Konfigurera redundansgrupp – CLI
Den här artikeln beskriver hur du konfigurerar haveriberedskap för SQL Managed Instance som aktiveras av Azure Arc med CLI. Innan du fortsätter bör du granska informationen och förutsättningarna i SQL Managed Instance som aktiveras av Azure Arc – haveriberedskap.
Förutsättningar
Följande krav måste uppfyllas innan du konfigurerar redundansgrupper mellan två instanser av SQL Managed Instance som aktiveras av Azure Arc:
- En Azure Arc-datakontrollant och en Arc-aktiverad SQL-hanterad instans som etablerats på den primära platsen med
--license-typesom en avBasePriceellerLicenseIncluded. - En Azure Arc-datakontrollant och en Arc-aktiverad SQL-hanterad instans som etablerats på den sekundära platsen med identisk konfiguration som primär när det gäller:
- Processor
- Minne
- Storage
- Tjänstenivå
- Sortering
- Andra instansinställningar
- Instansen på den sekundära platsen kräver
--license-typesomDisasterRecovery. Den här instansen måste vara ny, utan några användarobjekt.
Kommentar
- Det är viktigt att ange
--license-typenär den hanterade instansen skapas. Detta gör att DR-instansen kan seedas från den primära instansen i det primära datacentret. Att uppdatera den här egenskapen efter distributionen har inte samma effekt.
Distributionsprocess
Utför följande steg för att konfigurera en Azure-redundansgrupp mellan två instanser:
- Skapa en anpassad resurs för distribuerad tillgänglighetsgrupp på den primära platsen
- Skapa en anpassad resurs för distribuerad tillgänglighetsgrupp på den sekundära platsen
- Kopiera binära data från speglingscertifikaten
- Konfigurera den distribuerade tillgänglighetsgruppen mellan de primära och sekundära platserna i läge
syncellerasyncläge
Följande bild visar en korrekt konfigurerad distribuerad tillgänglighetsgrupp:
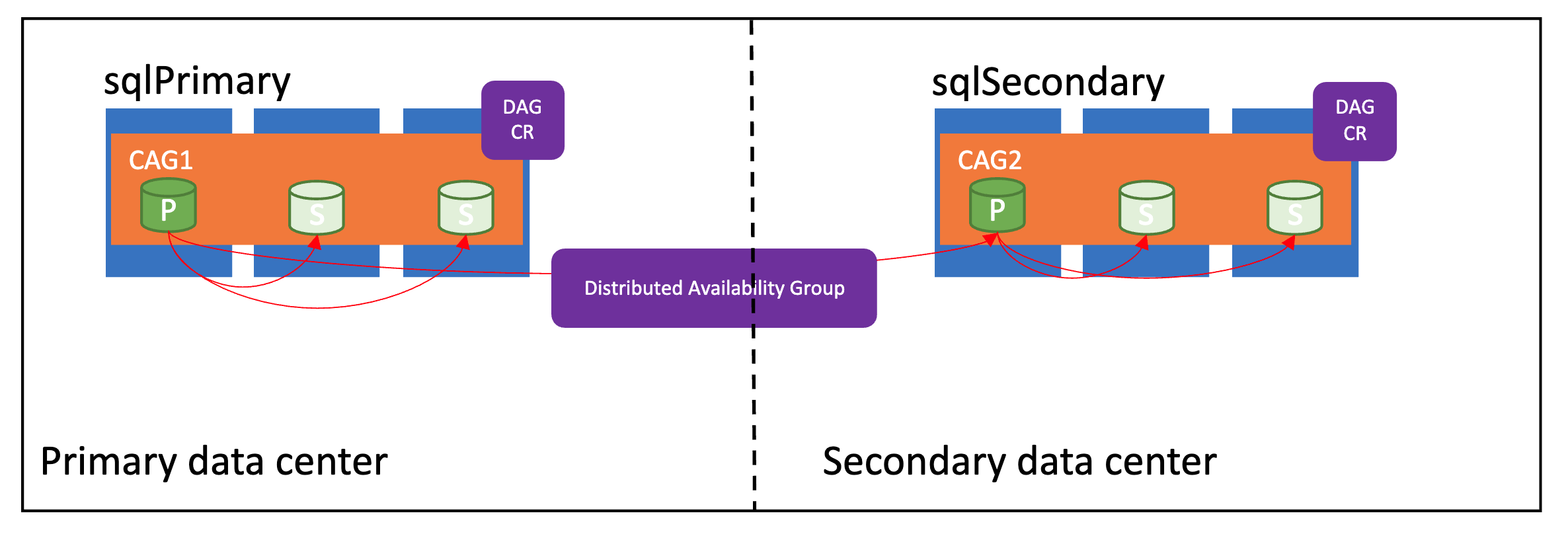
Synkroniseringslägen
Redundansgrupper i Azure Arc-datatjänster stöder två synkroniseringslägen – sync och async. Synkroniseringsläget påverkar direkt hur data synkroniseras mellan instanserna och potentiellt prestanda på den primära hanterade instansen.
Om primära och sekundära platser ligger inom några kilometer från varandra använder du sync läget. Annars kan du använda async läget för att undvika prestandapåverkan på den primära platsen.
Konfigurera Azure-redundansgrupp – direktläge
Följ stegen nedan om Azure Arc-datatjänsterna distribueras i directly anslutet läge.
När förutsättningarna är uppfyllda kör du kommandot nedan för att konfigurera En Azure-redundansgrupp mellan de två instanserna:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Exempel:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
Kommandot ovan:
- Skapar nödvändiga anpassade resurser på både primära och sekundära platser
- Kopierar speglingscertifikaten och konfigurerar redundansgruppen mellan instanserna
Konfigurera Azure-redundansgrupp – indirekt läge
Följ stegen nedan om Azure Arc-datatjänster distribueras i indirectly anslutet läge.
Etablera den hanterade instansen på den primära platsen.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sVäxla kontext till det sekundära klustret genom att köra
kubectl config use-context <secondarycluster>och etablera den hanterade instansen på den sekundära platsen som ska vara haveriberedskapsinstansen. I det här läget är systemdatabaserna inte en del av den inneslutna tillgänglighetsgruppen.Kommentar
Det är viktigt att ange
--license-type DisasterRecoveryunder den hanterade instansen. Detta gör att DR-instansen kan seedas från den primära instansen i det primära datacentret. Att uppdatera den här egenskapen efter distributionen har inte samma effekt.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sSpeglingscertifikat – Binära data i egenskapen Speglingscertifikat för den hanterade instansen behövs för att skapa CR för instansredundansgrupper (anpassad resurs).
Detta kan uppnås på några sätt:
(a) Om du använder
azCLI genererar du speglingscertifikatfilen först och pekar sedan på filen när du konfigurerar instansens redundansgrupp så att binära data läse från filen och kopieras över till CR. Certifikatfilerna behövs inte när redundansgruppen har skapats.(b) Om du använder
kubectlkopierar och klistrar du in binära data direkt från den hanterade instansens CR i yaml-filen som ska användas för att skapa redundansgruppen för instanser.Använda (a) ovan:
Skapa speglingscertifikatfilen för den primära instansen:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExempel:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sAnslut till det sekundära klustret och skapa speglingscertifikatfilen för den sekundära instansen:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExempel:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sNär speglingscertifikatfilerna har skapats kopierar du certifikatet från den sekundära instansen till en delad/lokal sökväg i det primära instansklustret och vice versa.
Skapa resursen för redundansgrupper på båda platserna.
Kommentar
Kontrollera att SQL-instanserna har olika namn för både primära och sekundära platser och
shared-nameatt värdet ska vara identiskt på båda platserna.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sExempel:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sPå den sekundära instansen kör du följande kommando för att konfigurera den anpassade resursen för redundansgruppen. I
--partner-mirroring-cert-filedet här fallet ska peka på en sökväg som har speglingscertifikatfilen genererad från den primära instansen enligt beskrivningen i 3(a) ovan.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sExempel:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Hämta hälsotillstånd för Azure-redundansgrupper
Information om redundansgruppen, till exempel primär roll, sekundär roll och aktuell hälsostatus, kan visas på den anpassade resursen på antingen den primära eller sekundära platsen.
Kör kommandot nedan på den primära och/eller den sekundära platsen för att visa en lista över den anpassade resursen för redundansgrupper:
kubectl get fog -n <namespace>
Beskriv den anpassade resursen för att hämta status för redundansgrupper enligt följande:
kubectl describe fog <failover group cr name> -n <namespace>
Åtgärder för redundansgrupp
När redundansgruppen har konfigurerats mellan de hanterade instanserna kan olika redundansåtgärder utföras beroende på omständigheterna.
Möjliga redundansscenarier är:
Instanserna på båda platserna är i felfritt tillstånd och en redundansväxling måste utföras:
- utföra en manuell redundansväxling från primär till sekundär utan dataförlust genom att ange
role=secondaryden primära SQL MI.
- utföra en manuell redundansväxling från primär till sekundär utan dataförlust genom att ange
Den primära platsen är inte felfri/kan inte nås och en redundansväxling måste utföras:
- den primära SQL-hanterade instansen som aktiveras av Azure Arc är inte felfri/kan inte nås
- den sekundära SQL Managed Instance som aktiveras av Azure Arc måste framflyttas till primär med potentiell dataförlust
- När den ursprungliga primära SQL Managed Instance som aktiveras av Azure Arc är online igen rapporteras den som
Primaryroll och feltillstånd och måste tvingas till ensecondaryroll så att den kan ansluta till redundansgruppen och data kan synkroniseras.
Manuell redundans (utan dataförlust)
Använd az sql instance-failover-group-arc update ... kommandogruppen för att initiera en redundansväxling från primär till sekundär. Väntande transaktioner på den geo-primära instansen replikeras över till den geo-sekundära instansen före redundansväxlingen.
Direktanslutet läge
Kör följande kommando för att initiera en manuell redundansväxling i direct anslutet läge med arm-API:er:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Exempel:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Indirekt anslutet läge
Kör följande kommando för att initiera en manuell redundansväxling i indirect anslutet läge med kubernetes-API:er:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Exempel:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Tvingad redundansväxling med dataförlust
I de fall då den geo-primära instansen blir otillgänglig kan följande kommandon köras på den geo-sekundära DR-instansen för att befordra till primär med en tvingad redundansväxling som medför potentiell dataförlust.
På den geo-sekundära DR-instansen kör du följande kommando för att befordra den till primär roll, med dataförlust.
Kommentar
Om har --partner-sync-mode konfigurerats som syncmåste den återställas till async när den sekundära har befordrats till primär.
Direktanslutet läge
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Exempel:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Indirekt anslutet läge
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
När den geo-primära instansen blir tillgänglig kör du kommandot nedan för att föra in den i redundansgruppen och synkronisera data:
Direktanslutet läge
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Indirekt anslutet läge
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
--partner-sync-mode Du kan också konfigurera tillbaka till sync läget om du vill.
Åtgärder efter redundansväxling
När du utför en redundansväxling från den primära platsen till den sekundära platsen, antingen med eller utan dataförlust, kan du behöva göra följande:
- Uppdatera niska veze för dina program för att ansluta till den nyligen upphöjda primära Arc SQL-hanterade instansen
- Om du planerar att fortsätta köra produktionsarbetsbelastningen utanför den sekundära platsen uppdaterar
--license-typedu till antingenBasePriceellerLicenseIncludedinitierar faktureringen för de virtuella kärnor som förbrukas.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för