Snabbstart: Köra Apache Hive-frågor i Azure HDInsight med Apache Zeppelin
I den här snabbstarten lär du dig hur du använder Apache Zeppelin för att köra Apache Hive-frågor i Azure HDInsight. HDInsight-Interaktiv fråga kluster innehåller Apache Zeppelin-notebook-filer som du kan använda för att köra interaktiva Hive-frågor.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Ett HDInsight-Interaktiv fråga kluster. Se Skapa kluster för att skapa ett HDInsight-kluster. Se till att välja Interaktiv fråga klustertyp.
Skapa en Apache Zeppelin-anteckning
Ersätt
CLUSTERNAMEmed namnet på klustret i följande URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Ange sedan URL:en i en webbläsare.Ange användarnamn och lösenord för klusterinloggning. Från Zeppelin-sidan kan du antingen skapa en ny anteckning eller öppna befintliga anteckningar. HiveSample innehåller vissa Hive-exempelfrågor.
Välj Skapa ny anteckning.
I dialogrutan Skapa ny anteckning skriver eller väljer du följande värden:
- Anteckningsnamn: Ange ett namn för anteckningen.
- Standardtolk: Välj jdbc i listrutan.
Välj Skapa anteckning.
Ange följande Hive-fråga i kodavsnittet och tryck sedan på Skift + Retur:
%jdbc(hive) show tables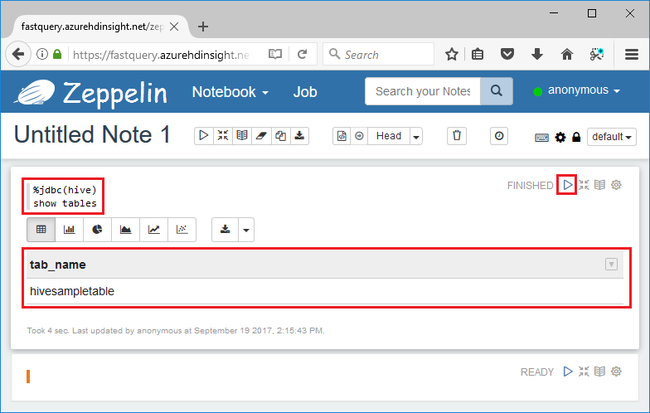
Instruktionen
%jdbc(hive)på den första raden instruerar anteckningsboken att använda Hive JDBC-tolken.Frågan ska returnera en Hive-tabell med namnet hivesampletable.
Följande är ytterligare två Hive-frågor som du kan köra mot hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Jämfört med den traditionella Hive kommer frågeresultaten tillbaka mycket snabbare.
Fler exempel
Skapa en tabell. Kör koden i Zeppelin Notebook:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Läs in data i den nya tabellen. Kör koden i Zeppelin Notebook:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Infoga en enskild post. Kör koden i Zeppelin Notebook:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Mer syntax finns i Språkhandboken för Hive.
Rensa resurser
När du har slutfört snabbstarten kanske du vill ta bort klustret. Med HDInsight lagras dina data i Azure Storage, så att du på ett säkert sätt kan ta bort ett kluster när de inte används. Du debiteras också för ett HDInsight-kluster, även om det inte används. Eftersom avgifterna för klustret är många gånger högre än avgifterna för lagring är det ekonomiskt klokt att ta bort kluster när de inte används.
Information om hur du tar bort ett kluster finns i Ta bort ett HDInsight-kluster med webbläsaren, PowerShell eller Azure CLI.
Nästa steg
I den här snabbstarten har du lärt dig hur du använder Apache Zeppelin för att köra Apache Hive-frågor i Azure HDInsight. Om du vill veta mer om Hive-frågor visar nästa artikel hur du kör frågor med Visual Studio.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för