Iterativ utveckling och felsökning med Azure Data Factory- och Synapse Analytics-pipelines
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Data Factory och Synapse Analytics stöder iterativ utveckling och felsökning av pipelines. Med de här funktionerna kan du testa ändringarna innan du skapar en pull-begäran eller publicerar dem till tjänsten.
En åtta minuter lång introduktion och demonstration av den här funktionen finns i följande video:
Felsöka en pipeline
När du redigerar med pipelinearbetsytan kan du testa dina aktiviteter med hjälp av felsökningsfunktionen . När du gör testkörningar behöver du inte publicera ändringarna i tjänsten innan du väljer Felsöka. Den här funktionen är användbar i scenarier där du vill se till att ändringarna fungerar som förväntat innan du uppdaterar arbetsflödet.
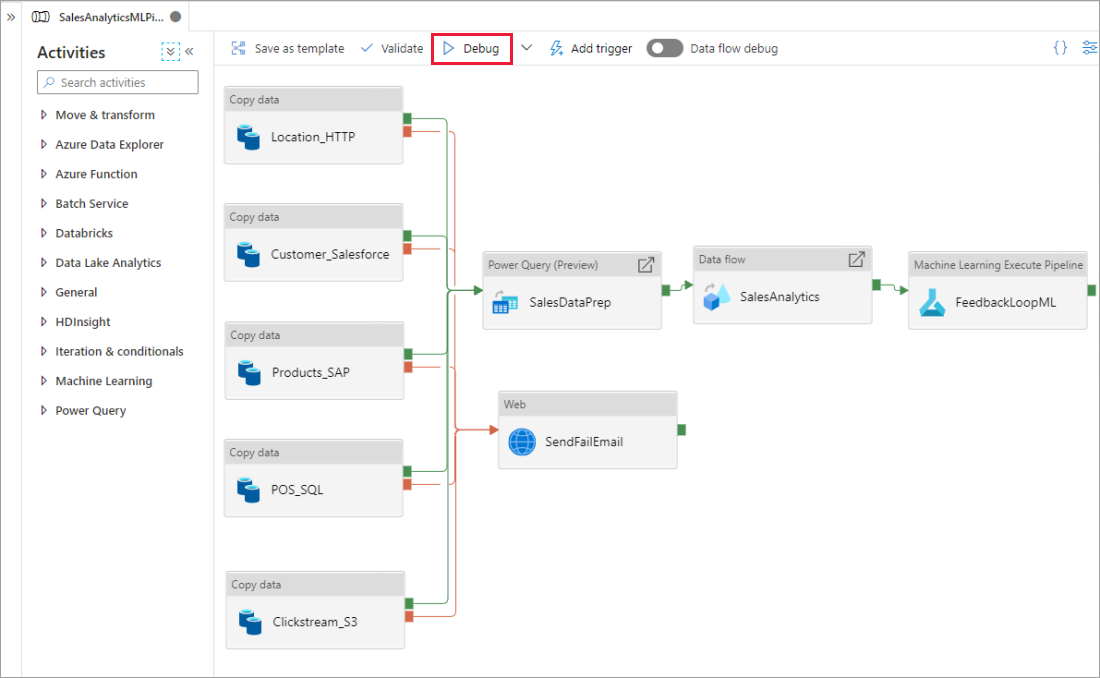
När pipelinen körs kan du se resultatet av varje aktivitet på fliken Utdata på pipelinearbetsytan.
Visa resultatet av dina testkörningar i utdatafönstret på pipelinearbetsytan.
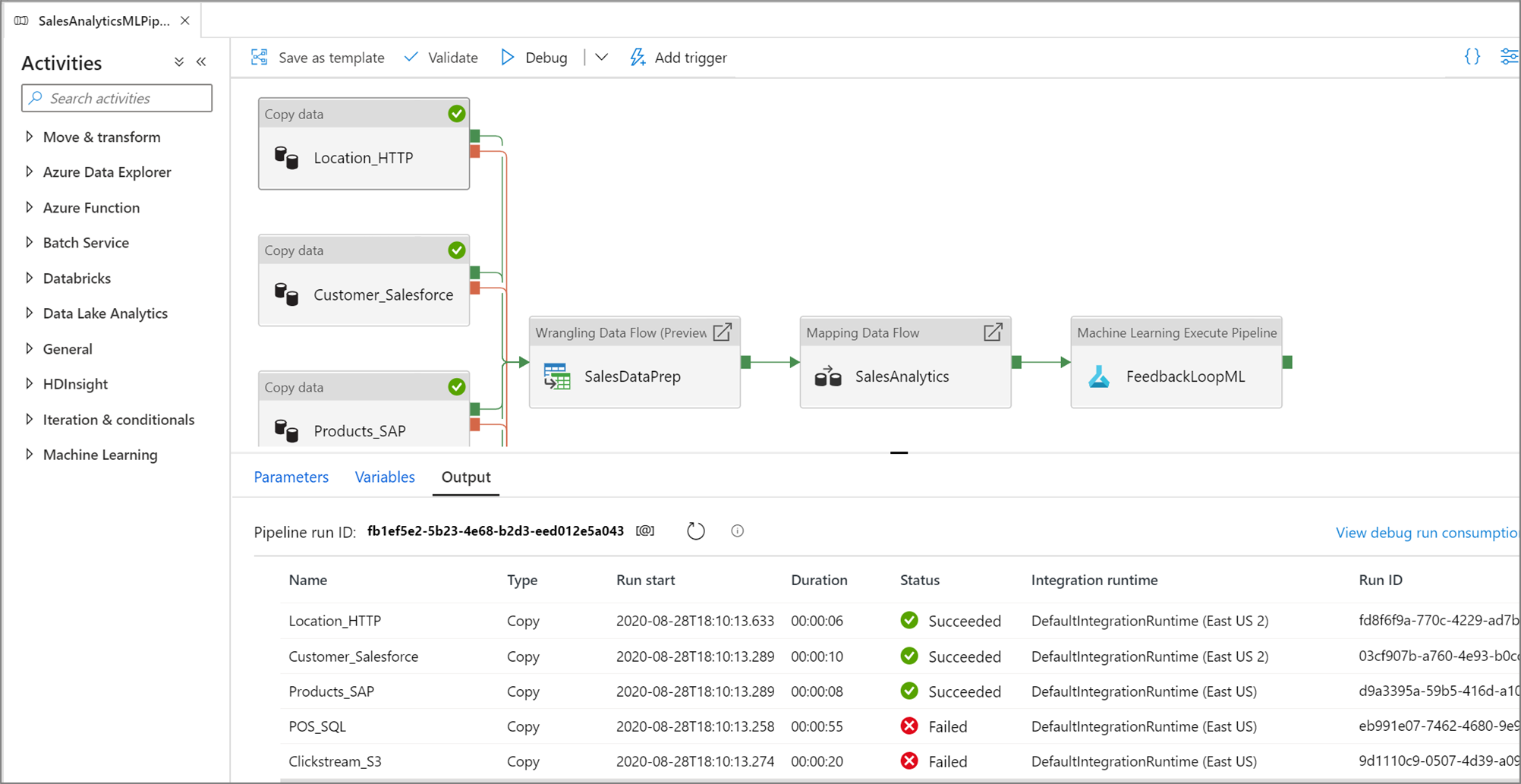
När en testkörning har slutförts lägger du till fler aktiviteter i pipelinen och fortsätter att felsöka på ett iterativt sätt. Du kan också avbryta en testkörning medan den pågår.
Viktigt!
Om du väljer Felsöka körs pipelinen. Om pipelinen till exempel innehåller kopieringsaktivitet kopierar testkörningen data från källa till mål. Därför rekommenderar vi att du använder testmappar i dina kopieringsaktiviteter och andra aktiviteter vid felsökning. När du har debuggat pipelinen växlar du till de faktiska mappar som du vill använda i normala åtgärder.
Ange brytpunkter
Med tjänsten kan du felsöka en pipeline tills du når en viss aktivitet på pipelinearbetsytan. Placera en brytpunkt på aktiviteten tills du vill testa och välj Felsök. Tjänsten ser till att testet endast körs tills brytpunktsaktiviteten på pipelinearbetsytan. Funktionen Felsökning tills är användbar när du inte vill testa hela pipelinen, utan bara en delmängd av aktiviteterna i pipelinen.
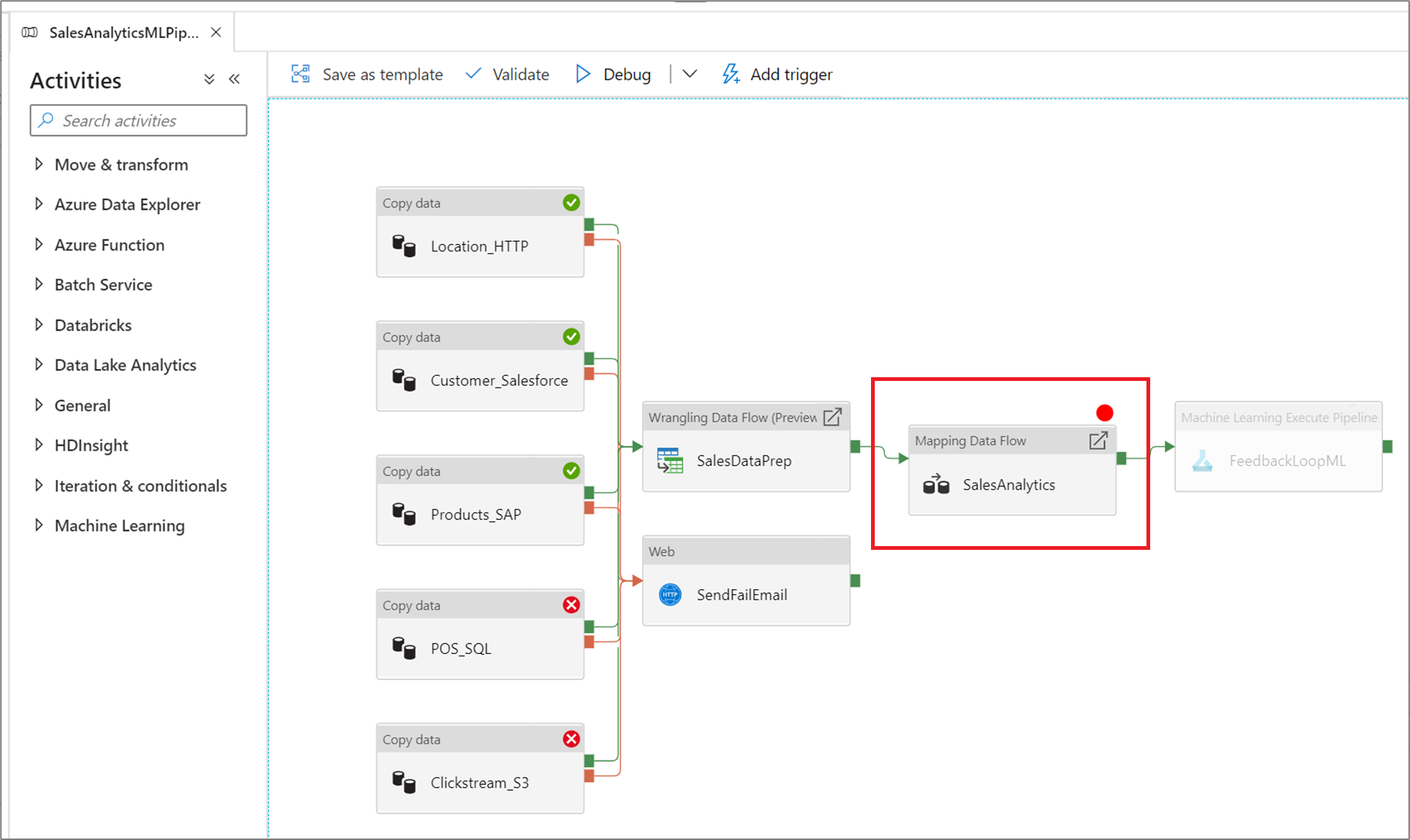
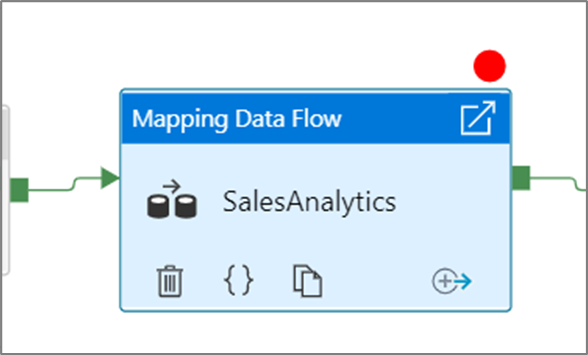
Om du vill ange en brytpunkt väljer du ett element på pipelinearbetsytan. Alternativet Felsök tills visas som en tom röd cirkel i det övre högra hörnet av elementet.
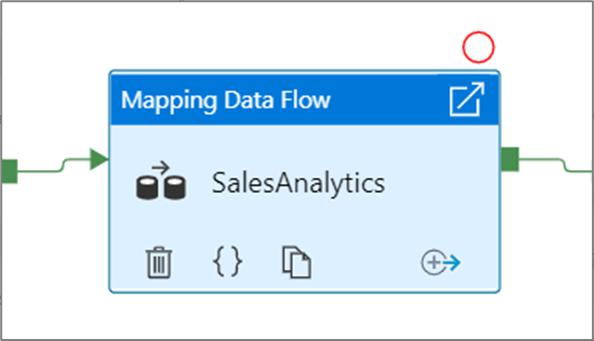
När du har valt alternativet Felsök tills ändras den till en fylld röd cirkel för att indikera att brytpunkten är aktiverad.
Övervaka felsökningskörningar
När du kör en pipeline-felsökningskörning visas resultatet i fönstret Utdata för pipelinearbetsytan. Fliken utdata innehåller bara den senaste körningen som inträffade under den aktuella webbläsarsessionen.
Om du vill visa en historisk vy över felsökningskörningar eller se en lista över alla aktiva felsökningskörningar kan du gå in i övervakningsmiljön.
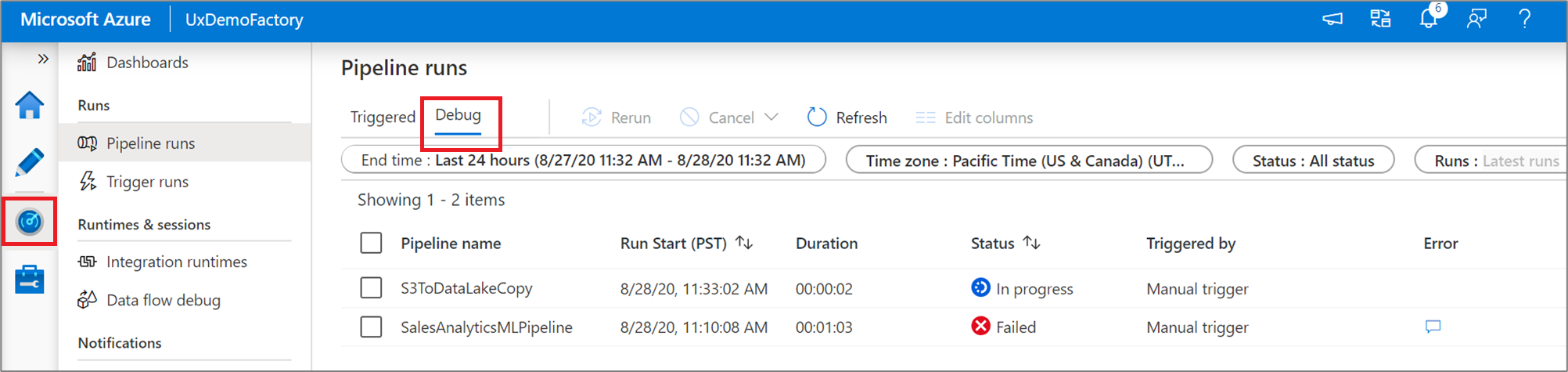
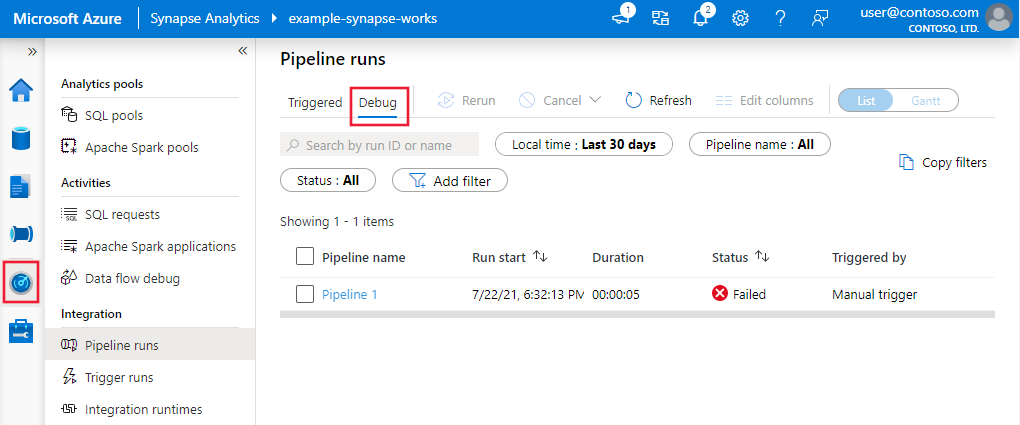
Kommentar
Tjänsten bevarar bara felsökningskörningshistoriken i 15 dagar.
Felsöka mappning av dataflöden
Genom att mappa dataflöden kan du skapa kodfri datatransformeringslogik som körs i stor skala. När du skapar din logik kan du aktivera en felsökningssession för att interaktivt arbeta med dina data med hjälp av ett Live Spark-kluster. Mer information finns i mappning av felsökningsläge för dataflöden.
Du kan övervaka aktiva felsökningssessioner för dataflöden i övervakningsmiljön.
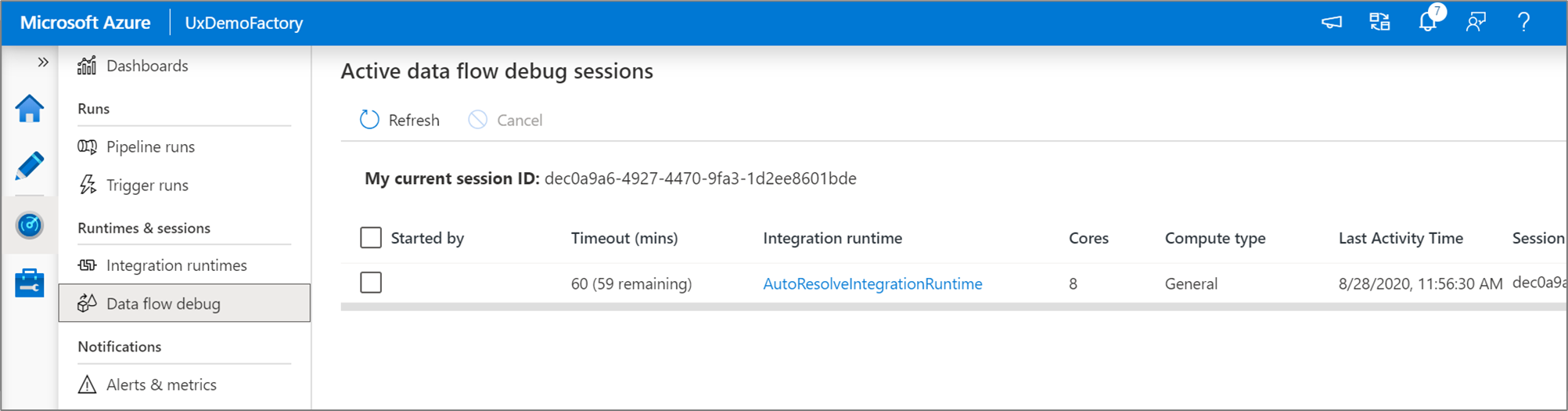
Dataförhandsvisning i dataflödesdesignern och pipeline-felsökning av dataflöden är avsedda att fungera bäst med små dataexempel. Men om du behöver testa logiken i en pipeline eller ett dataflöde mot stora mängder data ökar du storleken på Azure Integration Runtime som används i felsökningssessionen med fler kärnor och ett minimum av generell beräkning.
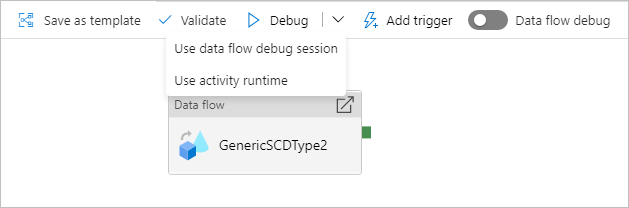
Felsöka en pipeline med en dataflödesaktivitet
När du kör en felsökningspipelinekörning med ett dataflöde har du två alternativ för vilken beräkning som ska användas. Du kan antingen använda ett befintligt felsökningskluster eller starta ett nytt just-in-time-kluster för dina dataflöden.
Om du använder en befintlig felsökningssession minskar starttiden för dataflödet avsevärt eftersom klustret redan körs, men rekommenderas inte för komplexa eller parallella arbetsbelastningar eftersom det kan misslyckas när flera jobb körs samtidigt.
Med hjälp av aktivitetskörningen skapas ett nytt kluster med de inställningar som anges i integreringskörningen för varje dataflödesaktivitet. Detta gör att varje jobb kan isoleras och bör användas för komplexa arbetsbelastningar eller prestandatestning. Du kan också styra TTL i Azure IR så att de klusterresurser som används för felsökning fortfarande är tillgängliga under den tidsperioden för att hantera ytterligare jobbbegäranden.
Kommentar
Om du har en pipeline med dataflöden som körs parallellt eller dataflöden som måste testas med stora datauppsättningar väljer du "Använd aktivitetskörning" så att tjänsten kan använda den integrationskörning som du har valt i dataflödesaktiviteten. Detta gör att dataflöden kan köras på flera kluster och kan hantera dina parallella dataflödeskörningar.
Relaterat innehåll
När du har testat dina ändringar kan du höja upp dem till högre miljöer med kontinuerlig integrering och distribution.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för