i Ta bort aktivitet
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i Datalager som stöds.