Extrahera, transformera och läsa in (ETL) i stor skala
Extrahera, transformera och läsa in (ETL) är den process som data hämtas från olika källor. Data samlas in på en standardplats, rensas och bearbetas. I slutändan läses data in i ett datalager som de kan frågas från. Äldre ETL-processer importerar data, rensar dem på plats och lagrar dem sedan i en relationsdatamotor. Med Azure HDInsight stöder en mängd olika Apache Hadoop-miljökomponenter ETL i stor skala.
Användningen av HDInsight i ETL-processen sammanfattas av den här pipelinen:
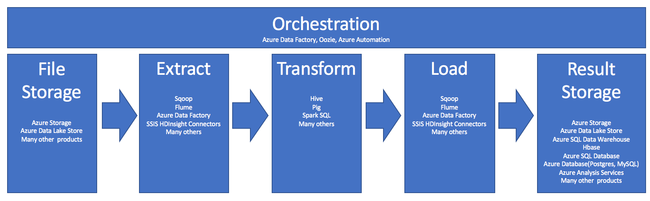
Följande avsnitt utforskar var och en av ETL-faserna och deras associerade komponenter.
Orkestrering
Orkestrering sträcker sig över alla faser i ETL-pipelinen. ETL-jobb i HDInsight omfattar ofta flera olika produkter som arbetar tillsammans med varandra. Till exempel:
- Du kan använda Apache Hive för att rensa en del av data och Apache Pig för att rensa en annan del.
- Du kan använda Azure Data Factory för att läsa in data i Azure SQL Database från Azure Data Lake Store.
Orkestrering krävs för att köra rätt jobb vid lämplig tidpunkt.
Apache Oozie
Apache Oozie är ett system för att koordinera arbetsflöden som hanterar Hadoop-jobb. Oozie körs i ett HDInsight-kluster och är integrerat med Hadoop-stacken. Oozie stöder Hadoop-jobb för Apache Hadoop MapReduce, Pig, Hive och Sqoop. Du kan använda Oozie för att schemalägga jobb som är specifika för ett system, till exempel Java-program eller shell-skript.
Mer information finns i Använda Apache Oozie med Apache Hadoop för att definiera och köra ett arbetsflöde i HDInsight. Se även Operationalisera datapipelinen.
Azure Data Factory
Azure Data Factory tillhandahåller orkestreringsfunktioner i form av PaaS (plattform som en tjänst). Azure Data Factory är en molnbaserad dataintegreringstjänst. Det gör att du kan skapa datadrivna arbetsflöden för orkestrering och automatisering av dataförflyttning och datatransformering.
Använd Azure Data Factory för att:
- Skapa och schemalägga datadrivna arbetsflöden. Dessa pipelines matar in data från olika datalager.
- Bearbeta och transformera data med hjälp av beräkningstjänster som HDInsight eller Hadoop. Du kan också använda Spark, Azure Data Lake Analytics, Azure Batch eller Azure Machine Learning för det här steget.
- Publicera utdata till datalager, till exempel Azure Synapse Analytics, för BI-program att använda.
Mer information om Azure Data Factory finns i dokumentationen.
Mata in fillagring och resultatlagring
Källdatafiler läses vanligtvis in på en plats i Azure Storage eller Azure Data Lake Storage. Filerna är vanligtvis i ett platt format, till exempel CSV. Men de kan vara i valfritt format.
Azure Storage
Azure Storage har specifika anpassningsmål. Mer information finns i Skalbarhets- och prestandamål för Blob Storage . För de flesta analysnoder skalar Azure Storage bäst när du hanterar många mindre filer. Så länge du är inom dina kontogränser garanterar Azure Storage samma prestanda, oavsett hur stora filerna är. Du kan lagra terabyte med data och ändå få konsekventa prestanda. Den här instruktionen gäller oavsett om du använder en delmängd eller alla data.
Azure Storage har flera typer av blobar. En tilläggsblob är ett bra alternativ för att lagra webbloggar eller sensordata.
Flera blobar kan distribueras över många servrar för att skala ut åtkomsten till dem. Men en enda blob hanteras bara av en enda server. Även om blobar kan grupperas logiskt i blobcontainrar finns det inga partitioneringskonsekvenser från den här grupperingen.
Azure Storage har ett WebHDFS API-lager för bloblagringen. Alla HDInsight-tjänster kan komma åt filer i Azure Blob Storage för datarensning och databearbetning. Detta liknar hur dessa tjänster skulle använda Hadoop Distributed File System (HDFS).
Data matas vanligtvis in i Azure Storage via PowerShell, Azure Storage SDK eller AzCopy.
Azure Data Lake Storage
Azure Data Lake Storage är en hanterad lagringsplats för hyperskala för analysdata. Den är kompatibel med och använder ett designparadigm som liknar HDFS. Data Lake Storage erbjuder obegränsad anpassningsbarhet för total kapacitet och storleken på enskilda filer. Det är ett bra val när du arbetar med stora filer, eftersom de kan lagras över flera noder. Partitionering av data i Data Lake Storage görs i bakgrunden. Tjänsten ger massivt dataflöde och kan köra analysjobb med tusentals samtidiga körare som effektivt läser och skriver flera hundra terabyte data.
Data matas vanligtvis in i Data Lake Storage via Azure Data Factory. Du kan också använda Data Lake Storage SDK:er, AdlCopy-tjänsten, Apache DistCp eller Apache Sqoop. Vilken tjänst du väljer beror på var data finns. Om det finns i ett befintligt Hadoop-kluster kan du använda Apache DistCp, AdlCopy-tjänsten eller Azure Data Factory. För data i Azure Blob Storage kan du använda Azure Data Lake Storage .NET SDK, Azure PowerShell eller Azure Data Factory.
Data Lake Storage är optimerat för händelseinmatning via Azure Event Hubs.
Överväganden för båda lagringsalternativen
För att ladda upp datauppsättningar i terabyteintervallet kan nätverksfördröjning vara ett stort problem. Detta gäller särskilt om data kommer från en lokal plats. I sådana fall kan du använda följande alternativ:
Azure ExpressRoute: Skapa privata anslutningar mellan Azure-datacenter och din lokala infrastruktur. Dessa anslutningar är ett tillförlitligt alternativ för överföring av stora mängder data. Mer information finns i Dokumentation om Azure ExpressRoute.
Dataöverföring från hårddiskar: Du kan använda Azure Import/Export-tjänsten för att skicka hårddiskar med dina data till ett Azure-datacenter. Dina data laddas först upp till Azure Blob Storage. Du kan sedan använda Azure Data Factory eller AdlCopy-verktyget för att kopiera data från Azure Blob Storage till Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analytics är ett lämpligt val för att lagra förberedda resultat. Du kan använda Azure HDInsight för att utföra dessa tjänster för Azure Synapse Analytics.
Azure Synapse Analytics är ett relationsdatabasarkiv som är optimerat för analysarbetsbelastningar. Den skalar baserat på partitionerade tabeller. Tabeller kan partitioneras över flera noder. Noderna väljs när de skapas. De kan skalas i efterhand, men det är en aktiv process som kan kräva dataförflyttning. Mer information finns i Hantera beräkning i Azure Synapse Analytics.
Apache HBase
Apache HBase är ett nyckel-/värdearkiv som är tillgängligt i Azure HDInsight. Det är en NoSQL-databas med öppen källkod som bygger på Hadoop och modelleras efter Google BigTable. HBase ger högpresterande slumpmässig åtkomst och stark konsekvens för stora mängder ostrukturerade och halvstrukturerade data.
Eftersom HBase är en schemalös databas behöver du inte definiera kolumner och datatyper innan du använder dem. Data lagras i raderna i en tabell och grupperas efter kolumnfamilj.
Den öppna källkoden skalas linjärt för att hantera petabyte med data på tusentals noder. HBase förlitar sig på dataredundans, batchbearbetning och andra funktioner som tillhandahålls av distribuerade program i Hadoop-miljön.
HBase är ett bra mål för sensor- och loggdata för framtida analys.
HBase-anpassningsbarhet är beroende av antalet noder i HDInsight-klustret.
Azure SQL-databaser
Azure erbjuder tre PaaS-relationsdatabaser:
- Azure SQL Database är en implementering av Microsoft SQL Server. Mer information om prestanda finns i Justera prestanda i Azure SQL Database.
- Azure Database for MySQL är en implementering av Oracle MySQL.
- Azure Database for PostgreSQL är en implementering av PostgreSQL.
Lägg till mer processor och minne för att skala upp dessa produkter. Du kan också välja att använda Premium-diskar med produkterna för bättre I/O-prestanda.
Azure Analysis Services
Azure Analysis Services är en analysdatamotor som används i beslutsstöd och affärsanalys. Den tillhandahåller analysdata för affärsrapporter och klientprogram som Power BI. Analysdata fungerar också med Excel, SQL Server Reporting Services-rapporter och andra datavisualiseringsverktyg.
Skala analyskuber genom att ändra nivåer för varje enskild kub. Mer information finns i Prissättning för Azure Analysis Services.
Extrahera och läsa in
När data finns i Azure kan du använda många tjänster för att extrahera och läsa in dem i andra produkter. HDInsight stöder Sqoop och Flume.
Apache Sqoop
Apache Sqoop är ett verktyg som utformats för att effektivt överföra data mellan strukturerade, halvstrukturerade och ostrukturerade datakällor.
Sqoop använder MapReduce för att importera och exportera data för att tillhandahålla parallell drift och feltolerans.
Apache Flume
Apache Flume är en distribuerad, tillförlitlig och tillgänglig tjänst för att effektivt samla in, aggregera och flytta stora mängder loggdata. Dess flexibla arkitektur baseras på strömmande dataflöden. Flume är robust och feltolerant med justerbara tillförlitlighetsmekanismer. Den har många mekanismer för redundans och återställning. Flume använder en enkel utökningsbar datamodell som möjliggör onlineanalysprogram.
Apache Flume kan inte användas med Azure HDInsight. Men en lokal Hadoop-installation kan använda Flume för att skicka data till antingen Azure Blob Storage eller Azure Data Lake Storage. Mer information finns i Använda Apache Flume med HDInsight.
Transformering
När data finns på den valda platsen måste du rensa dem, kombinera dem eller förbereda dem för ett specifikt användningsmönster. Hive, Pig och Spark SQL är alla bra val för den typen av arbete. De stöds alla i HDInsight.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för