Transformera data med hjälp av Hadoop MapReduce-aktivitet i Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
HDInsight MapReduce-aktiviteten i en Azure Data Factory- eller Synapse Analytics-pipeline anropar MapReduce-programmet på egen hand eller på begäran HDInsight-kluster. Den här artikeln bygger på artikeln om datatransformeringsaktiviteter , som visar en allmän översikt över datatransformering och de omvandlingsaktiviteter som stöds.
Mer information finns i introduktionsartiklarna för Azure Data Factory och Synapse Analytics och gör självstudien: Självstudie: transformera data innan du läser den här artikeln.
Mer information om hur du kör Pig/Hive-skript på ett HDInsight-kluster från en pipeline med hjälp av HDInsight Pig- och Hive-aktiviteter finns i Pig och Hive .
Lägga till en HDInsight MapReduce-aktivitet i en pipeline med användargränssnittet
Utför följande steg för att använda en HDInsight MapReduce-aktivitet till en pipeline:
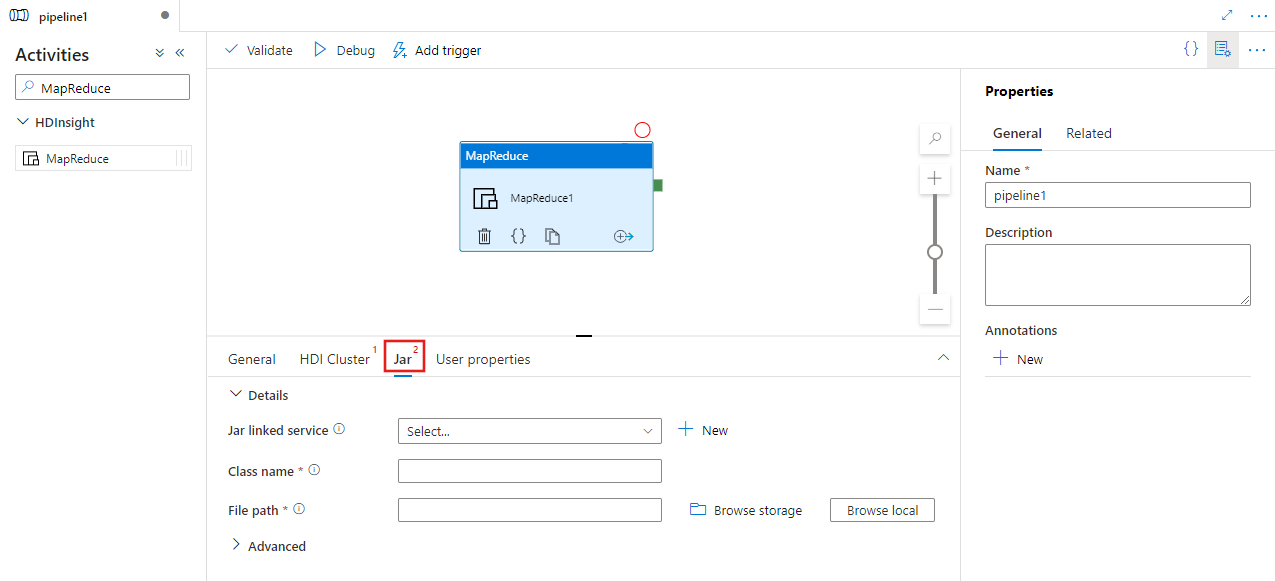
Sök efter MapReduce i fönstret Pipelineaktiviteter och dra en MapReduce-aktivitet till pipelinearbetsytan.
Välj den nya MapReduce-aktiviteten på arbetsytan om den inte redan är markerad.
Välj fliken HDI-kluster för att välja eller skapa en ny länkad tjänst till ett HDInsight-kluster som ska användas för att köra MapReduce-aktiviteten.

Välj fliken Jar för att välja eller skapa en ny jar-länkad tjänst till ett Azure Storage-konto som ska vara värd för skriptet. Ange ett klassnamn som ska köras där och en filsökväg på lagringsplatsen. Du kan också konfigurera avancerad information, inklusive en Jar libs-plats, felsökningskonfiguration och argument och parametrar som ska skickas till skriptet.
Syntax
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntaxinformation
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| name | Namnet på aktiviteten | Ja |
| description | Text som beskriver vad aktiviteten används för | Nej |
| type | För MapReduce-aktivitet är aktivitetstypen HDinsightMapReduce | Ja |
| linkedServiceName | Referens till HDInsight-klustret som registrerats som en länkad tjänst. Mer information om den här länkade tjänsten finns i artikeln Compute linked services (Beräkningslänkade tjänster ). | Ja |
| className | Namnet på den klass som ska köras | Ja |
| jarLinkedService | Referens till en länkad Azure Storage-tjänst som används för att lagra Jar-filerna. Här stöds endast Azure Blob Storage- och ADLS Gen2-länkade tjänster. Om du inte anger den här länkade tjänsten används den länkade Azure Storage-tjänsten som definierats i den länkade HDInsight-tjänsten. | Nej |
| jarFilePath | Ange sökvägen till jar-filerna som lagras i Azure Storage som jarLinkedService refererar till. Filnamnet är skiftlägeskänsligt. | Ja |
| jarlibs | Strängmatris för sökvägen till jar-biblioteksfilerna som refereras av jobbet som lagras i Azure Storage som definieras i jarLinkedService. Filnamnet är skiftlägeskänsligt. | Nej |
| getDebugInfo | Anger när loggfilerna kopieras till Azure Storage som används av HDInsight-klustret (eller) som anges av jarLinkedService. Tillåtna värden: Ingen, Alltid eller Fel. Standardvärde: Ingen. | Nej |
| Argument | Anger en matris med argument för ett Hadoop-jobb. Argumenten skickas som kommandoradsargument till varje uppgift. | Nej |
| Definierar | Ange parametrar som nyckel/värde-par för referens i Hive-skriptet. | Nej |
Exempel
Du kan använda HDInsight MapReduce-aktiviteten för att köra valfri MapReduce-jar-fil i ett HDInsight-kluster. I följande JSON-exempeldefinition för en pipeline konfigureras HDInsight-aktiviteten för att köra en Mahout JAR-fil.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Du kan ange eventuella argument för MapReduce-programmet i avsnittet argument . Vid körning visas några extra argument (till exempel mapreduce.job.tags) från MapReduce-ramverket. Om du vill särskilja argumenten med MapReduce-argumenten bör du överväga att använda både alternativ och värde som argument som visas i följande exempel (-s,--input,--output osv., är alternativ omedelbart följt av deras värden).
Relaterat innehåll
Se följande artiklar som förklarar hur du transformerar data på andra sätt: