Kopiera data från Azure Blob Storage till en SQL Database med verktyget Kopiera data
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien skapar du en datafabrik i Azure Portal. Sedan använder du verktyget Kopiera data för att skapa en pipeline som kopierar data från Azure Blob Storage till en SQL Database.
Kommentar
Om du inte har använt Azure Data Factory tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien får du göra följande:
- Skapa en datafabrik.
- Använd verktyget Kopiera data för att skapa en pipeline.
- Övervaka pipelinen och aktivitetskörningarna.
Förutsättningar
- Azure-prenumeration: Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- Azure Storage-konto: Använd Blob Storage som källdatalager . Om du inte har något Azure Storage-konto kan du läsa anvisningarna i Skapa ett lagringskonto.
- Azure SQL Database: Använd en SQL Database som datalager för mottagare . Om du inte har någon SQL Database kan du läsa anvisningarna i Skapa en SQL Database.
Förbereda SQL-databasen
Tillåt att Azure-tjänster får åtkomst till den logiska SQL-servern i din Azure SQL Database.
Kontrollera att inställningen Tillåt Att Azure-tjänster och resurser får åtkomst till den här servern är aktiverad för servern som kör SQL Database. Med den här inställningen kan Data Factory skriva data till din databasinstans. Om du vill verifiera och aktivera den här inställningen går du till logiska SQL Server > Security > Firewalls och virtuella nätverk > anger alternativet Tillåt Azure-tjänster och resurser att komma åt den här serveralternativet till PÅ.
Kommentar
Alternativet Att tillåta Att Azure-tjänster och resurser får åtkomst till den här servern ger nätverksåtkomst till din SQL Server från valfri Azure-resurs, inte bara de som finns i din prenumeration. Det kanske inte är lämpligt för alla miljöer, men är lämpligt för den här begränsade självstudien. Mer information finns i Brandväggsregler för Azure SQL Server. I stället kan du använda privata slutpunkter för att ansluta till Azure PaaS-tjänster utan att använda offentliga IP-adresser.
Skapa en blob och en SQL-tabell
Förbered bloblagringen och SQL Database för självstudien genom att utföra de här stegen.
Skapa en källblob
Starta Anteckningar. Kopiera följande text och spara den i en fil med namnet inputEmp.txt på din disk:
FirstName|LastName John|Doe Jane|DoeSkapa en container med namnet adfv2tutorial och ladda upp filen inputEmp.txt till containern. Du kan använda Azure Portal eller olika verktyg som Azure Storage Explorer för att utföra dessa uppgifter.
Skapa en SQL-mottagartabell
Använd följande SQL-skript för att skapa en tabell med namnet
dbo.empi din SQL Database:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Skapa en datafabrik
Välj Skapa en resursintegreringsdatafabrik>> på den vänstra menyn:
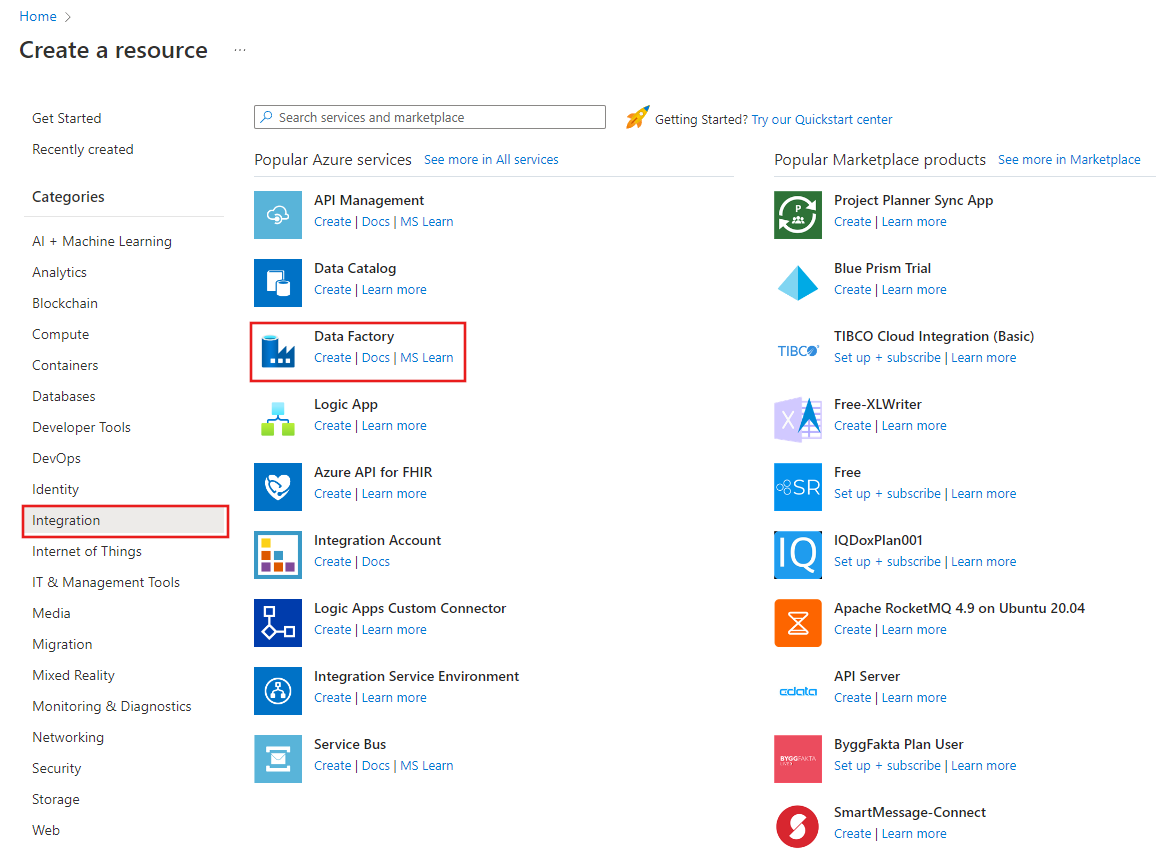
I fönstret Ny datafabrik, under Namn anger du ADFTutorialDataFactory.
Namnet på datafabriken måste vara globalt unikt. Du kan få följande felmeddelande:
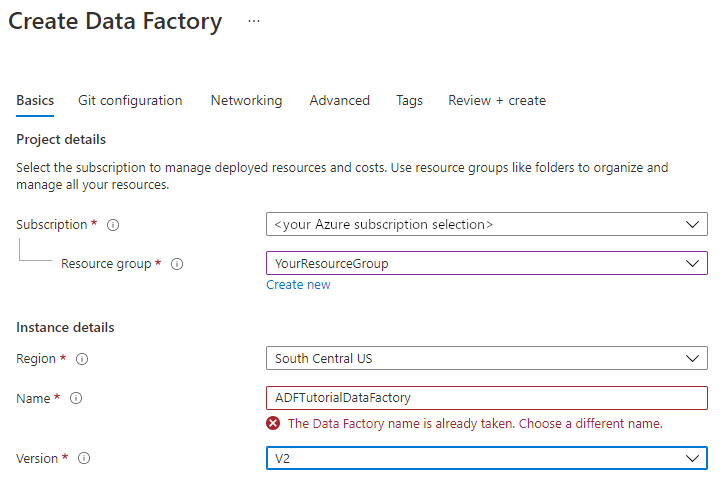
Ange ett annat namn för datafabriken om du får ett felmeddelande om namnvärdet. Använd till exempel namnet dittnamnADFTutorialDataFactory. Se artikeln Data Factory – namnregler för namnregler för Data Factory-artefakter.
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
a. Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
b. Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
För version väljer du V2.
Under plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalagren (t.ex. Azure Storage och SQL Database) och beräkningarna (t.ex. Azure HDInsight) som används i datafabriken kan finnas på andra platser och i andra regioner.
Välj Skapa.
När den har skapats visas startsidan för Data Factory.
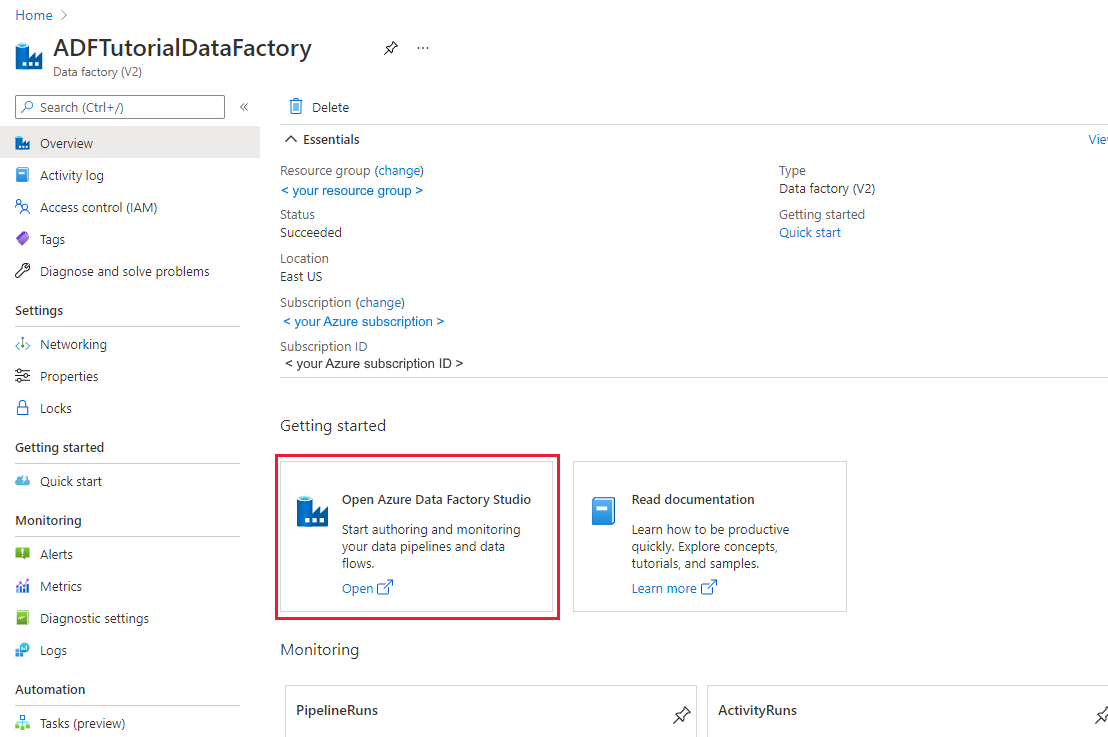
Om du vill starta Användargränssnittet för Azure Data Factory på en separat flik väljer du Öppna på panelen Öppna Azure Data Factory Studio.
Använd verktyget Kopiera data för att skapa en pipeline
På startsidan för Azure Data Factory väljer du panelen Mata in för att starta verktyget Kopiera data.
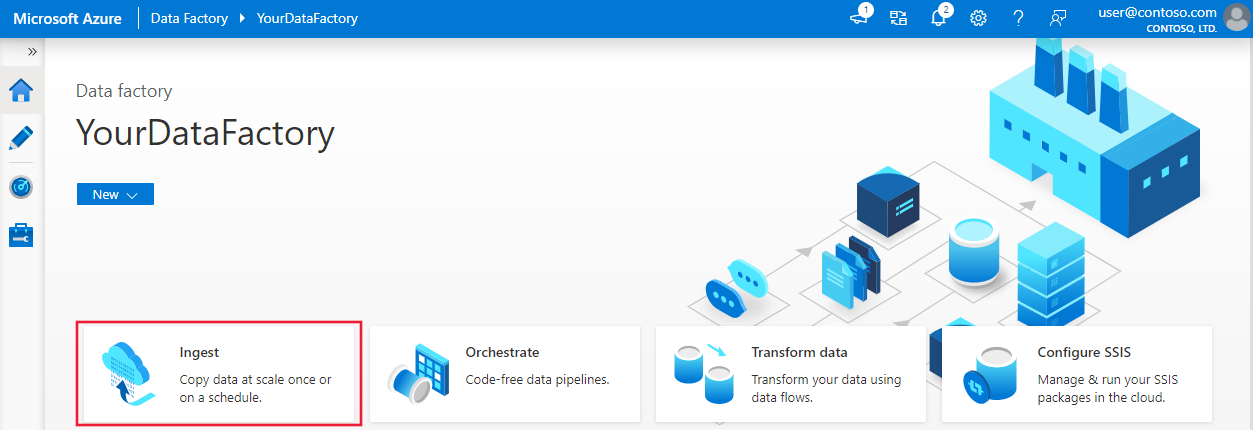
På sidan Egenskaper i verktyget Kopiera data väljer du Inbyggd kopieringsaktivitet under Aktivitetstyp och väljer sedan Nästa.

Gör följande på sidan Källdatalager:
a. Välj + Skapa ny anslutning för att lägga till en anslutning.
b. Välj Azure Blob Storage i galleriet och välj sedan Fortsätt.
c. På sidan Ny anslutning (Azure Blob Storage) väljer du din Azure-prenumeration i azure-prenumerationslistan och väljer ditt lagringskonto i listan Med lagringskontonamn. Testa anslutningen och välj sedan Skapa.
d. Välj den nyligen skapade länkade tjänsten som källa i anslutningsblocket.
e. I avsnittet Fil eller mapp väljer du Bläddra för att navigera till mappen adfv2tutorial , väljer filen inputEmp.txt och väljer sedan OK.
f. Välj Nästa för att gå vidare till nästa steg.

På sidan Inställningar för filformat aktiverar du kryssrutan för Första raden som rubrik. Observera att verktyget automatiskt identifierar kolumn- och radavgränsare, och du kan förhandsgranska data och visa schemat för indata genom att välja knappen Förhandsgranska data på den här sidan. Välj sedan Nästa.

Gör följande på sidan Måldatalager:
a. Välj + Skapa ny anslutning för att lägga till en anslutning.
b. Välj Azure SQL Database i galleriet och välj sedan Fortsätt.
c. På sidan Ny anslutning (Azure SQL Database) väljer du din Azure-prenumeration, ditt servernamn och databasnamn i listrutan. Välj sedan SQL-autentisering under Autentiseringstyp och ange användarnamn och lösenord. Testa anslutningen och välj Skapa.

d. Välj den nyligen skapade länkade tjänsten som mottagare och välj sedan Nästa.
På sidan Måldatalager väljer du Använd befintlig tabell och väljer tabellen
dbo.emp. Välj sedan Nästa.På sidan Kolumnmappning ser du att den andra och den tredje kolumnerna i indatafilen mappas till kolumnerna FirstName och LastName i emp-tabellen. Justera mappningen för att se till att det inte finns något fel och välj sedan Nästa.

På sidan Inställningar , under Aktivitetsnamn, anger du CopyFromBlobToSqlPipeline och väljer sedan Nästa.

Granska inställningarna på sidan Sammanfattning och klicka på Nästa.
Välj Övervaka på sidan Distribution för att övervaka pipelinen (aktiviteten).

På sidan Pipelinekörningar väljer du Uppdatera för att uppdatera listan. Välj länken under Pipelinenamn om du vill visa aktivitetskörningsinformation eller köra pipelinen igen.
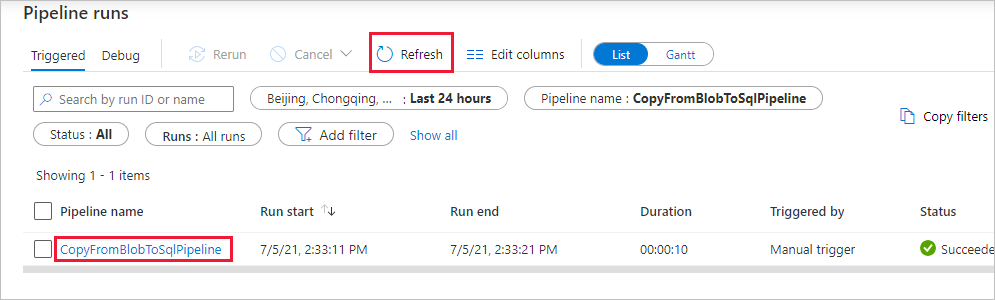
På sidan Aktivitetskörningar väljer du länken Information (glasögonikon) under kolumnen Aktivitetsnamn för mer information om kopieringsåtgärden. Om du vill gå tillbaka till vyn "Pipelinekörningar" väljer du länken Alla pipelinekörningar på menyn breadcrumb. Välj Uppdatera för att uppdatera vyn.

Kontrollera att data infogas i tabellen dbo.emp i SQL Database.
Klicka på fliken Författare till vänster för att växla till redigeringsläget. Du kan uppdatera de länkade tjänster, datauppsättningar och pipeliner som skapats med verktyget med hjälp av redigeraren. Mer information om hur du redigerar dessa entiteter i användargränssnittet för Data Factory finns i Azure Portal-versionen av den här självstudiekursen.

Relaterat innehåll
Pipelinen i det här exemplet kopierar data från Blob Storage till en SQL Database. Du har lärt dig att:
- Skapa en datafabrik.
- Använd verktyget Kopiera data för att skapa en pipeline.
- Övervaka pipelinen och aktivitetskörningarna.
Fortsätt till nästa självstudie om du vill lära dig att kopiera data från en lokal plats till molnet: