Migrera data från Amazon S3 till Azure Data Lake Storage Gen2
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Använd mallarna för att migrera petabyte med data som består av hundratals miljoner filer från Amazon S3 till Azure Data Lake Storage Gen2.
Kommentar
Om du vill kopiera små datavolymer från AWS S3 till Azure (till exempel mindre än 10 TB) är det effektivare och enklare att använda verktyget Kopiera data i Azure Data Factory. Mallen som beskrivs i den här artikeln är mer än vad du behöver.
Om lösningsmallarna
Datapartition rekommenderas särskilt när du migrerar mer än 10 TB data. Om du vill partitionering av data använder du prefixinställningen för att filtrera mapparna och filerna på Amazon S3 efter namn, och sedan kan varje ADF-kopieringsjobb kopiera en partition i taget. Du kan köra flera ADF-kopieringsjobb samtidigt för bättre dataflöde.
Datamigrering kräver normalt en engångsmigrering av historiska data samt regelbunden synkronisering av ändringarna från AWS S3 till Azure. Det finns två mallar nedan, där en mall omfattar en gång historisk datamigrering och en annan mall omfattar synkronisering av ändringarna från AWS S3 till Azure.
För mallen för att migrera historiska data från Amazon S3 till Azure Data Lake Storage Gen2
Den här mallen (mallnamn: migrera historiska data från AWS S3 till Azure Data Lake Storage Gen2) förutsätter att du har skrivit en partitionslista i en extern kontrolltabell i Azure SQL Database. Därför kommer den att använda en sökningsaktivitet för att hämta partitionslistan från den externa kontrolltabellen, iterera över varje partition och göra varje ADF-kopieringsjobb kopiera en partition i taget. När ett kopieringsjobb har slutförts använder den aktiviteten Lagrad procedur för att uppdatera statusen för kopiering av varje partition i kontrolltabellen.
Mallen innehåller fem aktiviteter:
- Sökningen hämtar de partitioner som inte har kopierats till Azure Data Lake Storage Gen2 från en extern kontrolltabell. Tabellnamnet är s3_partition_control_table och frågan som ska läsas in från tabellen är "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0".
- ForEach hämtar partitionslistan från sökningsaktiviteten och itererar varje partition till Aktiviteten TriggerCopy. Du kan ange att batchCount ska köra flera ADF-kopieringsjobb samtidigt. Vi har angett 2 i den här mallen.
- ExecutePipeline kör CopyFolderPartitionFromS3-pipeline . Anledningen till att vi skapar en annan pipeline för att göra varje kopieringsjobb till en partition är att det gör det enkelt att köra det misslyckade kopieringsjobbet igen för att läsa in den specifika partitionen igen från AWS S3. Alla andra kopieringsjobb som läser in andra partitioner påverkas inte.
- Kopierar varje partition från AWS S3 till Azure Data Lake Storage Gen2.
- SqlServerStoredProcedure uppdaterar statusen för att kopiera varje partition i kontrolltabellen.
Mallen innehåller två parametrar:
- AWS_S3_bucketName är ditt bucketnamn på AWS S3 där du vill migrera data från. Om du vill migrera data från flera bucketar på AWS S3 kan du lägga till ytterligare en kolumn i den externa kontrolltabellen för att lagra bucketnamnet för varje partition och även uppdatera pipelinen för att hämta data från den kolumnen.
- Azure_Storage_fileSystem är filSystemnamnet på Azure Data Lake Storage Gen2 där du vill migrera data till.
För att mallen endast ska kopiera ändrade filer från Amazon S3 till Azure Data Lake Storage Gen2
Den här mallen (mallnamn: kopiera deltadata från AWS S3 till Azure Data Lake Storage Gen2) använder LastModifiedTime för varje fil för att kopiera de nya eller uppdaterade filerna endast från AWS S3 till Azure. Tänk på om dina filer eller mappar redan har partitionerats med tidslik information som en del av fil- eller mappnamnet på AWS S3 (till exempel /åååå/mm/dd/file.csv), kan du gå till den här självstudien för att få den mer högpresterande metoden för inkrementell inläsning av nya filer. Den här mallen förutsätter att du har skrivit en partitionslista i en extern kontrolltabell i Azure SQL Database. Därför kommer den att använda en sökningsaktivitet för att hämta partitionslistan från den externa kontrolltabellen, iterera över varje partition och göra varje ADF-kopieringsjobb kopiera en partition i taget. När varje kopieringsjobb börjar kopiera filerna från AWS S3 förlitar det sig på egenskapen LastModifiedTime för att identifiera och kopiera endast de nya eller uppdaterade filerna. När ett kopieringsjobb har slutförts använder den aktiviteten Lagrad procedur för att uppdatera statusen för kopiering av varje partition i kontrolltabellen.
Mallen innehåller sju aktiviteter:
- Uppslag hämtar partitionerna från en extern kontrolltabell. Tabellnamnet är s3_partition_delta_control_table och frågan för att läsa in data från tabellen är "select distinct PartitionPrefix from s3_partition_delta_control_table".
- ForEach hämtar partitionslistan från sökningsaktiviteten och itererar varje partition till aktiviteten TriggerDeltaCopy. Du kan ange att batchCount ska köra flera ADF-kopieringsjobb samtidigt. Vi har angett 2 i den här mallen.
- ExecutePipeline kör DeltaCopyFolderPartitionFromS3-pipeline . Anledningen till att vi skapar en annan pipeline för att göra varje kopieringsjobb till en partition är att det gör det enkelt att köra det misslyckade kopieringsjobbet igen för att läsa in den specifika partitionen igen från AWS S3. Alla andra kopieringsjobb som läser in andra partitioner påverkas inte.
- Sökningen hämtar den senaste körningstiden för kopieringsjobbet från den externa kontrolltabellen så att de nya eller uppdaterade filerna kan identifieras via LastModifiedTime. Tabellnamnet är s3_partition_delta_control_table och frågan som ska läsas in från tabellen är "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' och SuccessOrFailure = 1".
- Kopierar endast nya eller ändrade filer för varje partition från AWS S3 till Azure Data Lake Storage Gen2. Egenskapen modifiedDatetimeStart är inställd på den senaste körningstiden för kopieringsjobbet. Egenskapen modifiedDatetimeEnd är inställd på den aktuella körningstiden för kopieringsjobbet. Tänk på att tiden tillämpas på UTC-tidszonen.
- SqlServerStoredProcedure uppdaterar statusen för att kopiera varje partition och kopiera körningstiden i kontrolltabellen när den lyckas. Kolumnen SuccessOrFailure är inställd på 1.
- SqlServerStoredProcedure uppdaterar statusen för att kopiera varje partition och kopiera körningstiden i kontrolltabellen när den misslyckas. Kolumnen SuccessOrFailure är inställd på 0.
Mallen innehåller två parametrar:
- AWS_S3_bucketName är ditt bucketnamn på AWS S3 där du vill migrera data från. Om du vill migrera data från flera bucketar på AWS S3 kan du lägga till ytterligare en kolumn i den externa kontrolltabellen för att lagra bucketnamnet för varje partition och även uppdatera pipelinen för att hämta data från den kolumnen.
- Azure_Storage_fileSystem är filSystemnamnet på Azure Data Lake Storage Gen2 där du vill migrera data till.
Så här använder du dessa två lösningsmallar
För mallen för att migrera historiska data från Amazon S3 till Azure Data Lake Storage Gen2
Skapa en kontrolltabell i Azure SQL Database för att lagra partitionslistan för AWS S3.
Kommentar
Tabellnamnet är s3_partition_control_table. Schemat för kontrolltabellen är PartitionPrefix och SuccessOrFailure, där PartitionPrefix är prefixinställningen i S3 för att filtrera mapparna och filerna i Amazon S3 efter namn, och SuccessOrFailure är statusen för att kopiera varje partition: 0 innebär att partitionen inte har kopierats till Azure och 1 innebär att partitionen har kopierats till Azure. Det finns 5 partitioner som definierats i kontrolltabellen och standardstatusen för kopiering av varje partition är 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Skapa en lagrad procedur i samma Azure SQL Database för kontrolltabell.
Kommentar
Namnet på den lagrade proceduren är sp_update_partition_success. Den anropas av SqlServerStoredProcedure-aktiviteten i din ADF-pipeline.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOGå till mallen Migrera historiska data från AWS S3 till Azure Data Lake Storage Gen2 . Ange anslutningarna till den externa kontrolltabellen, AWS S3 som datakällans lagringsplats och Azure Data Lake Storage Gen2 som målarkiv. Tänk på att den externa kontrolltabellen och den lagrade proceduren refererar till samma anslutning.

Välj Använd denna mall.

Du ser att de 2 pipelinerna och 3 datauppsättningarna har skapats, som du ser i följande exempel:

Gå till pipelinen "BulkCopyFromS3" och välj Felsök och ange Parametrar. Välj sedan Slutför.

Du ser resultat som liknar följande exempel:

För att mallen endast ska kopiera ändrade filer från Amazon S3 till Azure Data Lake Storage Gen2
Skapa en kontrolltabell i Azure SQL Database för att lagra partitionslistan för AWS S3.
Kommentar
Tabellnamnet är s3_partition_delta_control_table. Schemat för kontrolltabellen är PartitionPrefix, JobRunTime och SuccessOrFailure, där PartitionPrefix är prefixinställningen i S3 för att filtrera mapparna och filerna i Amazon S3 efter namn, JobRunTime är datetime-värdet när kopieringsjobb körs och SuccessOrFailure är statusen för att kopiera varje partition: 0 innebär att den här partitionen inte har kopierats till Azure och 1 innebär att partitionen har kopierats till Azure. Det finns 5 partitioner som definierats i kontrolltabellen. Standardvärdet för JobRunTime kan vara den tidpunkt då en gång historisk datamigrering startar. ADF-kopieringsaktiviteten kopierar filerna på AWS S3 som senast har ändrats efter den tiden. Standardstatusen för kopiering av varje partition är 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Skapa en lagrad procedur i samma Azure SQL Database för kontrolltabell.
Kommentar
Namnet på den lagrade proceduren är sp_insert_partition_JobRunTime_success. Den anropas av SqlServerStoredProcedure-aktiviteten i din ADF-pipeline.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOGå till mallen Kopiera deltadata från AWS S3 till Azure Data Lake Storage Gen2 . Ange anslutningarna till den externa kontrolltabellen, AWS S3 som datakällans lagringsplats och Azure Data Lake Storage Gen2 som målarkiv. Tänk på att den externa kontrolltabellen och den lagrade proceduren refererar till samma anslutning.

Välj Använd denna mall.

Du ser att de 2 pipelinerna och 3 datauppsättningarna har skapats, som du ser i följande exempel:

Gå till pipelinen "DeltaCopyFromS3" och välj Felsök och ange parametrarna. Välj sedan Slutför.

Du ser resultat som liknar följande exempel:

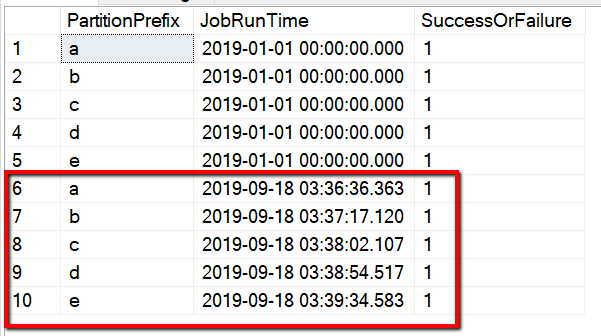
Du kan också kontrollera resultatet från kontrolltabellen med frågan "select * from s3_partition_delta_control_table" (välj * från s3_partition_delta_control_table), så visas utdata som liknar följande exempel: