Felsöka indataanslutningar
Den här artikeln beskriver vanliga problem med Azure Stream Analytics-indataanslutningar, hur du felsöker dessa problem och hur du korrigerar dem.
Många felsökningssteg kräver att du aktiverar resursloggar för ditt Stream Analytics-jobb. Om du inte har aktiverat resursloggar kan du läsa Felsöka Azure Stream Analytics med hjälp av resursloggar.
Jobbet tar inte emot indatahändelser
Kontrollera anslutningen till indata och utdata. Använd knappen Test Anslut ion för varje indata och utdata.
Granska dina indata:
Använd knappen Exempeldata för varje indata. Ladda ned indataexempeldata.
Granska exempeldata för att förstå schema- och datatyperna.
Kontrollera måtten för Azure Event Hubs för att se till att händelser skickas. Meddelandemåtten bör vara större än noll om Event Hubs tar emot meddelanden.
Kontrollera att du har valt ett tidsintervall i förhandsversionen av indata. Välj Välj tidsintervall och ange sedan en exempelvaraktighet innan du testar frågan.
Viktigt!
För Azure Stream Analytics-jobb som inte matas in i nätverket ska du inte förlita dig på källans IP-adress för anslutningar som kommer från Stream Analytics på något sätt. De kan vara offentliga eller privata IP-adresser, beroende på tjänstinfrastrukturåtgärder som sker då och då.
Felaktiga indatahändelser orsakar deserialiseringsfel
Deserialiseringsproblem uppstår när indataströmmen för ditt Stream Analytics-jobb innehåller felaktiga meddelanden. En parentes eller klammerparentes som saknas i ett JSON-objekt eller ett felaktigt tidsstämpelformat i tidsfältet kan till exempel orsaka ett felaktigt meddelande.
När ett Stream Analytics-jobb tar emot ett felaktigt formaterat meddelande från en indata släpper det meddelandet och meddelar dig med en varning. En varningssymbol visas på panelen Indata i Stream Analytics-jobbet. Varningssymbolen finns så länge jobbet är i ett körningstillstånd.
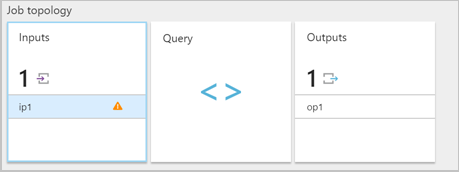
Aktivera resursloggar för att visa information om felet och meddelandet (nyttolasten) som orsakade felet. Det finns flera orsaker till att deserialiseringsfel kan inträffa. Mer information om specifika deserialiseringsfel finns i Indatafel. Om resursloggar inte är aktiverade visas ett kort meddelande i Azure-portalen.
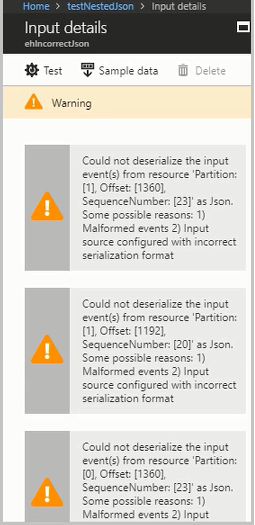
Om meddelandets nyttolast är större än 32 KB eller är i binärt format kör du den CheckMalformedEvents.cs kod som är tillgänglig på GitHub-exempellagringsplatsen. Den här koden läser partitions-ID-förskjutningen och skriver ut data som finns i förskjutningen.
Andra vanliga orsaker till indatadeserialiseringsfel är:
- En heltalskolumn som har ett värde som är större än
9223372036854775807. - Strängar i stället för en matris med objekt eller radavgränsade objekt. Giltigt exempel:
*[{'a':1}]*. Ogiltigt exempel:*"'a' :1"*. - Använda en Event Hubs-avbildningsblob i Avro-format som indata i ditt jobb.
- Att ha två kolumner i en enda indatahändelse som bara skiljer sig åt i fall. Exempel:
*column1*och*COLUMN1*.
Ändringar i antal partitioner
Partitionsantalet för händelsehubbar kan ändras. Om partitionsantalet för en händelsehubb ändras måste du stoppa och starta om Stream Analytics-jobbet.
Följande fel visas när partitionsantalet för en händelsehubb ändras medan jobbet körs: Microsoft.Streaming.Diagnostics.Exceptions.InputPartitioningChangedException.
Jobbet överskrider det maximala antalet Event Hubs-mottagare
Bästa praxis för att använda Event Hubs är att använda flera konsumentgrupper för jobbskalbarhet. Antalet läsare i Stream Analytics-jobbet för specifika indata påverkar antalet läsare i en enskild konsumentgrupp.
Det exakta antalet mottagare baseras på intern implementeringsinformation för utskalningstopologilogik. Talet exponeras inte externt. Antalet läsare kan ändras när ett jobb startas eller uppgraderas.
Följande felmeddelande visas när antalet mottagare överskrider maxgränsen. Meddelandet innehåller en lista över befintliga anslutningar som gjorts till Event Hubs under en konsumentgrupp. Taggen AzureStreamAnalytics anger att anslutningarna kommer från en Azure-strömningstjänst.
The streaming job failed: Stream Analytics job has validation errors: Job will exceed the maximum amount of Event Hubs Receivers.
The following information may be helpful in identifying the connected receivers: Exceeded the maximum number of allowed receivers per partition in a consumer group which is 5. List of connected receivers –
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1,
AzureStreamAnalytics_c4b65e4a-f572-4cfc-b4e2-cf237f43c6f0_1.
Kommentar
När antalet läsare ändras under en jobbuppgradering skrivs tillfälliga varningar till granskningsloggar. Stream Analytics-jobb återställs automatiskt från dessa tillfälliga problem.
Följ dessa steg om du vill lägga till en ny konsumentgrupp i din Event Hubs-instans:
Logga in på Azure-portalen.
Leta upp din händelsehubb.
Under rubriken Entiteter väljer du Event Hubs.
Välj händelsehubben efter namn.
På sidan Event Hubs-instans går du till rubriken Entiteter och väljer Konsumentgrupper. En konsumentgrupp med namnet $Default visas.
Välj + Konsumentgrupp för att lägga till en ny konsumentgrupp.
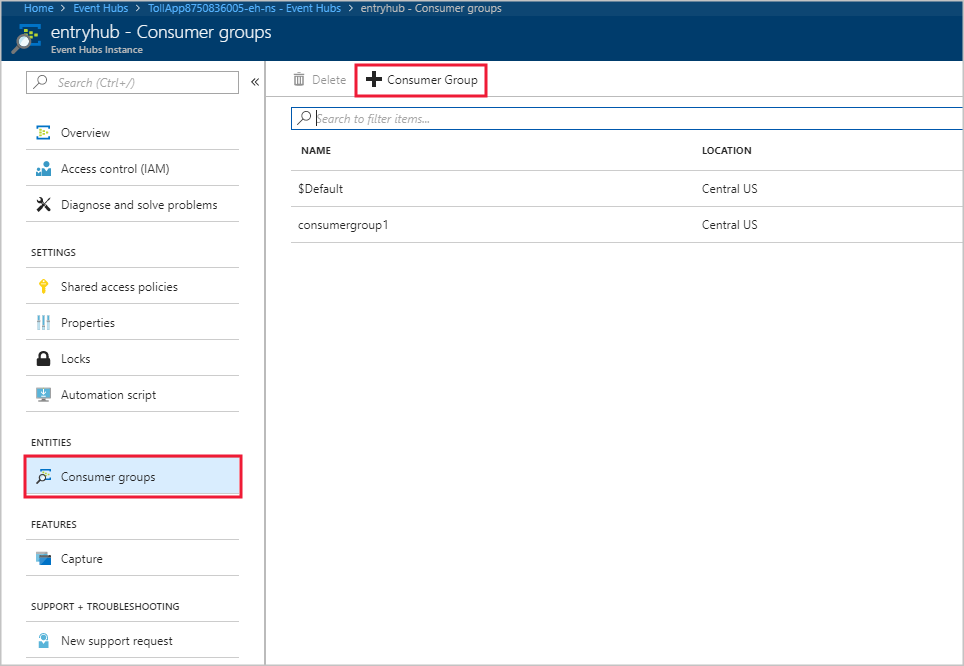
När du skapade indata i Stream Analytics-jobbet för att peka på händelsehubben angav du konsumentgruppen där. Event Hubs använder $Default om ingen konsumentgrupp har angetts. När du har skapat en konsumentgrupp redigerar du händelsehubbens indata i Stream Analytics-jobbet och anger namnet på den nya konsumentgruppen.
Läsare per partition överskrider gränsen för Event Hubs
Om din strömmande frågesyntax refererar till samma resurs för händelsehubbens indata flera gånger kan jobbmotorn använda flera läsare per fråga från samma konsumentgrupp. När det finns för många referenser till samma konsumentgrupp kan jobbet överskrida gränsen på fem och utlösa ett fel. Under dessa omständigheter kan du dela upp ytterligare genom att använda flera indata mellan flera konsumentgrupper.
Scenarier där antalet läsare per partition överskrider gränsen för Event Hubs på fem är:
Flera
SELECTinstruktioner: Om du använder fleraSELECTinstruktioner som refererar till samma händelsehubbindata skapar varjeSELECTinstruktion en ny mottagare.UNION: När du använderUNIONkan du ha flera indata som refererar till samma händelsehubb och konsumentgrupp.SELF JOIN: När du använder enSELF JOINåtgärd går det att referera till samma händelsehubb flera gånger.
Följande metodtips kan hjälpa till att minimera scenarier där antalet läsare per partition överskrider gränsen för Event Hubs på fem.
Dela upp frågan i flera steg med hjälp av en WITH-sats
Satsen WITH anger en tillfällig namngiven resultatuppsättning som en FROM sats i frågan kan referera till. Du definierar WITH satsen i körningsomfånget för en enda SELECT instruktion.
I stället för den här frågan:
SELECT foo
INTO output1
FROM inputEventHub
SELECT bar
INTO output2
FROM inputEventHub
…
Använder du den här frågan:
WITH data AS (
SELECT * FROM inputEventHub
)
SELECT foo
INTO output1
FROM data
SELECT bar
INTO output2
FROM data
…
Se till att indata binder till olika konsumentgrupper
Skapa separata konsumentgrupper för frågor där tre eller flera indata är anslutna till samma event hubs-konsumentgrupp. Den här uppgiften kräver att ytterligare Stream Analytics-indata skapas.
Skapa separata indata med olika konsumentgrupper
Du kan skapa separata indata med olika konsumentgrupper för samma händelsehubb. I följande exempel på en UNION fråga refererar InputOne och InputTwo till samma Event Hubs-källa. Alla frågor kan ha separata indata med olika konsumentgrupper. Frågan UNION är bara ett exempel.
WITH
DataOne AS
(
SELECT * FROM InputOne
),
DataTwo AS
(
SELECT * FROM InputTwo
),
SELECT foo FROM DataOne
UNION
SELECT foo FROM DataTwo
Läsare per partition överskrider IoT Hub-gränsen
Stream Analytics-jobb använder den inbyggda Event Hubs-kompatibla slutpunkten i Azure IoT Hub för att ansluta och läsa händelser från IoT Hub. Om läsarna per partition överskrider gränserna för IoT Hub kan du lösa problemet med hjälp av lösningarna för Event Hubs . Du kan skapa en konsumentgrupp för den inbyggda slutpunkten via IoT Hub-portalens slutpunktssession eller via IoT Hub SDK.
Få hjälp
Om du vill ha mer hjälp kan du prova microsofts Q&A-sida för Azure Stream Analytics.
Nästa steg
- Introduktion till Azure Stream Analytics
- Analysera bedrägliga samtalsdata med Stream Analytics och visualisera resultat på en Power BI-instrumentpanel
- Skala ett Azure Stream Analytics-jobb för att öka dataflödet
- Referens för Frågespråk för Azure Stream Analytics
- Azure Stream Analytics Management REST API