Geo-replikering (offentlig förhandsversion)
Det finns två funktioner som ger geo-haveriberedskap i Azure Event Hubs.
- Geo-haveriberedskap (Metadata DR), som bara tillhandahåller replikering av endast metadata.
- Geo-replikering (offentlig förhandsversion), som ger replikering av både metadata och data.
Dessa funktioner bör inte förväxlas med tillgänglighetszoner. Båda funktionerna för geografisk återställning ger motståndskraft mellan Azure-regioner som USA, östra och USA, västra. Stöd för tillgänglighetszoner ger motståndskraft inom en specifik geografisk region, till exempel USA, östra. Mer information om tillgänglighetszoner finns i Stöd för tillgänglighetszoner för Event Hubs.
Viktigt!
- Den här funktionen är för närvarande i offentlig förhandsversion och bör därför inte användas i produktionsscenarier.
- Följande regioner stöds för närvarande i den offentliga förhandsversionen.
| USA | Europa |
|---|---|
| Centrala USA EUAP | Italien, norra |
| Spanien, centrala | |
| Norge, östra |
Haveriberedskap för metadata jämfört med geo-replikering av metadata och data
Funktionen Metadata DR replikerar konfigurationsinformation för ett namnområde från ett primärt namnområde till ett sekundärt namnområde. Den stöder en engångsredundans till den sekundära regionen. Under den kundinitierade redundansväxlingen återpointas aliasnamnet för namnområdet till det sekundära namnområdet och sedan bryts parkopplingen. Inga data replikeras förutom konfigurationsinformation och inte heller replikeras behörighetstilldelningar.
Den nyare geo-replikeringsfunktionen replikerar konfigurationsinformation och alla data från ett primärt namnområde till ett eller flera sekundära namnområden. När en redundansväxling utförs blir den valda sekundären den primära och den tidigare primära blir sekundär. Användare kan utföra en redundansväxling tillbaka till den ursprungliga primära när så önskas.
Resten av den här artikeln fokuserar på geo-replikeringsfunktionen. Mer information om dr-funktionen för metadata finns i Händelsehubbar Geo-disater-återställning för metadata.
Geo-replikering
Den offentliga förhandsversionen av geo-replikeringsfunktionen stöds för namnområden i Event Hubs självbetjäningsskalning av dedikerade kluster. Du kan använda funktionen med nya eller befintliga namnområden i dedikerade självbetjäningskluster. Följande funktioner stöds inte med geo-replikering:
- Kundhanterade nycklar (CMK)
- Hanterad identitet för avbildning
- Funktioner för virtuellt nätverk (tjänstslutpunkter eller privata slutpunkter)
- Stöd för stora meddelanden (nu i offentlig förhandsversion)
- Kafka-transaktioner (nu i offentlig förhandsversion)
Några av de viktigaste aspekterna av den offentliga förhandsversionen av geo-datareplikering är:
- Primär-sekundär replikeringsmodell – Geo-replikering bygger på en primär-sekundär replikeringsmodell, där det vid en viss tidpunkt bara finns ett primärt namnområde som hanterar händelseproducenter och händelsekonsumenter.
- Event Hubs utför fullständigt hanterad byte-till-byte-replikering av metadata, händelsedata och konsumentförskjutning över sekundärfiler med de konfigurerade konsekvensnivåerna.
- Fullständigt domännamn för stabilt namnområde (FQDN) – FQDN behöver inte ändras när befordran utförs.
- Replikeringskonsekvens – Det finns två inställningar för replikeringskonsekvens, synkrona och asynkrona.
- Användarhanterad befordran av en sekundär till att vara den nya primära.
Du ändrar en sekundär till att vara en ny primär på två sätt:
- Planerad: en befordran av den sekundära till den primära där trafiken inte bearbetas förrän den nya primära fångar upp alla data som lagras av den tidigare primära instansen.
- Tvingad: som en redundansväxling där den sekundära blir primär så snabbt som möjligt. Geo-replikeringsfunktionen replikerar alla data och metadata från den primära regionen till de valda sekundära regionerna. Namnområdets FQDN pekar alltid på den primära regionen.
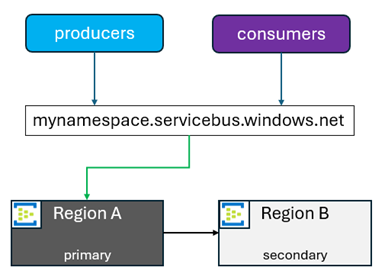
När du initierar en befordran av en sekundär pekar FQDN på den region som valts som den nya primära. Den gamla primära blir sedan sekundär. Du kan höja upp den sekundära till den nya primära av andra skäl än en redundansväxling. Dessa orsaker kan vara programuppgraderingar, redundanstestning eller valfritt antal andra saker. I sådana situationer är det vanligt att växla tillbaka när dessa aktiviteter har slutförts.
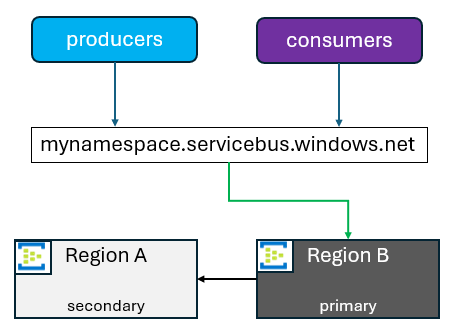
Sekundära regioner läggs till eller tas bort efter kundens gottfinnande. Det finns några aktuella begränsningar som är värda att notera:
- Det finns ingen möjlighet att stödja skrivskyddade vyer i sekundära regioner.
- Det finns ingen automatisk upp- och redundansfunktion. Alla kampanjer är kundinitierade.
- Sekundära regioner måste skilja sig från den primära regionen. Du kan inte välja ett annat dedikerat kluster i samma region.
- Endast en sekundär stöds för offentlig förhandsversion.
Replikeringskonsekvens
Det finns två konfigurationer för replikeringskonsekvens, synkrona och asynkrona. Det är viktigt att känna till skillnaderna mellan de två konfigurationerna eftersom de påverkar dina program och datakonsekvensen.
Asynkron replikering
När asynkron replikering är aktiverad checkas alla meddelanden in i den primära och skickas sedan till den sekundära. Användare kan konfigurera en acceptabel fördröjningstid som den sekundära måste komma ikapp. När fördröjningen för en aktiv sekundär är större än konfigurationen av användarfördröjning begränsar den primära regionen inkommande publiceringsbegäranden.
Synkron replikering
När synkron replikering är aktiverad replikeras publicerade händelser till den sekundära, som måste bekräfta meddelandet innan det checkas in i den primära. Med synkron replikering publicerar ditt program med den hastighet det tar att publicera, replikera, bekräfta och checka in. Det innebär också att ditt program är kopplat till tillgängligheten för båda regionerna. Om den sekundära regionen slutar fungera kan meddelanden inte bekräftas eller bekräftas.
Jämförelse av replikeringskonsekvens
Med synkron replikering:
- Svarstiden är längre på grund av den distribuerade incheckningen.
- Tillgängligheten är kopplad till tillgängligheten för två regioner. Om en region slutar fungera är namnområdet inte tillgängligt.
- Mottagna data finns alltid i minst två regioner (endast två regioner som stöds i den första offentliga förhandsversionen).
Synkron replikering ger den största försäkran om att dina data är säkra. Om du har synkron replikering checkas den in i alla regioner som har konfigurerats för geo-replikering när den har checkats in. Men när synkron replikering är aktiverad kan programmets tillgänglighet minskas beroende på tillgängligheten för båda regionerna.
Aktivering av asynkron replikering påverkar inte svarstiden särskilt mycket och tjänstens tillgänglighet påverkas inte av förlusten av en sekundär region. Asynkron replikering har inte den absoluta garantin för att alla regioner har data innan de checkas in som synkron replikering. Du kan också ange hur lång tid din sekundära kan vara osynkroniserad innan inkommande trafik begränsas. Inställningen kan vara mellan 5 minuter och 1 440 minuter, vilket är en dag. Om du vill använda regioner med ett stort avstånd mellan dem är asynkron replikering förmodligen det bästa alternativet för dig.
Konfigurationen av replikeringskonsekvens kan ändras efter konfigurationen av geo-replikering. Du kan gå från synkron till asynkron eller från asynkron till synkron. Om du går från synkron till asynkron förbättras svarstiden och programtillgängligheten. Om du går från asynkron till synkron konfigureras din sekundära som synkron när fördröjningen når noll. Om du av någon anledning kör med en kontinuerlig fördröjning kan du behöva pausa dina utgivare för att fördröjningen ska nå noll och ditt läge för att kunna växla till synkront.
De allmänna orsakerna till att synkron replikering är aktiverad beror på vikten av data, specifika affärsbehov eller efterlevnadsskäl. Om ditt primära mål är programtillgänglighet snarare än datasäkerhet är asynkron konsekvens förmodligen det bättre valet.
Val av sekundär region
Om du vill aktivera geo-replikeringsfunktionen måste du använda en primär och sekundär region där geo-replikeringsfunktionen är aktiverad. Du måste också ha ett Event Hubs-kluster som redan finns i både de primära och sekundära regionerna.
Geo-replikeringsfunktionen är beroende av att kunna replikera publicerade händelser från den primära till den sekundära regionen. Om den sekundära regionen finns på en annan kontinent har den stor inverkan på replikeringsfördröjningen från den primära till den sekundära regionen. Om du använder geo-replikering av tillgänglighets- och tillförlitlighetsskäl är det bäst att sekundära regioner är minst på samma kontinent där det är möjligt. Om du vill få en bättre förståelse för svarstiden som orsakas av geografiskt avstånd kan du lära dig mer från statistik över svarstidsfördröjning i Azure-nätverk | Microsoft Learn.
Hantering av geo-replikering
Med geo-replikeringsfunktionen kan du konfigurera en sekundär region att replikera konfiguration och data till. Du kan:
- Konfigurera geo-replikering – Sekundära regioner kan konfigureras på alla befintliga namnområden i ett dedikeradt kluster med självbetjäning i en region med geo-replikeringsfunktionen aktiverad. Den kan också konfigureras när namnområdet skapas i samma dedikerade kluster. Om du vill välja en sekundär region måste du ha ett dedikerat kluster tillgängligt i den sekundära regionen och den sekundära regionen måste också ha geo-replikeringsfunktionen aktiverad för den regionen.
- Konfigurera replikeringskonsekvensen – Synkron och asynkron replikering anges när geo-replikering konfigureras men kan också växlas efteråt. Med asynkron konsekvens kan du konfigurera hur lång tid en sekundär region tillåts fördröja.
- Utlös befordran/redundans – Alla kampanjer eller redundansväxlingar initieras av kunden. Under befordran kan du välja att göra den tvingad från början, eller till och med ändra dig när en kampanj har startat och göra den tvingad.
- Ta bort en sekundär – Om du när som helst vill ta bort geo-parkopplingen mellan primära och sekundära regioner kan du göra det och data i den sekundära regionen tas bort.
Övervaka datareplikering
Användare kan övervaka replikeringsjobbets förlopp genom att övervaka replikeringsfördröjningsmåttet i application metrics-loggar.
Aktivera application metrics-loggar i event hubs-namnområdet efter övervakning av Azure Event Hubs – Azure Event Hubs | Microsoft Learn.
När loggarna för programmått har aktiverats måste du skapa och använda data från namnområdet i några minuter innan du börjar se loggarna.
Om du vill visa loggar för programmått går du till avsnittet Övervakning på sidan Händelsehubbar och väljer Loggar på den vänstra menyn. Du kan använda följande fråga för att hitta replikeringsfördröjningen (i sekunder) mellan de primära och sekundära namnrymderna.
AzureDiagnostics | where TimeGenerated > ago(1h) | where Category == "ApplicationMetricsLogs" | where ActivityName_s == "ReplicationLagKolumnen
count_danger replikeringsfördröjningen i sekunder mellan den primära och sekundära regionen.
Publicera data
Händelsepubliceringsprogram kan publicera data till geo-replikerade namnområden via stabilt namnområdes-FQDN för det geo-replikerade namnområdet. Metoden för händelsepublicering är densamma som fallet med icke-Geo DR och inga ändringar i klientprogram krävs.
Händelsepublicering kanske inte är tillgänglig under följande omständigheter:
- Under respitperioden för redundans avvisar den befintliga primära regionen alla nya händelser som publiceras till händelsehubben.
- När replikeringsfördröjningen mellan primära och sekundära regioner når den maximala replikeringsfördröjningen kan arbetsbelastningen för utgivarens ingress begränsas. Publisher-program kan inte komma åt några namnområden direkt i de sekundära regionerna.
Använda data
Händelsekrävande program kan använda data med hjälp av det stabila namnområdets FQDN för ett geo-replikerat namnområde. Konsumentåtgärderna stöds inte från när redundansväxlingen initieras tills den har slutförts.
Kontrollpunkts-/förskjutningshantering
Händelsekrävande program kan fortsätta att underhålla förskjutningshantering som de skulle göra med ett enda namnområde.
Kafka
Förskjutningar checkas in direkt till Händelsehubbar och förskjutningar replikeras mellan regioner. Konsumenterna kan därför börja använda från den plats där den slutade i den primära regionen.
Event Hubs SDK/AMQP
Klienter som använder Event Hubs SDK måste uppgradera till april 2024-versionen av SDK: et. Den senaste versionen av Event Hubs SDK stöder redundansväxling med en uppdatering av kontrollpunkten. Kontrollpunkten hanteras av användare med ett kontrollpunktslager som Azure Blob Storage eller en anpassad lagringslösning. Om det sker en redundansväxling måste kontrollpunktslagret vara tillgängligt från den sekundära regionen så att klienter kan hämta kontrollpunktsdata och undvika förlust av meddelanden.
Prissättning
Dedikerade Event Hubs-kluster prissätts oberoende av geo-replikering. Användning av geo-replikering med Event Hubs dedicated kräver att du har minst två dedikerade kluster i separata regioner. De dedikerade kluster som används som sekundära instanser för geo-replikering kan användas för andra arbetsbelastningar. Det debiteras för geo-replikering baserat på den publicerade bandbredden * antalet sekundära regioner. Geo-replikeringsavgiften undantas i tidig offentlig förhandsversion.
Relaterat innehåll
Mer information om hur du använder geo-replikeringsfunktionen finns i Använda geo-replikering.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för