Pivottransformering i dataflödesmappning
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd pivottransformeringen för att skapa flera kolumner från de unika radvärdena för en enskild kolumn. Pivot är en aggregeringstransformering där du väljer gruppera efter kolumner och genererar pivotkolumner med hjälp av aggregeringsfunktioner.
Konfiguration
Pivottransformeringen kräver tre olika indata: gruppera efter kolumner, pivotnyckeln och hur du genererar de pivoterade kolumnerna
Gruppera efter
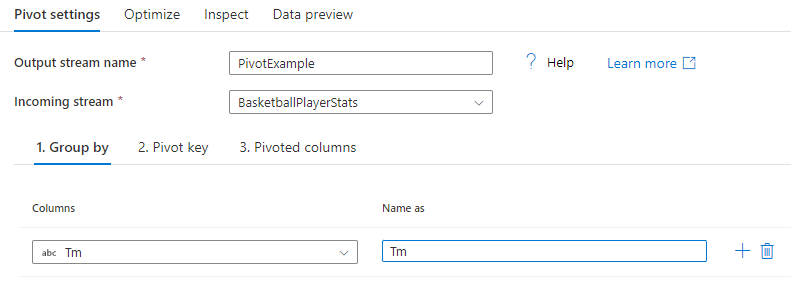
Välj vilka kolumner som de pivoterade kolumnerna ska aggregeras över. Utdata grupperar alla rader med samma grupp efter värden i en rad. Aggregeringen som görs i den pivoterade kolumnen sker över varje grupp.
Det här avsnittet är valfritt. Om ingen grupp efter kolumner väljs aggregeras hela dataströmmen och endast en rad matas ut.
Pivotnyckel
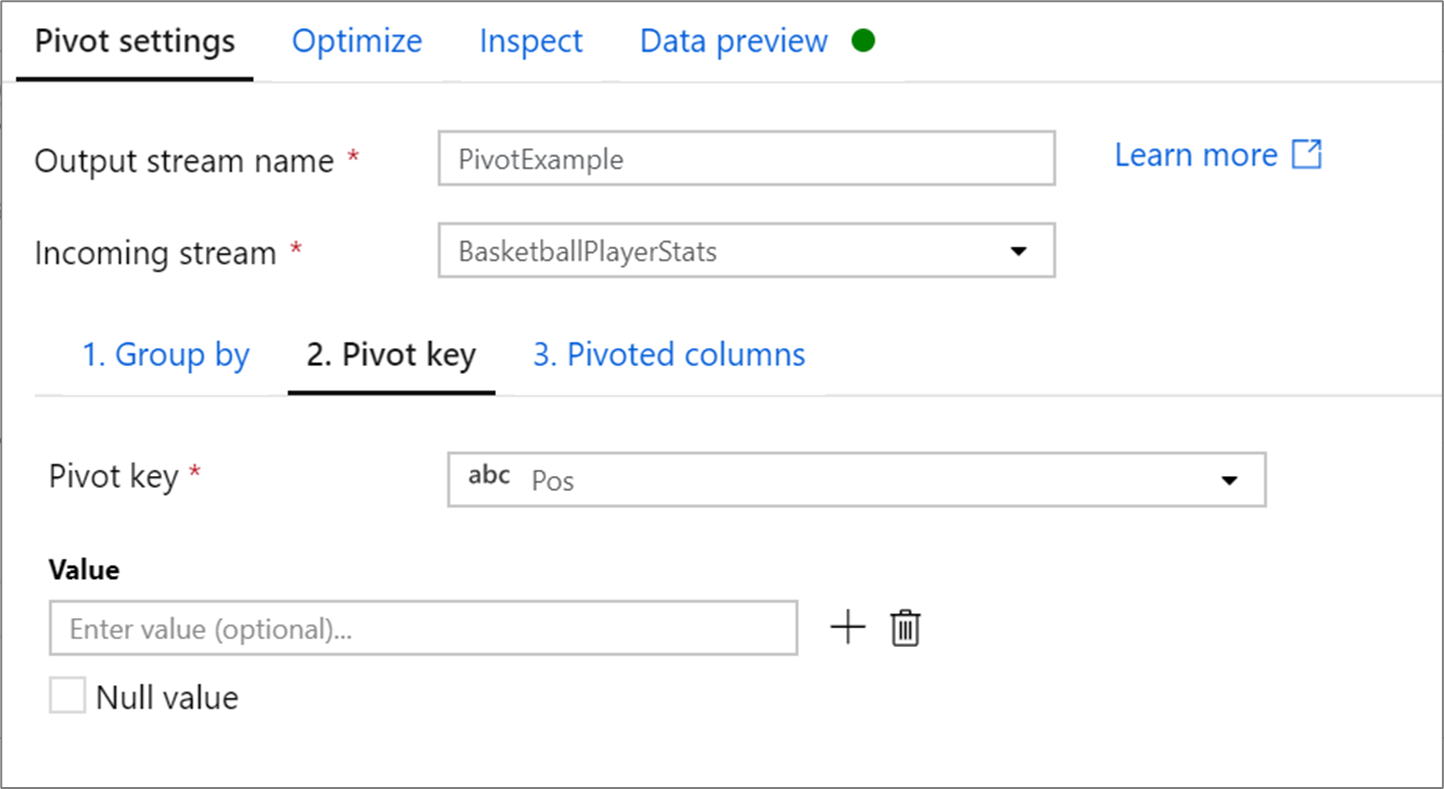
Pivotnyckeln är den kolumn vars radvärden pivoteras till nya kolumner. Som standard skapar pivottransformeringen en ny kolumn för varje unikt radvärde.
I avsnittet med etiketten Värde kan du ange specifika radvärden som ska pivoteras. Endast radvärdena som anges i det här avsnittet pivoteras. Om du aktiverar Null-värdet skapas en pivoterad kolumn för null-värdena i kolumnen.
Pivoterade kolumner
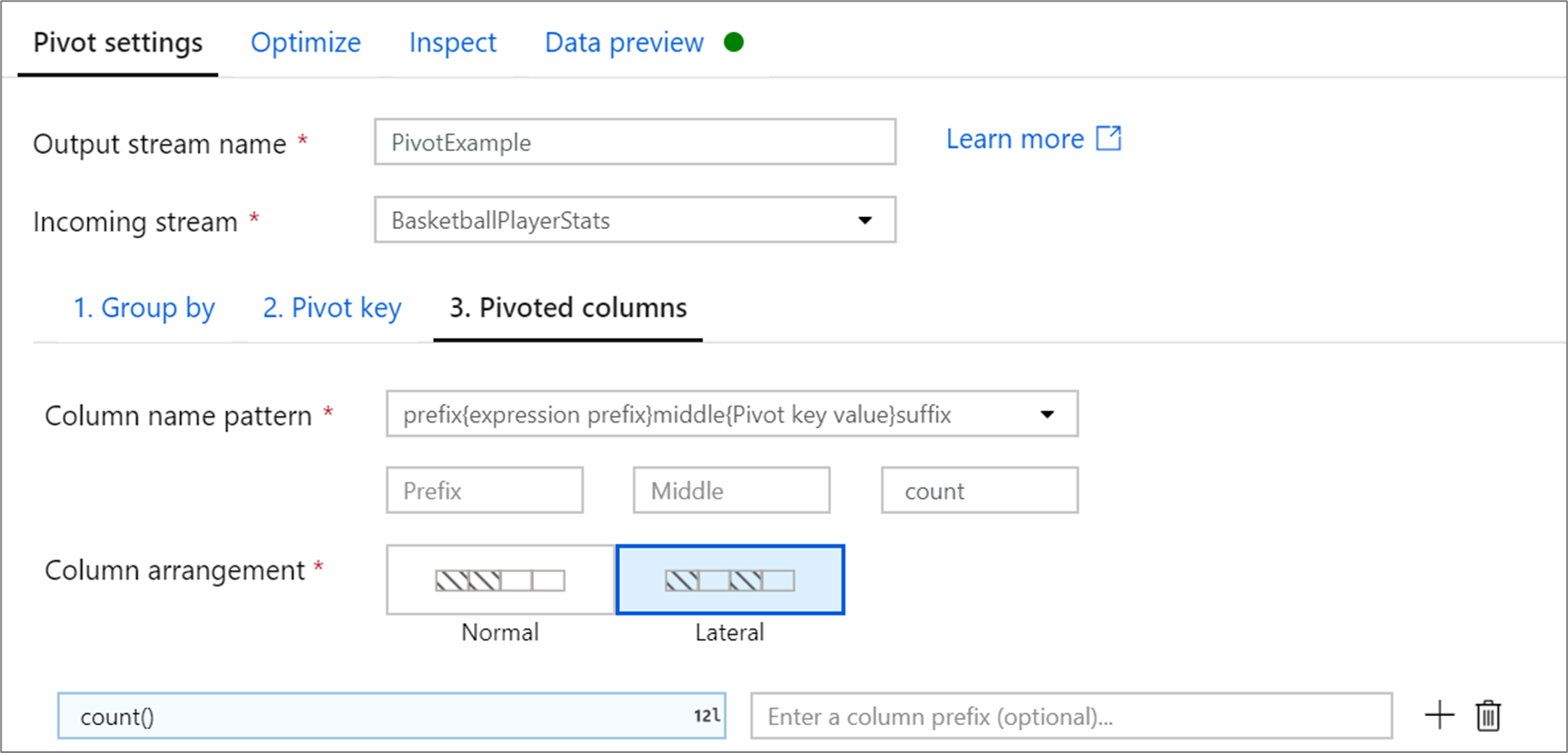
För varje unikt pivotnyckelvärde som blir en kolumn genererar du ett aggregerat radvärde för varje grupp. Du kan skapa flera kolumner per pivotnyckel. Varje pivotkolumn måste innehålla minst en mängdfunktion.
Mönster för kolumnnamn: Välj hur du formaterar kolumnnamnet för varje pivotkolumn. Det utdatakolumnnamnet är en kombination av pivotnyckelvärdet, kolumnprefixet och det valfria prefixet, suffixet, mellantecken.
Kolumnarrangemang: Om du genererar mer än en pivotkolumn per pivotnyckel väljer du hur du vill att kolumnerna ska ordnas.
Kolumnprefix: Om du genererar mer än en pivotkolumn per pivotnyckel anger du ett kolumnprefix för varje kolumn. Den här inställningen är valfri om du bara har en pivoterad kolumn.
Hjälpgrafik
Hjälpgrafiken nedan visar hur de olika pivotkomponenterna interagerar med varandra
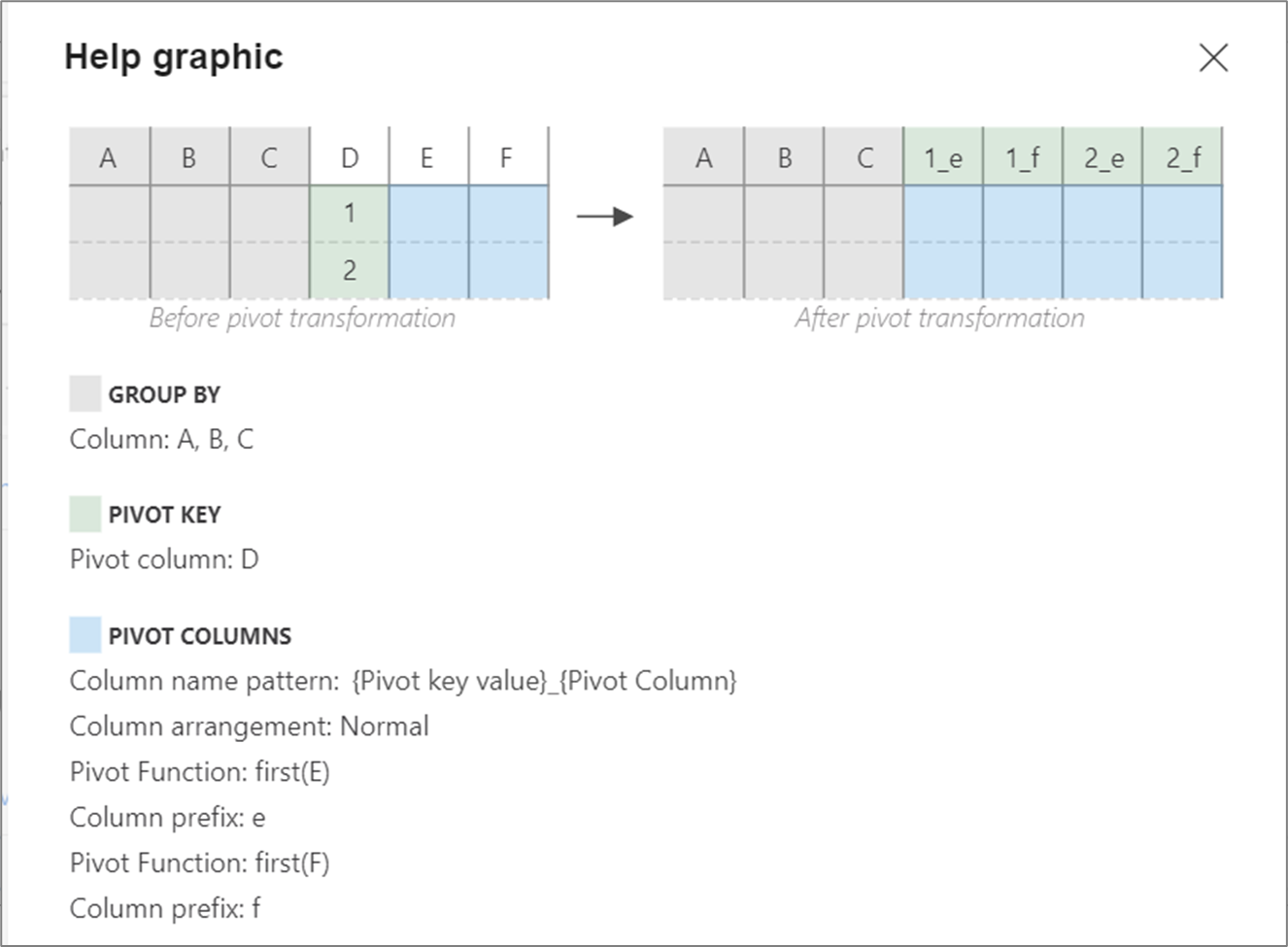
Pivotdata
Om inga värden anges i pivotnyckelkonfigurationen genereras de pivoterade kolumnerna dynamiskt vid körning. Antalet pivoterade kolumner är lika med antalet unika pivotnyckelvärden multiplicerat med antalet pivotkolumner. Eftersom detta kan vara ett föränderligt tal visar UX inte kolumnmetadata på fliken Inspektera och det kommer inte att finnas någon kolumnspridning. Om du vill transformera dessa kolumner använder du kolumnmönsterfunktionerna för att mappa dataflödet.
Om specifika pivotnyckelvärden anges visas de pivoterade kolumnerna i metadata. Kolumnnamnen kommer att vara tillgängliga för dig i mappningen Inspektera och Mottagare.
Generera metadata från driftade kolumner
Pivot genererar nya kolumnnamn dynamiskt baserat på radvärden. Du kan lägga till dessa nya kolumner i metadata som kan refereras senare i dataflödet. Det gör du genom att använda snabbåtgärden map drifted i dataförhandsgranskningen.
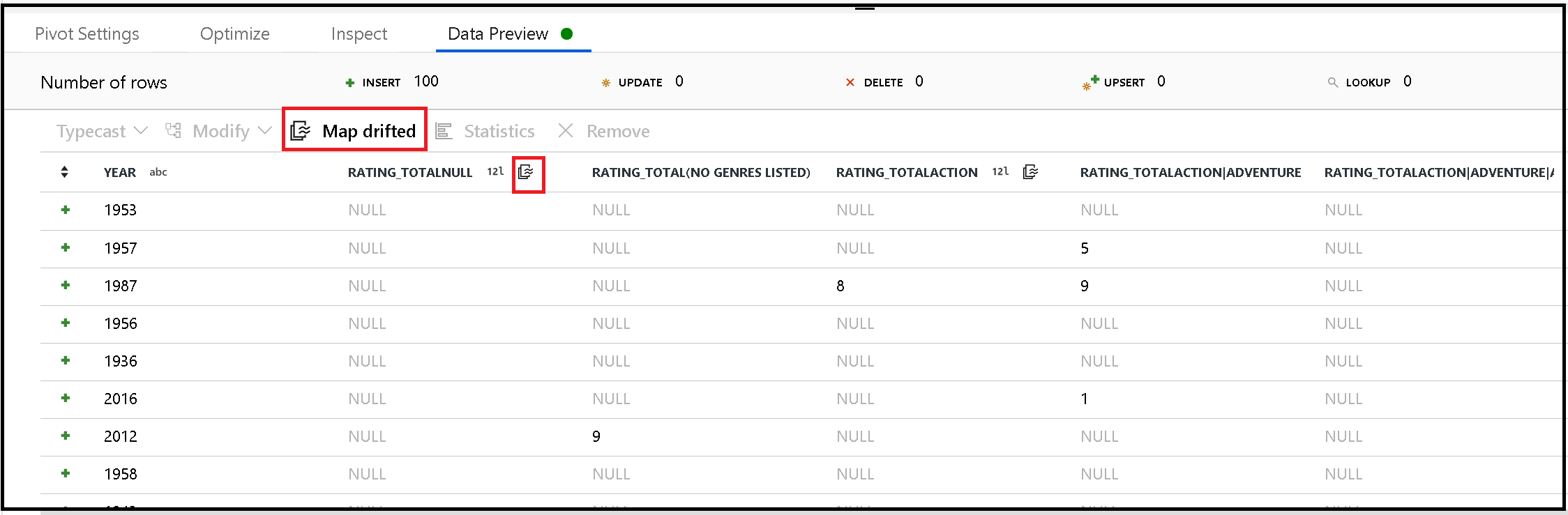
Sjunkande pivoterade kolumner
Även om pivoterade kolumner är dynamiska kan de fortfarande skrivas till måldatalagret. Aktivera Tillåt schemaavvikelse i mottagarinställningarna. På så sätt kan du skriva kolumner som inte ingår i metadata. Du kommer inte att se de nya dynamiska namnen i dina kolumnmetadata, men med alternativet schemaavvikelse kan du landa data.
Återansluta ursprungliga fält
Pivottransformeringen projicerar bara gruppen efter och pivoterade kolumner. Om du vill att utdata ska inkludera andra indatakolumner använder du ett självkopplingsmönster .
Dataflödesskript
Syntax
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Exempel
Skärmarna som visas i konfigurationsavsnittet har följande dataflödesskript:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
Relaterat innehåll
Prova transformeringen unpivot för att omvandla kolumnvärden till radvärden.