Deltaformat i Azure Data Factory
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du kopierar data till och från en deltasjö som lagras i Azure Data Lake Store Gen2 eller Azure Blob Storage med hjälp av deltaformatet. Den här anslutningsappen är tillgänglig som en infogad datauppsättning i mappning av dataflöden som både en källa och en mottagare.
Mappa dataflödesegenskaper
Den här anslutningsappen är tillgänglig som en infogad datauppsättning i mappning av dataflöden som både en källa och en mottagare.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en deltakälla. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Format | Formatet måste vara delta |
ja | delta |
format |
| Filsystem | Container-/filsystemet i deltasjön | ja | String | fileSystem |
| Folder path | Katalogen för deltasjön | ja | String | folderPath |
| Komprimeringstyp | Komprimeringstypen för deltatabellen | nej | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | Välj om komprimeringen ska slutföras så snabbt som möjligt eller om den resulterande filen ska komprimeras optimalt. | krävs om compressedType anges. |
Optimal eller Fastest |
compressionLevel |
| Tidsresa | Välj om du vill köra frågor mot en äldre ögonblicksbild av en deltatabell | nej | Fråga efter tidsstämpel: Tidsstämpel Fråga efter version: Heltal |
timestampAsOf versionAsOf |
| Tillåt att inga filer hittas | Om sant utlöses inte ett fel om inga filer hittas | nej | true eller false |
ignoreNoFilesFound |
Importera schema
Delta är endast tillgängligt som en infogad datauppsättning och har som standard inget associerat schema. Om du vill hämta kolumnmetadata klickar du på knappen Importera schema på fliken Projektion . På så sätt kan du referera till kolumnnamnen och datatyperna som anges av corpus. Om du vill importera schemat måste en dataflödesbugingsession vara aktiv och du måste ha en befintlig CDM-entitetsdefinitionsfil att peka på.
Exempel på deltakällaskript
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Egenskaper för mottagare
I tabellen nedan visas de egenskaper som stöds av en deltamottagare. Du kan redigera de här egenskaperna på fliken Inställningar .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Format | Formatet måste vara delta |
ja | delta |
format |
| Filsystem | Container-/filsystemet i deltasjön | ja | String | fileSystem |
| Folder path | Katalogen för deltasjön | ja | String | folderPath |
| Komprimeringstyp | Komprimeringstypen för deltatabellen | nej | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | Välj om komprimeringen ska slutföras så snabbt som möjligt eller om den resulterande filen ska komprimeras optimalt. | krävs om compressedType anges. |
Optimal eller Fastest |
compressionLevel |
| Vakuum | Tar bort filer som är äldre än den angivna varaktigheten som inte längre är relevanta för den aktuella tabellversionen. När ett värde på 0 eller mindre anges utförs inte vakuumåtgärden. | ja | Integer | vakuum |
| Tabellåtgärd | Talar om för ADF vad du ska göra med deltatabellen i måltabellen i mottagaren. Du kan lämna den som den är och lägga till nya rader, skriva över den befintliga tabelldefinitionen och data med nya metadata och data, eller behålla den befintliga tabellstrukturen men först trunkera alla rader och sedan infoga de nya raderna. | nej | Ingen, Trunkera, Skriv över | deltaTruncate, overwrite |
| Uppdatera metod | När du väljer "Tillåt infoga" ensam eller när du skriver till en ny deltatabell tar målet emot alla inkommande rader oavsett radprinciperna som angetts. Om dina data innehåller rader med andra radprinciper måste de undantas med hjälp av en tidigare filtertransformering. När alla uppdateringsmetoder har valts utförs en Sammanslagning, där rader infogas/tas bort/upserted/uppdateras enligt radprinciperna som angetts med hjälp av en föregående Alter Row-transformering. |
ja | true eller false |
infogningsbar kan tas bort upsertable kan uppdateras |
| Optimerad skrivning | Uppnå högre dataflöde för skrivåtgärder via optimering av intern blandning i Spark-köre. Därför kan du märka färre partitioner och filer som är av större storlek | nej | true eller false |
optimizedWrite: true |
| Automatisk komprimering | När en skrivåtgärd har slutförts kör OPTIMIZE Spark automatiskt kommandot för att ordna om data, vilket resulterar i fler partitioner om det behövs, för bättre läsprestanda i framtiden |
nej | true eller false |
autoCompact: true |
Exempel på deltamottagareskript
Det associerade dataflödesskriptet är:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Deltamottagare med partitionsrensning
Med det här alternativet under Uppdateringsmetod ovan (t.ex. update/upsert/delete) kan du begränsa antalet partitioner som inspekteras. Endast partitioner som uppfyller det här villkoret hämtas från målarkivet. Du kan ange en fast uppsättning värden som en partitionskolumn kan ta.
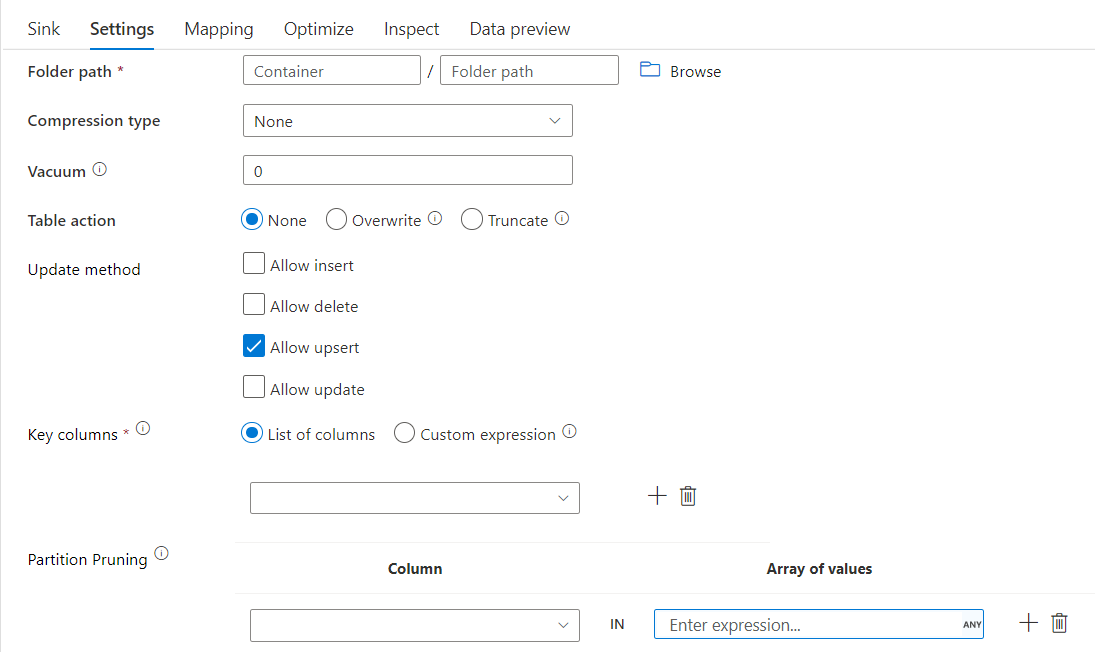
Exempel på skript för deltamottagare med partitionsrensning
Ett exempelskript anges enligt nedan.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta läser bara 2 partitioner där part_col == 5 och 8 från måldeltatarkivet i stället för alla partitioner. part_col är en kolumn som måldeltatdata partitioneras av. Den behöver inte finnas i källdata.
Alternativ för optimering av deltamottagare
På fliken Inställningar hittar du ytterligare tre alternativ för att optimera omvandlingen av deltamottagare.
När alternativet Slå samman schema är aktiverat tillåter det schemautveckling, dvs. alla kolumner som finns i den aktuella inkommande strömmen men inte i deltatabellen för mål läggs automatiskt till i schemat. Det här alternativet stöds för alla uppdateringsmetoder.
När Automatisk komprimering är aktiverat kontrollerar transformering efter en enskild skrivning om filer kan komprimeras ytterligare och kör ett snabbt OPTIMIZE-jobb (med filstorlekar på 128 MB i stället för 1 GB) för att ytterligare komprimera filer för partitioner som har flest antal små filer. Automatisk komprimering hjälper till att samla ett stort antal små filer i ett mindre antal stora filer. Automatisk komprimering startar bara när det finns minst 50 filer. När en komprimeringsåtgärd har utförts skapar den en ny version av tabellen och skriver en ny fil som innehåller data från flera tidigare filer i ett komprimerat komprimerat format.
När Optimera skrivning är aktiverat optimerar mottagartransformeringen dynamiskt partitionsstorlekarna baserat på faktiska data genom att försöka skriva ut 128 MB filer för varje tabellpartition. Det här är en ungefärlig storlek och kan variera beroende på datamängdens egenskaper. Optimerade skrivningar förbättrar den övergripande effektiviteten för skrivningar och efterföljande läsningar. Den organiserar partitioner så att prestandan för efterföljande läsningar förbättras.
Dricks
Den optimerade skrivprocessen gör ditt övergripande ETL-jobb långsammare eftersom sink utfärdar Spark Delta Lake Optimize-kommandot när dina data har bearbetats. Vi rekommenderar att du använder optimerad skrivning sparsamt. Om du till exempel har en datapipeline per timme kör du ett dataflöde med Optimerad skrivning dagligen.
Kända begränsningar
När du skriver till en deltamottagare finns det en känd begränsning där antalet rader som skrivs inte visas i övervakningsutdata.
Relaterat innehåll
- Skapa en källtransformering i dataflödet för mappning.
- Skapa en mottagartransformering i dataflödet för mappning.
- Skapa en ändringsradtransformering för att markera rader som infoga, uppdatera, upsert eller ta bort.