Använda Azure Toolkit for IntelliJ för att skapa Apache Spark-program för HDInsight-kluster
Den här artikeln visar hur du utvecklar Apache Spark-program i Azure HDInsight med hjälp av Azure Toolkit-plugin-programmet för IntelliJ IDE. Azure HDInsight är en hanterad analystjänst med öppen källkod i molnet. Med tjänsten kan du använda ramverk med öppen källkod som Hadoop, Apache Spark, Apache Hive och Apache Kafka.
Du kan använda Azure Toolkit-plugin-programmet på några olika sätt:
- Utveckla och skicka ett Scala Spark-program till ett HDInsight Spark-kluster.
- Få åtkomst till dina Azure HDInsight Spark-klusterresurser.
- Utveckla och köra ett Scala Spark-program lokalt.
I den här artikeln kan du se hur du:
- Använda plugin-programmet Azure Toolkit for IntelliJ
- Utveckla Apache Spark-program
- Skicka ett program till Azure HDInsight-kluster
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight. Endast HDInsight-kluster i offentliga moln stöds medan andra säkra molntyper (t.ex. myndighetsmoln) inte är det.
Oracle Java Development Kit. Den här artikeln använder Java version 8.0.202.
IntelliJ IDEA. Den här artikeln använder IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Se Installera Azure Toolkit för IntelliJ.
Installera plugin-programmet Scala för IntelliJ IDEA
Steg för att installera Scala-plugin-programmet:
Öppna IntelliJ IDEA.
På välkomstskärmen går du till Konfigurera>Plugin-program för att öppna fönstret Plugin-program.

Välj Installera för det Scala-plugin-program som visas i det nya fönstret.

Du måste starta om IDE när plugin-programmet har installerats.
Skapa ett Spark Scala-program för ett HDInsight Spark-kluster
Starta IntelliJ IDEA och välj Skapa nytt projekt för att öppna fönstret Nytt projekt.
Välj Azure Spark/HDInsight i den vänstra rutan.
Välj Spark-projekt (Scala) i huvudfönstret.
Välj något av följande alternativ i listrutan Build tool (Skapa verktyg ):
Maven för guidestöd när du skapar Scala-projekt.
SBT för att hantera beroenden när du skapar Scala-projektet.

Välj Nästa.
I fönstret Nytt projekt anger du följande information:
Property beskrivning Projektnamn Ange ett namn. Den här artikeln använder myApp.Projektplats Ange platsen där projektet ska sparas. Projekt-SDK Det här fältet kan vara tomt vid din första användning av IDEA. Välj Nytt... och navigera till din JDK. Spark-version Skapandeguiden integrerar rätt version för Spark SDK och Scala SDK. Om Sparks klusterversion är äldre än 2.0 väljer du Spark 1.x. Annars väljer du Spark 2.x. I det här exemplet används Spark 2.3.0 (Scala 2.11.8). 
Välj Slutför. Det kan ta några minuter innan projektet blir tillgängligt.
Spark-projektet skapar automatiskt en artefakt åt dig. Gör följande för att visa artefakten:
a. Från menyraden går du till Filprojektstruktur>....
b. I fönstret Projektstruktur väljer du Artefakter.
c. Välj Avbryt när du har sett artefakten.

Lägg till programmets källkod genom att göra följande:
a. Från Project navigerar du till myApp>src>main>scala.
b. Högerklicka på scala och gå sedan till Ny>Scala-klass.

c. I dialogrutan Skapa ny Scala-klass anger du ett namn, väljer Objekt i listrutan Typ och väljer sedan OK.
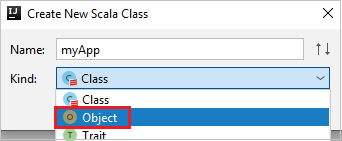
d. Filen myApp.scala öppnas sedan i huvudvyn. Ersätt standardkoden med koden som finns nedan:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Koden läser data från HVAC.csv (finns i alla HDInsight Spark-kluster), hämtar de rader som bara har en siffra i den sjunde kolumnen i CSV-filen och skriver utdata till
/HVACOutunder standardlagringscontainern för klustret.
Anslut till ditt HDInsight-kluster
Användaren kan antingen logga in på din Azure-prenumeration eller länka ett HDInsight-kluster. Använd Ambari-användarnamnet/lösenordet eller domänanslutna autentiseringsuppgifter för att ansluta till ditt HDInsight-kluster.
Logga in till din Azure-prenumeration
Från menyraden går du till Visa>verktyg Windows>Azure Explorer.

Högerklicka på Azure-noden i Azure Explorer och välj sedan Logga in.

I dialogrutan Azure-inloggning väljer du Enhetsinloggning och sedan Logga in.

I dialogrutan Azure Device Login (Azure Device Login) klickar du på Kopiera och öppna.
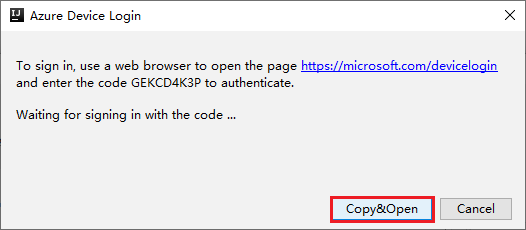
I webbläsargränssnittet klistrar du in koden och klickar sedan på Nästa.

Ange dina Azure-autentiseringsuppgifter och stäng sedan webbläsaren.

När du har loggat in visas alla Azure-prenumerationer som är associerade med autentiseringsuppgifterna i dialogrutan Välj prenumerationer . Välj din prenumeration och välj sedan knappen Välj .

Från Azure Explorer expanderar du HDInsight för att visa DE HDInsight Spark-kluster som finns i dina prenumerationer.

Om du vill visa de resurser (till exempel lagringskonton) som är associerade med klustret kan du ytterligare expandera en klusternamnsnod.

Länka ett kluster
Du kan länka ett HDInsight-kluster med hjälp av det Apache Ambari-hanterade användarnamnet. På samma sätt kan du för ett domänanslutet HDInsight-kluster länka med hjälp av domänen och användarnamnet, till exempel user1@contoso.com. Du kan också länka Livy Service-kluster.
Från menyraden går du till Visa>verktyg Windows>Azure Explorer.
Högerklicka på HDInsight-noden i Azure Explorer och välj sedan Länka ett kluster.

De tillgängliga alternativen i fönstret Länka ett kluster varierar beroende på vilket värde du väljer i listrutan Länkresurstyp . Ange dina värden och välj sedan OK.
HDInsight-kluster
Property Värde Länkresurstyp Välj HDInsight-kluster i listrutan. Klusternamn/URL Ange klusternamn. Autentiseringstyp Lämna som grundläggande autentisering Användarnamn Ange klusteranvändarnamn, standard är administratör. Lösenord Ange lösenord som användarnamn. 
Livy Service
Property Värde Länkresurstyp Välj Livy Service i listrutan. Livy-slutpunkt Ange Livy-slutpunkt Klusternamn Ange klusternamn. Yarn-slutpunkt Valfritt. Autentiseringstyp Lämna som grundläggande autentisering Användarnamn Ange klusteranvändarnamn, standard är administratör. Lösenord Ange lösenord som användarnamn. 
Du kan se ditt länkade kluster från HDInsight-noden .

Du kan också ta bort länken till ett kluster från Azure Explorer.

Köra ett Spark Scala-program i ett HDInsight Spark-kluster
När du har skapat ett Scala-program kan du skicka det till klustret.
Från Project går du till myApp>src>main>scala>myApp. Högerklicka på myApp och välj Skicka Spark-program (det kommer sannolikt att finnas längst ned i listan).

I dialogrutan Skicka Spark-program väljer du 1. Spark på HDInsight.
I fönstret Redigera konfiguration anger du följande värden och väljer sedan OK:
Property Värde Spark-kluster (endast Linux) Välj det HDInsight Spark-kluster som du vill köra programmet på. Välj en artefakt som ska skickas Låt standardinställningen vara kvar. Huvudklassnamn Standardvärdet är huvudklassen från den valda filen. Du kan ändra klassen genom att välja ellipsen(...) och välja en annan klass. Jobbkonfigurationer Du kan ändra standardnycklarna och eller värdena. Mer information finns i Apache Livy REST API. Kommandoradsargument Du kan ange argument avgränsade med blanksteg för huvudklassen om det behövs. Refererade jars och refererade filer Du kan ange sökvägarna för de refererade jar-filerna och filerna om det finns några. Du kan också bläddra bland filer i det virtuella Azure-filsystemet, som för närvarande endast stöder ADLS Gen 2-kluster. Mer information: Apache Spark-konfiguration. Se även Ladda upp resurser till kluster. Lagring för jobbuppladdning Expandera för att visa ytterligare alternativ. Lagringstyp Välj Använd Azure Blob för att ladda upp från listrutan. Lagringskonto Ange ditt lagringskonto. Lagringsnyckel Ange lagringsnyckeln. Lagringscontainer Välj din lagringscontainer i listrutan när lagringskontot och lagringsnyckeln har angetts. 
Välj SparkJobRun för att skicka projektet till det valda klustret. Fliken Fjärr-Spark-jobb i kluster visar jobbkörningens förlopp längst ned. Du kan stoppa programmet genom att klicka på den röda knappen.

Felsöka Apache Spark-program lokalt eller via fjärranslutning i ett HDInsight-kluster
Vi rekommenderar också ett annat sätt att skicka Spark-programmet till klustret. Du kan göra det genom att ange parametrarna i IDE för körnings-/felsökningskonfigurationer . Se Felsöka Apache Spark-program lokalt eller via fjärranslutning i ett HDInsight-kluster med Azure Toolkit for IntelliJ via SSH.
Få åtkomst till och hantera HDInsight Spark-kluster med hjälp av Azure Toolkit for IntelliJ
Du kan utföra olika åtgärder med hjälp av Azure Toolkit for IntelliJ. De flesta åtgärderna startas från Azure Explorer. Från menyraden går du till Visa>verktyg Windows>Azure Explorer.
Få åtkomst till jobbvyn
Från Azure Explorer går du till HDInsight><Dina klusterjobb>>.

I den högra rutan visar fliken Spark-jobbvy alla program som kördes i klustret. Välj namnet på programmet som du vill se mer information för.

Hovra över jobbdiagrammet om du vill visa grundläggande jobbinformation som körs. Om du vill visa stegdiagrammet och informationen som varje jobb genererar väljer du en nod i jobbdiagrammet.

Om du vill visa loggar som används ofta, till exempel Driver Stderr, Driver Stdout och Directory Info, väljer du fliken Logg .

Du kan visa användargränssnittet för Spark-historik och YARN-användargränssnittet (på programnivå). Välj en länk överst i fönstret.
Få åtkomst till Spark-historikservern
Från Azure Explorer expanderar du HDInsight, högerklickar på ditt Spark-klusternamn och väljer sedan Öppna Användargränssnitt för Spark-historik.
När du uppmanas att ange klustrets administratörsautentiseringsuppgifter, som du angav när du konfigurerade klustret.
På instrumentpanelen för Spark-historikservern kan du använda programnamnet för att leta efter det program som du precis har kört. I föregående kod anger du programnamnet med hjälp
val conf = new SparkConf().setAppName("myApp")av . Ditt Spark-programnamn är myApp.
Starta Ambari-portalen
Från Azure Explorer expanderar du HDInsight, högerklickar på ditt Spark-klusternamn och väljer sedan Öppna klusterhanteringsportalen (Ambari).
När du uppmanas att göra det anger du autentiseringsuppgifterna för administratören för klustret. Du angav dessa autentiseringsuppgifter under klusterkonfigurationsprocessen.
Hantera Azure-prenumerationer
Som standard listar Azure Toolkit for IntelliJ Spark-klustren från alla dina Azure-prenumerationer. Om det behövs kan du ange de prenumerationer som du vill komma åt.
Högerklicka på Azure-rotnoden i Azure Explorer och välj sedan Välj prenumerationer.
I fönstret Välj prenumerationer avmarkerar du kryssrutorna bredvid de prenumerationer som du inte vill komma åt och väljer sedan Stäng.
Spark-konsolen
Du kan köra Spark Local Console (Scala) eller köra Spark Livy Interactive Session Console (Scala).
Lokal Spark-konsol (Scala)
Kontrollera att du har uppfyllt WINUTILS.EXE förutsättning.
Från menyraden går du till Kör>Redigera konfigurationer....
I fönstret Kör/felsöka konfigurationer går du till Apache Spark på HDInsight>[Spark på HDInsight] myApp i den vänstra rutan.
Välj fliken i
Locally Runhuvudfönstret.Ange följande värden och välj sedan OK:
Property Värde Jobbets huvudklass Standardvärdet är huvudklassen från den valda filen. Du kan ändra klassen genom att välja ellipsen(...) och välja en annan klass. Miljövariabler Kontrollera att värdet för HADOOP_HOME är korrekt. WINUTILS.exe plats Kontrollera att sökvägen är korrekt. 
Från Project går du till myApp>src>main>scala>myApp.
Från menyraden går du till Verktyg>Spark-konsolen>Kör Spark Local Console(Scala).
Sedan kan två dialogrutor visas för att fråga dig om du vill åtgärda beroenden automatiskt. I så fall väljer du Automatisk korrigering.


Konsolen bör se ut ungefär som bilden nedan. I konsolfönstret skriver du
sc.appNameoch trycker sedan på ctrl+Retur. Resultatet visas. Du kan avsluta den lokala konsolen genom att klicka på röd knapp.
Spark Livy Interactive Session Console (Scala)
Från menyraden går du till Kör>Redigera konfigurationer....
I fönstret Kör/felsöka konfigurationer går du till Apache Spark på HDInsight>[Spark på HDInsight] myApp i den vänstra rutan.
Välj fliken i
Remotely Run in Clusterhuvudfönstret.Ange följande värden och välj sedan OK:
Property Värde Spark-kluster (endast Linux) Välj det HDInsight Spark-kluster som du vill köra programmet på. Huvudklassnamn Standardvärdet är huvudklassen från den valda filen. Du kan ändra klassen genom att välja ellipsen(...) och välja en annan klass. 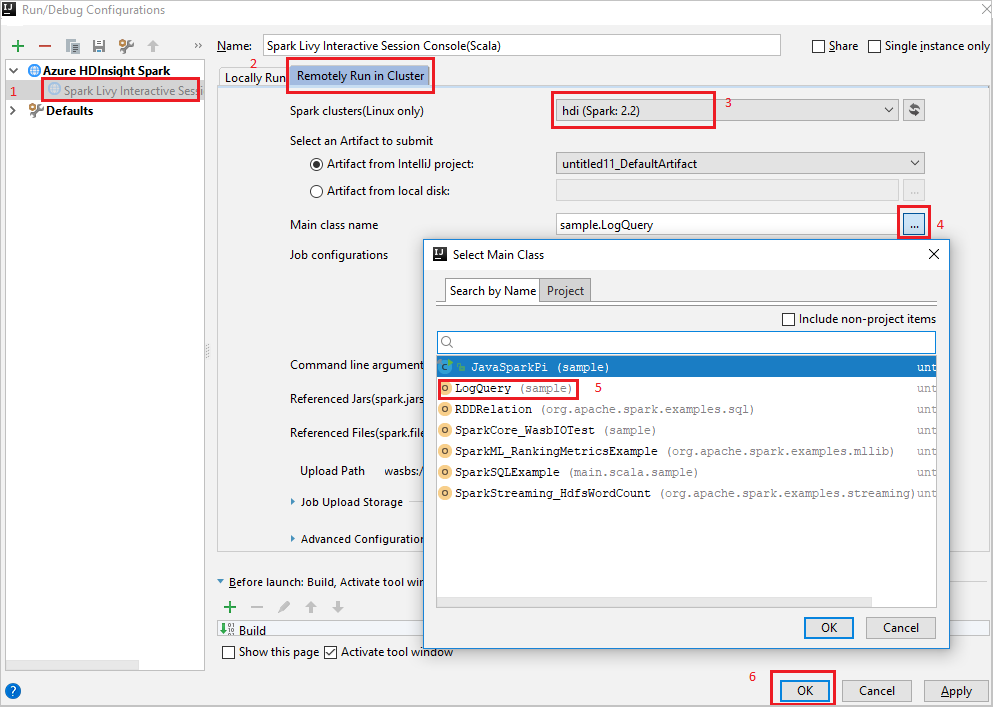
Från Project går du till myApp>src>main>scala>myApp.
Från menyraden går du till Verktyg>Spark-konsolen>Kör Spark Livy Interactive Session Console(Scala).
Konsolen bör se ut ungefär som bilden nedan. I konsolfönstret skriver du
sc.appNameoch trycker sedan på ctrl+Retur. Resultatet visas. Du kan avsluta den lokala konsolen genom att klicka på röd knapp.
Skicka markeringen till Spark-konsolen
Det är praktiskt att förutse skriptresultatet genom att skicka kod till den lokala konsolen eller Livy Interactive Session Console (Scala). Du kan markera lite kod i Scala-filen och sedan högerklicka på Skicka markering till Spark-konsolen. Den valda koden skickas till konsolen. Resultatet visas efter koden i konsolen. Konsolen kontrollerar om det finns några fel.

Integrera med HDInsight Identity Broker (HIB)
Anslut till ditt HDInsight ESP-kluster med ID Broker (HIB)
Du kan följa de vanliga stegen för att logga in på Azure-prenumerationen för att ansluta till ditt HDInsight ESP-kluster med ID Broker (HIB). Efter inloggningen visas klusterlistan i Azure Explorer. Mer information finns i Anslut till ditt HDInsight-kluster.
Kör ett Spark Scala-program i ett HDInsight ESP-kluster med ID Broker (HIB)
Du kan följa de normala stegen för att skicka jobbet till HDInsight ESP-kluster med ID Broker (HIB). Mer information finns i Kör ett Spark Scala-program i ett HDInsight Spark-kluster.
Vi laddar upp nödvändiga filer till en mapp med namnet med ditt inloggningskonto, och du kan se uppladdningssökvägen i konfigurationsfilen.

Spark-konsolen på ett HDInsight ESP-kluster med ID Broker (HIB)
Du kan köra Spark Local Console (Scala) eller köra Spark Livy Interactive Session Console (Scala) på ett HDInsight ESP-kluster med ID Broker (HIB). Mer information finns i Spark-konsolen.
Kommentar
För HDInsight ESP-klustret med Id Broker (HIB) stöds för närvarande inte länkning av ett kluster och felsökning av Apache Spark-program via fjärranslutning .
Rollen endast läsare
När användare skickar jobb till ett kluster med behörighet som endast läsare krävs Ambari-autentiseringsuppgifter.
Länka kluster från snabbmenyn
Logga in med rollkontot endast för läsare.
Från Azure Explorer expanderar du HDInsight för att visa HDInsight-kluster som finns i din prenumeration. Klustren som är märkta "Role:Reader" har endast behörighet som endast läsare.

Högerklicka på klustret med behörighet som endast läsare. Välj Länka det här klustret från snabbmenyn för att länka kluster. Ange användarnamnet och lösenordet för Ambari.

Om klustret har länkats uppdateras HDInsight. Klustrets fas länkas.

Länka kluster genom att expandera noden Jobb
Klicka på Noden Jobb . Fönstret Nekad åtkomst till klusterjobb öppnas.
Klicka på Länka det här klustret för att länka klustret.

Länka kluster från fönstret Kör/felsöka konfigurationer
Skapa en HDInsight-konfiguration. Välj sedan Fjärrkör i kluster.
Välj ett kluster som har rollbehörighet endast för läsare för Spark-kluster (endast Linux). Varningsmeddelandet visas. Du kan klicka på Länka det här klustret för att länka klustret.

Visa lagringskonton
För kluster med behörighet som endast läsare klickar du på noden Lagringskonton , fönstret Nekad lagringsåtkomst visas. Du kan klicka på Öppna Azure Storage Explorer för att öppna Storage Explorer.


För länkade kluster klickar du på noden Lagringskonton , fönstret Nekad lagringsåtkomst visas. Du kan klicka på Öppna Azure Storage för att öppna Storage Explorer.


Konvertera befintliga IntelliJ IDEA-program till att använda Azure Toolkit for IntelliJ
Du kan konvertera befintliga Spark Scala-program som du skapade i IntelliJ IDEA till att vara kompatibla med Azure Toolkit for IntelliJ. Du kan sedan använda plugin-programmet för att skicka programmen till ett HDInsight Spark-kluster.
Öppna den associerade
.imlfilen för ett befintligt Spark Scala-program som skapades via IntelliJ IDEA.På rotnivå är ett modulelement som följande text:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Redigera elementet som ska läggas till
UniqueKey="HDInsightTool"så att modulelementet ser ut som följande text:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Spara ändringarna. Ditt program bör nu vara kompatibelt med Azure Toolkit for IntelliJ. Du kan testa det genom att högerklicka på projektnamnet i Project. Popup-menyn har nu alternativet Skicka Spark-program till HDInsight.
Rensa resurser
Om du inte kommer att fortsätta att använda det här programmet tar du bort klustret som du skapade med följande steg:
Logga in på Azure-portalen.
I rutan Sök längst upp skriver du HDInsight.
Välj HDInsight-kluster under Tjänster.
I listan över HDInsight-kluster som visas väljer du ... bredvid klustret som du skapade för den här artikeln.
Välj Ta bort. Välj Ja.

Fel och lösning
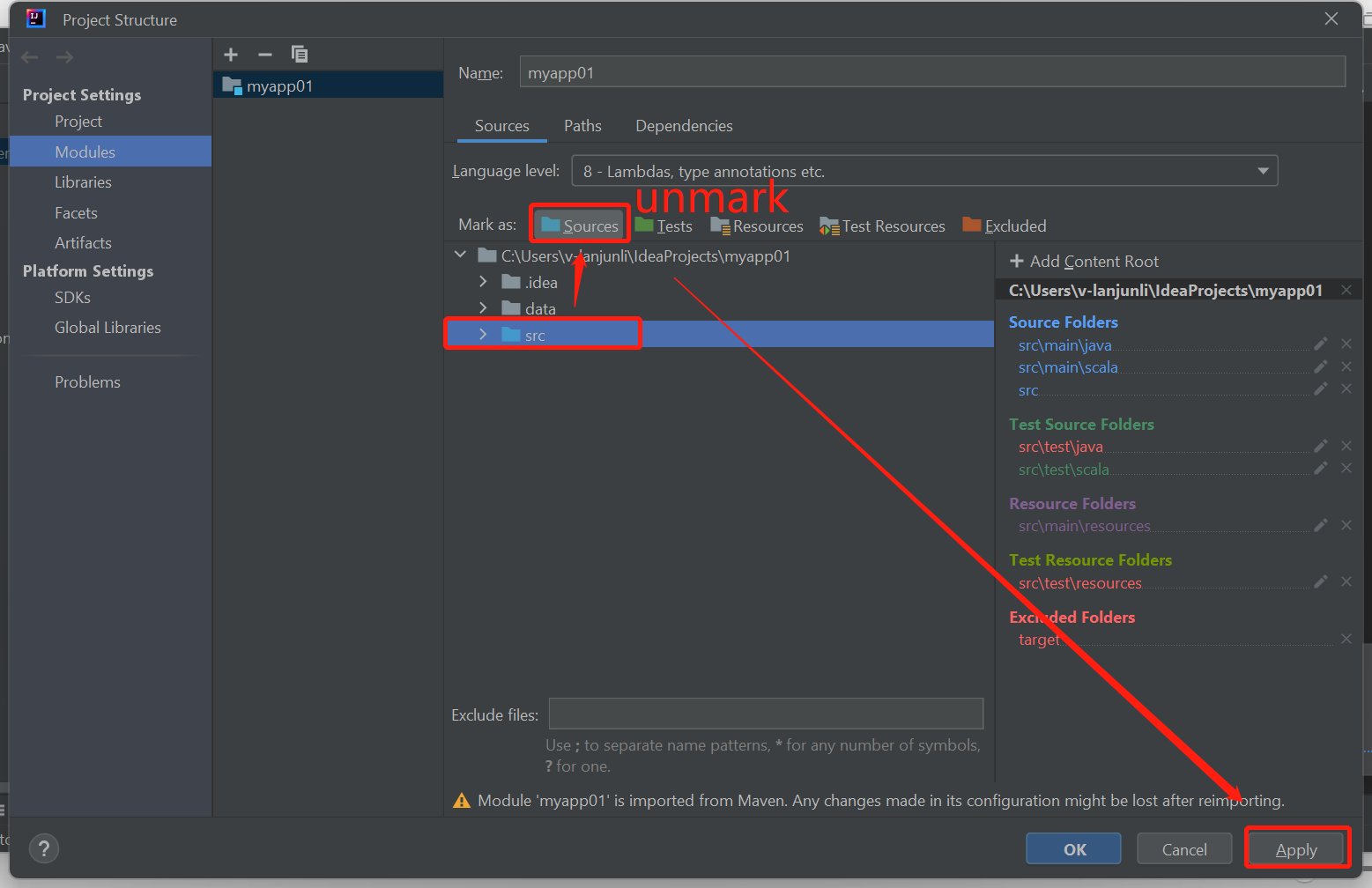
Avmarkera src-mappen som Källor om du får fel om att det inte gick att skapa enligt nedan:

Avmarkera src-mappen som Källor för att lösa problemet:
Gå till Arkiv och välj Projektstruktur.
Välj modulerna under Project Inställningar.
Välj src-filen och avmarkera som Källor.
Klicka på knappen Använd och klicka sedan på OK för att stänga dialogrutan.
Nästa steg
I den här artikeln har du lärt dig hur du använder Plugin-programmet Azure Toolkit for IntelliJ för att utveckla Apache Spark-program skrivna i Scala. Sedan skickade de dem till ett HDInsight Spark-kluster direkt från IntelliJ:s integrerade utvecklingsmiljö (IDE). Gå vidare till nästa artikel för att se hur de data som du har registrerat i Apache Spark kan hämtas till ett BI-analysverktyg såsom Power BI.