Standarddiagnostik för lastbalanserare med mått, aviseringar och resurshälsa
Azure Load Balancer visar följande diagnostikfunktioner:
Flerdimensionella mått och aviseringar: Tillhandahåller flerdimensionella diagnostikfunktioner via Azure Monitor för Azure Load Balancer-konfigurationer. Du kan övervaka, hantera och felsöka dina standardresurser för lastbalanserare.
Resurshälsa: Resource Health-statusen för lastbalanseraren är tillgänglig på sidan Resurshälsa under Övervaka. Den här automatiska kontrollen informerar dig om den aktuella tillgängligheten för lastbalanserarens resurs.
Den här artikeln innehåller en snabb genomgång av dessa funktioner och erbjuder olika sätt att använda dem för en standardlastbalanserare.
Flerdimensionella mått
Azure Load Balancer tillhandahåller flerdimensionella mått via Azure Metrics i Azure Portal, och det hjälper dig att få diagnostiska insikter i realtid om dina lastbalanserares resurser. Observera att flerdimensionella mått inte stöds för grundläggande lastbalanserare
De olika konfigurationerna för lastbalanserare innehåller följande mått:
| Mått | Resurstyp | beskrivning | Rekommenderad aggregering |
|---|---|---|---|
| Tillgänglighet för datasökvägar | Offentlig och intern lastbalanserare | En lastbalanserare använder kontinuerligt datasökvägen inifrån en region till lastbalanserarens klientdel till nätverket som stöder den virtuella datorn. Så länge felfria instanser finns kvar följer mätningen samma sökväg som programmets belastningsutjämningstrafik. Den datasökväg som används verifieras. Mätningen är osynlig för ditt program och stör inte andra åtgärder. | Genomsnitt |
| Status för hälsoavsökningen | Offentlig och intern lastbalanserare | En lastbalanserare använder en distribuerad hälsoavsökningstjänst som övervakar programslutpunktens hälsa enligt konfigurationsinställningarna. Med det här måttet får du en sammanställd vy eller filtrerad vy per slutpunkt för varje instansslutpunkt i lastbalanserarens pool. Du kan se hur lastbalanseraren ser hälsotillståndet för ditt program, enligt konfigurationen av hälsoavsökningen. | Genomsnitt |
| SYN-antal | Offentlig och intern lastbalanserare | En lastbalanserare avslutar inte TCP-anslutningar (Transmission Control Protocol) eller interagerar med TCP- eller UDP-flöden (User Data-gram Packet). Flöden och deras handskakningar sker alltid mellan källan och den virtuella datorinstansen. Du kan felsöka dina scenarier med TCP-protokoll på ett bättre sätt genom att använda räknare för SYN-paket för att förstå hur många TCP-anslutningsförsök som görs. Måttet rapporterar antalet TCP SYN-paket som tagits emot. | Sum |
| Antal SNAT-anslutningar (Source Network Address Translation) | Offentlig lastbalanserare | En lastbalanserare rapporterar antalet utgående flöden som är maskerade för klientdelen för den offentliga IP-adressen. SNAT-portar är en outtömlig resurs. Det här måttet kan ge en indikation på hur mycket ditt program förlitar sig på SNAT för utgående flöden. Räknare för lyckade och misslyckade utgående SNAT-flöden rapporteras. Räknarna kan användas för att felsöka och förstå hälsotillståndet för dina utgående flöden. | Sum |
| Allokerade SNAT-portar | Offentlig lastbalanserare | En lastbalanserare rapporterar antalet SNAT-portar som allokerats per serverdelsinstans | Genomsnitt. |
| Använda SNAT-portar | Offentlig lastbalanserare | En lastbalanserare rapporterar antalet SNAT-portar som används per serverdelsinstans. | Genomsnitt |
| Antal byte | Offentlig och intern lastbalanserare | En lastbalanserare rapporterar de data som bearbetas per klientdel. Du kanske märker att byteen inte distribueras lika mellan serverdelsinstanserna. Detta förväntas eftersom Azure Load Balancer-algoritmen baseras på flöden | Sum |
| Antal paket | Offentlig och intern lastbalanserare | En lastbalanserare rapporterar de paket som bearbetas per klientdel. | Sum |
Kommentar
Bandbreddsrelaterade mått som SYN-paket, antal byte och antal paket samlar inte in någon trafik till en intern lastbalanserare via en UDR (t.ex. från en NVA eller brandvägg).
Max- och minaggregeringar är inte tillgängliga för måtten SYN count, packet count, SNAT connection count och byte count. Antalsaggregering rekommenderas inte för datasökvägstillgänglighet och hälsoavsökningsstatus. Använd genomsnitt i stället för bäst representerade hälsodata.
Visa måtten för lastbalanseraren i Azure Portal
Azure Portal exponerar lastbalanserarens mått via sidan Mått. Den här sidan är tillgänglig både på lastbalanserarens resurssida för en viss resurs och på sidan Azure Monitor.
Kommentar
Azure Load Balancer skickar inte hälsoavsökningar till frigjorda virtuella datorer. När virtuella datorer frigörs slutar lastbalanseraren att rapportera mått för den instansen. Mått som inte är tillgängliga visas som en streckad rad i portalen eller visar ett felmeddelande som anger att mått inte kan hämtas.
Så här visar du måtten för lastbalanserarens resurser:
Gå till måttsidan och utför någon av följande uppgifter:
På lastbalanserarens resurssida väljer du måtttypen i listrutan.
På sidan Azure Monitor väljer du lastbalanserarens resurs.
Ange lämplig måttaggregeringstyp.
Du kan också konfigurera nödvändig filtrering och gruppering.
Du kan också konfigurera tidsintervallet och aggregeringen. Som standard visas tiden i UTC.
Kommentar
Tidsaggregering är viktigt när du tolkar vissa mått eftersom data samplas en gång per minut. Om tidsaggregering är inställt på fem minuter och måttaggregeringstypen Summa används för mått som SNAT-allokering, visar diagrammet fem gånger den totala allokerade SNAT-portarna.
Rekommendation: När du analyserar måttaggregeringstypen Summa och Antal rekommenderar vi att du använder ett tidsaggregeringsvärde som är större än en minut.

Bild: Mått för datasökvägstillgänglighet för en standardlastbalanserare
Hämta flerdimensionella mått programmatiskt via API:er
Api-vägledning för att hämta flerdimensionella måttdefinitioner och värden finns i Genomgång av REST API för Azure Monitoring. Dessa mått kan skrivas till ett lagringskonto genom att lägga till en diagnostikinställning för kategorin Alla mått.
Vanliga diagnostikscenarier och rekommenderade vyer
Är datasökvägen upp och tillgänglig för min lastbalanserares klientdel?
Expandera
Måttet Tillgänglighet för datasökväg beskriver hälsotillståndet i regionen för datasökvägen till den beräkningsvärd där dina virtuella datorer finns. Måttet är en återspegling av lastbalanserarens hälsotillstånd baserat på konfigurationen och Azure-infrastrukturen. Du kan använda måttet för att:
Övervaka tjänstens externa tillgänglighet.
Undersök plattformen där din tjänst distribueras och ta reda på om den är felfri. Kontrollera om gästoperativsystemet eller programinstansen är felfri.
Isolera om en händelse är relaterad till din tjänst eller det underliggande dataplanet. Blanda inte ihop det här måttet med måttet Status för hälsoavsökning.
Så här hämtar du tillgängligheten för datasökvägen för dina lastbalanserares resurser:
Kontrollera att rätt lastbalanseringsresurs är markerad.
I listrutan Mått väljer du Tillgänglighet för datasökväg.
I listrutan Sammansättning väljer du Genomsnittlig.
Lägg dessutom till ett filter på klientdelens IP-adress eller klientdelsport som dimension med den nödvändiga IP-adressen för klientdelen eller klientdelsporten. Gruppera dem sedan efter den valda dimensionen.

Bild: Information om avsökning av lastbalanserares klientdel
Måttet genereras av en avsökningstjänst i regionen som simulerar trafik. Avsökningstjänsten genererar regelbundet ett paket som matchar distributionens klientdels- och belastningsutjämningsregel. Paketet passerar sedan regionen från källan till värden för en virtuell dator i serverdelspoolen. Lastbalanserarens infrastruktur utför samma belastningsutjämning och översättningsåtgärder som för all annan trafik. När avsökningen har anlänt till värden, där en virtuell dator i serverdelspoolen finns, genererar värden ett svar på avsökningstjänsten. Den virtuella datorn ser inte den här trafiken.
Observera att måttet För tillgänglighet för datasökväg endast genereras i IP-konfigurationer på klientdelen med belastningsutjämningsregler.
Måttet för datasökvägstillgänglighet kan degraderas av följande skäl:
Distributionen har inga felfria virtuella datorer kvar i serverdelspoolen.
Ett infrastrukturfel har inträffat.
I diagnostiksyfte kan du använda måttet för tillgänglighet för datasökvägar tillsammans med hälsoavsökningens status.
Använd Genomsnitt som aggregering för de flesta scenarier.
Svarar serverdelsinstanserna för min lastbalanserare på avsökningar?
Expandera
Måttet Status för hälsoavsökning beskriver hälsotillståndet för programdistributionen som konfigurerats av dig när du konfigurerar hälsoavsökningen för lastbalanseraren. Lastbalanseraren använder statusen för hälsoavsökningen för att avgöra var nya flöden ska skickas. Hälsoavsökningar kommer från en Azure-infrastrukturadress och visas i gästoperativsystemet på den virtuella datorn.
Så här hämtar du måttet Status för hälsoavsökning för lastbalanserarens resurser:
Välj måttet Status för hälsoavsökning med typen för genomsnittlig aggregering.
Tillämpa ett filter på den port eller IP-adress som krävs för klienten (eller båda).
Hälsoavsökningar misslyckas av följande orsaker:
Du konfigurerar en hälsoavsökning till en port som inte lyssnar eller inte svarar eller använder fel protokoll. Om tjänsten använder direkt serverretur eller flytande IP-regler kontrollerar du att tjänsten lyssnar på IP-adressen för nätverkskortets IP-konfiguration och den loopback som har konfigurerats med klientdelens IP-adress.
Nätverkssäkerhetsgruppen, den virtuella datorns brandvägg för gästoperativsystem eller filter på programnivå tillåter inte hälsoavsökningstrafiken.
Använd Genomsnitt som aggregering för de flesta scenarier.
Hur gör jag för att kolla in min statistik över utgående anslutningar?
Expandera
Måttet för SNAT-anslutningar beskriver volymen av lyckade och misslyckade anslutningar för utgående flöden.
En misslyckad anslutningsvolym på större än noll indikerar SNAT-portöverbelastning. Du måste undersöka ytterligare för att avgöra vad som kan orsaka dessa fel. SNAT-portöverbelastningsmanifest som ett fel vid upprättande av ett utgående flöde. Läs artikeln om utgående anslutningar för att förstå scenarier och mekanismer i arbetet och lära dig hur du minimerar och utformar för att undvika SNAT-portöverbelastning.
Så här hämtar du SNAT-anslutningsstatistik:
Välj måtttypen SNAT-anslutningar och Summa som aggregering.
Gruppera efter anslutningstillstånd för lyckade och misslyckade antal SNAT-anslutningar som ska representeras av olika rader.

Bild: Antal SNAT-anslutningar för lastbalanserare
Hur gör jag för att kontrollera min SNAT-portanvändning och allokering?
Expandera
Måttet för använda SNAT-portar spårar hur många SNAT-portar som används för att underhålla utgående flöden. Det här måttet anger hur många unika flöden som upprättas mellan en internetkälla och en virtuell dator på serverdelen eller en vm-skalningsuppsättning som ligger bakom en lastbalanserare och som inte har någon offentlig IP-adress. Genom att jämföra antalet SNAT-portar som du använder med måttet Allokerade SNAT-portar kan du avgöra om tjänsten upplever eller riskerar SNAT-överbelastning och resulterande utgående flödesfel.
Om dina mått indikerar risk för fel i utgående flöde refererar du till artikeln och vidtar åtgärder för att minimera detta för att säkerställa tjänstens hälsa.
Så här visar du användning och allokering av SNAT-portar:
Ange tidssammansättningen för diagrammet till 1 minut för att säkerställa att önskade data visas.
Välj Använda SNAT-portar och/eller allokerade SNAT-portar som måtttyp och Medelvärde som aggregering.
Som standard är dessa mått det genomsnittliga antalet SNAT-portar som allokeras till eller används av varje virtuell serverdelsdator eller vm-skalningsuppsättning. De motsvarar alla offentliga IP-adresser för klientdelen som mappas till lastbalanseraren, aggregerade över TCP och UDP.
Om du vill visa totalt antal SNAT-portar som används av eller allokerats för lastbalanseraren använder du måttaggregeringssumma.
Filtrera efter en specifik protokolltyp, en uppsättning ip-adresser för serverdelen och/eller klientdels-IP-adresser.
Om du vill övervaka hälsotillståndet per serverdel eller klientdelsinstans använder du delning.
- Med delning av anteckningar kan endast ett enda mått visas i taget.
Om du till exempel vill övervaka SNAT-användning för TCP-flöden per dator, aggregera efter genomsnitt, dela efter IP-adresser för serverdelen och filtrera efter protokolltyp.

Bild: Genomsnittlig TCP SNAT-portallokering och användning för en uppsättning virtuella serverdelsdatorer

Bild: TCP SNAT-portanvändning per serverdelsinstans
Hur gör jag för att kontrollera inkommande/utgående anslutningsförsök för min tjänst?
Expandera
Ett SYN-paketmått beskriver volymen av TCP SYN-paket, som har anlänt eller skickats för utgående flöden som är associerade med en specifik klientdel. Du kan använda det här måttet för att förstå TCP-anslutningsförsök till din tjänst.Mer information om utgående anslutningar finns i SNAT (Source Network Address Translation) för utgående anslutningar
Använd Sum som sammansättning för de flesta scenarier.

Bild: SYN-antal lastbalanserare
Hur gör jag för att kontrollera förbrukningen av nätverksbandbredd?
Expandera
Måttet byte och paketräknare beskriver mängden byte och paket som skickas eller tas emot av tjänsten per klientdel.
Använd Sum som sammansättning för de flesta scenarier.
Så här hämtar du byte- eller paketräkningsstatistik:
Välj måtttypen Bytes Count och/eller Packet Count med Sum som sammansättning.
Gör något av följande:
Använd ett filter på en specifik klientdels-IP-adress, klientdelsport, serverdels-IP eller serverdelsport.
Hämta övergripande statistik för lastbalanserarens resurs utan filtrering.

Bild: Antal byte för lastbalanserare
Hur gör jag för att diagnostisera distributionen av lastbalanseraren?
Expandera
Genom att använda en kombination av måtten för datasökvägstillgänglighet och status för hälsoavsökningar i ett enda diagram kan du identifiera var du ska leta efter problemet och lösa problemet. Du kan se till att Azure fungerar korrekt och använda den här kunskapen för att slutgiltigt fastställa att konfigurationen eller programmet är rotorsaken.
Du kan använda mått för hälsoavsökning för att förstå hur Azure ser på hälsotillståndet för distributionen enligt den konfiguration som du har angett. Att titta på hälsoavsökningar är alltid ett bra första steg när det gäller att övervaka eller fastställa en orsak.
Du kan ta det ett steg längre och använda datasökvägstillgänglighetsmått för att få insikt i hur Azure visar hälsotillståndet för det underliggande dataplanet som ansvarar för din specifika distribution. När du kombinerar båda måtten kan du isolera var felet kan vara, vilket visas i det här exemplet:
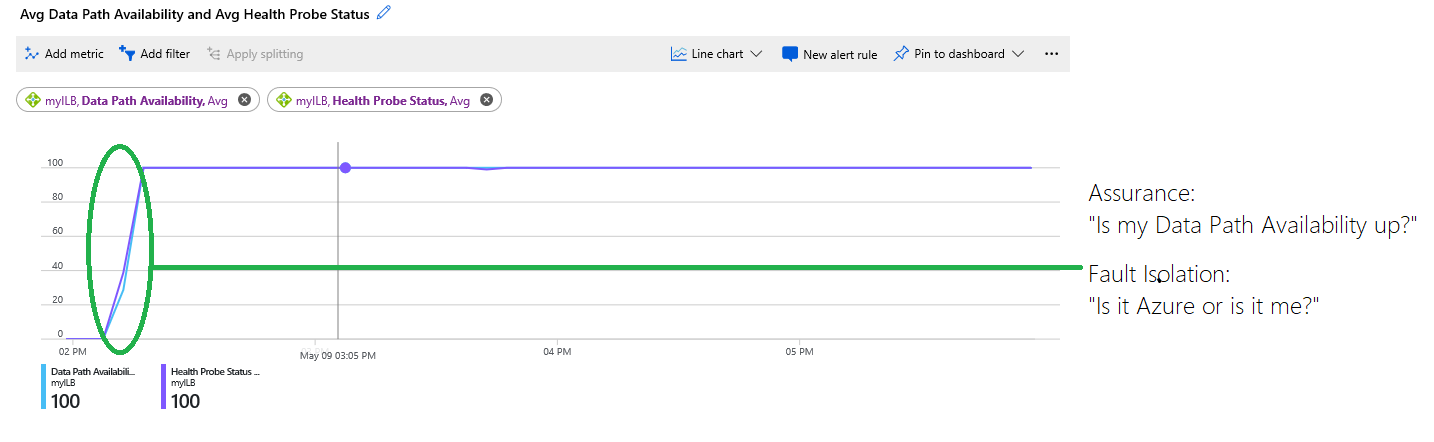
Bild: Kombinera datasökvägstillgänglighet och statusmått för hälsoavsökning
Diagrammet visar följande information:
Infrastrukturen som var värd för dina virtuella datorer var inte tillgänglig och låg på 0 procent i början av diagrammet. Senare var infrastrukturen felfri och de virtuella datorerna kunde nås och mer än en virtuell dator placerades i serverdelen. Den här informationen anges av den blå spårningen för datasökvägstillgänglighet, som senare var 100 procent.
Hälsoavsökningsstatusen, som anges av den lila spårningen, är 0 procent i början av diagrammet. Det inringade området i grönt markerar var hälsoavsökningens status blev felfri och då kunde kundens distribution acceptera nya flöden.
Diagrammet gör det möjligt för kunder att felsöka distributionen på egen hand utan att behöva gissa eller fråga support om andra problem uppstår. Tjänsten var inte tillgänglig eftersom hälsoavsökningarna misslyckades på grund av antingen en felkonfiguration eller ett misslyckat program.
Konfigurera aviseringar för flerdimensionella mått
Azure Load Balancer stöder enkelt konfigurerbara aviseringar för flerdimensionella mått. Konfigurera anpassade tröskelvärden för specifika mått för att utlösa aviseringar med varierande allvarlighetsgrad för att ge en upplevelse för resursövervakning utan beröring.
Så här konfigurerar du varningar:
Gå till aviseringssidan för lastbalanseraren
Skapa en ny aviseringsregel
Konfigurera aviseringsvillkor (Obs! För att undvika bullriga aviseringar rekommenderar vi att du konfigurerar aviseringar med aggregeringstypen inställd på Genomsnitt, ser tillbaka på ett femminutersfönster med data och med ett tröskelvärde på 95 %)
(Valfritt) Lägg till åtgärdsgrupp för automatisk reparation
Tilldela allvarlighetsgrad, namn och beskrivning för aviseringar som möjliggör intuitiv reaktion
Aviseringar om inkommande tillgänglighet
Kommentar
Om lastbalanserarens serverdelspooler är tomma har lastbalanseraren inga giltiga datasökvägar att testa. Därför kommer datasökvägstillgänglighetsmåttet inte att vara tillgängligt och eventuella konfigurerade Azure-aviseringar på datasökvägens tillgänglighetsmått utlöses inte.
Om du vill avisera om inkommande tillgänglighet kan du skapa två separata aviseringar med hjälp av måtten för tillgänglighet för datasökväg och statusmått för hälsoavsökning. Kunder kan ha olika scenarier som kräver specifik aviseringslogik, men exemplen nedan är användbara för de flesta konfigurationer.
Med hjälp av tillgänglighet för datasökvägar kan du utlösa aviseringar när en specifik belastningsutjämningsregel blir otillgänglig. Du kan konfigurera den här aviseringen genom att ange ett aviseringsvillkor för datasökvägens tillgänglighet och dela upp med alla aktuella värden och framtida värden för både klientdelsporten och klientdelens IP-adress. Om aviseringslogik anges till mindre än eller lika med 0 utlöses aviseringen när någon belastningsutjämningsregel slutar svara. Ange sammansättningskornighet och utvärderingsfrekvens enligt önskad utvärdering.
Med status för hälsoavsökning kan du avisera när en viss serverdelsinstans inte svarar på hälsoavsökningen under en betydande tid. Konfigurera aviseringsvillkoret för att använda måttet för hälsoavsökningsstatus och dela upp efter serverdels-IP-adress och serverdelsport. Detta säkerställer att du kan avisera separat för varje enskild serverdelsinstanss möjlighet att hantera trafik på en specifik port. Använd den genomsnittliga aggregeringstypen och ange tröskelvärdet enligt hur ofta serverdelsinstansen avsöks och det tröskelvärde som anses vara felfritt.
Du kan också avisera på en serverdelspoolnivå genom att inte dela upp efter några dimensioner och använda den genomsnittliga aggregeringstypen. På så sätt kan du konfigurera aviseringsregler, till exempel aviseringar när 50 % av mina medlemmar i serverdelspoolen inte är felfria.
Aviseringar om utgående tillgänglighet
För utgående tillgänglighet kan du konfigurera två separata aviseringar med SNAT-anslutningsantalet och använda SNAT-portmått.
Om du vill identifiera utgående anslutningsfel konfigurerar du en avisering med SNAT-anslutningsantal och filtrering till anslutningstillstånd = Misslyckades. Använd den totala aggregeringen. Sedan kan du dela upp detta efter serverdels-IP-adress inställd på alla aktuella och framtida värden för att avisera separat för varje serverdelsinstans som har misslyckade anslutningar. Ange tröskelvärdet till större än noll eller ett högre tal om du förväntar dig att se några utgående anslutningsfel.
Med använda SNAT-portar kan du avisera om en högre risk för SNAT-överbelastning och utgående anslutningsfel. Se till att du delar upp med ip-adress och protokoll för serverdelen när du använder den här aviseringen. Använd den genomsnittliga aggregeringen. Ange tröskelvärdet till större än en procentandel av det antal portar som du har allokerat per instans som du anser är osäker. Konfigurera till exempel en avisering med låg allvarlighetsgrad när en serverdelsinstans använder 75 % av sina allokerade portar. Konfigurera en varning med hög allvarlighetsgrad när den använder 90 % eller 100 % av sina allokerade portar.
Status för resurshälsa
Hälsostatus för standardresurserna för lastbalanseraren exponeras via den befintliga resurshälsan under Övervaka > Tjänststatus. Den utvärderas varannan minut genom att mäta tillgängligheten för datavägar som avgör om klientdelens belastningsutjämningsslutpunkter är tillgängliga.
| Status för resurshälsa | Beskrivning |
|---|---|
| Tillgängligt | Din standardresurs för lastbalanserare är felfri och tillgänglig. |
| Degraderad | Din standardlastbalanserare har plattforms- eller användarinitierade händelser som påverkar prestanda. Måttet för datasökvägstillgänglighet har rapporterat mindre än 90 % men större än 25 % hälsa i minst två minuter. Med den här statusen får du måttlig till svår prestandaeffekt. Följ felsökningsguiden för RHC för att avgöra om det finns användarinitierade händelser som påverkar din tillgänglighet. |
| Inte tillgänglig | Standardresursen för lastbalanseraren är inte felfri. Måttet för datasökvägstillgänglighet har rapporterat mindre 25 % hälsa i minst två minuter. Med den här statusen får du betydande prestandaeffekt eller brist på tillgänglighet för inkommande anslutningar. Det kan finnas användar- eller plattformshändelser som orsakar otillgänglighet. Följ felsökningsguiden för RHC för att avgöra om det finns användarinitierade händelser som påverkar din tillgänglighet. |
| Okänt | Hälsostatusen för lastbalanserarens resurs har inte uppdaterats eller har inte tagit emot information om tillgängligheten för datasökvägen under de senaste 10 minuterna. Det här tillståndet bör vara tillfälligt och återspegla rätt status så snart data tas emot. |
Så här visar du hälsotillståndet för dina offentliga standardresurser för lastbalanserare:
Välj Övervaka> Tjänststatus.

Bild: Länken för tjänstens hälsotillstånd i Azure Monitor
Välj Resurshälsa och kontrollera sedan att Prenumerations-ID och Resurstyp = lastbalanserare är markerade.

Bild: Välj resurs för hälsovyn
I listan väljer du lastbalanserarens resurs för att visa dess historiska hälsostatus.

Bild: Status för resurshälsa
En allmän beskrivning av en resurshälsostatus finns i dokumentationen om resurshälsa.
Resource Health-aviseringar
Azure Resource Health-aviseringar kan meddela dig nästan i realtid när hälsotillståndet för lastbalanserarens resurs ändras. Vi rekommenderar att du anger hälsoaviseringar för resursen så att du meddelas när lastbalanserarens resurs är i ett degraderat eller otillgängligt tillstånd.
När du skapar Azure-resurshälsoaviseringar för lastbalanserare skickar Azure hälsomeddelanden för resurser till din Azure-prenumeration. Du kan skapa och anpassa aviseringar baserat på:
- Den prenumeration som påverkas
- Den resursgrupp som påverkas
- Den resurstyp som påverkas (lastbalanserare)
- Den specifika resursen (valfri lastbalanserare som du väljer att konfigurera en avisering för)
- Händelsestatus för lastbalanserarens resurs som påverkas
- Den aktuella statusen för den lastbalanserare som påverkas
- Den tidigare statusen för lastbalanserarens resurs som påverkas
- Orsakstypen för lastbalanserarens resurs som påverkas
Du kan också konfigurera vem aviseringen ska skickas till:
- En ny åtgärdsgrupp (som kan användas för framtida aviseringar)
- En befintlig åtgärdsgrupp
Mer information om hur du konfigurerar dessa resurshälsoaviseringar finns i:
- Aviseringar om resurshälsa med hjälp av Azure Portal
- Aviseringar om resurshälsa med Hjälp av Resource Manager-mallar
Nästa steg
- Läs mer om Nätverksanalys.
- Lär dig mer om hur du använder Insights för att visa de här måtten som är förkonfigurerade för lastbalanseraren.
- Läs mer om standardlastbalanserare.