Använda Apache Zeppelin-anteckningsböcker med Apache Spark-kluster i Azure HDInsight
HDInsight Spark-kluster innehåller Apache Zeppelin-notebook-filer . Använd notebook-filerna för att köra Apache Spark-jobb. I den här artikeln får du lära dig hur du använder Zeppelin-notebook-filen i ett HDInsight-kluster.
Förutsättningar
- Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
- URI-schemat för dina klusters primära lagring. Schemat skulle vara
wasb://för Azure Blob Storage,abfs://för Azure Data Lake Storage Gen2 elleradl://för Azure Data Lake Storage Gen1. Om säker överföring är aktiverad för Blob Storage blirwasbs://URI:n . Mer information finns i Kräv säker överföring i Azure Storage .
Starta en Apache Zeppelin-anteckningsbok
I Översikt över Spark-klustret väljer du Zeppelin Notebook från klusterinstrumentpaneler. Ange administratörsautentiseringsuppgifterna för klustret.
Kommentar
Du kan också nå Zeppelin Notebook för klustret genom att öppna följande URL i webbläsaren. Ersätt CLUSTERNAME med namnet på klustret:
https://CLUSTERNAME.azurehdinsight.net/zeppelinSkapa en ny anteckningsbok. Gå till Anteckningsbok>Skapa ny anteckning i rubrikfönstret.

Ange ett namn på anteckningsboken och välj sedan Skapa anteckning.
Kontrollera att notebook-huvudet visar en ansluten status. Den betecknas med en grön punkt i det övre högra hörnet.

Läs in exempeldata i en tillfällig tabell. När du skapar ett Spark-kluster i HDInsight kopieras exempeldatafilen,
hvac.csv, till det associerade lagringskontot under\HdiSamples\SensorSampleData\hvac.I det tomma stycket som skapas som standard i den nya notebook-filen klistrar du in följande kodfragment.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Tryck på SKIFT + RETUR eller välj knappen Spela upp för stycket för att köra kodfragmentet. Statusen till höger i stycket ska gå från KLAR, VÄNTAR, KÖRS till KLAR. Utdata visas längst ned i samma stycke. Skärmbilden ser ut som följande bild:

Du kan också ange en rubrik för varje stycke. I det högra hörnet i stycket väljer du ikonen Inställningar (sprocket) och väljer sedan Visa rubrik.
Kommentar
%spark2-tolk stöds inte i Zeppelin-notebook-filer i alla HDInsight-versioner, och %sh-tolken stöds inte från HDInsight 4.0 och senare.
Nu kan du köra Spark SQL-instruktioner i
hvactabellen. Klistra in följande fråga i ett nytt stycke. Frågan hämtar byggnads-ID:t. Också skillnaden mellan målet och faktiska temperaturer för varje byggnad på ett visst datum. Tryck på SKIFT + RETUR.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Instruktionen %sql i början instruerar notebook-filen att använda Livy Scala-tolken.
Välj ikonen Stapeldiagram för att ändra visningen. inställningar visas när du har valt stapeldiagram, låter dig välja Nycklar och Värden. Följande skärmbild visar utdata.

Du kan också köra Spark SQL-instruktioner med hjälp av variabler i frågan. Nästa kodfragment visar hur du definierar en variabel,
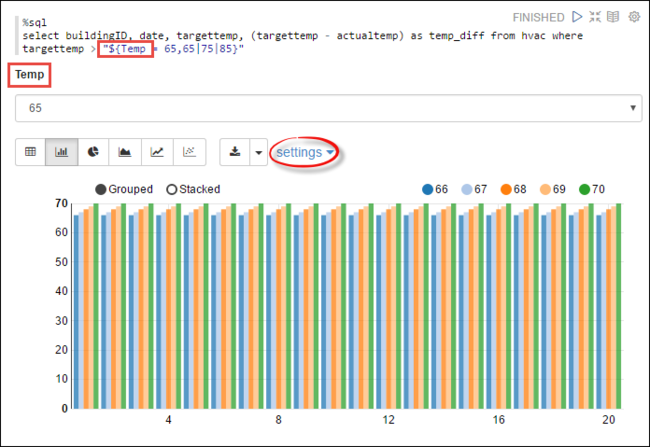
Temp, i frågan med de möjliga värden som du vill fråga med. När du först kör frågan fylls en listruta automatiskt med de värden som du har angett för variabeln.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Klistra in det här kodfragmentet i ett nytt stycke och tryck på SKIFT + RETUR. Välj sedan 65 i listrutan Temp .
Välj ikonen Stapeldiagram för att ändra visningen. Välj sedan inställningar och gör följande ändringar:
Grupper: Lägg till måltemp.
Värden: 1. Ta bort datum. 2. Lägg till temp_diff. 3. Ändra aggregatorn från SUM till AVG.
Följande skärmbild visar utdata.
Hur gör jag för att använda externa paket med notebook-filen?
Zeppelin Notebook i Apache Spark-kluster i HDInsight kan använda externa, community-bidragna paket som inte ingår i klustret. Sök på Maven-lagringsplatsen efter den fullständiga listan över paket som är tillgängliga. Du kan också hämta en lista över tillgängliga paket från andra källor. En fullständig lista över community-bidragda paket finns till exempel på Spark Packages.
I den här artikeln får du se hur du använder spark-csv-paketet med Jupyter Notebook.
Öppna tolkinställningar. I det övre högra hörnet väljer du det inloggade användarnamnet och väljer sedan Tolk.

Rulla till livy2 och välj sedan redigera.

Navigera till nyckeln
livy.spark.jars.packagesoch ange dess värde i formatetgroup:id:version. Om du vill använda spark-csv-paketet måste du ange värdet för nyckeln tillcom.databricks:spark-csv_2.10:1.4.0.
Välj Spara och sedan OK för att starta om Livy-tolken.
Om du vill förstå hur du anländer till värdet för nyckeln som anges ovan gör du så här.
a. Leta upp paketet på Maven-lagringsplatsen. I den här artikeln använde vi spark-csv.
b. Från lagringsplatsen samlar du in värdena för GroupId, ArtifactId och Version.

c. Sammanfoga de tre värdena, avgränsade med ett kolon (:).
com.databricks:spark-csv_2.10:1.4.0
Var sparas Zeppelin-anteckningsböckerna?
Zeppelin-notebook-filerna sparas i klustrets huvudnoder. Om du tar bort klustret tas även notebook-filerna bort. Om du vill bevara dina notebook-filer för senare användning i andra kluster måste du exportera dem när du har kört jobben. Om du vill exportera en notebook-fil väljer du ikonen Exportera enligt bilden nedan.

Den här åtgärden sparar notebook-filen som en JSON-fil på nedladdningsplatsen.
Kommentar
I HDI 4.0 är sökvägen till zeppelin notebook-katalogen,
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/T.ex /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Var som i HDI 5.0 och ovanför den här sökvägen är annorlunda
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/T.ex /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Filnamnet som lagras är annorlunda i HDI 5.0. Den lagras som
<notebook_name>_<sessionid>.zplnT.ex testzeppelin_2JJK53XQA.zpln
I HDI 4.0 lagras filnamnet bara note.json under session_id katalog.
T.ex /2JMC9BZ8X/note.json
HDI Zeppelin sparar alltid notebook-filen i sökvägen
/usr/hdp/<version>/zeppelin/notebook/på en lokal hn0-disk.Om du vill att notebook-filen ska vara tillgänglig även efter att klustret har tagits bort kan du försöka använda Azure File Storage (Använda SMB-protokoll) och länka den till den lokala sökvägen. Mer information finns i Mount SMB Azure file share on Linux (Montera SMB Azure-filresurs på Linux)
När du har monterat den kan du ändra zeppelin-konfigurationen zeppelin.notebook.dir till den monterade sökvägen i ambari-användargränssnittet.
- SMB-filresursen som GitNotebookRepo-lagring rekommenderas inte för zeppelin version 0.10.1
Använd Shiro för att konfigurera åtkomst till Zeppelin-tolkar i ESP-kluster (Enterprise Security Package)
Som nämnts ovan stöds inte tolken %sh från HDInsight 4.0 och senare. Eftersom tolken introducerar potentiella säkerhetsproblem, till exempel åtkomstnyckelflikar med shell-kommandon, har den dessutom %sh tagits bort från HDInsight 3.6 ESP-kluster. Det innebär att %sh tolken inte är tillgänglig när du klickar på Skapa ny anteckning eller i tolkgränssnittet som standard.
Privilegierade domänanvändare kan använda Shiro.ini filen för att styra åtkomsten till tolkgränssnittet. Endast dessa användare kan skapa nya %sh tolkar och ange behörigheter för varje ny %sh tolk. Använd följande steg för att styra åtkomsten shiro.ini med hjälp av filen:
Definiera en ny roll med ett befintligt domännamn för domängruppen. I följande exempel
adminGroupNameär en grupp privilegierade användare i AAD. Använd inte specialtecken eller blanksteg i gruppnamnet. Tecknen efter=ger behörighet för den här rollen.*innebär att gruppen har fullständiga behörigheter.[roles] adminGroupName = *Lägg till den nya rollen för åtkomst till Zeppelin-tolkar. I följande exempel får alla användare i
adminGroupNameåtkomst till Zeppelin-tolkar och kan skapa nya tolkar. Du kan placera flera roller mellan hakparenteserna iroles[], avgränsade med kommatecken. Sedan kan användare som har nödvändiga behörigheter komma åt Zeppelin-tolkar.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Exempel shiro.ini för flera domängrupper:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy sessionshantering
Det första kodstycket i zeppelinanteckningsboken skapar en ny Livy-session i klustret. Den här sessionen delas över alla Zeppelin-anteckningsböcker som du senare skapar. Om Livy-sessionen av någon anledning avlivas körs inte jobb från Zeppelin-anteckningsboken.
I sådana fall måste du utföra följande steg innan du kan börja köra jobb från en Zeppelin-anteckningsbok.
Starta om Livy-tolken från Zeppelin-anteckningsboken. Det gör du genom att öppna tolkinställningarna genom att välja det inloggade användarnamnet i det övre högra hörnet och sedan välja Tolk.
Rulla till livy2 och välj sedan starta om.

Kör en kodcell från en befintlig Zeppelin-anteckningsbok. Den här koden skapar en ny Livy-session i HDInsight-klustret.
Allmän information
Verifiera tjänsten
Om du vill verifiera tjänsten från Ambari går du till https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary platsen där CLUSTERNAME är namnet på klustret.
För att verifiera tjänsten från en kommandorad, SSH till huvudnoden. Växla användare till zeppelin med kommandot sudo su zeppelin. Statuskommandon:
| Kommando | beskrivning |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Tjänststatus. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Tjänstversion. |
ps -aux | grep zeppelin |
Identifiera PID. |
Loggplatser
| Tjänst | Sökväg |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Serverloggar | /var/log/zeppelin |
Konfigurationstolkare, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf eller /etc/zeppelin/conf |
| PID-katalog | /var/run/zeppelin |
Aktivera felsökningsloggning
Navigera till
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summaryplatsen där CLUSTERNAME är namnet på klustret.Gå till CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Ändra
log4j.appender.dailyfile.Threshold = INFOtilllog4j.appender.dailyfile.Threshold = DEBUG.Lägg till
log4j.logger.org.apache.zeppelin.realm=DEBUG.Spara ändringar och starta om tjänsten.