Konfigurera logginsamling i Container Insights
Den här artikeln innehåller information om hur du konfigurerar datainsamling i Container Insights för ditt Kubernetes-kluster när det har registrerats. Vägledning om hur du aktiverar containerinsikter i klustret finns i Aktivera övervakning för Kubernetes-kluster.
Konfigurationsmetoder
Det finns två metoder som används för att konfigurera och filtrera data som samlas in i Container Insights. Beroende på inställningen kan du välja mellan de två metoderna eller så kan du behöva använda den ena eller den andra. De två metoderna beskrivs i tabellen nedan med detaljerad information i följande avsnitt.
| Metod | beskrivning |
|---|---|
| Datainsamlingsregel (DCR) | Regler för datainsamling är uppsättningar med instruktioner som stöder datainsamling med hjälp av Azure Monitor-pipelinen. En DCR skapas när du aktiverar containerinsikter och du kan ändra inställningarna i den här domänkontrollanten med hjälp av Azure Portal eller andra metoder. |
| ConfigMap | ConfigMaps är en Kubernetes-mekanism som gör att du kan lagra icke-konfidentiella data, till exempel en konfigurationsfil eller miljövariabler. Container insights söker efter en ConfigMap för varje kluster med särskilda inställningar som definierar data som ska samlas in. |
Konfigurera datainsamling med DCR
DCR som skapats av Container Insights heter MSCI-cluster-region-cluster-name><><. Du kan visa den här domänkontrollanten tillsammans med andra i din prenumeration och du kan redigera den med hjälp av metoder som beskrivs i Skapa och redigera regler för datainsamling (DCR) i Azure Monitor. Du kan ändra domänkontrollanten direkt för vissa anpassningar, men du kan utföra de flesta nödvändiga konfigurationerna med hjälp av de metoder som beskrivs nedan. Mer information om hur du redigerar DCR direkt finns i Datatransformeringar i Container Insights .
Viktigt!
AKS-kluster måste använda antingen en systemtilldelad eller användartilldelad hanterad identitet. Om klustret använder ett huvudnamn för tjänsten måste du uppdatera klustret så att det använder en systemtilldelad hanterad identitet eller en användartilldelad hanterad identitet.
Konfigurera DCR med Azure Portal
Med hjälp av Azure Portal kan du välja mellan flera förinställda konfigurationer för datainsamling i Container Insights. Dessa konfigurationer omfattar olika uppsättningar med tabeller och insamlingsfrekvenser beroende på dina särskilda prioriteringar. Du kan också anpassa inställningarna för att endast samla in de data du behöver. Du kan använda Azure Portal för att anpassa konfigurationen i ditt befintliga kluster när containerinsikter har aktiverats, eller så kan du utföra den här konfigurationen när du aktiverar Container insights i klustret.
Välj klustret i Azure Portal.
Välj alternativet Insikter i avsnittet Övervakning på menyn.
Om Container Insights redan har aktiverats i klustret väljer du knappen Övervakningsinställningar . Om inte väljer du Konfigurera Azure Monitor och läser Aktivera övervakning på ditt Kubernetes-kluster med Azure Monitor för mer information om hur du aktiverar övervakning.
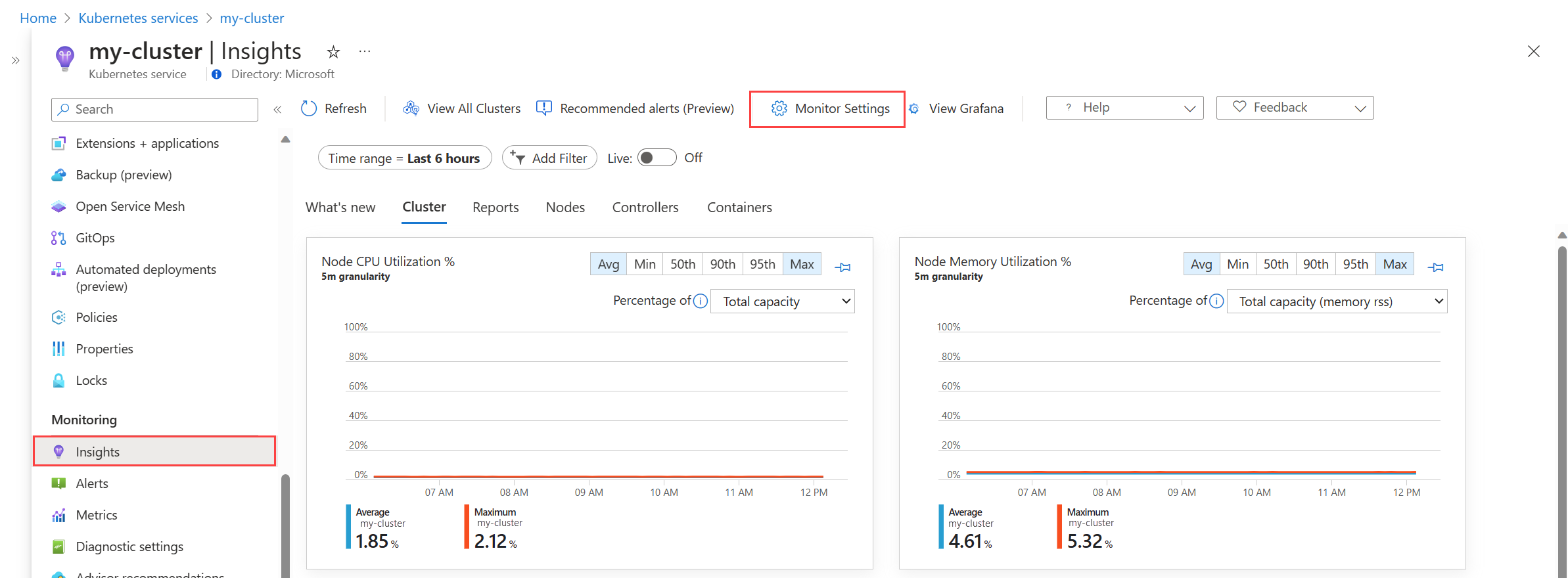
För AKS och Arc-aktiverade Kubernetes väljer du Använd hanterad identitet om du ännu inte har migrerat klustret till hanterad identitetsautentisering.
Välj en av kostnadsförinställningarna.
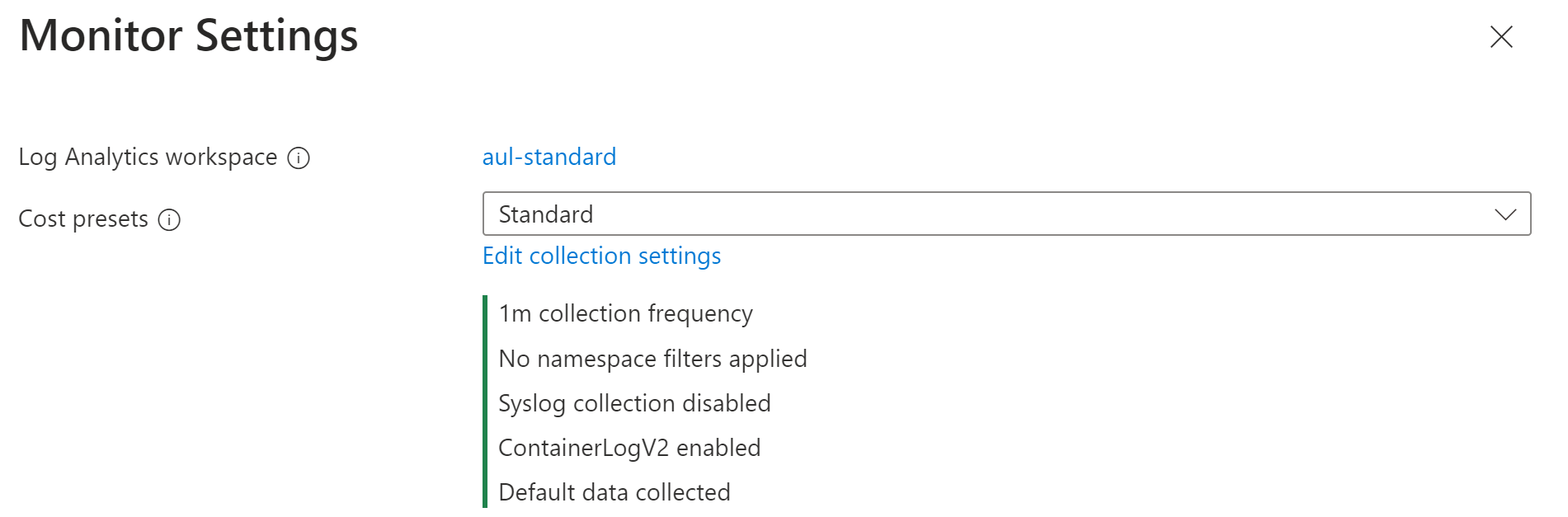
Förinställd kostnad Insamlingsfrekvens Namnområdesfilter Syslog-samling Insamlade data Standard 1 m Ingen Inte aktiverad Alla standardtabeller för containerinsikter Kostnadsoptimerad 5 m Exkluderar kube-system, gatekeeper-system, azure-arc Inte aktiverad Alla standardtabeller för containerinsikter Syslog 1 m Ingen Aktiverad som standard Alla standardtabeller för containerinsikter Loggar och händelser 1 m Ingen Inte aktiverad ContainerLog/ContainerLogV2
KubeEvents
KubePodInventoryOm du vill anpassa inställningarna klickar du på Redigera samlingsinställningar.
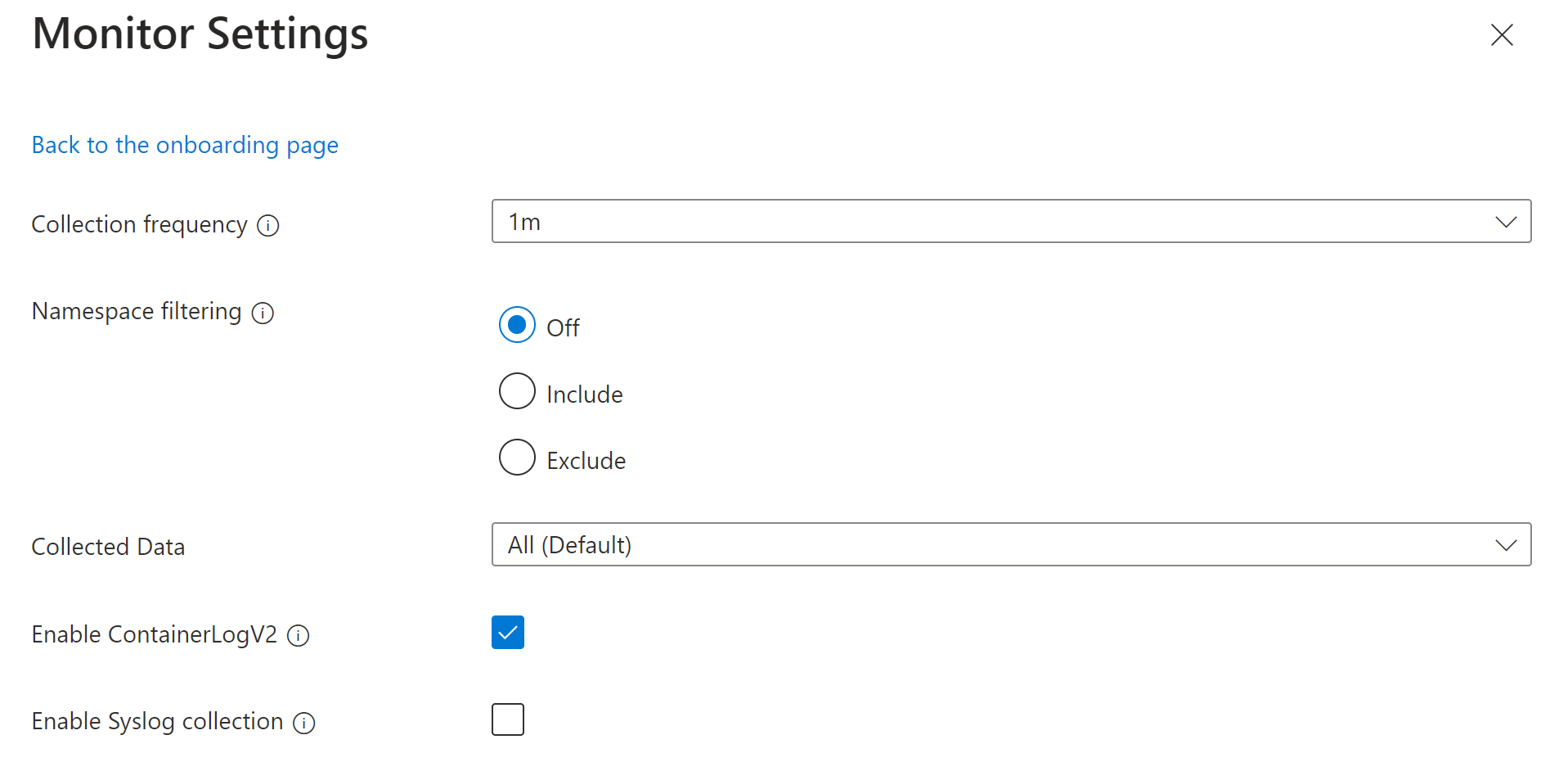
Name beskrivning Insamlingsfrekvens Avgör hur ofta agenten samlar in data. Giltiga värden är 1–30 m i 1m intervall Standardvärdet är 1 m. Namnområdesfiltrering Av: Samlar in data på alla namnområden.
Inkludera: Samlar endast in data från värdena i fältet namnområden .
Exkludera: Samlar in data från alla namnområden förutom värdena i fältet namnområden .
Matris med kommaavgränsade Kubernetes-namnområden för att samla in inventerings- och perf-data baserat på namnområdetFilteringMode. Till exempel samlar namnrymder = ["kube-system", "default"] med inställningen Inkludera endast dessa två namnområden. Med inställningen Exkludera samlar agenten in data från alla andra namnområden förutom kube-system och standard.Insamlade data Definierar vilka Container insights-tabeller som ska samlas in. Se nedan för en beskrivning av varje gruppering. Aktivera ContainerLogV2 Boolesk flagga för att aktivera ContainerLogV2-schema. Om värdet är true matas stdout-/stderr-loggarna in i tabellen ContainerLogV2 . Annars matas containerloggarna in i tabellen ContainerLog , om inget annat anges i ConfigMap. När du anger enskilda strömmar måste du inkludera motsvarande tabell för ContainerLog eller ContainerLogV2. Aktivera Syslog-samling Aktiverar Syslog-samling från klustret. Med alternativet Insamlade data kan du välja de tabeller som är ifyllda för klustret. Tabellerna grupperas efter de vanligaste scenarierna. Om du vill ange enskilda tabeller måste du ändra domänkontrollanten med hjälp av en annan metod.
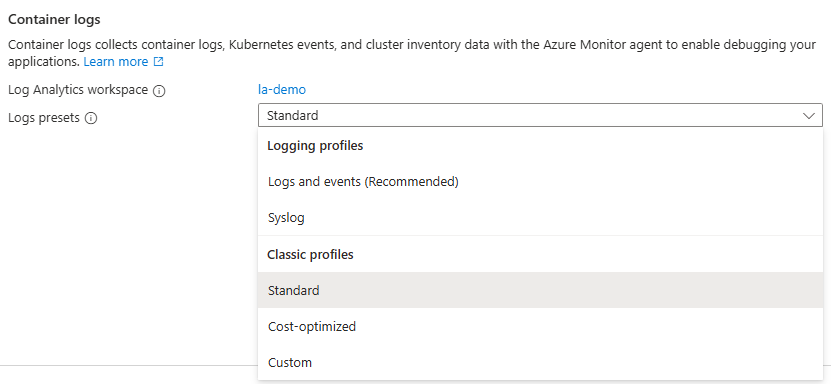
Gruppering Tabeller Kommentar Alla (standard) Alla standardtabeller för containerinsikter Krävs för att aktivera standardvisualiseringar för Container Insights Prestanda Perf, InsightsMetrics Loggar och händelser ContainerLog eller ContainerLogV2, KubeEvents, KubePodInventory Rekommenderas om du har aktiverat hanterade Prometheus-mått Arbetsbelastningar, distributioner och HPA:er InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices Beständiga volymer InsightsMetrics, KubePVInventory Spara inställningarna genom att klicka på Konfigurera .




Tillämpliga tabeller och mått för DCR
Inställningarna för insamlingsfrekvens och namnområdesfiltrering i DCR gäller inte för alla Container Insights-data. Följande tabeller visar tabellerna i Log Analytics-arbetsytan som används av Container Insights och de mått som samlas in tillsammans med de inställningar som gäller för var och en.
| Tabellnamn | Intervall? | Namnområden? | Kommentarer |
|---|---|---|---|
| ContainerInventory | Ja | Ja | |
| ContainerNodeInventory | Ja | Nej | Datainsamlingsinställningen för namnområden är inte tillämplig eftersom Kubernetes Node inte är en resurs med namnområdesomfång |
| KubeNodeInventory | Ja | Nej | Datainsamlingsinställningen för namnområden är inte tillämplig Kubernetes Node är inte en resurs med namnområdesomfång |
| KubePodInventory | Ja | Ja | |
| KubePVInventory | Ja | Ja | |
| KubeServices | Ja | Ja | |
| KubeEvents | Nej | Ja | Datainsamlingsinställning för intervall gäller inte för Kubernetes-händelser |
| Perf | Ja | Ja | Datainsamlingsinställningen för namnområden gäller inte för Kubernetes Node-relaterade mått eftersom Kubernetes-noden inte är ett namnområdesomfångsobjekt. |
| InsightsMetrics | Ja | Ja | Datainsamlingsinställningar gäller endast för mått som samlar in följande namnområden: container.azm.ms/kubestate, container.azm.ms/pv och container.azm.ms/gpu |
| Namnområde för mått | Intervall? | Namnområden? | Kommentarer |
|---|---|---|---|
| Insights.container/nodes | Ja | Nej | Noden är inte en resurs med namnområdesomfång |
| Insights.container/poddar | Ja | Ja | |
| Insights.container/containers | Ja | Ja | |
| Insights.container/persistentvolumes | Ja | Ja |
Strömma värden i DCR
När du anger vilka tabeller som ska samlas in med HJÄLP av CLI eller ARM anger du ett dataströmnamn som motsvarar en viss tabell på Log Analytics-arbetsytan. I följande tabell visas dataströmnamnet för varje tabell.
Kommentar
Om du är bekant med strukturen för en datainsamlingsregel anges dataströmnamnen i den här tabellen i avsnittet dataflöden i DCR.
| Stream | Container insights-tabell |
|---|---|
| Microsoft-ContainerInventory | ContainerInventory |
| Microsoft-ContainerLog | ContainerLog |
| Microsoft-ContainerLogV2 | ContainerLogV2 |
| Microsoft-ContainerLogV2-HighScale | ContainerLogV2 (högskalat läge)1 |
| Microsoft-ContainerNodeInventory | ContainerNodeInventory |
| Microsoft-InsightsMetrics | InsightsMetrics |
| Microsoft-KubeEvents | KubeEvents |
| Microsoft-KubeMonAgentEvents | KubeMonAgentEvents |
| Microsoft-KubeNodeInventory | KubeNodeInventory |
| Microsoft-KubePodInventory | KubePodInventory |
| Microsoft-KubePVInventory | KubePVInventory |
| Microsoft-KubeServices | KubeServices |
| Microsoft-Perf | Perf |
1 Du bör inte använda både Microsoft-ContainerLogV2 och Microsoft-ContainerLogV2-HighScale i samma DCR. Detta resulterar i dubbletter av data.
Dela DCR med flera kluster
När du aktiverar Container Insights i ett Kubernetes-kluster skapas en ny DCR för klustret och DCR för varje kluster kan ändras oberoende av varandra. Om du har flera kluster med anpassade övervakningskonfigurationer kanske du vill dela en enda DCR med flera kluster. Du kan sedan göra ändringar i en enda domänkontrollant som implementeras automatiskt för alla kluster som är associerade med den.
En DCR är associerad med ett kluster med en datainsamlingsregel associerar (DCRA). Använd DCR-förhandsversionen för att visa och ta bort befintliga DCR-associationer för varje kluster. Du kan sedan använda den här funktionen för att lägga till en association till en enda DCR för flera kluster.
Konfigurera datainsamling med hjälp av ConfigMap
ConfigMaps är en Kubernetes-mekanism som gör att du kan lagra icke-konfidentiella data, till exempel en konfigurationsfil eller miljövariabler. Container insights söker efter en ConfigMap för varje kluster med särskilda inställningar som definierar data som ska samlas in.
Viktigt!
ConfigMap är en global lista och det kan bara finnas en ConfigMap som tillämpas på agenten för Container Insights. Om du tillämpar en annan ConfigMap överskrids de tidigare inställningarna för ConfigMap-samlingen.
Förutsättningar
- Den lägsta agentversion som stöds för att samla in stdout-, stderr- och miljövariabler från containerarbetsbelastningar är ciprod06142019 eller senare.
Konfigurera och distribuera ConfigMap
Använd följande procedur för att konfigurera och distribuera konfigurationsfilen ConfigMap till klustret:
Om du inte redan har en ConfigMap för containerinsikter laddar du ned mallen ConfigMap YAML-filen och öppnar den i ett redigeringsprogram.
Redigera YAML-filen ConfigMap med dina anpassningar. Mallen innehåller alla giltiga inställningar med beskrivningar. Om du vill aktivera en inställning tar du bort kommentarstecknet (#) och anger dess värde.
Skapa en ConfigMap genom att köra följande kubectl-kommando:
kubectl config set-context <cluster-name> kubectl apply -f <configmap_yaml_file.yaml> # Example: kubectl config set-context my-cluster kubectl apply -f container-azm-ms-agentconfig.yamlKonfigurationsändringen kan ta några minuter innan den börjar gälla. Sedan startas alla Azure Monitor Agent-poddar i klustret om. Omstarten är en löpande omstart för alla Azure Monitor Agent-poddar, så alla startas inte om samtidigt. När omstarterna är klara får du ett meddelande som liknar följande resultat:
configmap "container-azm-ms-agentconfig" created`.
Verifiera konfiguration
Om du vill kontrollera att konfigurationen har tillämpats på ett kluster använder du följande kommando för att granska loggarna från en agentpodd.
kubectl logs ama-logs-fdf58 -n kube-system -c ama-logs
Om det finns konfigurationsfel från Azure Monitor Agent-poddarna visar utdata fel som liknar följande:
***************Start Config Processing********************
config::unsupported/missing config schema version - 'v21' , using defaults
Använd följande alternativ för att utföra mer felsökning av konfigurationsändringar:
Använd samma
kubectl logskommando från en agentpodd.Granska liveloggar efter fel som liknar följande:
config::error::Exception while parsing config map for log collection/env variable settings: \nparse error on value \"$\" ($end), using defaults, please check config map for errorsData skickas till
KubeMonAgentEventstabellen på Log Analytics-arbetsytan varje timme med allvarlighetsgrad för fel vid konfigurationsfel. Om det inte finns några fel kommer posten i tabellen att ha data med allvarlighetsgradsinformation, som inte rapporterar några fel. KolumnenTagsinnehåller mer information om podden och container-ID:t där felet inträffade och även den första förekomsten, den senaste förekomsten och antalet under den senaste timmen.
Verifiera schemaversionen
Konfigurationsschemaversioner som stöds är tillgängliga som poddanteckning (schemaversioner) i Azure Monitor Agent-podden. Du kan se dem med följande kubectl-kommando.
kubectl describe pod ama-logs-fdf58 -n=kube-system.
Inställningar för ConfigMap
I följande tabell beskrivs de inställningar som du kan konfigurera för att styra datainsamling med ConfigMap.
| Inställning | Datatyp | Värde | beskrivning |
|---|---|---|---|
schema-version |
Sträng (skiftlägeskänslig) | v1 | Används av agenten när du parsar den här ConfigMap. Schemaversionen som stöds för närvarande är v1. Det går inte att ändra det här värdet och avvisas när ConfigMap utvärderas. |
config-version |
String | Gör att du kan hålla reda på den här konfigurationsfilens version i källkontrollsystemet/lagringsplatsen. Maximalt antal tillåtna tecken är 10 och alla andra tecken trunkeras. | |
| [log_collection_settings] | |||
[stdout]enabled |
Booleskt | true falskt |
Styr om stdout-containerloggsamling är aktiverad. När det är inställt på true och inga namnrymder undantas för stdout-loggsamling samlas stdout-loggar in från alla containrar över alla poddar och noder i klustret. Om det inte anges i ConfigMap är truestandardvärdet . |
[stdout]exclude_namespaces |
String | Kommaavgränsad matris | Matris med Kubernetes-namnområden för vilka stdout-loggar inte samlas in. Den här inställningen gäller endast om enabled är inställd på true. Om det inte anges i ConfigMap är standardvärdet["kube-system","gatekeeper-system"]. |
[stderr]enabled |
Booleskt | true falskt |
Styr om stderr-containerloggsamlingen är aktiverad. När det är inställt på true och inga namnområden undantas för stderr-loggsamlingen samlas stderr-loggar in från alla containrar över alla poddar och noder i klustret. Om det inte anges i ConfigMap är truestandardvärdet . |
[stderr]exclude_namespaces |
String | Kommaavgränsad matris | Matris med Kubernetes-namnområden för vilka stderr-loggar inte samlas in. Den här inställningen gäller endast om enabled är inställd på true. Om det inte anges i ConfigMap är standardvärdet["kube-system","gatekeeper-system"]. |
[env_var]enabled |
Booleskt | true falskt |
Styr miljövariabelsamlingen för alla poddar och noder i klustret. Om det inte anges i ConfigMap är truestandardvärdet . |
[enrich_container_logs]enabled |
Booleskt | true falskt |
Styr berikning av containerloggar för att fylla i Name egenskapsvärdena och Image för varje loggpost som skrivs till tabellen ContainerLog för alla containerloggar i klustret. Om det inte anges i ConfigMap är falsestandardvärdet . |
[collect_all_kube_events]enabled |
Booleskt | true falskt |
Styr om Kube-händelser av alla typer samlas in. Som standard samlas inte Kube-händelser med typen Normal in. När den här inställningen är truefiltreras inte längre normalhändelserna och alla händelser samlas in. Om det inte anges i ConfigMap är falsestandardvärdet . |
[schema]containerlog_schema_version |
Sträng (skiftlägeskänslig) | v2 v1 |
Anger logginmatningsformatet. Om v2används tabellen ContainerLogV2. Om v1används tabellen ContainerLog (den här tabellen har föråldrats). För kluster som aktiverar containerinsikter med azure CLI version 2.54.0 eller senare är v2standardinställningen . Mer information finns i Loggschema för Container Insights. |
[enable_multiline_logs]enabled |
Booleskt | true falskt |
Styr om flerradscontainerloggar är aktiverade. Mer information finns i Flerradsloggning i Container Insights . Om det inte anges i ConfigMap är falsestandardvärdet . Detta kräver att inställningen schema är v2. |
[metadata_collection]enabled |
Booleskt | true falskt |
Styr om metadata samlas in i KubernetesMetadata kolumnen i ContainerLogV2 tabellen. |
[metadata_collection]include_fields |
String | Kommaavgränsad matris | Lista över metadatafält som ska inkluderas. Om inställningen inte används samlas alla fält in. Giltiga värden är ["podLabels","podAnnotations","podUid","image","imageID","imageRepo","imageTag"] |
| [metric_collection_settings] | |||
[collect_kube_system_pv_metrics]enabled |
Booleskt | true falskt |
Tillåter att mått för beständiga volymer (PV) samlas in i kube-system-namnområdet. Som standard samlas inte användningsstatistik för beständiga volymer med beständiga volymanspråk i kube-system-namnområdet in. När den här inställningen är inställd truepå samlas PV-användningsstatistik för alla namnområden in. Om det inte anges i ConfigMap är falsestandardvärdet . |
| [agent_settings] | |||
[proxy_config]ignore_proxy_settings |
Booleskt | true falskt |
När trueignoreras proxyinställningarna. För både AKS- och Arc-aktiverade Kubernetes-miljöer, om klustret har konfigurerats med vidarebefordrad proxy, tillämpas proxyinställningarna automatiskt och används för agenten. För vissa konfigurationer, till exempel med AMPLS + Proxy, kanske du vill att proxykonfigurationen ska ignoreras. Om det inte anges i ConfigMap är falsestandardvärdet . |
Nästa steg
- Mer information om hur du sparar kostnader finns i Filtrera logginsamling i Container Insights genom att konfigurera Containerinsikter för att filtrera data som du inte behöver.