Optimera Apache Hive-frågor i Azure HDInsight
Den här artikeln beskriver några av de vanligaste prestandaoptimeringarna som du kan använda för att förbättra prestandan för dina Apache Hive-frågor.
Val av klustertyp
I Azure HDInsight kan du köra Apache Hive-frågor på några olika klustertyper.
Välj lämplig klustertyp för att optimera prestanda för dina arbetsbelastningsbehov:
- Välj Interaktiv fråga klustertyp för att optimera för
ad hocinteraktiva frågor. - Välj Apache Hadoop-klustertyp för att optimera för Hive-frågor som används som en batchprocess.
- Spark - och HBase-klustertyper kan också köra Hive-frågor och kan vara lämpliga om du kör dessa arbetsbelastningar.
Mer information om hur du kör Hive-frågor på olika HDInsight-klustertyper finns i Vad är Apache Hive och HiveQL på Azure HDInsight?.
Skala ut arbetsnoder
Genom att öka antalet arbetsnoder i ett HDInsight-kluster kan arbetet använda fler mappare och reducers parallellt. Det finns två sätt att öka skalan i HDInsight:
När du skapar ett kluster kan du ange antalet arbetsnoder med hjälp av Azure-portalen, Azure PowerShell eller kommandoradsgränssnittet. Mer information finns i Skapa HDInsight-kluster. Följande skärmbild visar konfigurationen av arbetsnoden på Azure-portalen:
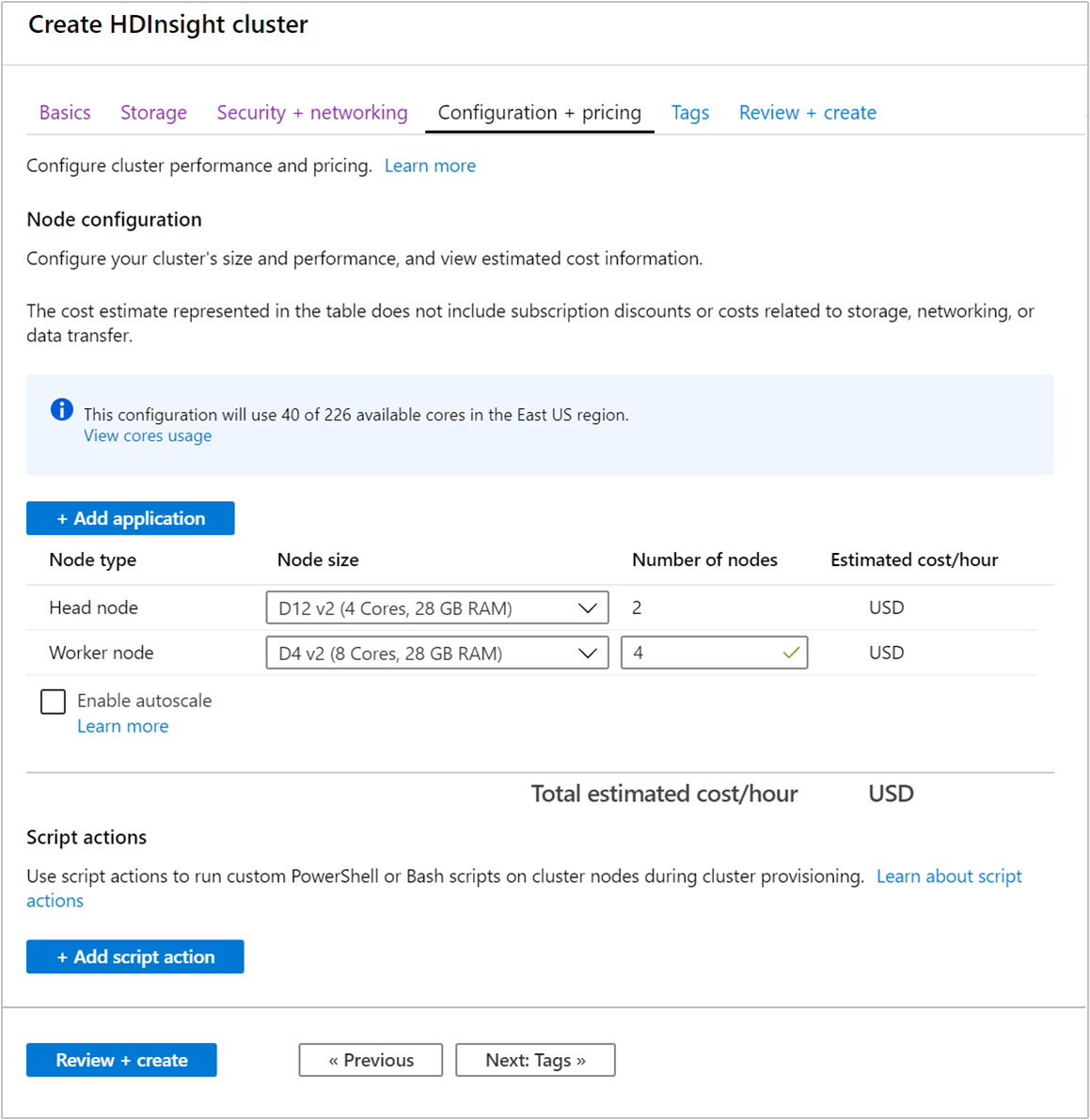
När du har skapat kan du också redigera antalet arbetsnoder för att skala ut ett kluster ytterligare utan att återskapa något:
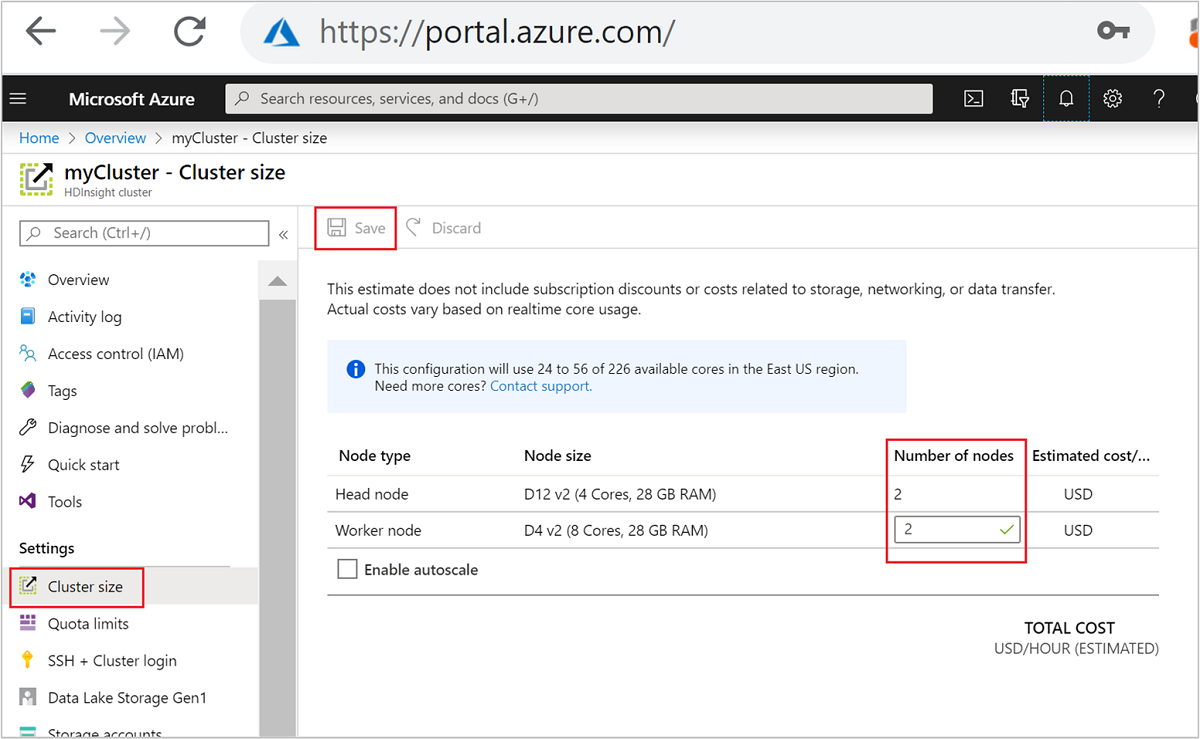
Mer information om hur du skalar HDInsight finns i Skala HDInsight-kluster
Använda Apache Tez i stället för Kartreducering
Apache Tez är en alternativ körningsmotor till MapReduce-motorn. Linux-baserade HDInsight-kluster har Tez aktiverat.
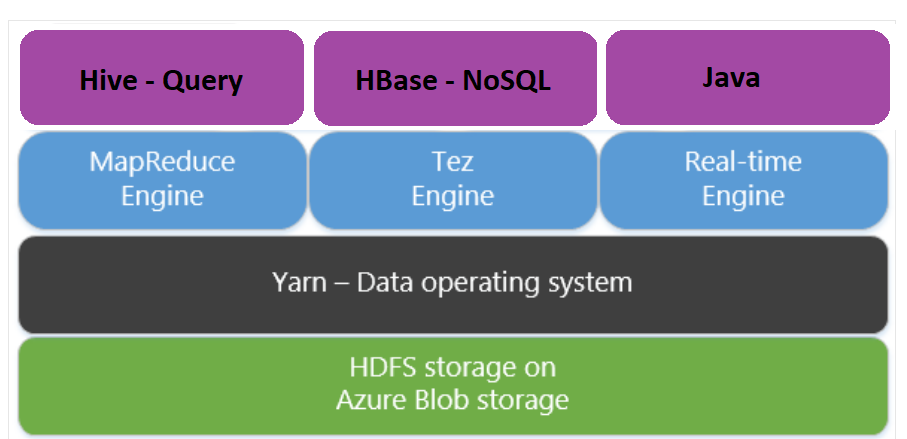
Tez är snabbare eftersom:
- Kör riktad acyklisk graf (DAG) som ett enda jobb i MapReduce-motorn. DAG kräver att varje uppsättning mappningskomponenter följs av en uppsättning reducerare. Denna kravspecifikation leder till att flera MapReduce-jobb startas för varje Hive-fråga. Tez har inte denna begränsning och kan bearbeta DAG som ett enda jobb, vilket minimerar omkostnaderna för jobbstart.
- Undviker onödiga skrivningar. Flera jobb används för att bearbeta samma Hive-fråga i MapReduce-motorn. Utdata för varje MapReduce-jobb skrivs till HDFS för mellanliggande data. Eftersom Tez minimerar antalet jobb för varje Hive-fråga kan det undvika onödiga skrivningar.
- Minimerar fördröjningar vid start. Tez är bättre på att minimera startfördröjningen genom att minska antalet mappningskomponenter som behövs för att starta och även förbättra optimeringen hela vägen.
- Återanvänder containrar. När det är möjligt återanvänder Tez containrar för att säkerställa att svarstiden från att starta containrar minskar.
- Teknik för kontinuerlig optimering. Traditionellt gjordes optimering under kompileringsfasen. Det finns emellertid mer information om indata som möjliggör bättre optimering under körningen. Tez använder kontinuerliga optimeringstekniker som gör det möjligt att optimera planen längre in i körningsfasen.
Mer information om dessa begrepp finns i Apache TEZ.
Du kan göra valfri Hive-fråga tez aktiverad genom att prefixera frågan med följande kommando:
set hive.execution.engine=tez;
Hive-partitionering
I/O-åtgärder är den största prestandaflaskhalsen för att köra Hive-frågor. Prestandan kan förbättras om mängden data som behöver läsas kan minskas. Som standard genomsöker Hive-frågor hela Hive-tabeller. Men för frågor som bara behöver skanna en liten mängd data (till exempel frågor med filtrering) skapar det här beteendet onödiga omkostnader. Hive-partitionering gör att Hive-frågor endast kan komma åt den nödvändiga mängden data i Hive-tabeller.
Hive-partitionering implementeras genom att omorganisera rådata till nya kataloger. Varje partition har en egen filkatalog. Användaren definierar partitioneringen. Följande diagram visar partitionering av en Hive-tabell efter kolumnen År. En ny katalog skapas för varje år.
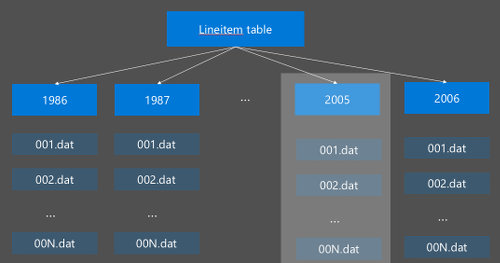
Några partitioneringsöverväganden:
- Inte under partition – Partitionering på kolumner med bara några få värden kan orsaka få partitioner. Till exempel skapar partitionering på kön bara två partitioner som ska skapas (man och kvinna), så minska svarstiden med högst hälften.
- Överskrid inte partitionen – Om du skapar en partition i en kolumn med ett unikt värde (till exempel userid) orsakas flera partitioner. Över partitionen orsakar mycket stress på klusternamnnoden eftersom den måste hantera det stora antalet kataloger.
- Undvik datasnedvridning – Välj partitioneringsnyckeln på ett klokt sätt så att alla partitioner är jämna. Till exempel kan partitionering i kolumnen State skeva fördelningen av data. Eftersom delstaten Kalifornien har en befolkning som är nästan 30 gånger större än Vermont, är partitionsstorleken potentiellt skev och prestandan kan variera enormt.
Om du vill skapa en partitionstabell använder du satsen Partitionerad av :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
När den partitionerade tabellen har skapats kan du antingen skapa statisk partitionering eller dynamisk partitionering.
Statisk partitionering innebär att du redan har fragmenterade data i lämpliga kataloger. Med statiska partitioner lägger du till Hive-partitioner manuellt baserat på katalogplatsen. Följande kodfragment är ett exempel.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Dynamisk partitionering innebär att du vill att Hive ska skapa partitioner automatiskt åt dig. Eftersom du redan har skapat partitioneringstabellen från mellanlagringstabellen behöver du bara infoga data i den partitionerade tabellen:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Mer information finns i Partitionerade tabeller.
Använda ORCFile-formatet
Hive stöder olika filformat. Till exempel:
- Text: standardfilformatet och fungerar med de flesta scenarier.
- Avro: fungerar bra för samverkansscenarier.
- ORC/Parquet: passar bäst för prestanda.
ORC-format (optimerad radkolumn) är ett mycket effektivt sätt att lagra Hive-data. Jämfört med andra format har ORC följande fördelar:
- stöd för komplexa typer, inklusive DateTime och komplexa och halvstrukturerade typer.
- upp till 70 % komprimering.
- indexerar var 10 000 rad, vilket gör det möjligt att hoppa över rader.
- en betydande minskning av körningen av körning.
Om du vill aktivera ORC-format skapar du först en tabell med satsen Lagrad som ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Därefter infogar du data till ORC-tabellen från mellanlagringstabellen. Till exempel:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Du kan läsa mer om ORC-formatet i Apache Hive Language-manualen.
Vektorisering
Med vektorisering kan Hive bearbeta en batch med 1 024 rader tillsammans i stället för att bearbeta en rad i taget. Det innebär att enkla åtgärder utförs snabbare eftersom mindre intern kod behöver köras.
Så här aktiverar du vektoriseringsprefixet för Hive-frågan med följande inställning:
set hive.vectorized.execution.enabled = true;
Mer information finns i Körning av vektoriserade frågor.
Andra optimeringsmetoder
Det finns fler optimeringsmetoder som du kan överväga, till exempel:
- Hive-bucketing: en teknik som gör det möjligt att klustra eller segmentera stora uppsättningar data för att optimera frågeprestanda.
- Kopplingsoptimering: optimering av Hive:s frågekörningsplanering för att förbättra effektiviteten för kopplingar och minska behovet av användartips. Mer information finns i Kopplingsoptimering.
- Öka reducers.
Nästa steg
I den här artikeln har du lärt dig flera vanliga Metoder för Hive-frågeoptimering. Mer information finns i följande artiklar:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för