Analysera webbplatsloggar med ett anpassat Python-bibliotek med Apache Spark-kluster i HDInsight
Den här notebook-filen visar hur du analyserar loggdata med hjälp av ett anpassat bibliotek med Apache Spark i HDInsight. Det anpassade biblioteket som vi använder är ett Python-bibliotek som heter iislogparser.py.
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
Spara rådata som en RDD
I det här avsnittet använder vi Jupyter Notebook som är associerat med ett Apache Spark-kluster i HDInsight för att köra jobb som bearbetar dina rådata och sparar dem som en Hive-tabell. Exempeldata är en .csv fil (hvac.csv) som är tillgänglig i alla kluster som standard.
När dina data har sparats som en Apache Hive-tabell ansluter vi i nästa avsnitt till Hive-tabellen med hjälp av BI-verktyg som Power BI och Tableau.
Från en webbläsare går du till
https://CLUSTERNAME.azurehdinsight.net/jupyter, därCLUSTERNAMEär namnet på klustret.Skapa en ny anteckningsbok. Välj Ny och sedan PySpark.
 Notebook"-kantlinje="true":::
Notebook"-kantlinje="true":::En ny anteckningsbok skapas och öppnas med namnet Untitled.pynb. Välj anteckningsbokens namn överst och ange ett eget namn.
Eftersom du har skapat en notebook-fil med PySpark-kerneln behöver du inte skapa några kontexter explicit. Spark- och Hive-kontexterna skapas automatiskt för dig när du kör den första kodcellen. Du kan börja med att importera de typer som krävs för det här scenariot. Klistra in följande kodfragment i en tom cell och tryck sedan på Skift + Retur.
from pyspark.sql import Row from pyspark.sql.types import *Skapa en RDD med hjälp av de exempelloggdata som redan är tillgängliga i klustret. Du kan komma åt data i standardlagringskontot som är associerat med klustret på
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Kör följande kod:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Hämta en exempellogguppsättning för att kontrollera att föregående steg har slutförts.
logs.take(5)Du bör se utdata som liknar följande text:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analysera loggdata med ett anpassat Python-bibliotek
I utdata ovan innehåller de första raderna rubrikinformationen och varje återstående rad matchar schemat som beskrivs i rubriken. Det kan vara komplicerat att parsa sådana loggar. Därför använder vi ett anpassat Python-bibliotek (iislogparser.py) som gör det mycket enklare att parsa sådana loggar. Som standard ingår det här biblioteket i Spark-klustret i HDInsight på
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Det här biblioteket finns dock inte i
PYTHONPATHså vi kan inte använda det med hjälp av en import-instruktion somimport iislogparser. Om du vill använda det här biblioteket måste vi distribuera det till alla arbetsnoder. Kör följande kodfragment.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparsertillhandahåller en funktionparse_log_linesom returnerarNoneom en loggrad är en rubrikrad och returnerar en instans avLogLineklassen om den påträffar en loggrad.LogLineAnvänd klassen för att extrahera endast loggraderna från RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Hämta ett par extraherade loggrader för att kontrollera att steget har slutförts.
logLines.take(2)Utdata bör likna följande text:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]Klassen
LogLinehar i sin tur några användbara metoder, till exempelis_error(), som returnerar om en loggpost har en felkod. Använd den här klassen för att beräkna antalet fel i de extraherade loggraderna och logga sedan alla fel till en annan fil.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')Utdata ska ange
There are 30 errors and 646 log entries.Du kan också använda Matplotlib för att konstruera en visualisering av data. Om du till exempel vill isolera orsaken till begäranden som körs under lång tid kanske du vill hitta de filer som tar mest tid att hantera i genomsnitt. Kodfragmentet nedan hämtar de 25 främsta resurserna som tog mest tid att hantera en begäran.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Du bör se utdata som följande text:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Du kan också visa den här informationen i form av ett diagram. Som ett första steg för att skapa ett diagram kan vi först skapa en tillfällig tabell AverageTime. Tabellen grupperar loggarna efter tid för att se om det fanns några ovanliga svarstidstoppar vid en viss tidpunkt.
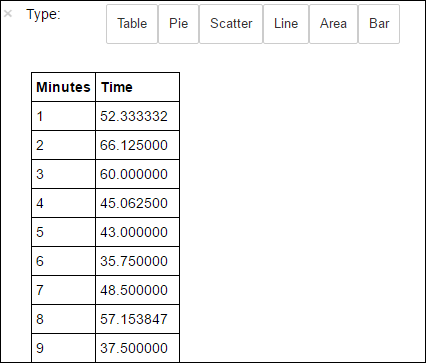
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Du kan sedan köra följande SQL-fråga för att hämta alla poster i tabellen AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeMagin
%%sqlföljt av-o averagetimesäkerställer att frågans utdata sparas lokalt på Jupyter-servern (vanligtvis huvudnoden i klustret). Utdata sparas som en Pandas-dataram med det angivna namnet averagetime.Du bör se utdata som följande bild:
 yter sql query output" border="true":::
yter sql query output" border="true":::Mer information om magin finns i
%%sqlParametrar som stöds med %%sql-magin.Nu kan du använda Matplotlib, ett bibliotek som används för att konstruera visualisering av data, för att skapa ett diagram. Eftersom diagrammet måste skapas från den lokalt bevarade genomsnittsdataramen måste kodfragmentet börja med magin
%%local. Detta säkerställer att koden körs lokalt på Jupyter-servern.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Du bör se utdata som följande bild:
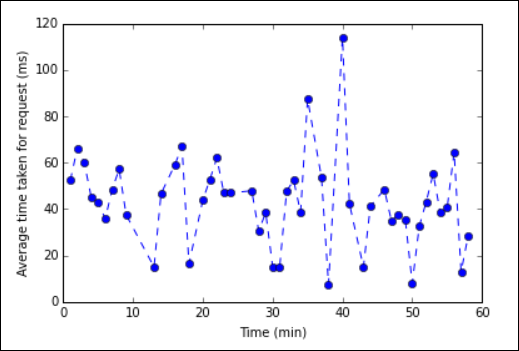 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::När du har kört programmet bör du stänga av anteckningsboken för att frigöra resurserna. Du gör det genom att välja Stäng och stoppa i anteckningsbokens Fil-meny. Den här åtgärden stängs av och anteckningsboken stängs.
Nästa steg
Utforska följande artiklar:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för