Kopiera och transformera data i Snowflake med Hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder aktiviteten Kopiera i Azure Data Factory- och Azure Synapse-pipelines för att kopiera data från och till Snowflake och använda Dataflöde för att transformera data i Snowflake. Mer information finns i introduktionsartikeln för Data Factory eller Azure Synapse Analytics.
Viktigt!
Den nya Snowflake-anslutningsappen ger förbättrat inbyggt Snowflake-stöd. Om du använder den äldre Snowflake-anslutningsappen i din lösning rekommenderar vi att du uppgraderar snowflake-anslutningen så snart som möjligt. Mer information om skillnaden mellan den äldre och den senaste versionen finns i det här avsnittet .
Funktioner som stöds
Den här Snowflake-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/mottagare) | (1) (2) |
| Mappa dataflöde (källa/mottagare) | (1) |
| Sökningsaktivitet | (1) (2) |
| Skriptaktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
För aktiviteten Kopiera stöder den här Snowflake-anslutningsappen följande funktioner:
- Kopiera data från Snowflake som använder Snowflakes COPY till kommandot [location] för att uppnå bästa prestanda.
- Kopiera data till Snowflake som drar nytta av Snowflakes COPY till kommandot [table] för att uppnå bästa prestanda. Det stöder Snowflake i Azure.
- Om en proxy krävs för att ansluta till Snowflake från en lokalt installerad integrationskörning måste du konfigurera miljövariablerna för HTTP_PROXY och HTTPS_PROXY på Integration Runtime-värden.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det. Se till att lägga till DE IP-adresser som den lokalt installerade integrationskörningen använder i listan över tillåtna.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Snowflake-kontot som används för Källa eller Mottagare ska ha nödvändig USAGE åtkomst till databasen och läs-/skrivåtkomst för schemat och tabellerna/vyerna under den. Dessutom bör den också ha CREATE STAGE på schemat för att kunna skapa den externa fasen med SAS-URI.
Följande värden för kontoegenskaper måste anges
| Property | Beskrivning | Obligatoriskt | Standardvärde |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Anger om du vill kräva ett lagringsintegreringsobjekt som molnautentiseringsuppgifter när du skapar en namngiven extern fas (med create stage) för att få åtkomst till en lagringsplats för privata moln. | FALSKT | FALSKT |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Anger om du behöver använda en namngiven extern fas som refererar till ett lagringsintegreringsobjekt som molnautentiseringsuppgifter vid inläsning av data från eller avlastning av data till en lagringsplats för privata moln. | FALSKT | FALSKT |
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Kom igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
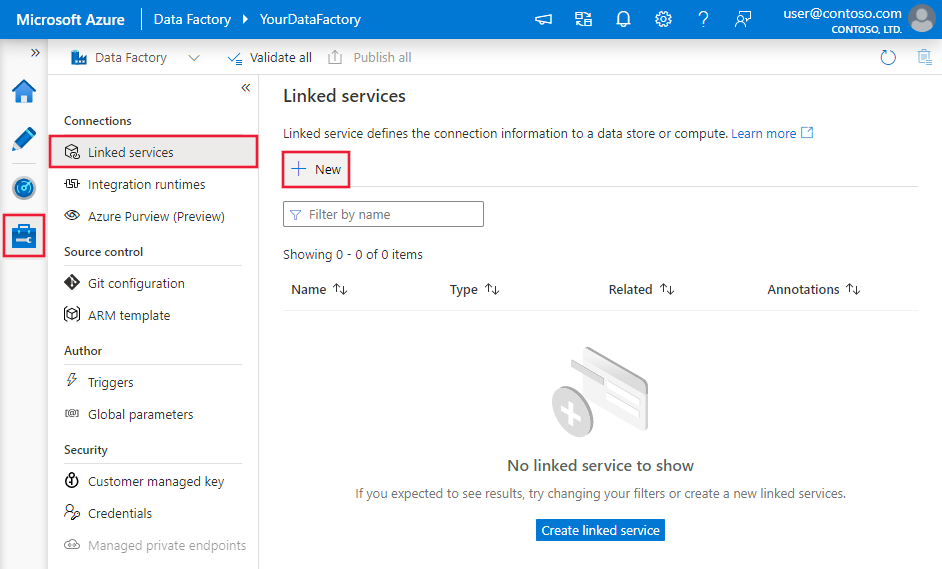
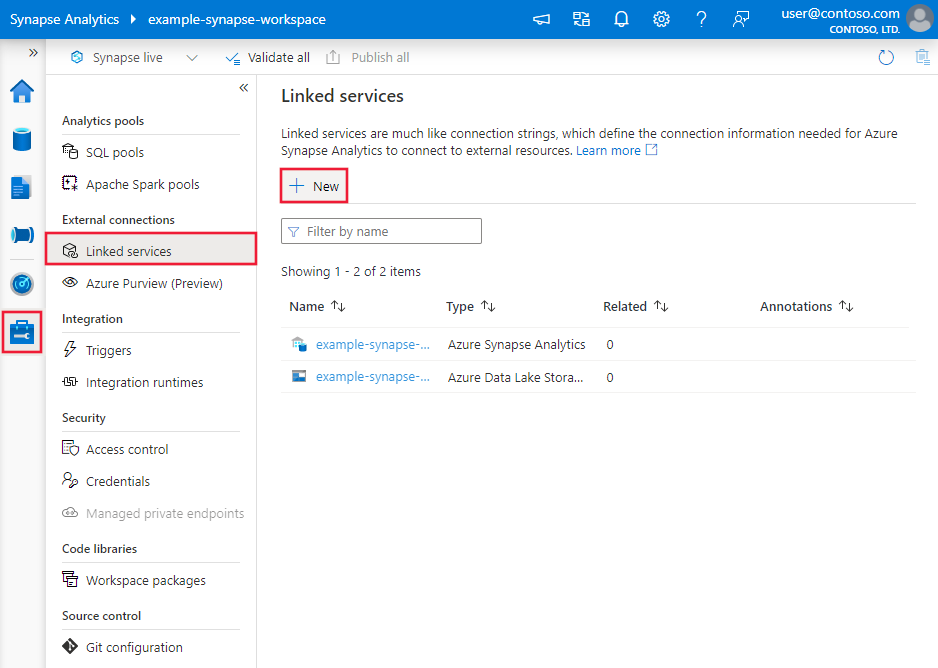
Skapa en länkad tjänst till Snowflake med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Snowflake i användargränssnittet för Azure Portal.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Snowflake och välj Snowflake-anslutningsappen.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.

Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som definierar entiteter som är specifika för en Snowflake-anslutning.
Länkade tjänstegenskaper
Dessa allmänna egenskaper stöds för den länkade Snowflake-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på SnowflakeV2. | Ja |
| accountIdentifier | Namnet på kontot tillsammans med organisationen. Till exempel myorg-account123. | Ja |
| database | Standarddatabasen som används för sessionen efter anslutningen. | Ja |
| lager | Det virtuella standardlager som används för sessionen efter anslutningen. | Ja |
| authenticationType | Typ av autentisering som används för att ansluta till Snowflake-tjänsten. Tillåtna värden är: Basic (standard) och KeyPair. Se motsvarande avsnitt nedan om fler egenskaper respektive exempel. | Nej |
| roll | Standardsäkerhetsrollen som används för sessionen efter anslutningen. | Nej |
| värd | Värdnamnet för Snowflake-kontot. Exempel: contoso.snowflakecomputing.com. .cn stöds också. |
Nej |
| connectVia | Den integrationskörning som används för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Den här Snowflake-anslutningsappen stöder följande autentiseringstyper. Mer information finns i motsvarande avsnitt.
Grundläggande autentisering
Om du vill använda grundläggande autentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| användare | Inloggningsnamn för Snowflake-användaren. | Ja |
| password | Lösenordet för Snowflake-användaren. Markera det här fältet som en SecureString-typ för att lagra det på ett säkert sätt. Du kan också referera till en hemlighet som lagras i Azure Key Vault. | Ja |
Exempel:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Lösenord i Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Kommentar
Mappning Dataflöde stöder endast grundläggande autentisering.
Autentisering med nyckelpar
Om du vill använda autentisering med nyckelpar måste du konfigurera och skapa en autentiseringsanvändare för nyckelpar i Snowflake genom att referera till nyckelparautentisering och nyckelparrotation. Anteckna sedan den privata nyckeln och lösenfrasen (valfritt) som du använder för att definiera den länkade tjänsten.
Förutom de allmänna egenskaper som beskrivs i föregående avsnitt anger du följande egenskaper:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| användare | Inloggningsnamn för Snowflake-användaren. | Ja |
| privateKey | Den privata nyckel som används för nyckelparautentisering. För att säkerställa att den privata nyckeln är giltig när den skickas till Azure Data Factory, och med tanke på att privateKey-filen innehåller nya radtecken (\n), är det viktigt att formatera privateKey-innehållet korrekt i dess strängliteralform. Den här processen innebär att du lägger till \n explicit till varje ny rad. |
Ja |
| privateKeyPassphrase | Lösenfrasen som används för att dekryptera den privata nyckeln, om den är krypterad. | Nej |
Exempel:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar .
Följande egenskaper stöds för Snowflake-datauppsättningen.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till SnowflakeV2Table. | Ja |
| schema | Namnet på schemat. Observera att schemanamnet är skiftlägeskänsligt. | Nej för källa, ja för mottagare |
| table | Namnet på tabellen/vyn. Observera att tabellnamnet är skiftlägeskänsligt. | Nej för källa, ja för mottagare |
Exempel:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Snowflake-källan och mottagaren.
Snowflake som källa
Snowflake Connector använder Snowflakes COPY-kommando till [location] för att uppnå bästa prestanda.
Om datalager och format för mottagare stöds internt av kommandot Snowflake COPY kan du använda aktiviteten Kopiera för att kopiera direkt från Snowflake till mottagare. Mer information finns i Direktkopiering från Snowflake. Annars använder du inbyggd stegvis kopia från Snowflake.
Om du vill kopiera data från Snowflake stöds följande egenskaper i avsnittet aktiviteten Kopiera källa.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för den aktiviteten Kopiera källan måste anges till SnowflakeV2Source. | Ja |
| query | Anger SQL-frågan för att läsa data från Snowflake. Om namnen på schemat, tabellen och kolumnerna innehåller gemener citerar du objektidentifieraren i frågan, t.ex. select * from "schema"."myTable".Det går inte att köra den lagrade proceduren. |
Nej |
| exportSettings | Avancerade inställningar som används för att hämta data från Snowflake. Du kan konfigurera de som stöds av KOMMANDOT KOPIERA till som tjänsten kommer att passera när du anropar -instruktionen. | Ja |
Under exportSettings: |
||
| type | Typ av exportkommando, inställt på SnowflakeExportCopyCommand. | Ja |
| storageIntegration | Ange namnet på din lagringsintegrering som du skapade i Snowflake. Nödvändiga steg för att använda lagringsintegreringen finns i Konfigurera en Snowflake-lagringsintegrering. | Nej |
| additionalCopyOptions | Ytterligare kopieringsalternativ tillhandahålls som en ordlista med nyckel/värde-par. Exempel: MAX_FILE_SIZE, SKRIV ÖVER. Mer information finns i Snowflake-kopieringsalternativ. | Nej |
| additionalFormatOptions | Ytterligare filformatalternativ som tillhandahålls för kommandot COPY som en ordlista med nyckel/värde-par. Exempel: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Mer information finns i Formattypsalternativ för Snowflake. | Nej |
Kommentar
Kontrollera att du har behörighet att köra följande kommando och komma åt schemat INFORMATION_SCHEMA och tabellen KOLUMNER.
COPY INTO <location>
Direktkopia från Snowflake
Om ditt datalager och format för mottagare uppfyller kriterierna som beskrivs i det här avsnittet kan du använda aktiviteten Kopiera för att kopiera direkt från Snowflake till mottagare. Tjänsten kontrollerar inställningarna och misslyckas med aktiviteten Kopiera köras om följande villkor inte uppfylls:
När du anger
storageIntegrationi källan:Datalagret för mottagare är Azure Blob Storage som du refererade till i den externa fasen i Snowflake. Du måste utföra följande steg innan du kopierar data:
Skapa en länkad Azure Blob Storage-tjänst för Azure Blob Storage för mottagare med alla autentiseringstyper som stöds.
Bevilja minst rollen Storage Blob Data Contributor till Tjänstens huvudnamn för Snowflake i azure bloblagringsåtkomstkontroll (IAM) för mottagare.
När du inte anger
storageIntegrationi källan:Den länkade tjänsten för mottagare är Azure Blob Storage med signaturautentisering för delad åtkomst. Om du vill kopiera data direkt till Azure Data Lake Storage Gen2 i följande format som stöds kan du skapa en länkad Azure Blob Storage-tjänst med SAS-autentisering mot ditt Azure Data Lake Storage Gen2-konto för att undvika att använda mellanlagrade kopior från Snowflake.
Dataformatet för mottagare är av Parquet, avgränsad text eller JSON med följande konfigurationer:
- För Parquet-format är komprimeringskodcen Ingen, Snappy eller Lzo.
- För avgränsat textformat :
rowDelimiterär \r\n eller ett enskilt tecken.compressionkan inte vara någon komprimering, gzip, bzip2 eller deflate.encodingNameär kvar som standard eller inställd på utf-8.quoteCharär dubbla citattecken, enkla citattecken eller tomma strängar (inget citattecken).
- För JSON-format stöder direktkopiering endast fallet att snowflake-källtabellen eller frågeresultatet bara har en enda kolumn och datatypen för den här kolumnen är VARIANT, OBJECT eller ARRAY.
compressionkan inte vara någon komprimering, gzip, bzip2 eller deflate.encodingNameär kvar som standard eller inställd på utf-8.filePatterni kopieringsaktivitetsmottagaren lämnas som standard eller inställd på setOfObjects.
I kopieringsaktivitetskällan
additionalColumnsanges inte.Kolumnmappning har inte angetts.
Exempel:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mellanlagrad kopia från Snowflake
När ditt datalager eller format för mottagare inte är inbyggt kompatibelt med kommandot Snowflake COPY, som du nämnde i det förra avsnittet, aktiverar du den inbyggda mellanlagrade kopian med hjälp av en mellanliggande Azure Blob Storage-instans. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Tjänsten exporterar data från Snowflake till mellanlagring, kopierar sedan data till mottagare och rensar slutligen dina tillfälliga data från mellanlagringen. Mer information om hur du kopierar data med mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst som refererar till Azure Storage-kontot som mellanlagring. Ange enableStaging sedan egenskaperna och stagingSettings i aktiviteten Kopiera.
När du anger
storageIntegrationi källan ska mellanlagringen av Azure Blob Storage vara den som du hänvisade till i den externa fasen i Snowflake. Se till att du skapar en länkad Azure Blob Storage-tjänst för den med all autentisering som stöds och bevilja minst rollen Storage Blob Data Contributor till Tjänstens huvudnamn för Snowflake i mellanlagringen av Åtkomstkontroll för Azure Blob Storage (IAM).När du inte anger
storageIntegrationi källan måste den länkade Azure Blob Storage-mellanlagringstjänsten använda signaturautentisering för delad åtkomst, vilket krävs av kommandot Snowflake COPY. Se till att du beviljar rätt åtkomstbehörighet till Snowflake i mellanlagringen av Azure Blob Storage. Mer information om detta finns i den här artikeln.
Exempel:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
När du utför en mellanlagrad kopia från Snowflake är det viktigt att ange beteendet för mottagarkopiering till Sammanfoga filer. Den här inställningen säkerställer att alla partitionerade filer hanteras korrekt och sammanfogas, vilket förhindrar problemet där endast den senaste partitionerade filen kopieras.
Exempelkonfiguration
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Kommentar
Om du inte anger beteendet för mottagarkopiering till Sammanfoga filer kan det bara leda till att den senaste partitionerade filen kopieras.
Snowflake som handfat
Snowflake Connector använder Snowflakes COPY-kommando till [table] för att uppnå bästa prestanda. Det stöder skrivning av data till Snowflake i Azure.
Om källdatalagret och formatet stöds internt av kommandot Snowflake COPY kan du använda aktiviteten Kopiera för att kopiera direkt från källan till Snowflake. Mer information finns i Direktkopiering till Snowflake. Annars använder du inbyggd stegvis kopia till Snowflake.
För att kopiera data till Snowflake stöds följande egenskaper i avsnittet aktiviteten Kopiera mottagare.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för aktiviteten Kopiera mottagare, inställd på SnowflakeV2Sink. | Ja |
| preCopyScript | Ange en SQL-fråga för aktiviteten Kopiera som ska köras innan du skriver data till Snowflake i varje körning. Använd den här egenskapen för att rensa inlästa data. | Nej |
| importSettings | Avancerade inställningar som används för att skriva data till Snowflake. Du kan konfigurera de som stöds av KOMMANDOT KOPIERA till som tjänsten kommer att passera när du anropar -instruktionen. | Ja |
Under importSettings: |
||
| type | Typ av importkommando, inställt på SnowflakeImportCopyCommand. | Ja |
| storageIntegration | Ange namnet på din lagringsintegrering som du skapade i Snowflake. Nödvändiga steg för att använda lagringsintegreringen finns i Konfigurera en Snowflake-lagringsintegrering. | Nej |
| additionalCopyOptions | Ytterligare kopieringsalternativ tillhandahålls som en ordlista med nyckel/värde-par. Exempel: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Mer information finns i Snowflake-kopieringsalternativ. | Nej |
| additionalFormatOptions | Ytterligare filformatalternativ som tillhandahålls till kommandot COPY, som tillhandahålls som en ordlista med nyckel/värde-par. Exempel: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Mer information finns i Formattypsalternativ för Snowflake. | Nej |
Kommentar
Kontrollera att du har behörighet att köra följande kommando och komma åt schemat INFORMATION_SCHEMA och tabellen KOLUMNER.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Direktkopia till Snowflake
Om källdatalagret och formatet uppfyller kriterierna som beskrivs i det här avsnittet kan du använda aktiviteten Kopiera för att kopiera direkt från källan till Snowflake. Tjänsten kontrollerar inställningarna och misslyckas med aktiviteten Kopiera köras om följande villkor inte uppfylls:
När du anger
storageIntegrationi mottagaren:Källdatalagret är Azure Blob Storage som du refererade till i den externa fasen i Snowflake. Du måste utföra följande steg innan du kopierar data:
Skapa en länkad Azure Blob Storage-tjänst för Azure Blob Storage-källan med alla autentiseringstyper som stöds.
Bevilja minst rollen Storage Blob Data Reader till Tjänstens huvudnamn för Snowflake i azure bloblagringsåtkomstkontroll (IAM) för källan.
När du inte anger
storageIntegrationi mottagaren:Den länkade källtjänsten är Azure Blob Storage med signaturautentisering för delad åtkomst. Om du vill kopiera data direkt från Azure Data Lake Storage Gen2 i följande format som stöds kan du skapa en länkad Azure Blob Storage-tjänst med SAS-autentisering mot ditt Azure Data Lake Storage Gen2-konto för att undvika att använda mellanlagrad kopia till Snowflake.
Källdataformatet är Parquet, Avgränsad text eller JSON med följande konfigurationer:
För Parquet-format är komprimeringskodcen Ingen eller Snappy.
För avgränsat textformat :
rowDelimiterär \r\n eller ett enskilt tecken. Om radgränsare inte är "\r\n",firstRowAsHeadermåste vara false ochskipLineCountinte anges.compressionkan inte vara någon komprimering, gzip, bzip2 eller deflate.encodingNameär kvar som standard eller inställt på "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-89", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255".quoteCharär dubbla citattecken, enkla citattecken eller tomma strängar (inget citattecken).
För JSON-format stöder direktkopiering endast skiftläge som sänker Snowflake-tabellen bara har en enda kolumn och datatypen för den här kolumnen är VARIANT, OBJECT eller ARRAY.
compressionkan inte vara någon komprimering, gzip, bzip2 eller deflate.encodingNameär kvar som standard eller inställd på utf-8.- Kolumnmappning har inte angetts.
I aktiviteten Kopiera källa:
additionalColumnshar inte angetts.- Om källan är en mapp är
recursiveden inställd på true. prefix,modifiedDateTimeStart,modifiedDateTimeEndochenablePartitionDiscoveryhar inte angetts.
Exempel:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Mellanlagrad kopia till Snowflake
När ditt källdatalager eller -format inte är inbyggt kompatibelt med kommandot Snowflake COPY, som du nämnde i det förra avsnittet, aktiverar du den inbyggda mellanlagrade kopian med hjälp av en tillfällig Azure Blob Storage-instans. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Tjänsten konverterar automatiskt data för att uppfylla dataformatkraven för Snowflake. Sedan anropas COPY-kommandot för att läsa in data till Snowflake. Slutligen rensas dina tillfälliga data från bloblagringen. Mer information om hur du kopierar data med mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst som refererar till Azure Storage-kontot som mellanlagring. Ange enableStaging sedan egenskaperna och stagingSettings i aktiviteten Kopiera.
När du anger
storageIntegrationi mottagaren bör mellanlagringen av Azure Blob Storage vara den som du hänvisade till i den externa fasen i Snowflake. Se till att du skapar en länkad Azure Blob Storage-tjänst för den med all autentisering som stöds och bevilja minst rollen Storage Blob Data Reader till Snowflake-tjänstens huvudnamn i mellanlagringen av Åtkomstkontroll för Azure Blob Storage (IAM).När du inte anger
storageIntegrationi mottagaren måste den länkade Azure Blob Storage-mellanlagringstjänsten använda signaturautentisering för delad åtkomst enligt vad som krävs av kommandot Snowflake COPY.
Exempel:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Mappa dataflödesegenskaper
När du transformerar data i dataflödet för mappning kan du läsa från och skriva till tabeller i Snowflake. Mer information finns i källtransformering och mottagartransformation i mappning av dataflöden. Du kan välja att använda en Snowflake-datauppsättning eller en infogad datauppsättning som käll- och mottagartyp.
Källtransformering
I tabellen nedan visas de egenskaper som stöds av Snowflake-källan. Du kan redigera dessa egenskaper på fliken Källalternativ. Anslutningsappen använder intern dataöverföring i Snowflake.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Register | Om du väljer Tabell som indata hämtar dataflödet alla data från tabellen som anges i Datamängden Snowflake eller i källalternativen när du använder infogad datauppsättning. | Nej | String | (endast för infogad datamängd) tableName schemaName |
| Fråga | Om du väljer Fråga som indata anger du en fråga för att hämta data från Snowflake. Den här inställningen åsidosätter alla tabeller som du har valt i datauppsättningen. Om namnen på schemat, tabellen och kolumnerna innehåller gemener citerar du objektidentifieraren i frågan, t.ex. select * from "schema"."myTable". |
Nej | String | query |
| Aktivera inkrementellt extrahering (förhandsversion) | Använd det här alternativet om du vill be ADF att endast bearbeta rader som har ändrats sedan den senaste gången pipelinen kördes. | Nej | Booleskt | enableCdc |
| Inkrementell kolumn | När du använder funktionen för inkrementell extrahering måste du välja den datum/tid/numeriska kolumn som du vill använda som vattenstämpel i källtabellen. | Nej | String | waterMarkColumn |
| Aktivera Snowflake Ändringsspårning (förhandsversion) | Med det här alternativet kan ADF använda Snowflakes teknik för att ändra datainsamling för att endast bearbeta deltadata sedan den föregående pipelinekörningen. Det här alternativet läser automatiskt in deltadata med radinfognings-, uppdaterings- och borttagningsåtgärder utan att det krävs någon inkrementell kolumn. | Nej | Booleskt | enableNativeCdc |
| Nettoändringar | När du använder spårning av snowflake-ändringar kan du använda det här alternativet för att hämta deduplicerade ändrade rader eller omfattande ändringar. Deduplicerade ändrade rader visar endast de senaste versionerna av raderna som har ändrats sedan en viss tidpunkt, medan omfattande ändringar visar alla versioner av varje rad som har ändrats, inklusive de som har tagits bort eller uppdaterats. Om du till exempel uppdaterar en rad visas en borttagningsversion och en infogningsversion i omfattande ändringar, men endast infogningsversionen i deduplicerade ändrade rader. Beroende på ditt användningsfall kan du välja det alternativ som passar dina behov. Standardalternativet är falskt, vilket innebär fullständiga ändringar. | Nej | Booleskt | netChanges |
| Inkludera systemkolumner | När du använder snowflake-ändringsspårning kan du använda alternativet systemColumns för att styra om metadataströmkolumnerna som tillhandahålls av Snowflake inkluderas eller exkluderas i utdata för ändringsspårning. Som standard är systemColumns inställt på true, vilket innebär att kolumnerna för metadataström ingår. Du kan ange systemColumns till false om du vill exkludera dem. | Nej | Booleskt | systemColumns |
| Börja läsa från början | Om du anger det här alternativet med inkrementell extrahering och ändringsspårning instrueras ADF att läsa alla rader vid första körningen av en pipeline med inkrementellt extrahering aktiverat. | Nej | Booleskt | skipInitialLoad |
Exempel på Snowflake-källskript
När du använder Snowflake-datauppsättningen som källtyp är det associerade dataflödesskriptet:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Om du använder infogad datauppsättning är det associerade dataflödesskriptet:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Intern Ändringsspårning
Azure Data Factory har nu stöd för en inbyggd funktion i Snowflake som kallas ändringsspårning, vilket innebär spårning av ändringar i form av loggar. Med den här funktionen i snowflake kan vi spåra ändringar i data över tid, vilket gör det användbart för inkrementell datainläsning och granskning. När du aktiverar Ändra datainsamling och väljer Snowflake-Ändringsspårning skapar vi ett Stream-objekt för källtabellen som möjliggör ändringsspårning i snowflake-källtabellen. Därefter använder vi CHANGES-satsen i vår fråga för att hämta endast nya eller uppdaterade data från källtabellen. Vi rekommenderar också att du schemalägger pipelinen så att ändringar förbrukas inom intervallet för datakvarhållningstid som angetts för snowflake-källtabellen, annars kan användaren se inkonsekvent beteende i insamlade ändringar.
Transformering av mottagare
I tabellen nedan visas de egenskaper som stöds av Snowflake-mottagare. Du kan redigera de här egenskaperna på fliken Inställningar . När du använder infogad datauppsättning visas ytterligare inställningar, som är samma som egenskaperna som beskrivs i avsnittet egenskaper för datamängd. Anslutningsappen använder intern dataöverföring i Snowflake.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Uppdatera metod | Ange vilka åtgärder som tillåts på ditt Snowflake-mål. För att uppdatera, öka eller ta bort rader krävs en Alter row-transformering för att tagga rader för dessa åtgärder. |
Ja | true eller false |
kan tas bort infogningsbar kan uppdateras upsertable |
| Nyckelkolumner | För uppdateringar, upserts och borttagningar måste en nyckelkolumn eller kolumner anges för att avgöra vilken rad som ska ändras. | Nej | Matris | keys |
| Tabellåtgärd | Avgör om du vill återskapa eller ta bort alla rader från måltabellen innan du skriver. - Ingen: Ingen åtgärd utförs i tabellen. - Återskapa: Tabellen tas bort och återskapas. Krävs om du skapar en ny tabell dynamiskt. - Trunkera: Alla rader från måltabellen tas bort. |
Nej | true eller false |
återskapa trunkera |
Exempel på snowflake-mottagarskript
När du använder Snowflake-datauppsättningen som mottagartyp är det associerade dataflödesskriptet:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Om du använder infogad datauppsättning är det associerade dataflödesskriptet:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Optimering av pushdown-frågor
Genom att ange loggningsnivån för pipelinen till Ingen exkluderar vi överföringen av mellanliggande transformeringsmått, förhindrar potentiella hinder för Spark-optimeringar och aktiverar optimering av pushdown-frågor som tillhandahålls av Snowflake. Den här pushdown-optimeringen möjliggör betydande prestandaförbättringar för stora Snowflake-tabeller med omfattande datauppsättningar.
Kommentar
Vi stöder inte tillfälliga tabeller i Snowflake eftersom de är lokala för sessionen eller användaren som skapar dem, vilket gör dem otillgängliga för andra sessioner och är benägna att skrivas över som vanliga tabeller av Snowflake. Även om Snowflake erbjuder tillfälliga tabeller som ett alternativ, som är tillgängliga globalt, kräver de manuell borttagning, vilket strider mot vårt primära mål att använda Temp-tabeller, vilket är att undvika borttagningsåtgärder i källschemat.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Uppgradera Snowflake-anslutningsappen
Om du vill uppgradera Snowflake-anslutningsappen kan du göra en sida-vid-sida-uppgradering eller en uppgradering på plats.
Sida vid sida-uppgradering
Utför följande steg för att utföra en sida vid sida-uppgradering:
- Skapa en ny Snowflake-länkad tjänst och konfigurera den genom att referera till de länkade tjänstegenskaperna.
- Skapa en datauppsättning baserat på den nyligen skapade snowflake-länkade tjänsten.
- Ersätt den nya länkade tjänsten och datauppsättningen med de befintliga i pipelines som riktar sig mot de äldre objekten.
Uppgradering på plats
Om du vill utföra en uppgradering på plats måste du redigera den befintliga länkade tjänstnyttolasten och uppdatera datauppsättningen för att använda den nya länkade tjänsten.
Uppdatera typen från Snowflake till SnowflakeV2.
Ändra den länkade tjänstens nyttolast från det äldre formatet till det nya mönstret. Du kan antingen fylla i varje fält från användargränssnittet när du har ändrat den typ som nämns ovan eller uppdatera nyttolasten direkt via JSON-redigeraren. Se avsnittet Länkade tjänstegenskaper i den här artikeln för de anslutningsegenskaper som stöds. Följande exempel visar skillnaderna i nyttolast för äldre och nya Snowflake-länkade tjänster:
Äldre snowflake länkad tjänst JSON-nyttolast:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Ny snowflake länkad tjänst JSON-nyttolast:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Uppdatera datauppsättningen så att den nya länkade tjänsten används. Du kan antingen skapa en ny datauppsättning baserat på den nyligen skapade länkade tjänsten eller uppdatera en befintlig datauppsättnings typegenskap från SnowflakeTable till SnowflakeV2Table.
Skillnader mellan Snowflake och Snowflake (äldre)
Snowflake-anslutningsappen erbjuder nya funktioner och är kompatibel med de flesta funktioner i Snowflake(äldre) anslutningsprogram. Tabellen nedan visar funktionsskillnaderna mellan Snowflake och Snowflake (äldre).
| Snowflake | Snowflake (äldre) |
|---|---|
| Stöd för autentisering med grundläggande och nyckelpar. | Stöd för grundläggande autentisering. |
| Skriptparametrar stöds för närvarande inte i Skriptaktivitet. Du kan också använda dynamiska uttryck för skriptparametrar. Mer information finns i Uttryck och funktioner i Azure Data Factory och Azure Synapse Analytics. | Stöd för skriptparametrar i skriptaktivitet. |
Stöd för BigDecimal i uppslagsaktivitet. NUMBER-typen, enligt definitionen i Snowflake, visas som en sträng i uppslagsaktiviteten. Om du vill dölja den till numerisk typ kan du använda pipelineparametern med funktionen int eller float. Till exempel , int(activity('lookup').output.firstRow.VALUE)float(activity('lookup').output.firstRow.VALUE) |
BigDecimal stöds inte i uppslagsaktivitet. |
Egenskaperna accountIdentifier, warehouse, databaseschema och role används för att upprätta en anslutning. |
Egenskapen connectionstring används för att upprätta en anslutning. |
| tidsstämpeldatatypen i Snowflake läss som Datatypen DateTimeOffset i söknings- och skriptaktiviteten. | tidsstämpeldatatypen i Snowflake läss som DateTime-datatyp i uppslags- och skriptaktivitet. Om du fortfarande behöver använda Datetime-värdet som en parameter i pipelinen efter uppgraderingen av anslutningsappen kan du konvertera DateTimeOffset-typen till DateTime-typ med hjälp av funktionen formatDateTime (rekommenderas) eller concat-funktionen. Till exempel: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') |
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare efter aktiviteten Kopiera finns i datalager och format som stöds.