Läs in data stegvis från flera tabeller i SQL Server till en databas i Azure SQL Database med hjälp av Azure Portal
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien skapar du en Azure Data Factory med en pipeline som läser in deltadata från flera tabeller i en SQL Server-databas till en databas i Azure SQL Database.
I de här självstudierna går du igenom följande steg:
- Förbereda käll- och måldatalager.
- Skapa en datafabrik.
- Skapa en lokalt installerad integrationskörning.
- Installera Integration Runtime.
- Skapa länkade tjänster.
- Skapa datauppsättningar för källa, mottagare och vattenstämpel.
- Skapa, köra och övervaka en pipeline.
- Granska resultaten.
- Lägga till eller uppdatera data i källtabeller.
- Köra och övervaka pipelinen igen.
- Granska de slutliga resultaten.
Översikt
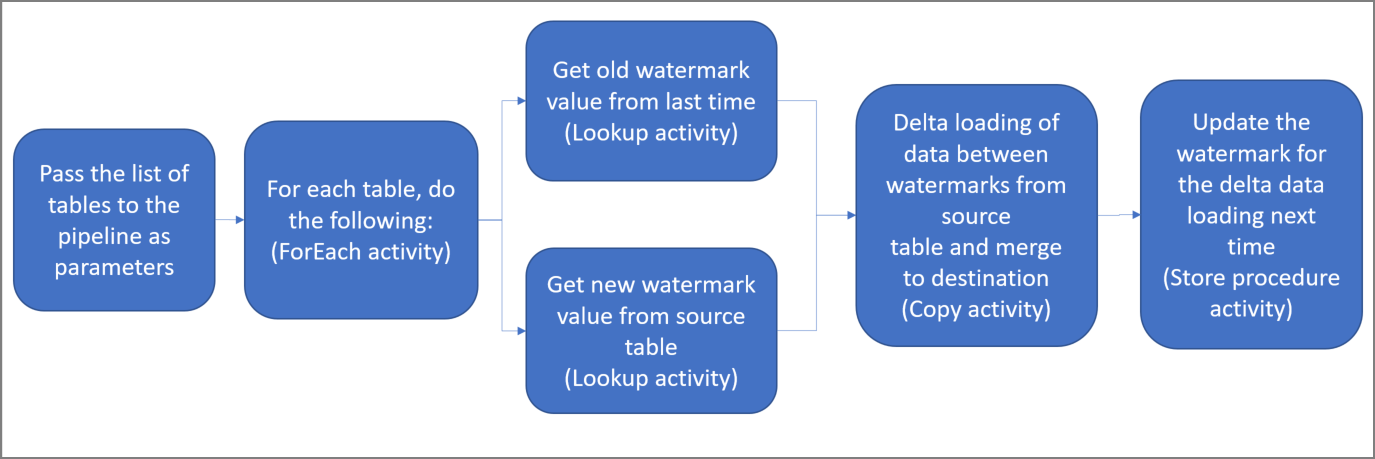
Här är några viktiga steg för att skapa den här lösningen:
Markera vattenstämpelkolumnen.
Markera en kolumn för varje tabell i källdatalagret som går att använda för att identifiera de nya eller uppdaterade posterna för varje körning. Vanligtvis ökar data i den markerade kolumnen (till exempel last_modify_time elle ID) när rader skapas eller uppdateras. Det maximala värdet i den här kolumnen används som vattenstämpel.
Förbered datalagringen för att lagra värdet för vattenstämpeln.
I den här självstudien lagrar du storleksgränsen i en SQL-databas.
Skapa en pipeline med följande aktiviteter:
a. Skapa en ForEach-aktivitet som upprepas över en lista med namn på källtabeller och som skickas som en parameter till pipelinen. För varje källtabell anropas följande aktiviteter som utför deltainläsningen för tabellen.
b. Skapa två sökningsaktiviteter. Använd den första sökningsaktiviteten för att hämta det sista vattenstämpelvärdet. Använd den andra sökningsaktiviteten för att hämta det nya vattenstämpelvärdet. Vattenstämpelvärdena skickas till kopieringsaktiviteten.
c. Skapa en {0}kopieringsaktivitet{0} som kopierar raderna från källdatalagringen med värdet för vattenstämpelkolumnen som är större än det gamla värdet och mindre än det nya. Sedan kopieras deltadata från källdatalagringen till Azure Blob-lagring som en ny fil.
d. Skapa en StoredProcedure-aktivitet som uppdaterar vattenstämpelvärdet för den pipeline som körs nästa gång.
Här är det avancerade diagrammet:
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- SQL Server. Du använder en SQL Server-databas som källdatalager i den här självstudien.
- Azure SQL Database. Du använder en databas i Azure SQL Database som datalager för mottagare. Om du inte har någon databas i SQL Database kan du läsa Skapa en databas i Azure SQL Database för steg för att skapa en.
Skapa källtabeller i din SQL Server-databas
Öppna SQL Server Management Studio och anslut till din SQL Serverdatabas.
I Server Explorer högerklickar du på databasen och väljer Ny fråga.
Kör följande SQL-kommando mot databasen för att skapa tabeller med namnen
customer_tableochproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Skapa måltabeller i databasen
Öppna SQL Server Management Studio och anslut till databasen i Azure SQL Database.
I Server Explorer högerklickar du på databasen och väljer Ny fråga.
Kör följande SQL-kommando mot databasen för att skapa tabeller med namnen
customer_tableochproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Skapa en annan tabell i databasen för att lagra värdet för högvattenstämpel
Kör följande SQL-kommando mot databasen för att skapa en tabell med namnet
watermarktableför att lagra vattenstämpelvärdet:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Infoga inledande värden för högvattenmärket för båda källtabellerna i vattenmärkestabellen.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Skapa en lagrad procedur i databasen
Kör följande kommando för att skapa en lagrad procedur i databasen. Den här lagrade proceduren uppdaterar vattenmärkets värde efter varje pipelinekörning.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Skapa datatyper och ytterligare lagrade procedurer i databasen
Kör följande fråga för att skapa två lagrade procedurer och två datatyper i databasen. De används för att slå samman data från källtabellerna till måltabellerna.
För att göra resan enkel att börja med använder vi direkt dessa lagrade procedurer som skickar deltadata via en tabellvariabel och sammanfogar dem sedan till målarkivet. Var försiktig så att det inte förväntar sig att ett "stort" antal deltarader (mer än 100) ska lagras i tabellvariabeln.
Om du behöver sammanfoga ett stort antal deltarader i målarkivet föreslår vi att du använder kopieringsaktivitet för att kopiera alla deltadata till en tillfällig "mellanlagringstabell" i mållagret först och sedan skapar en egen lagrad procedur utan att använda tabellvariabeln för att sammanfoga dem från tabellen "mellanlagring" till tabellen "final".
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Skapa en datafabrik
Starta webbläsaren Microsoft Edge eller Google Chrome. Just nu är det bara webbläsarna Microsoft Edge och Google Chrome som har stöd för Data Factory UI.
Välj Skapa en resursintegreringsdatafabrik>> på den vänstra menyn:
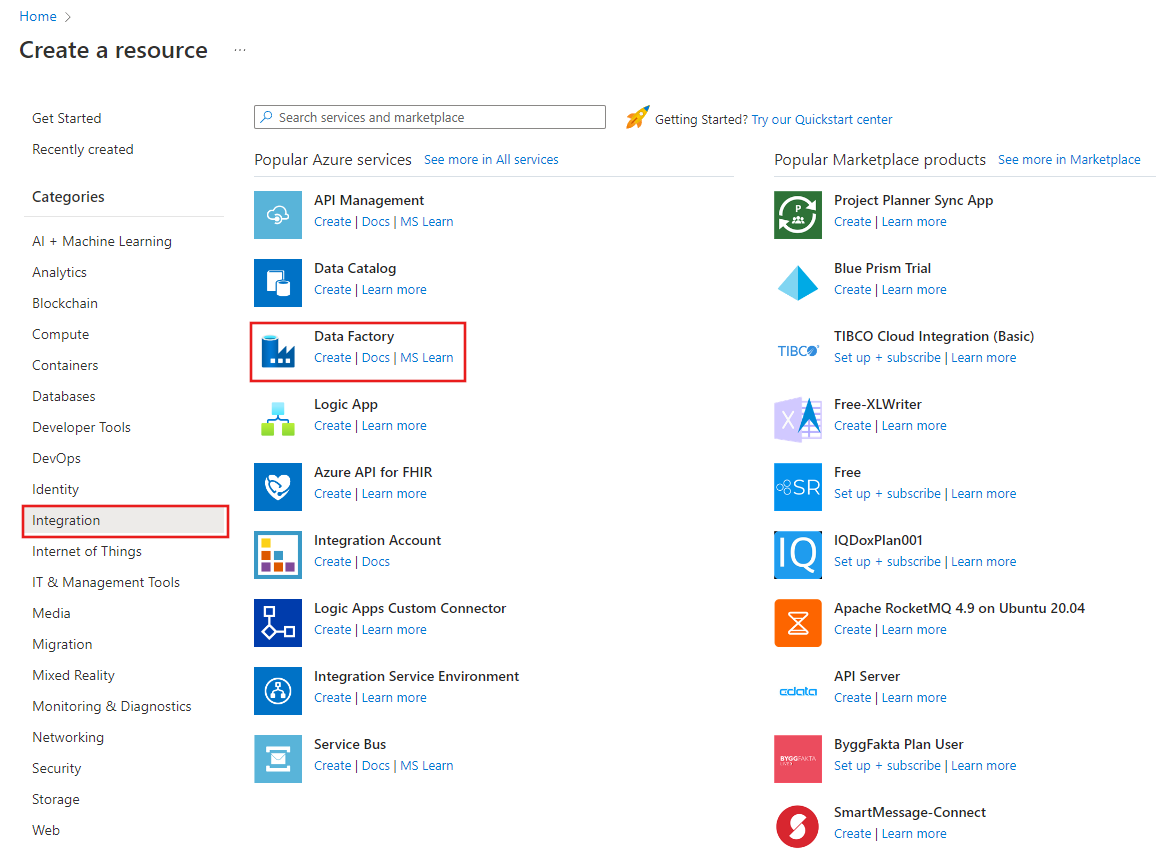
På sidan Ny datafabrik anger du ADFMultiIncCopyTutorialDF som namn.
Namnet på Azure Data Factory måste vara globalt unikt. Om du ser ett rött utropstecken med följande fel ändrar du namnet på datafabriken (till exempel dittnamnADFIncCopyTutorialDF) och provar att skapa fabriken igen. Se artikeln Data Factory – namnregler för namnregler för Data Factory-artefakter.
Data factory name "ADFIncCopyTutorialDF" is not availableVälj den Azure-prenumeration som du vill skapa den nya datafabriken i.
För resursgruppen utför du något av följande steg:
- Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
- Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper till att hantera Azure-resurser.
Välj V2 för versionen.
Välj plats för datafabriken. Endast platser som stöds visas i listrutan. Datalagren (Azure Storage, Azure SQL Database osv.) och beräkningarna (HDInsight osv.) som används i Data Factory kan finnas i andra regioner.
Klicka på Skapa.
När datafabriken har skapats visas sidan Datafabrik som på bilden.
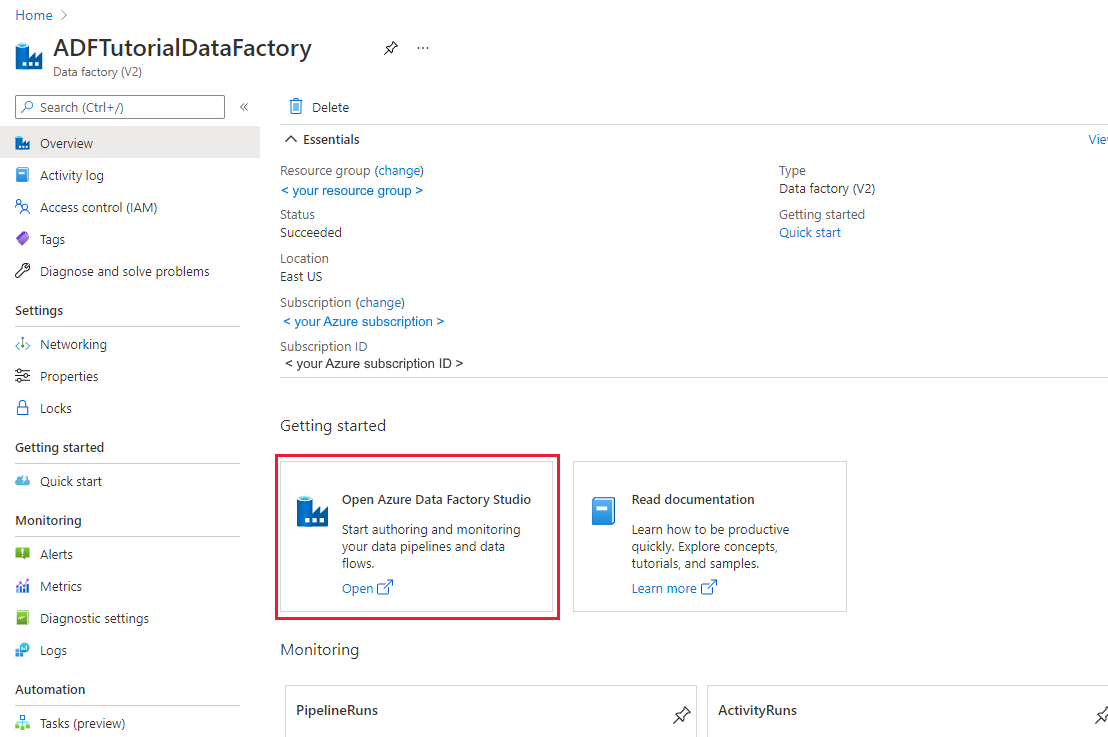
Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta Användargränssnittet för Azure Data Factory på en separat flik.
Skapa Integration Runtime med lokal installation
När du flyttar data från ett datalager i ett privat nätverk (lokalt) till ett Azure-datalager ska du installera en lokal Integration Runtime (IR) i din lokala miljö. Lokalt installerad IR flyttar data mellan ditt privata nätverk och Azure.
På startsidan för Azure Data Factory-användargränssnittet väljer du fliken Hantera i det vänstra fönstret.
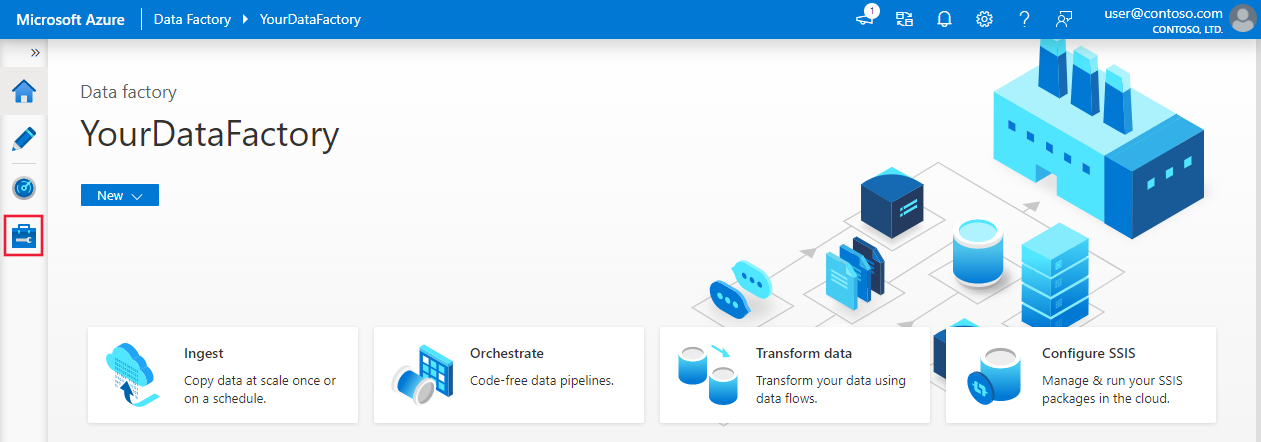
Välj Integreringskörningar i det vänstra fönstret och välj sedan +Nytt.
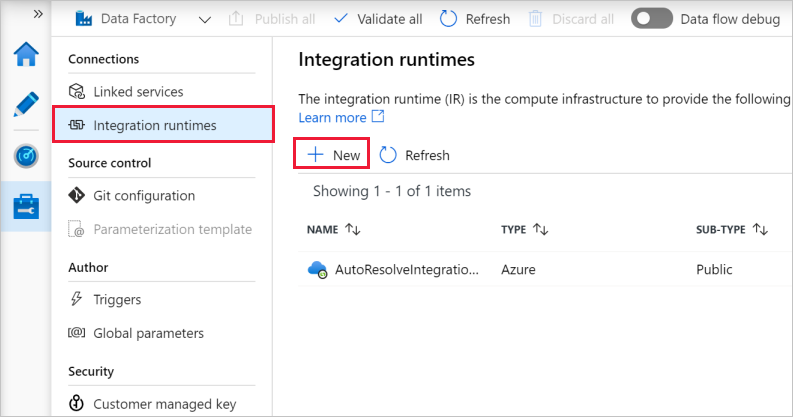
I fönstret Installation av Integration Runtime väljer du Utför dataflytt och sändningsaktiviteter till externa beräkningar och klickar på Fortsätt.
Välj Lokalt värdhanterad och klicka på Fortsätt.
Ange MySelfHostedIR som Namn och klicka på Skapa.
Klicka på Click here to launch the express setup for this computer (Klicka här för att starta expressinstallation för den här datorn) i avsnittet Option 1: Express setup (Alternativ 1: Expressinstallation).

Klicka på Stäng i fönstret Snabbinstallation av Integration Runtime (lokal installation).

Klicka på Slutför i webbläsaren för att stänga installationsfönstret för Integration Runtime.
Bekräfta att du ser MySelfHostedIR i listan över Integration Runtimes.
Skapa länkade tjänster
Du kan skapa länkade tjänster i en datafabrik för att länka ditt datalager och beräkna datafabrik-tjänster. I det här avsnittet skapar du länkade tjänster till din SQL Server-databas och din databas i Azure SQL Database.
Skapa länkad tjänst till SQL Server
I det här steget länkar du SQL Server-databasen till datafabriken.
I fönstret Anslutningar växlar du från fliken Integration Runtimes till fliken med länkade tjänster och klickar på + Ny.
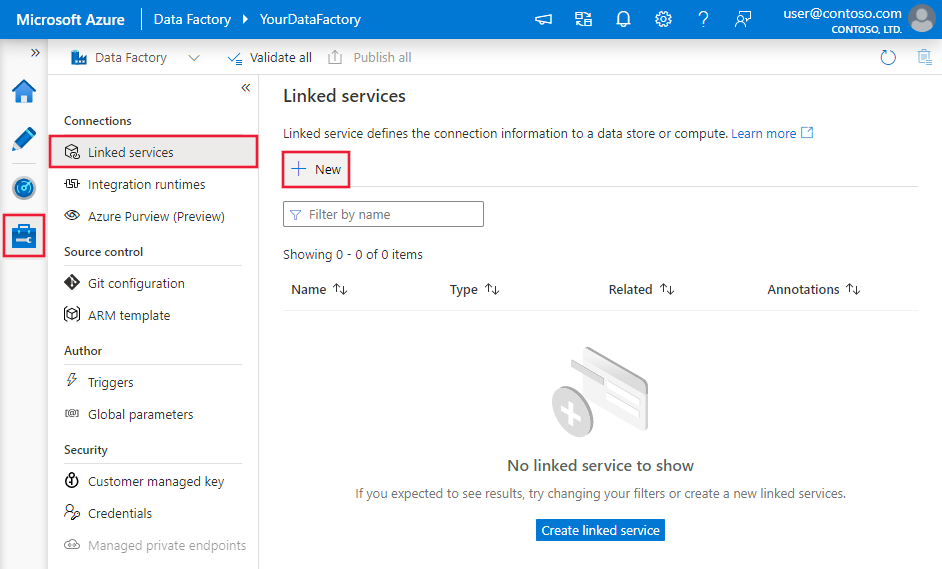
I fönstret New Linked Service (Ny länkad tjänst) väljer du SQL Server och klickar på Fortsätt.
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
- Ange SqlServerLinkedService som namn.
- Välj MySelfHostedIR för Connect via integration runtime (Anslut via Integration Runtime). Det här är ett viktigt steg. Integration Runtime i standardversionen kan inte ansluta till ett lokalt datalager. Använda den lokalt installerade Integration Runtime som du skapade tidigare.
- För Servernamn anger du namnet på den dator som har SQL Server-databasen.
- För Databasnamn anger du namnet på databasen i SQL Server som innehåller källdata. Du skapade en tabell och infogade data i den här databasen som en del av förberedelserna.
- För Autentiseringstyp väljer du vilken typ av autentisering du vill använda för att ansluta till databasen.
- För Användarnamn anger du namnet på en användare som har åtkomst till SQL Server-databasen. Om du behöver använda ett snedstreck (
\) i ditt användarkonto eller användarnamn använder du escape-tecknet (\). Ett exempel ärmydomain\\myuser. - För Lösenord anger du lösenordet för användaren.
- Om du vill testa om Data Factory kan ansluta till SQL Server-databasen, klickar du på Testa anslutning. Åtgärda eventuella fel tills anslutningen lyckas.
- Spara den länkade tjänsten genom att klicka på Slutför.
Skapa länkad tjänst för Azure SQL Database
I det sista steget skapar du en länkad tjänst för att länka SQL Server-databasen till datafabriken. I det här steget länkar du mål-/mottagardatabasen till datafabriken.
I fönstret Anslutningar växlar du från fliken Integration Runtimes till fliken med länkade tjänster och klickar på + Ny.
I fönstret New Linked Service (Ny länkad tjänst) väljer du Azure SQL Database och klickar på Fortsätt.
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
- Ange AzureSqlDatabaseLinkedService som namn.
- Som Servernamn väljer du namnet på servern i listrutan.
- Som Databasnamn väljer du den databas där du skapade customer_table och project_table som en del av förutsättningarna.
- Som Användarnamn anger du namnet på den användare som har åtkomst till databasen.
- För Lösenord anger du lösenordet för användaren.
- Om du vill testa om Data Factory kan ansluta till SQL Server-databasen, klickar du på Testa anslutning. Åtgärda eventuella fel tills anslutningen lyckas.
- Spara den länkade tjänsten genom att klicka på Slutför.
Bekräfta att du ser två länkade tjänster i listan.
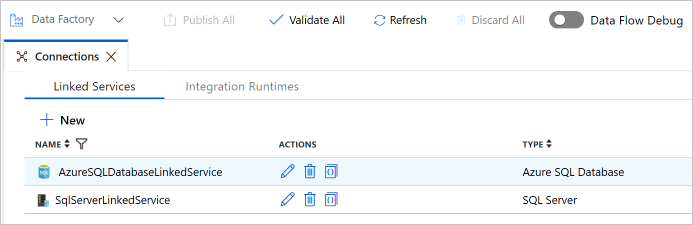
Skapa datauppsättningar
I det här steget skapar du datauppsättningar som representerar datakällan, datamålet och platsen för vattenstämpeln.
Skapa en källdatauppsättning
I den vänstra rutan klickar du på + (plus) och sedan på Datauppsättning.
I fönstret Ny datauppsättning väljer du SQL Server och klickar på Fortsätt.
Du ser en ny flik öppnas i webbläsaren för att konfigurera datauppsättningen. Du ser också en datauppsättning i trädvyn. Längst ned på fliken Allmänt i fönstret Egenskaper skriver du SourceDataset som namn.
Byt till fliken Connection (Anslutning) i fönstret Egenskaper och välj SqlServerLinkedService för Linked service (Länkad tjänst). Du väljer inte en tabell här. Kopieringsaktivitet i pipelinen använder en SQL-fråga till att läsa in data, snarare än att läsa in hela tabellen.

Skapa en källdatauppsättning
I den vänstra rutan klickar du på + (plus) och sedan på Datauppsättning.
I fönstret Ny datauppsättning väljer du Azure SQL Database och klickar på Fortsätt.
Du ser en ny flik öppnas i webbläsaren för att konfigurera datauppsättningen. Du ser också en datauppsättning i trädvyn. Längst ned på fliken Allmänt i fönstret Egenskaper skriver du SinkDataset som namn.
Växla till fliken Parameters (Parametrar) i fönstret Egenskaper och utför följande steg:
Klicka på + Ny i avsnittet för att skapa/uppdatera parametrar.
Ange SinkTableName som namn, och String som typ. Den här datauppsättningen tar SinkTableName som en parameter. Parametern SinkTableName anges dynamiskt vid körning av pipelinen. ForEach-aktiviteten i pipelinen upprepas över en lista med tabellnamn och skickar tabellnamnet till datamängden i varje iteration.

Växla till fliken Anslutning i Fönstret Egenskaper och välj AzureSqlDatabaseLinkedService för länkad tjänst. För egenskapen Table (Tabell) klickar du på Add dynamic content (Lägg till dynamiskt innehåll).
I fönstret Lägg till dynamiskt innehåll väljer du SinkTableName i avsnittet Parametrar .
När du har klickat på Slutför visas "@dataset(). SinkTableName" som tabellnamn.

Skapa en datauppsättning för en vattenstämpel
I det här steget skapar du en datauppsättning för att lagra ett värde för ett högvattenmärke.
I den vänstra rutan klickar du på + (plus) och sedan på Datauppsättning.
I fönstret Ny datauppsättning väljer du Azure SQL Database och klickar på Fortsätt.
Längst ned på fliken Allmänt i fönstret Egenskaper skriver du WatermarkDataset som namn.
Växla till fliken Anslutning och gör följande:
Välj AzureSqlDatabaseLinkedService som länkad tjänst.
Välj [dbo].[watermarktable] för Tabell.
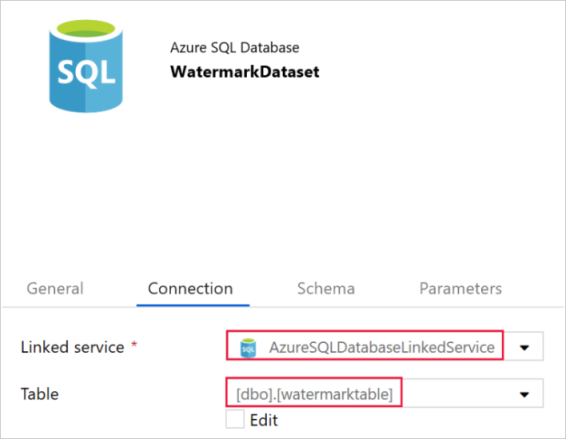
Skapa en pipeline
Den här pipelinen tar en lista med tabellnamn som en parameter. ForEach-aktiviteten upprepas över listan med tabellnamn och utför följande åtgärder:
Använd sökningsaktiviteten till att hämta det gamla vattenmärkesvärdet (startvärdet eller det som användes i den senaste iterationen).
Använd sökningsaktiviteten för att hämta det nya högvattenmärket (högsta värdet i kolumnen vattenmärke i källtabellen).
Använd kopieringsaktiviteten till att kopiera data mellan de två vattenmärkesvärdena från källdatabasen till måldatabasen.
Använd StoredProcedure-aktiviteten för att uppdatera det gamla vattenmärket som ska användas i det första steget i nästa iteration.
Skapa pipelinen
I den vänstra rutan klickar du på + (plus) och sedan på Pipeline.
I panelen Allmänt under Egenskaper anger du IncrementalCopyPipeline som Namn. Dölj sedan panelen genom att klicka på ikonen Egenskaper i det övre högra hörnet.
Gör följande på fliken Parametrar :
- Klicka på + Ny.
- Ange tableList som parameterns namn.
- Välj Matris som parametertyp.
I verktygslådan Aktiviteter expanderar du Iteration & Conditions (Iteration och villkor) och drar och släpper aktiviteten ForEach till pipelinedesignytan. På fliken Allmänt i fönstret Egenskaper skriver du IterateSQLTables som namn.
Växla till fliken Inställningar och ange
@pipeline().parameters.tableListför Objekt. Aktiviteten ForEach upprepas över listan med tabeller och utför följande inkrementella kopieringsåtgärd.
Markera aktiviteten ForEach i pipelinen om det inte redan är markerat. Klicka på knappen Redigera (pennikonen).
I verktygslådan Aktiviteter expanderar du Allmänt och drar och släpper sökningen på pipelinedesignytan. Ange LookupOldWaterMarkActivity som Namn.
Växla till fliken Settings (Inställningar) i fönstret Egenskaper och utför följande steg:
Markera WatermarkDataset för Källdatauppsättning.
Välj Fråga för Använd fråga.
Ange följande SQL-fråga för Fråga.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'
Dra och släpp aktiviteten Lookup från verktygslådan Aktiviteter och ange LookupNewWaterMarkActivity som namn.
Växla till fliken Settings (Inställningar).
Markera SourceDataset för Källdatauppsättning.
Välj Fråga för Använd fråga.
Ange följande SQL-fråga för Fråga.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}
Dra och släpp aktiviteten Copy (Kopiera) från verktygslådan Aktiviteter och ange IncrementalCopyActivity som namn.
Koppla aktiviteterna Lookup (Sökning) till aktiviteten Copy (Kopiering), en i taget. Koppla genom att börja dra den gröna rutan som hör till Lookup-aktiviteten och släpp den på Copy-aktiviteten. Släpp musknappen när du ser att kantlinjefärgen för kopieringsaktiviteten ändras till blått.

Markera Copy-aktiviteten i pipeline. Växla till fliken Source (Käll) i egenskapsfönstret.
Markera SourceDataset för Källdatauppsättning.
Välj Fråga för Använd fråga.
Ange följande SQL-fråga för Fråga.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
Växla till fliken Sink (Mottagare) och markera SinkDataset för Sink Dataset (Datauppsättning för mottagare).
Använd följande steg:
I datauppsättningsegenskaperna för parametern SinkTableName anger du
@{item().TABLE_NAME}.För egenskapen Namn på lagrad procedur anger du
@{item().StoredProcedureNameForMergeOperation}.För Egenskapen Tabelltyp anger du
@{item().TableType}.För Parameternamn för tabelltyp anger du
@{item().TABLE_NAME}.
Dra och släpp aktiviteten Lagrad procedur från verktygslådan Aktiviteter till pipelinedesignytan. Koppla aktiviteten Copy (Kopiera) till aktiviteten Lagrad procedur.
Välj aktiviteten Lagrad procedur i pipelinen och ange StoredProceduretoWriteWatermarkActivity för namn på fliken Allmänt i fönstret Egenskaper.
Växla till fliken SQL-konto och välj AzureSqlDatabaseLinkedService som Länkad tjänst.

Växla till fliken Lagrad procedur och gör följande:
Som Namn på lagrad procedur väljer du
[dbo].[usp_write_watermark].Välj Importera parameter.
Ange följande värden för parametrarna:
Namn Typ Värde LastModifiedtime Datum/tid @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}
Välj Publicera alla för att publicera de entiteter som du skapade till Data Factory-tjänsten.
Vänta tills du ser meddelandet om att entiteterna har publicerats. Klicka på länken Visa meddelanden om du vill se dem. Stäng meddelandefönstret genom att klicka på X.
Köra pipelinen
Klicka på Lägg till utlösare i verktygsfältet för pipelinen och klicka på Utlös nu.
I fönstret Pipelinekörning anger du följande värde för parametern tableList. Klicka på Slutför.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]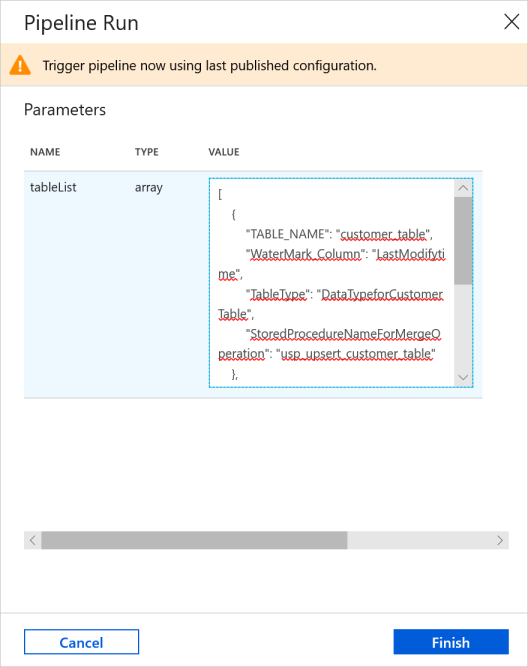
Övervaka pipelinen
Växla till fliken Övervaka till vänster. Du kan se den pipelinekörning som utlöstes av den manuella utlösaren. Du kan använda länkar under kolumnen PIPELINE NAME för att visa aktivitetsinformation och köra pipelinen igen.
Om du vill se aktivitetskörningar som är associerade med pipelinekörningen väljer du länken under kolumnen PIPELINE NAME (PIPELINE NAME ). Om du vill ha mer information om aktivitetskörningarna väljer du länken Information (glasögonikonen) under kolumnen AKTIVITETSNAMN .
Välj Alla pipelinekörningar överst för att gå tillbaka till vyn Pipelinekörningar. Välj Uppdatera för att uppdatera vyn.
Granska resultaten
Kör följande frågor mot SQL-måldatabasen i SQL Server Management Studio för att verifiera att data har kopierats från källtabellerna till måltabellerna:
Fråga
select * from customer_table
Output
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Fråga
select * from project_table
Output
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Fråga
select * from watermarktable
Output
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Observera att vattenstämpelvärdena för båda tabellerna har uppdaterats.
Lägga till mer data i källtabellerna
Kör följande fråga mot SQL Servers källdatabas för att uppdatera en befintlig rad i customer_table. Infoga en ny rad i project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Kör pipelinen igen
Växla till fliken Redigera till vänster i webbläsarfönstret.
Klicka på Lägg till utlösare i verktygsfältet för pipelinen och klicka på Utlös nu.
I fönstret Pipelinekörning anger du följande värde för parametern tableList. Klicka på Slutför.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Övervaka pipelinen igen
Växla till fliken Övervaka till vänster. Du kan se den pipelinekörning som utlöstes av den manuella utlösaren. Du kan använda länkar under kolumnen PIPELINE NAME för att visa aktivitetsinformation och köra pipelinen igen.
Om du vill se aktivitetskörningar som är associerade med pipelinekörningen väljer du länken under kolumnen PIPELINE NAME (PIPELINE NAME ). Om du vill ha mer information om aktivitetskörningarna väljer du länken Information (glasögonikonen) under kolumnen AKTIVITETSNAMN .
Välj Alla pipelinekörningar överst för att gå tillbaka till vyn Pipelinekörningar. Välj Uppdatera för att uppdatera vyn.
Granska de slutliga resultaten
I SQL Server Management Studio kör du följande frågor mot SQL-måldatabasen för att kontrollera att uppdaterade/nya data kopierades från källtabeller till måltabeller.
Fråga
select * from customer_table
Output
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Lägg märke till de nya värdena för Name och LastModifytime för PersonID för nummer 3.
Fråga
select * from project_table
Output
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Observera att posten NewProject har lagts till i project_table.
Fråga
select * from watermarktable
Output
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Observera att vattenstämpelvärdena för båda tabellerna har uppdaterats.
Relaterat innehåll
I den här självstudiekursen fick du:
- Förbereda käll- och måldatalager.
- Skapa en datafabrik.
- Skapa Integration Runtime (IR) med egen värd.
- Installera Integration Runtime.
- Skapa länkade tjänster.
- Skapa datauppsättningar för källa, mottagare och vattenstämpel.
- Skapa, köra och övervaka en pipeline.
- Granska resultaten.
- Lägga till eller uppdatera data i källtabeller.
- Köra och övervaka pipelinen igen.
- Granska de slutliga resultaten.
Fortsätt till följande självstudie och lär dig att transformera data med ett Spark-kluster på Azure: