Kopiera data på ett säkert sätt från Azure Blob Storage till en SQL-databas med hjälp av privata slutpunkter
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudiekursen skapar du en datafabrik med Azure Data Factory-användargränssnittet. Pipelinen i den här datafabriken kopierar data på ett säkert sätt från Azure Blob Storage till en Azure SQL-databas (båda tillåter åtkomst till endast valda nätverk) med hjälp av privata slutpunkter i Azure Data Factory Managed Virtual Network. Konfigurationsmönstret i den här självstudien gäller kopiering av ett filbaserat datalager till ett relationsdatalager. En lista över datalager som stöds som källor och mottagare finns i tabellen Datalager och format som stöds. Funktionen privata slutpunkter är tillgänglig på alla nivåer i Azure Data Factory, så ingen specifik nivå krävs för att använda dem. Mer information om priser och nivåer finns på sidan med priser för Azure Data Factory.
Kommentar
Om du inte har använt datafabriken tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien gör du följande:
- Skapa en datafabrik.
- Skapa en pipeline med en kopieringsaktivitet.
Förutsättningar
- Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt Azure-konto innan du börjar.
- Azure Storage-konto. Du kan använda Blob Storage som källa för datalagringen. Om du inte har ett lagringskonto finns det anvisningar om hur du skapar ett i Skapa ett Azure Storage-konto. Kontrollera att lagringskontot endast tillåter åtkomst från valda nätverk.
- Azure SQL Database. Du använder databasen som mottagare för datalagringen. Om du inte har någon Azure SQL-databas kan du läsa Skapa en SQL-databas för steg för att skapa en. Kontrollera att SQL Database-kontot endast tillåter åtkomst från valda nätverk.
Skapa en blob och en SQL-tabell
Förbered nu bloblagringen och SQL-databasen för självstudien genom att utföra följande steg.
Skapa en källblob
Öppna Anteckningar. Kopiera följande text och spara den som en emp.txt-fil på din disk:
FirstName,LastName John,Doe Jane,DoeSkapa en container med namnet adftutorial i bloblagringen. Skapa en mapp som heter input i den här containern. Ladda sedan upp filen emp.txt till mappen input. Använd Azure-portalen eller verktyg som Azure Storage Explorer när du gör uppgifterna.
Skapa en SQL-mottagartabell
Använd följande SQL-skript för att skapa tabellen dbo.emp i din SQL-databas:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Skapa en datafabrik
I det här steget skapar du en datafabrik och startar sedan användargränssnittet för datafabriken för att skapa en pipeline i datafabriken.
Öppna Microsoft Edge eller Google Chrome. För närvarande stöder endast Microsoft Edge- och Google Chrome-webbläsare Data Factory-användargränssnittet.
Välj Skapa en resurs>Analys>Data Factory i menyn till vänster.
I fönstret Ny datafabrik, under Namn anger du ADFTutorialDataFactory.
Namnet på Azure Data Factory måste vara globalt unikt. Om du får ett felmeddelande om namnvärdet anger du ett annat namn för datafabriken (till exempel dittnamnADFTutorialDataFactory). Se artikeln om namnregler för datafabriker för namnregler för datafabriksartefakter.
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
- Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
- Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalagren (t.ex. Azure Storage och SQL-databas) och beräkningarna (t.ex. Azure HDInsight) som används i datafabriken kan finnas i andra regioner.
Välj Skapa.
När skapandet är klart visas meddelandet i meddelandecentret. Välj Gå till resurs för att gå till sidan DataFabrik .
Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta användargränssnittet för Data Factory på en separat flik.
Skapa en Azure-integreringskörning i Data Factory Managed Virtual Network
I det här steget skapar du en Azure-integreringskörning och aktiverar Data Factory Managed Virtual Network.
I Data Factory-portalen går du till Hantera och väljer Nytt för att skapa en ny Azure-integreringskörning.
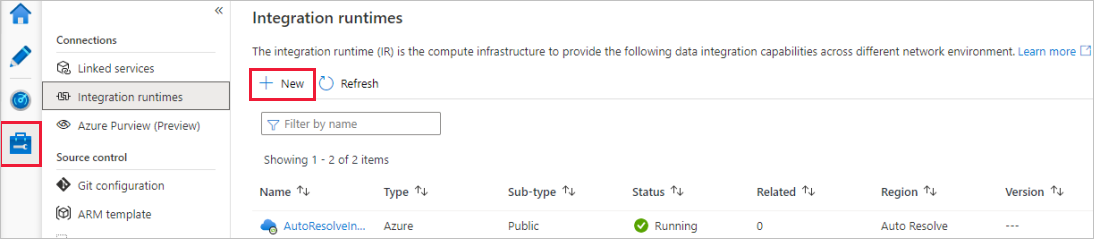
På sidan Installation av integrationskörning väljer du vilken integrationskörning som ska skapas baserat på de funktioner som krävs. I den här självstudien väljer du Azure, Lokalt installerad och klickar sedan på Fortsätt.
Välj Azure och klicka sedan på Fortsätt för att skapa en Azure Integration-körning.
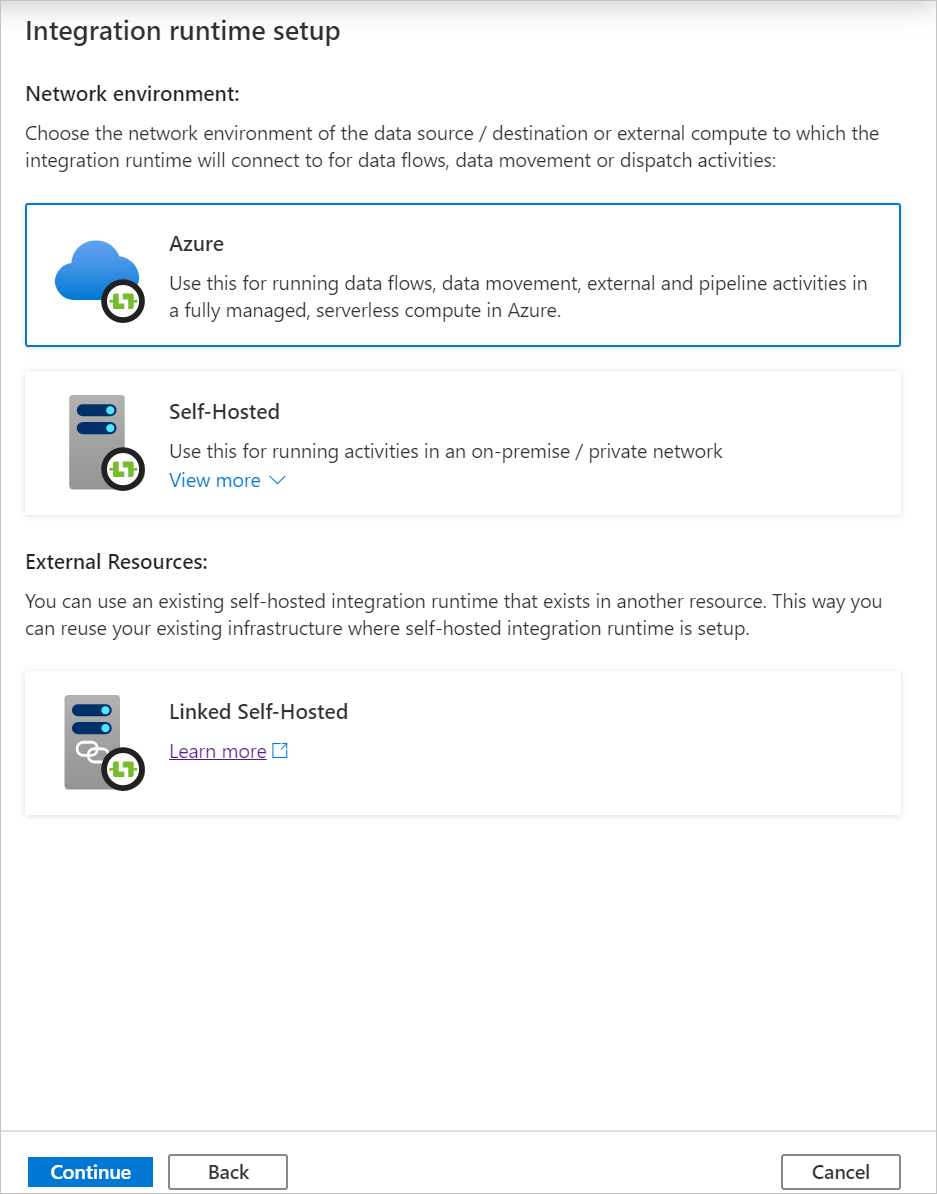
Under Konfiguration av virtuellt nätverk (förhandsversion) väljer du Aktivera.
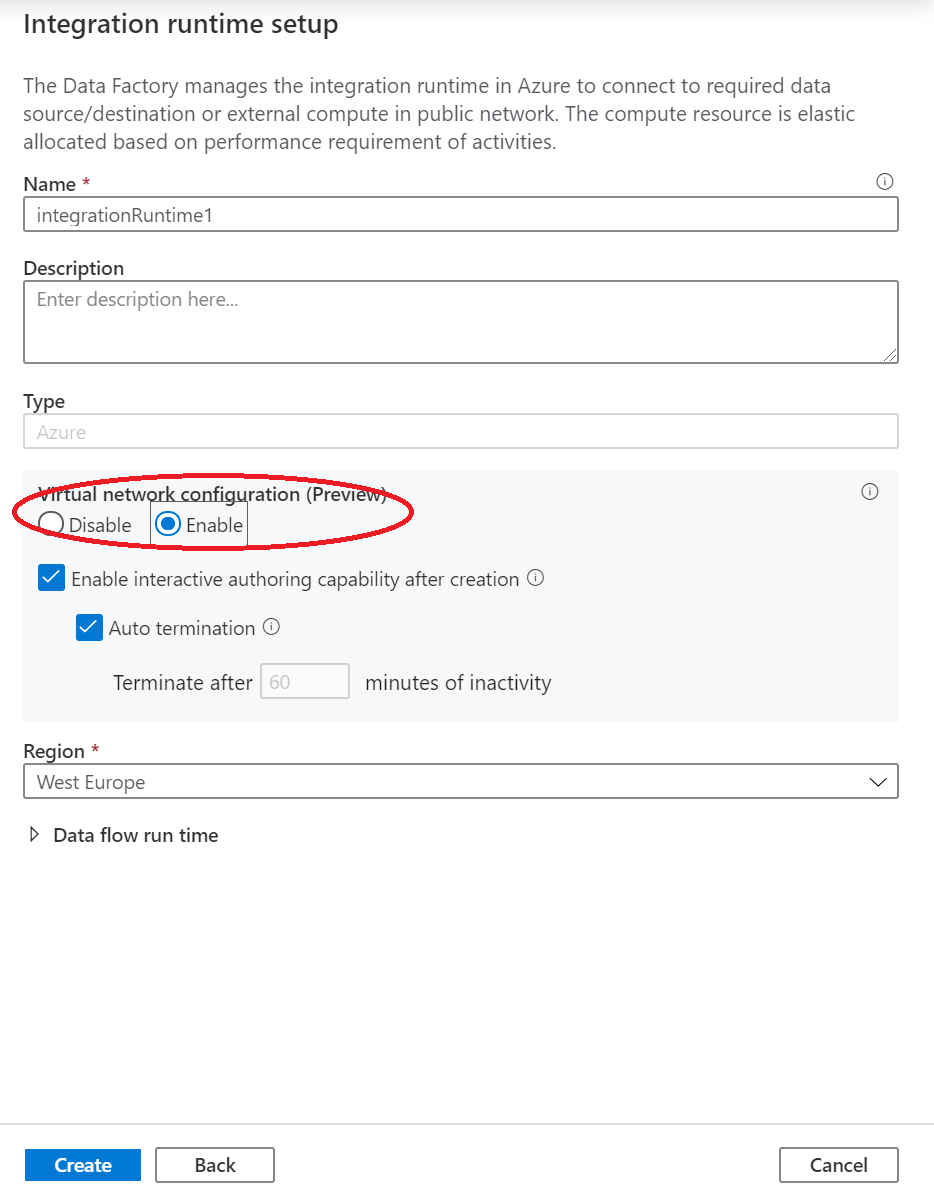
Välj Skapa.
Skapa en pipeline
I det här steget skapar du en pipeline med en kopieringsaktivitet i datafabriken. Kopieringsaktiviteten kopierar data från Blob Storage till en SQL-databas. I snabbstartssjälvstudien skapade du en pipeline med följande steg:
- Skapa den länkade tjänsten.
- Skapa datauppsättningar för indata och utdata.
- Skapa en pipeline.
I den här självstudien börjar du med att skapa en pipeline. Sedan skapar du länkade tjänster och datauppsättningar när du behöver dem för att konfigurera pipelinen.
På startsidan väljer du Orkestrera.
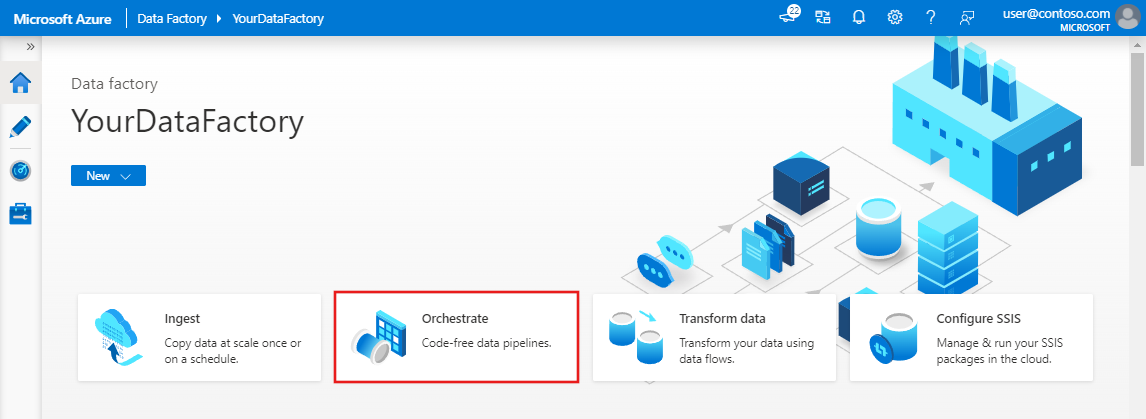
I egenskapsfönstret för pipelinen anger du CopyPipeline som pipelinenamn.
I rutan Aktiviteter expanderar du kategorin Flytta och transformera och drar aktiviteten Kopiera data från verktygslådan till pipelinedesignytan. Ange CopyFromBlobToSql som namn.
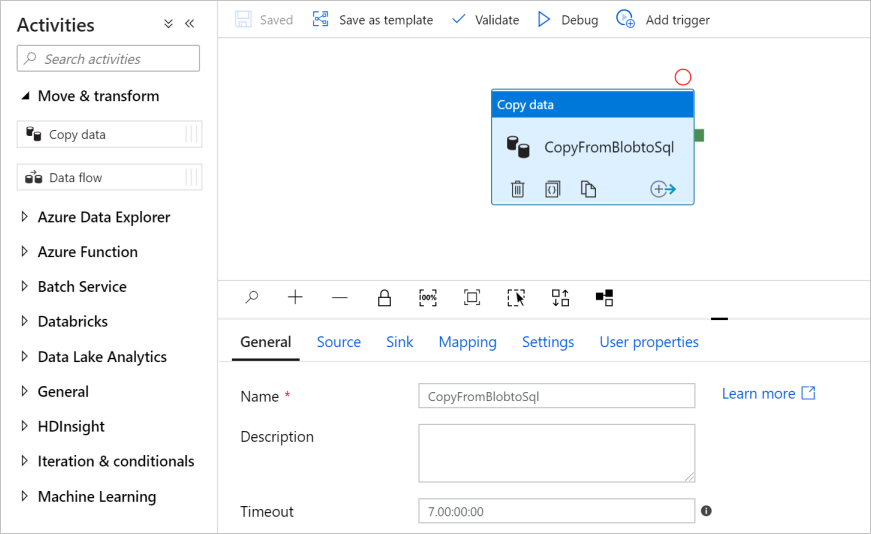
Konfigurera en källa
Dricks
I den här självstudien använder du kontonyckeln som autentiseringstyp för källdatalagret. Du kan också välja andra autentiseringsmetoder som stöds, till exempel SAS URI, tjänstens huvudnamn och hanterad identitet om det behövs. Mer information finns i motsvarande avsnitt i Kopiera och transformera data i Azure Blob Storage med hjälp av Azure Data Factory.
Om du vill lagra hemligheter för datalager på ett säkert sätt rekommenderar vi också att du använder Azure Key Vault. Mer information och illustrationer finns i Lagra autentiseringsuppgifter i Azure Key Vault.
Skapa en källdatauppsättning och länkad tjänst
Gå till fliken Källa . Välj + Ny för att skapa en källdatauppsättning.
I dialogrutan Ny datauppsättning väljer du Azure Blob Storage och sedan Fortsätt. Dina källdata finns i Blob Storage, så du väljer Azure Blob Storage för källdatauppsättningen.
I dialogrutan Välj format väljer du formattypen för dina data och väljer sedan Fortsätt.
I dialogrutan Ange egenskaper anger du SourceBlobDataset som Namn. Markera kryssrutan för Första raden som rubrik. Under textrutan Länkad tjänst väljer du + Ny.
I dialogrutan Ny länkad tjänst (Azure Blob Storage) anger du AzureStorageLinkedService som Namn och väljer ditt lagringskonto i listan Lagringskontonamn.
Se till att du aktiverar interaktiv redigering. Det kan ta ungefär en minut att aktiveras.
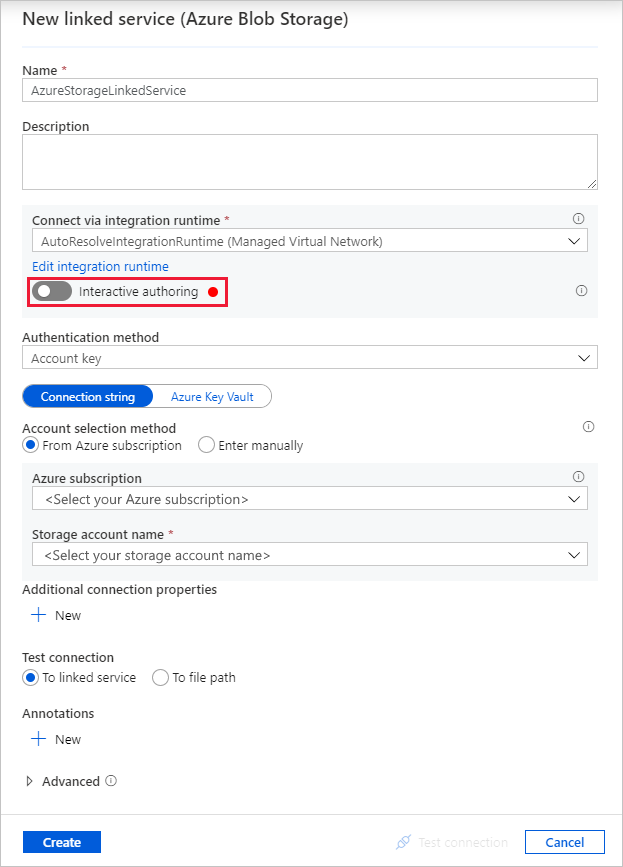
Välj Testanslutning. Det bör misslyckas när lagringskontot endast tillåter åtkomst från valda nätverk och kräver att Data Factory skapar en privat slutpunkt till det som ska godkännas innan det används. I felmeddelandet bör du se en länk för att skapa en privat slutpunkt som du kan följa för att skapa en hanterad privat slutpunkt. Ett alternativ är att gå direkt till fliken Hantera och följa anvisningarna i nästa avsnitt för att skapa en hanterad privat slutpunkt.
Kommentar
Fliken Hantera kanske inte är tillgänglig för alla datafabriksinstanser. Om du inte ser den kan du komma åt privata slutpunkter genom att välja Skapa>anslutningar>privat slutpunkt.
Håll dialogrutan öppen och gå sedan till ditt lagringskonto.
Följ anvisningarna i det här avsnittet för att godkänna den privata länken.
Gå tillbaka till dialogrutan. Välj Testa anslutning igen och välj Skapa för att distribuera den länkade tjänsten.
När den länkade tjänsten har skapats går den tillbaka till sidan Ange egenskaper . Vid Filsökväg väljer du Bläddra.
Gå till mappen adftutorial/input , välj filen emp.txt och välj sedan OK.
Välj OK. Den går automatiskt till pipelinesidan. På fliken Källa bekräftar du att SourceBlobDataset har valts. Om du vill förhandsgranska data på den här sidan väljer du Förhandsgranska data.
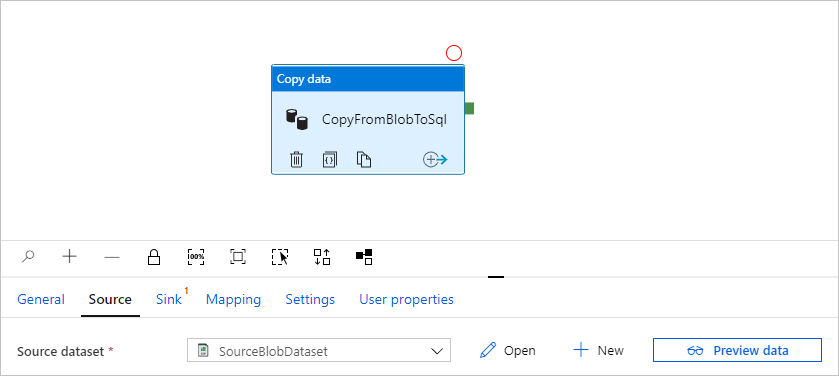
Skapa en hanterad privat slutpunkt
Om du inte valde hyperlänken när du testade anslutningen följer du sökvägen. Nu måste du skapa en hanterad privat slutpunkt som du ska ansluta till den länkade tjänst som du skapade.
Gå till fliken Hantera .
Kommentar
Fliken Hantera kanske inte är tillgänglig för alla Data Factory-instanser. Om du inte ser den kan du komma åt privata slutpunkter genom att välja Skapa>anslutningar>privat slutpunkt.
Gå till avsnittet Hanterade privata slutpunkter .
Välj + Ny under Hanterade privata slutpunkter.
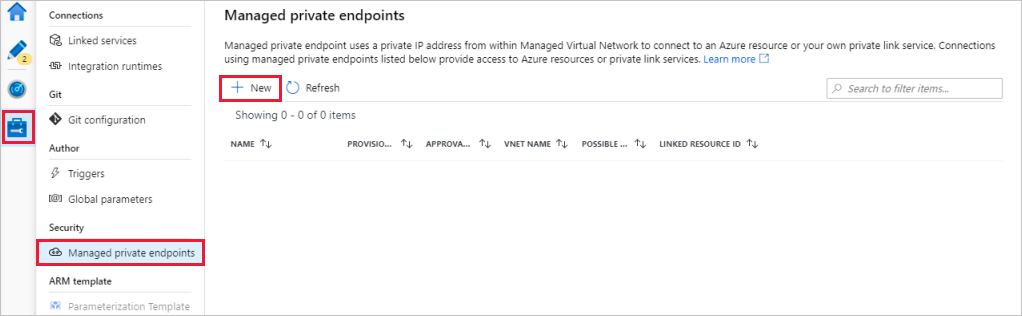
Välj panelen Azure Blob Storage i listan och välj Fortsätt.
Ange namnet på lagringskontot som du skapade.
Välj Skapa.
Efter några sekunder bör du se att den privata länken som skapats behöver ett godkännande.
Välj den privata slutpunkt som du skapade. Du kan se en hyperlänk som gör att du godkänner den privata slutpunkten på lagringskontonivå.
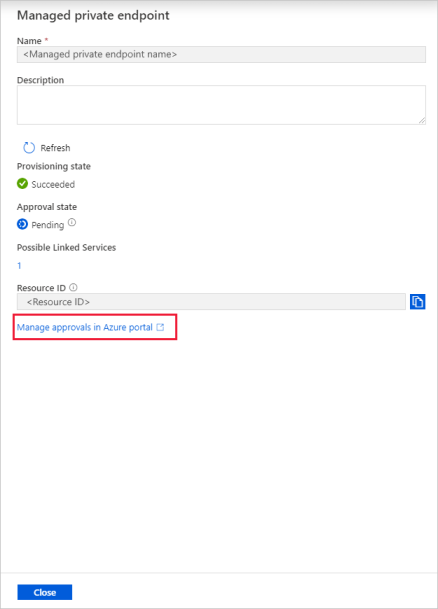
Godkännande av en privat länk i ett lagringskonto
I lagringskontot går du till Privata slutpunktsanslutningar under avsnittet Inställningar .
Markera kryssrutan för den privata slutpunkt som du skapade och välj Godkänn.
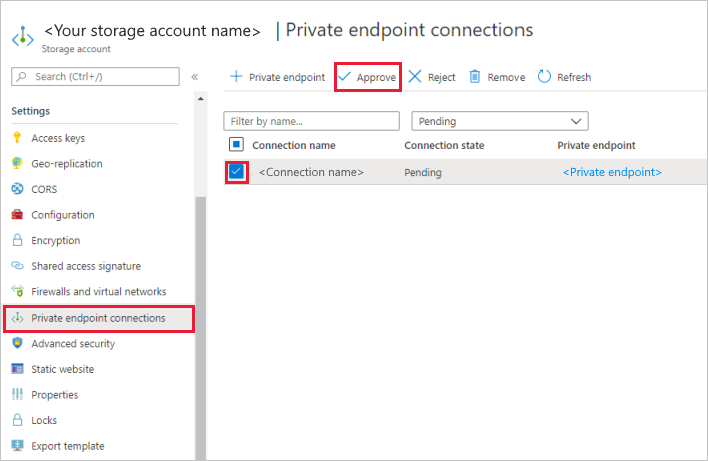
Lägg till en beskrivning och välj Ja.
Gå tillbaka till Avsnittet Hanterade privata slutpunkter på fliken Hantera i Data Factory.
Efter ungefär en eller två minuter bör godkännandet av din privata slutpunkt visas i användargränssnittet för Data Factory.
Konfigurera en mottagare
Dricks
I den här självstudien använder du SQL-autentisering som autentiseringstyp för ditt datalager för mottagare. Du kan också välja andra autentiseringsmetoder som stöds, till exempel Tjänstens huvudnamn och Hanterad identitet om det behövs. Mer information finns i motsvarande avsnitt i Kopiera och transformera data i Azure SQL Database med hjälp av Azure Data Factory.
Om du vill lagra hemligheter för datalager på ett säkert sätt rekommenderar vi också att du använder Azure Key Vault. Mer information och illustrationer finns i Lagra autentiseringsuppgifter i Azure Key Vault.
Skapa en datauppsättning för mottagare och länkad tjänst
Gå till fliken Mottagare och välj + Nytt för att skapa en datauppsättning för mottagare.
I dialogrutan Ny datauppsättning anger du SQL i sökrutan för att filtrera kopplingarna. Välj Azure SQL Database och välj sedan Fortsätt. I dessa självstudier kopierar du data till en SQL-databas.
I dialogrutan Ange egenskaper anger du OutputSqlDataset som Namn. I listrutan Länkad tjänst väljer du + Ny. En datauppsättning måste associeras med en länkad tjänst. Den länkade tjänsten har anslutningssträngen som Data Factory använder för att ansluta till SQL-databasen vid körning. Datauppsättningen anger den container, mapp och fil (valfritt) som data kopieras till.
I dialogrutan Ny länkad tjänst (Azure SQL Database) gör du följande:
- Under Namn anger du AzureSqlDatabaseLinkedService.
- Under Servernamn väljer du din SQL Server-instans.
- Se till att du aktiverar interaktiv redigering.
- Under Databasnamn väljer du din SQL-databas.
- Under Användarnamn anger du namnet på användaren.
- För Lösenord anger du användarens lösenord.
- Välj Testanslutning. Det bör misslyckas eftersom SQL-servern endast tillåter åtkomst från valda nätverk och kräver att Data Factory skapar en privat slutpunkt till den, som ska godkännas innan den används. I felmeddelandet bör du se en länk för att skapa en privat slutpunkt som du kan följa för att skapa en hanterad privat slutpunkt. Ett alternativ är att gå direkt till fliken Hantera och följa anvisningarna i nästa avsnitt för att skapa en hanterad privat slutpunkt.
- Håll dialogrutan öppen och gå sedan till den valda SQL-servern.
- Följ anvisningarna i det här avsnittet för att godkänna den privata länken.
- Gå tillbaka till dialogrutan. Välj Testa anslutning igen och välj Skapa för att distribuera den länkade tjänsten.
Den går automatiskt till dialogrutan Ange egenskaper . Under Tabell väljer du [dbo].[emp]. Välj sedan OK.
Gå till fliken med pipelinen och bekräfta att OutputSqlDataset har valts i Datauppsättning för mottagare.
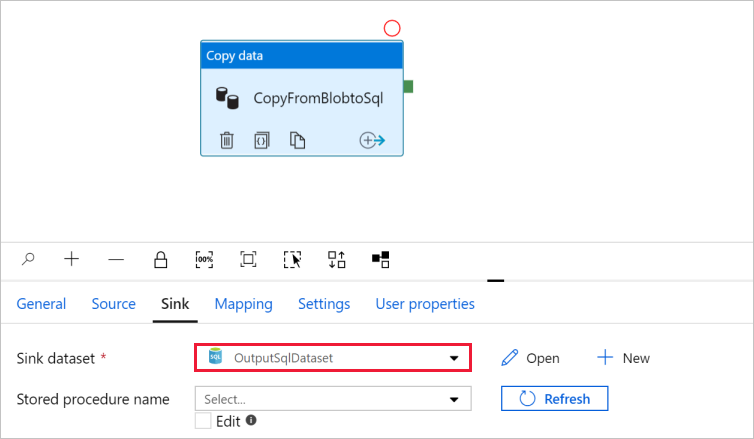
Du kan också mappa schemat för källan till motsvarande schema för målet genom att följa schemamappningen i kopieringsaktiviteten.
Skapa en hanterad privat slutpunkt
Om du inte valde hyperlänken när du testade anslutningen följer du sökvägen. Nu måste du skapa en hanterad privat slutpunkt som du ska ansluta till den länkade tjänst som du skapade.
Gå till fliken Hantera .
Gå till avsnittet Hanterade privata slutpunkter .
Välj + Ny under Hanterade privata slutpunkter.
Välj Azure SQL Database-panelen i listan och välj Fortsätt.
Ange namnet på den SQL-server som du har valt.
Välj Skapa.
Efter några sekunder bör du se att den privata länken som skapats behöver ett godkännande.
Välj den privata slutpunkt som du skapade. Du kan se en hyperlänk som gör att du godkänner den privata slutpunkten på SQL-servernivå.
Godkännande av en privat länk i SQL Server
- I SQL-servern går du till Privata slutpunktsanslutningar under avsnittet Inställningar .
- Markera kryssrutan för den privata slutpunkt som du skapade och välj Godkänn.
- Lägg till en beskrivning och välj Ja.
- Gå tillbaka till Avsnittet Hanterade privata slutpunkter på fliken Hantera i Data Factory.
- Det bör ta en eller två minuter innan godkännandet visas för din privata slutpunkt.
Felsöka och publicera en pipeline
Du kan felsöka en pipeline innan du publicerar artefakter (länkade tjänster, datauppsättningar och pipelines) till datafabriken eller din egen Azure Repos Git-lagringsplats.
- Välj Felsöka i verktygsfält för att felsöka pipelinen. Du ser status för pipelinekörningen på fliken Utdata längst ned i fönstret.
- När pipelinen har körts väljer du Publicera alla i det översta verktygsfältet. Den här åtgärden publicerar entiteter (datauppsättningar och pipelines) som du har skapat till Data Factory.
- Vänta tills du ser meddelandet om att entiteterna har publicerats. Om du vill se meddelanden väljer du Visa meddelanden i det övre högra hörnet (klockknappen).
Sammanfattning
Pipelinen i det här exemplet kopierar data från Blob Storage till SQL Database med hjälp av privata slutpunkter i Data Factory Managed Virtual Network. Du har lärt dig att:
- Skapa en datafabrik.
- Skapa en pipeline med en kopieringsaktivitet.