Använd MirrorMaker för att replikera Apache Kafka-ämnen med Kafka i HDInsight
Lär dig hur du använder Apache Kafkas speglingsfunktion för att replikera ämnen till ett sekundärt kluster. Du kan köra spegling som en kontinuerlig process, eller tillfälligt, för att migrera data från ett kluster till ett annat.
I den här artikeln använder du spegling för att replikera ämnen mellan två HDInsight-kluster. Dessa kluster finns i olika virtuella nätverk i olika datacenter.
Varning
Använd inte spegling som ett sätt att uppnå feltolerans. Förskjutningen till objekt i ett ämne skiljer sig mellan de primära och sekundära klustren, så klienterna kan inte använda de två utbytbart. Om du är orolig för feltolerans bör du ange replikering för ämnena i klustret. Mer information finns i Komma igång med Apache Kafka i HDInsight.
Så här fungerar Apache Kafka-spegling
Spegling fungerar med verktyget MirrorMaker , som är en del av Apache Kafka. MirrorMaker använder poster från ämnen i det primära klustret och skapar sedan en lokal kopia på det sekundära klustret. MirrorMaker använder en (eller flera) konsumenter som läser från det primära klustret och en producent som skriver till det lokala (sekundära) klustret.
Den mest användbara speglingskonfigurationen för haveriberedskap använder Kafka-kluster i olika Azure-regioner. För att uppnå detta peerkopplas de virtuella nätverk där klustren finns.
Följande diagram illustrerar speglingsprocessen och hur kommunikationen flödar mellan kluster:
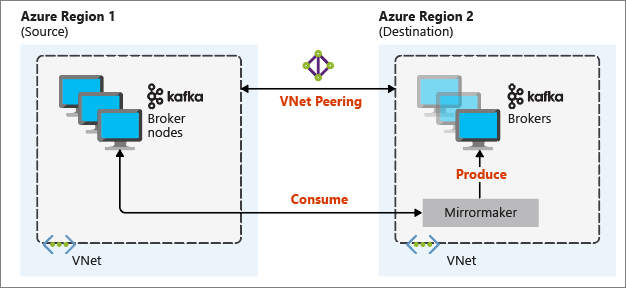
De primära och sekundära klustren kan vara olika i antalet noder och partitioner, och förskjutningar i ämnena är också olika. Spegling underhåller nyckelvärdet som används för partitionering, så postordningen bevaras per nyckel.
Spegling över nätverksgränser
Om du behöver spegla mellan Kafka-kluster i olika nätverk finns följande ytterligare överväganden:
Gatewayer: Nätverken måste kunna kommunicera på TCP/IP-nivå.
Serveradressering: Du kan välja att adressera dina klusternoder med hjälp av deras IP-adresser eller fullständigt kvalificerade domännamn.
IP-adresser: Om du konfigurerar dina Kafka-kluster att använda IP-adressannonsering kan du fortsätta med speglingskonfigurationen med hjälp av IP-adresserna för asynkrona noder och ZooKeeper-noder.
Domännamn: Om du inte konfigurerar dina Kafka-kluster för IP-adressannonsering måste klustren kunna ansluta till varandra med hjälp av fullständigt kvalificerade domännamn (FQDN). Detta kräver en DNS-server (Domain Name System) i varje nätverk som har konfigurerats för att vidarebefordra begäranden till de andra nätverken. När du skapar ett virtuellt Azure-nätverk, i stället för att använda den automatiska DNS som medföljer nätverket, måste du ange en anpassad DNS-server och IP-adressen för servern. När du har skapat det virtuella nätverket måste du sedan skapa en virtuell Azure-dator som använder den IP-adressen. Sedan installerar och konfigurerar du DNS-programvara på den.
Viktigt
Skapa och konfigurera den anpassade DNS-servern innan du installerar HDInsight i det virtuella nätverket. Det krävs ingen ytterligare konfiguration för att HDInsight ska kunna använda DNS-servern som konfigurerats för det virtuella nätverket.
Mer information om hur du ansluter två virtuella Azure-nätverk finns i Konfigurera en anslutning.
Speglingsarkitektur
Den här arkitekturen har två kluster i olika resursgrupper och virtuella nätverk: en primär och en sekundär.
Steg för att skapa
Skapa två nya resursgrupper:
Resursgrupp Plats kafka-primary-rg Central US kafka-secondary-rg USA, norra centrala Skapa ett nytt virtuellt nätverk kafka-primary-vnet i kafka-primary-rg. Lämna standardinställningarna.
Skapa ett nytt virtuellt nätverk kafka-secondary-vnet i kafka-secondary-rg, även med standardinställningar.
Skapa två nya Kafka-kluster:
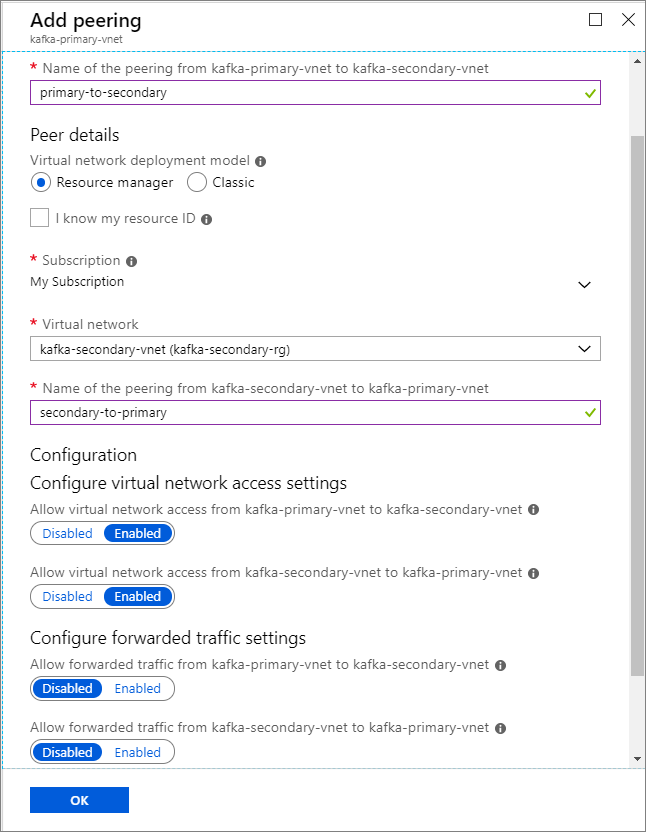
Klusternamn Resursgrupp Virtuellt nätverk Lagringskonto kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Skapa peering för virtuella nätverk. Det här steget skapar två peerings: en från kafka-primary-vnet till kafka-secondary-vnet och en från kafka-secondary-vnet till kafka-primary-vnet.
Välj det virtuella nätverket kafka-primary-vnet .
Under Inställningar väljer du Peerings.
Välj Lägg till.
På skärmen Lägg till peering anger du informationen enligt följande skärmbild.
Konfigurera IP-annonsering
Konfigurera IP-annonsering så att en klient kan ansluta med hjälp av asynkrona IP-adresser i stället för domännamn.
Gå till Ambari-instrumentpanelen för det primära klustret:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Välj Tjänster>Kafka. Välj fliken Konfigurationer .
Lägg till följande konfigurationsrader i det nedre avsnittet kafka-env-mall . Välj Spara.
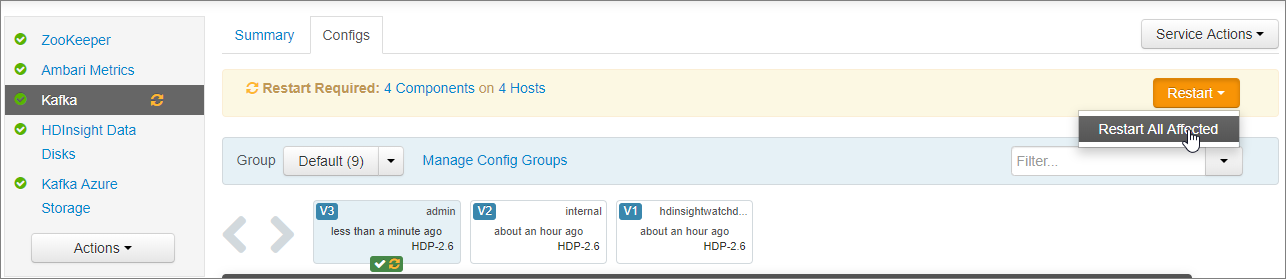
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesAnge en anteckning på skärmen Spara konfiguration och välj Spara.
Om du får en konfigurationsvarning väljer du Fortsätt ändå.
I Spara konfigurationsändringar väljer du Ok.
I meddelandet Starta om obligatoriskt väljer du Starta om Starta om>alla som påverkas. Välj sedan Bekräfta starta om alla.
Konfigurera Kafka att lyssna på alla nätverksgränssnitt
- Stanna kvar på fliken Konfigurationer under Services>Kafka. I avsnittet Kafka Broker anger du lyssnaregenskapen till
PLAINTEXT://0.0.0.0:9092. - Välj Spara.
- Välj Starta om>Bekräfta starta om alla.
Registrera Asynkrona IP-adresser och ZooKeeper-adresser för det primära klustret
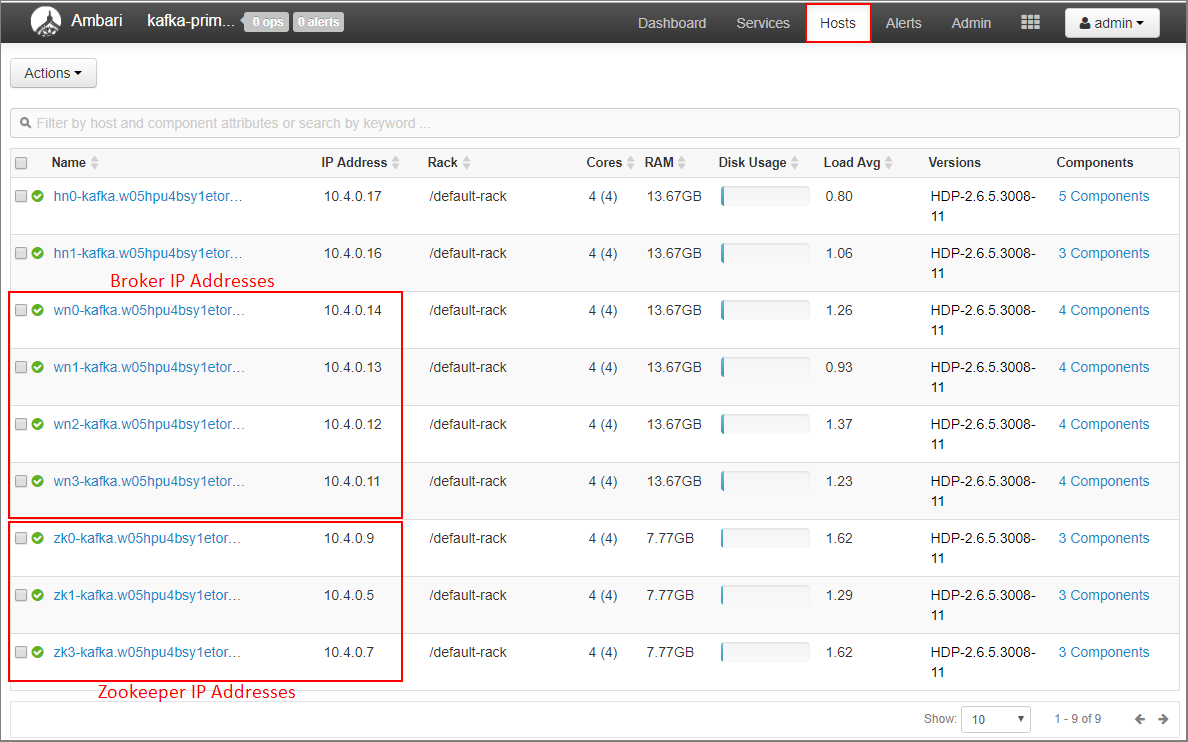
Välj Värdar på Ambari-instrumentpanelen.
Anteckna IP-adresserna för asynkrona meddelandeköer och ZooKeepers. Asynkrona noder har angetts som de två första bokstäverna i värdnamnet och ZooKeeper-noderna har zk som de två första bokstäverna i värdnamnet.
Upprepa de föregående tre stegen för det andra klustret , kafka-secondary-cluster: konfigurera IP-annonsering, ange lyssnare och anteckna asynkrona ip-adresser och ZooKeeper-IP-adresser.
Skapa ämnen
Anslut till det primära klustret med hjälp av SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netErsätt
sshusermed det SSH-användarnamn som du använde när du skapade klustret. ErsättPRIMARYCLUSTERmed det basnamn som du använde när du skapade klustret.Mer information finns i Använda SSH med HDInsight.
Använd följande kommando för att skapa två miljövariabler med Apache ZooKeeper-värdarna och asynkrona värdar för det primära klustret. Ersätt strängar som
ZOOKEEPER_IP_ADDRESS1med de faktiska IP-adresser som registrerats tidigare, till exempel10.23.0.11och10.23.0.7. Detsamma gäller förBROKER_IP_ADDRESS1. Om du använder FQDN-matchning med en anpassad DNS-server följer du dessa steg för att hämta namnen broker och ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Om du vill skapa ett ämne med namnet
testtopicanvänder du följande kommando:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSAnvänd följande kommando för att kontrollera att ämnet har skapats:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSSvaret innehåller
testtopic.Använd följande för att visa värdinformationen för den asynkrona meddelandekön för det här (det primära) klustret:
echo $PRIMARY_BROKERHOSTSDetta returnerar information som liknar följande text:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Spara den här informationen. Den används i nästa avsnitt.
Konfigurera spegling
Anslut till det sekundära klustret med hjälp av en annan SSH-session:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netErsätt
sshusermed det SSH-användarnamn som du använde när du skapade klustret. ErsättSECONDARYCLUSTERmed det namn som du använde när du skapade klustret.Mer information finns i Använda SSH med HDInsight.
Använd en
consumer.propertiesfil för att konfigurera kommunikation med det primära klustret. Använd följande kommando för att skapa filen:nano consumer.propertiesAnvänd följande text som innehållet i
consumer.propertiesfilen:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupErsätt
PRIMARY_BROKERHOSTSmed den asynkrona värdens IP-adresser från det primära klustret.Den här filen beskriver konsumentinformationen som ska användas vid läsning från det primära Kafka-klustret. Mer information finns i Konsumentkonfigurationer på
kafka.apache.org.Spara filen genom att trycka på Ctrl+X, trycka på Y och sedan på Retur.
Innan du konfigurerar den producent som kommunicerar med det sekundära klustret konfigurerar du en variabel för den asynkrona IP-adressen för det sekundära klustret. Använd följande kommandon för att skapa den här variabeln:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Kommandot
echo $SECONDARY_BROKERHOSTSbör returnera information som liknar följande text:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Använd en
producer.propertiesfil för att kommunicera det sekundära klustret. Använd följande kommando för att skapa filen:nano producer.propertiesAnvänd följande text som innehållet i
producer.propertiesfilen:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneErsätt
SECONDARY_BROKERHOSTSmed de asynkrona IP-adresserna som användes i föregående steg.Mer information finns i Producentkonfigurationer på
kafka.apache.org.Använd följande kommandon för att skapa en miljövariabel med IP-adresserna för ZooKeeper-värdarna för det sekundära klustret:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Standardkonfigurationen för Kafka i HDInsight tillåter inte automatiskt skapande av ämnen. Du måste använda något av följande alternativ innan du startar speglingsprocessen:
Skapa ämnena i det sekundära klustret: Med det här alternativet kan du också ange antalet partitioner och replikeringsfaktorn.
Du kan skapa ämnen i förväg med hjälp av följande kommando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSErsätt
testtopicmed namnet på det ämne som ska skapas.Konfigurera klustret för automatisk skapande av ämnen: Med det här alternativet kan MirrorMaker skapa ämnen automatiskt. Observera att det kan skapa dem med ett annat antal partitioner eller en annan replikeringsfaktor än det primära ämnet.
Utför följande steg för att konfigurera det sekundära klustret för att automatiskt skapa ämnen:
- Gå till Ambari-instrumentpanelen för det sekundära klustret:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Välj Tjänster>Kafka. Välj sedan fliken Konfigurationer .
- I fältet Filter anger du värdet
auto.create. Detta filtrerar listan över egenskaper och visarauto.create.topics.enableinställningen. - Ändra värdet
auto.create.topics.enableför tilltrueoch välj sedan Spara. Lägg till en anteckning och välj sedan Spara igen. - Välj Kafka-tjänsten , välj Starta om och välj sedan Starta om alla som påverkas. När du uppmanas väljer du Bekräfta omstart av alla.
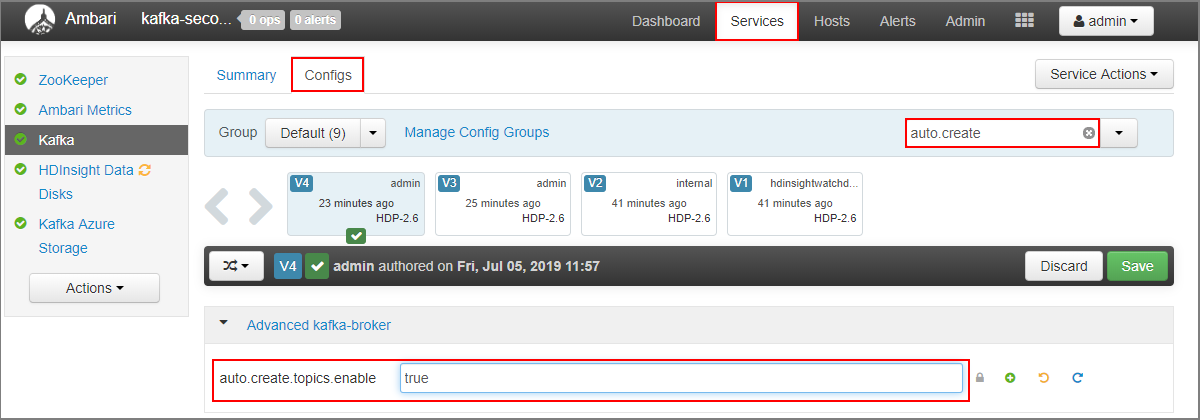
- Gå till Ambari-instrumentpanelen för det sekundära klustret:
Starta MirrorMaker
Anteckning
Den här artikeln innehåller referenser till en term som Microsoft inte längre använder. När termen tas bort från programvaran tar vi bort den från den här artikeln.
Från SSH-anslutningen till det sekundära klustret använder du följande kommando för att starta MirrorMaker-processen:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4De parametrar som används i det här exemplet är:
Parameter Beskrivning --consumer.configAnger filen som innehåller konsumentegenskaper. Du använder dessa egenskaper för att skapa en konsument som läser från det primära Kafka-klustret. --producer.configAnger filen som innehåller producentegenskaper. Du använder dessa egenskaper för att skapa en producent som skriver till det sekundära Kafka-klustret. --whitelistEn lista med ämnen som MirrorMaker replikerar från det primära klustret till det sekundära. --num.streamsAntalet konsumenttrådar som ska skapas. Konsumenten på den sekundära noden väntar nu på att få meddelanden.
Från SSH-anslutningen till det primära klustret använder du följande kommando för att starta en producent och skicka meddelanden till ämnet:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicNär du kommer till en tom rad med en markör skriver du in några textmeddelanden. Meddelandena skickas till ämnet i det primära klustret. När du är klar trycker du på Ctrl+C för att avsluta producentprocessen.
Från SSH-anslutningen till det sekundära klustret trycker du på Ctrl+C för att avsluta MirrorMaker-processen. Det kan ta flera sekunder att avsluta processen. Kontrollera att meddelandena har replikerats till den sekundära genom att använda följande kommando:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningListan över ämnen innehåller
testtopicnu , som skapas när MirrorMaster speglar ämnet från det primära klustret till det sekundära. Meddelandena som hämtas från ämnet är desamma som de som du angav i det primära klustret.
Ta bort klustret
Varning
Faktureringen för HDInsight-kluster beräknas proportionellt per minut, oavsett om du använder dem eller inte. Se till att ta bort klustret när du har använt det. Se hur du tar bort ett HDInsight-kluster.
Stegen i den här artikeln skapade kluster i olika Azure-resursgrupper. Om du vill ta bort alla resurser som skapats kan du ta bort de två resursgrupper som skapats: kafka-primary-rg och kafka-secondary-rg. När du tar bort resursgrupperna tas alla resurser som skapas bort genom att följa den här artikeln, inklusive kluster, virtuella nätverk och lagringskonton.
Nästa steg
I den här artikeln har du lärt dig hur du använder MirrorMaker för att skapa en replik av ett Apache Kafka-kluster . Använd följande länkar för att identifiera andra sätt att arbeta med Kafka:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för