Gå socialt med Azure Cosmos DB
GÄLLER FÖR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kassandra
Kassandra ![]() Gremlin
Gremlin ![]() Bord
Bord
Att leva i ett massivt sammankopplat samhälle innebär att du någon gång i livet blir en del av ett socialt nätverk. Du använder sociala nätverk för att hålla kontakten med vänner, kollegor, familj eller ibland för att dela din passion med människor med gemensamma intressen.
Som tekniker eller utvecklare kanske du har undrat hur dessa nätverk lagrar och kopplar samman dina data. Eller så har du till och med fått i uppdrag att skapa eller skapa ett nytt socialt nätverk för en specifik nischmarknad. Det är då den viktiga frågan uppstår: Hur lagras alla dessa data?
Anta att du skapar ett nytt och glänsande socialt nätverk där användarna kan publicera artiklar med relaterade medier, till exempel bilder, videor eller till och med musik. Användare kan kommentera inlägg och ge poäng för omdömen. Det kommer att finnas ett flöde av inlägg som användarna kommer att se och interagera med på huvudwebbplatsens landningssida. Den här metoden låter inte komplex först, men för enkelhetens skull ska vi sluta där. (Du kan gå in i anpassade användarfeeds som påverkas av relationer, men det går utöver målet med den här artikeln.)
Så, hur lagrar du dessa data och var?
Du kan ha erfarenhet av SQL-databaser eller en uppfattning om relationsmodellering av data. Du kan börja rita något på följande sätt:
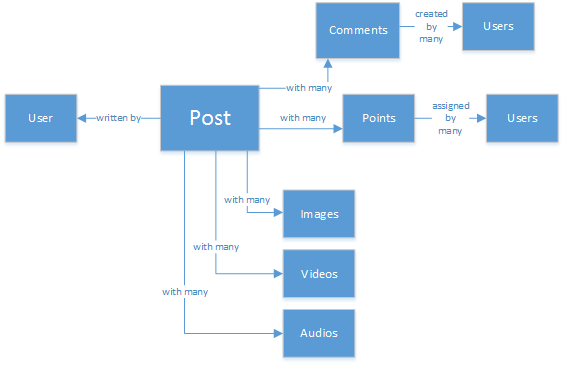
En perfekt normaliserad och vacker datastruktur... som inte skalas.
Missförstå mig inte, jag har arbetat med SQL-databaser hela mitt liv. De är bra, men som alla mönster, metoder och programvaruplattformar är det inte perfekt för varje scenario.
Varför är inte SQL det bästa valet i det här scenariot? Nu ska vi titta på strukturen för ett enda inlägg. Om jag vill visa inlägget i en webbplats eller ett program, skulle jag behöva göra en fråga med ... genom att ansluta åtta tabeller(!) bara för att visa ett enda inlägg. Föreställ dig nu en ström av inlägg som dynamiskt läses in och visas på skärmen, och du kanske ser vart jag ska.
Du kan använda en enorm SQL-instans med tillräckligt med kraft för att lösa tusentals frågor med många kopplingar för att hantera ditt innehåll. Men varför skulle du göra det när det finns en enklare lösning?
NoSQL-vägen
Den här artikeln beskriver hur du modellerar din sociala plattforms data med Azures NoSQL-databas Azure Cosmos DB kostnadseffektivt. Den visar också hur du använder andra Azure Cosmos DB-funktioner som API:et för Gremlin. Med en NoSQL-metod , lagring av data i JSON-format och tillämpning av avnormalisering kan det tidigare komplicerade inlägget omvandlas till ett enda dokument:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Och det kan hämtas med en enda fråga och utan kopplingar. Den här frågan är mycket enkel och enkel, och budgetmässigt kräver den färre resurser för att uppnå ett bättre resultat.
Azure Cosmos DB ser till att alla egenskaper indexeras med dess automatiska indexering. Den automatiska indexeringen kan till och med anpassas. Med den schemafria metoden kan vi lagra dokument med olika och dynamiska strukturer. I morgon kanske du vill att inlägg ska ha en lista över kategorier eller hashtaggar associerade med dem? Azure Cosmos DB hanterar de nya dokumenten med de tillagda attributen utan extra arbete som krävs av oss.
Kommentarer till ett inlägg kan behandlas som andra inlägg med en överordnad egenskap. (Den här metoden förenklar objektmappningen.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Och alla sociala interaktioner kan lagras på ett separat objekt som räknare:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Att skapa feeds handlar bara om att skapa dokument som kan innehålla en lista över post-ID:t med en viss relevansordning:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Du kan ha en "senaste" ström med inlägg ordnade efter skapandedatum. Eller så kan du ha en "hetaste" ström med dessa inlägg med fler likes under de senaste 24 timmarna. Du kan till och med implementera en anpassad ström för varje användare baserat på logik som följare och intressen. Det skulle fortfarande vara en lista över inlägg. Det handlar om hur du skapar dessa listor, men läsprestandan förblir obehindrat. När du har hämtat en av dessa listor utfärdar du en enda fråga till Azure Cosmos DB med nyckelordet IN för att hämta sidor med inlägg i taget.
Flödesströmmarna kan skapas med hjälp av Azure App Services bakgrundsprocesser: Webbjobb. När ett inlägg har skapats kan bakgrundsbearbetning utlösas med hjälp av Azure Storage-köer och webbjobb som utlöses med hjälp av Azure Webjobs SDK, vilket implementerar efterspridningen i strömmar baserat på din egen anpassade logik.
Punkter och gilla-markeringar över ett inlägg kan bearbetas på ett uppskjutet sätt med samma teknik för att skapa en så småningom konsekvent miljö.
Följare är svårare. Azure Cosmos DB har en gräns för dokumentstorlek och läsning/skrivning av stora dokument kan påverka programmets skalbarhet. Så du kanske tänker på att lagra följare som ett dokument med den här strukturen:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Den här strukturen kan fungera för en användare med några tusen följare. Om vissa kändisar ansluter sig till leden kommer den här metoden dock att leda till en stor dokumentstorlek, och det kan så småningom träffa dokumentets storleksgräns.
För att lösa det här problemet kan du använda en blandad metod. Som en del av dokumentet Användarstatistik kan du lagra antalet följare:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Du kan lagra det faktiska diagrammet med följare med hjälp av Azure Cosmos DB API för Gremlin för att skapa hörn för varje användare och kanter som upprätthåller "A-follows-B"-relationerna. Med API:et för Gremlin kan du hämta anhängare till en viss användare och skapa mer komplexa frågor för att föreslå personer gemensamt. Om du lägger till innehållskategorier i diagrammet som personer gillar eller gillar kan du börja väva upplevelser som inkluderar identifiering av smart innehåll, föreslå innehåll som de personer du följer, eller hitta personer som du kanske har mycket gemensamt med.
Dokumentet Användarstatistik kan fortfarande användas för att skapa kort i användargränssnittet eller snabbprofilförhandsgranskningar.
Mönstret "Stege" och dataduplicering
Som du kanske har märkt i JSON-dokumentet som refererar till ett inlägg finns det många förekomster av en användare. Och du skulle ha gissat rätt, dessa dubbletter innebär att den information som beskriver en användare, med tanke på den här avnormaliseringen, kan finnas på mer än en plats.
Om du vill tillåta snabbare frågor får du dataduplicering. Problemet med den här sidoeffekten är att om en användares data ändras genom någon åtgärd måste du hitta alla aktiviteter som användaren någonsin har gjort och uppdatera dem alla. Det låter inte praktiskt, eller hur?
Du kommer att lösa det genom att identifiera nyckelattributen för en användare som du visar i ditt program för varje aktivitet. Om du visuellt visar ett inlägg i ditt program och bara visar skaparens namn och bild, varför lagra alla användarens data i attributet "createdBy"? Om du bara visar användarens bild för varje kommentar behöver du egentligen inte resten av användarens information. Det är där något jag kallar "Ladder pattern" blir inblandat.
Låt oss ta användarinformation som exempel:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Genom att titta på den här informationen kan du snabbt identifiera vilken viktig information som inte är det, vilket skapar en "Stege":

Det minsta steget kallas userChunk, den minimala information som identifierar en användare och som används för dataduplicering. Genom att minska den duplicerade datastorleken till endast den information som du kommer att "visa" minskar du risken för massiva uppdateringar.
Mellansteget kallas användaren. Det är de fullständiga data som kommer att användas på de flesta prestandaberoende frågor i Azure Cosmos DB, den mest använda och kritiska. Den innehåller den information som representeras av en UserChunk.
Den största är den utökade användaren. Den innehåller viktig användarinformation och andra data som inte behöver läsas snabbt eller har slutlig användning, till exempel inloggningsprocessen. Dessa data kan lagras utanför Azure Cosmos DB, i Azure SQL Database eller Azure Storage Tables.
Varför skulle du dela upp användaren och till och med lagra den här informationen på olika platser? Eftersom ur prestandasynpunkt, desto större dokument, desto dyrare frågor. Håll dokumenten smala, med rätt information för att göra alla dina prestandaberoende frågor för ditt sociala nätverk. Lagra den andra extra informationen för eventuella scenarier som fullständiga profilredigeringar, inloggningar och datautvinning för användningsanalys och stordatainitiativ. Du bryr dig verkligen inte om datainsamlingen för datautvinning är långsammare eftersom den körs i Azure SQL Database. Du är dock orolig för att användarna har en snabb och smal upplevelse. En användare som lagras i Azure Cosmos DB skulle se ut så här:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Och ett inlägg skulle se ut så här:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
När en redigering uppstår där ett segmentattribut påverkas kan du enkelt hitta de dokument som påverkas. Använd bara frågor som pekar på de indexerade attributen, till exempel SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", och uppdatera sedan segmenten.
Sökrutan
Användarna genererar lyckligtvis mycket innehåll. Och du bör kunna ge möjlighet att söka och hitta innehåll som kanske inte är direkt i deras innehållsströmmar, kanske för att du inte följer skaparna, eller kanske du bara försöker hitta det gamla inlägget du gjorde för sex månader sedan.
Eftersom du använder Azure Cosmos DB kan du enkelt implementera en sökmotor med Hjälp av Azure AI Search på några minuter utan att skriva någon annan kod än sökprocessen och användargränssnittet.
Varför är den här processen så enkel?
Azure AI Search implementerar vad de kallar indexerare, bakgrundsprocesser som fastnar i dina datalagringsplatser och automatiskt lägger till, uppdaterar eller tar bort dina objekt i indexen. De stöder azure SQL Database-indexerare, Azure Blobs-indexerare och tack och lov Azure Cosmos DB-indexerare. Övergången av information från Azure Cosmos DB till Azure AI Search är enkel. Båda teknikerna lagrar information i JSON-format, så du behöver bara skapa ditt index och mappa attributen från dina dokument som du vill indexera. Det var allt. Beroende på storleken på dina data kommer allt innehåll att vara tillgängligt för sökning inom några minuter av den bästa lösningen Sök som en tjänst i molninfrastrukturen.
Mer information om Azure AI Search finns i Liftarens guide till sökning.
Den underliggande kunskapen
När du har lagrat allt det här innehållet som växer och växer varje dag kan du tänka: Vad kan jag göra med all den här informationsströmmen från mina användare?
Svaret är enkelt: Sätt det att arbeta och lära av det.
Men vad kan du lära dig? Några enkla exempel är attitydanalys, innehållsrekommendationer baserat på en användares inställningar eller till och med en automatiserad con režim šatora rator som ser till att innehållet som publiceras av ditt sociala nätverk är säkert för familjen.
Nu när jag fick dig fast, tror du förmodligen att du behöver lite doktorsexamen i matematikvetenskap för att extrahera dessa mönster och information från enkla databaser och filer, men du skulle ha fel.
Azure Mašinsko učenje är en fullständigt hanterad molntjänst som låter dig skapa arbetsflöden med hjälp av algoritmer i ett enkelt dra och släpp-gränssnitt, koda dina egna algoritmer i R eller använda några av de redan byggda och redo att använda API:er som: Textanalys, Content Moderator eller rekommendationer.
Om du vill uppnå något av dessa Mašinsko učenje scenarier kan du använda Azure Data Lake för att mata in informationen från olika källor. Du kan också använda U-SQL för att bearbeta informationen och generera utdata som kan bearbetas av Azure Mašinsko učenje.
Ett annat tillgängligt alternativ är att använda Azure AI-tjänster för att analysera användarnas innehåll. Du kan inte bara förstå dem bättre (genom att analysera vad de skriver med API för textanalys), utan du kan också identifiera oönskat eller moget innehåll och agera därefter med API för visuellt innehåll. Azure AI-tjänster innehåller många färdiga lösningar som inte kräver någon typ av Mašinsko učenje kunskap att använda.
En social upplevelse i planetskala
Det finns en sista, men inte minst, viktig artikel som jag måste ta itu med: skalbarhet. När du utformar en arkitektur bör varje komponent skalas på egen hand. Du kommer så småningom att behöva bearbeta mer data, eller så vill du ha en större geografisk täckning. Tack och lov är det en nyckelfärdig upplevelse med Azure Cosmos DB att uppnå båda uppgifterna.
Azure Cosmos DB stöder dynamisk partitionering direkt. Den skapar automatiskt partitioner baserat på en viss partitionsnyckel, som definieras som ett attribut i dina dokument. Du måste definiera rätt partitionsnyckel vid designtillfället. Mer information finns i Partitionering i Azure Cosmos DB.
För en social upplevelse måste du anpassa partitioneringsstrategin till hur du frågar och skriver. (Läsningar inom samma partition är till exempel önskvärda och undviker "hot spots" genom att sprida skrivningar på flera partitioner.) Några alternativ är: partitioner baserade på en tidsnyckel (dag/månad/vecka), efter innehållskategori, geografisk region eller användare. Allt beror egentligen på hur du ska köra frågor mot data och visa data i din sociala upplevelse.
Azure Cosmos DB kör dina frågor (inklusive aggregeringar) över alla partitioner transparent, så du behöver inte lägga till någon logik när dina data växer.
Med tiden kommer du så småningom att öka i trafiken och din resursförbrukning (mätt i RU:er eller enheter för begäranden) ökar. Du läser och skriver oftare när användarbasen växer. Användarbasen börjar skapa och läsa mer innehåll. Det är därför viktigt att du kan skala ditt dataflöde . Det är enkelt att öka ru:erna. Du kan göra det med några klick på Azure-portalen eller genom att utfärda kommandon via API:et.
Vad händer om saker och ting blir bättre? Anta att användare från ett annat land/en annan region eller kontinent märker din plattform och börjar använda den. Vilken stor överraskning!
Men vänta! Du inser snart att deras erfarenhet av din plattform inte är optimal. De är så långt borta från din operativa region att svarstiden är fruktansvärd. Du vill uppenbarligen inte att de ska sluta. Om det bara fanns ett enkelt sätt att utöka din globala räckvidd? Det är det!
Med Azure Cosmos DB kan du replikera dina data globalt och transparent med ett par klick och automatiskt välja bland de tillgängliga regionerna från klientkoden. Den här processen innebär också att du kan ha flera redundansregioner.
När du replikerar dina data globalt måste du se till att dina klienter kan dra nytta av dem. Om du använder en webbklientdel eller använder API:er från mobila klienter kan du distribuera Azure Traffic Manager och klona Azure App Service i alla önskade regioner med hjälp av en prestandakonfiguration för att stödja din utökade globala täckning. När dina klienter kommer åt klientdelen eller API:erna dirigeras de till närmaste App Service, som i sin tur ansluter till den lokala Azure Cosmos DB-repliken.
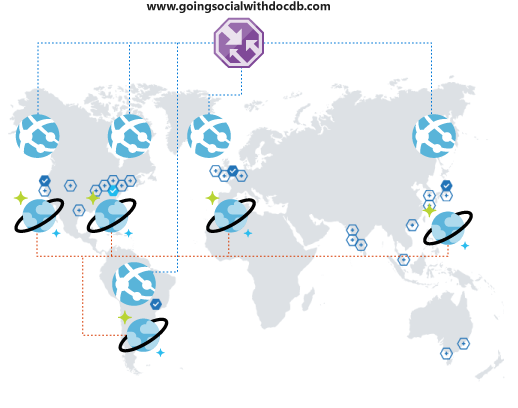
Slutsats
Den här artikeln belyser alternativen för att skapa sociala nätverk helt på Azure med billiga tjänster. Det ger resultat genom att uppmuntra användningen av en lagringslösning med flera lager och datadistribution som kallas "Stege".
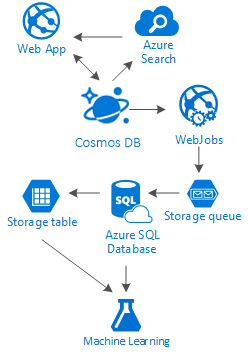
Sanningen är att det inte finns någon silverkula för den här typen av scenarier. Det är den synergi som skapas genom kombinationen av fantastiska tjänster som gör att vi kan skapa fantastiska upplevelser: hastigheten och friheten för Azure Cosmos DB att tillhandahålla ett bra socialt program, intelligensen bakom en förstklassig söklösning som Azure AI Search, flexibiliteten i Azure App Services att vara värd för inte ens språkoberoende program utan kraftfulla bakgrundsprocesser och den utökningsbara Azure Storage och Azure SQL Database för lagring av enorma mängder data och de stora mängder data analyskraft i Azure Mašinsko učenje för att skapa kunskap och intelligens som kan ge feedback till dina processer och hjälpa oss att leverera rätt innehåll till rätt användare.
Nästa steg
Mer information om användningsfall för Azure Cosmos DB finns i Vanliga Användningsfall för Azure Cosmos DB.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för