Självstudie: Använda Apache Spark Structured Streaming med Apache Kafka i HDInsight
Den här självstudien visar hur du använder Apache Spark Structured Streaming till att läsa och skriva data med Apache Kafka i Azure HDInsight.
Spark Structured Streaming är en strömbearbetningsmotor som bygger på Spark SQL. Med den kan du uttrycka strömmande beräkningar på samma sätt som batchberäkningar av statiska data.
I den här självstudien lär du dig att:
- Använda en Azure Resource Manager-mall för att skapa kluster
- Använda Spark Structured Streaming med Kafka
När du är klar med stegen i det här dokumentet bör du komma ihåg att ta bort klustren för att undvika extra avgifter.
Förutsättningar
jq, en JSON-processor på kommandoraden. Se https://stedolan.github.io/jq/.
Kunskaper om Jupyter Notebooks med Spark på HDInsight. Mer information finns i dokumentet Läsa in data och köra frågor med Apache Spark på HDInsight.
Kunskaper i programmeringsspråket Scala. Koden som används i den här självstudien är skriven i Scala.
Om du vet hur man skapar Kafka-avsnitt. Mer information finns i dokumentet Snabbstart för Apache Kafka i HDInsight.
Viktigt!
Stegen i det här dokumentet kräver en Azure-resursgrupp som innehåller både en Apache Spark på HDInsight och en Kafka på HDInsight-klustret. Båda dessa kluster finns i ett virtuellt Azure-nätverk, vilket innebär att Apache Spark-klustret kan kommunicera direkt med Kafka-klustret.
Dokumentet innehåller länkar till en mall som kan skapa alla nödvändiga Azure-resurser.
Mer information om hur du använder HDInsight i ett virtuellt nätverk finns i dokumentet Planera ett virtuellt nätverk för HDInsight .
Structured Streaming med Apache Kafka
Apache Spark Structured Streaming är en bearbetningsmotor för dataströmmar som bygger på Apache Spark SQL-motorn. När du använder Structured Streaming kan du skriva direktuppspelningsfrågor på samma sätt som du skriver batchfrågor.
Följande kodfragment visar läsning från Kafka och lagring på en fil. Den första är en batchåtgärd och den andra är en strömningsåtgärd:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
I båda kodfragmenten läses data från Kafka och skrivs till en fil. Skillnader mellan exemplen är:
| Batch | Strömning |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Strömningsåtgärden använder awaitTermination(30000)också , vilket stoppar strömmen efter 30 000 ms.
Om du vill använda Structured Streaming med Kafka måste ditt projekt ha ett beroende på paketet org.apache.spark : spark-sql-kafka-0-10_2.11. Versionen av det här paketet ska överensstämma med version på Spark på HDInsight. För Spark 2.4 (finns i HDInsight 4.0) kan du hitta beroendeinformationen för olika projekttyper på https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
För Jupyter Notebook som används med den här självstudien läser följande cell in det här paketberoendet:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Skapa kluster
Apache Kafka på HDInsight ger inte åtkomst till Kafka-mäklarna via det offentliga Internet. Allt som använder Kafka måste finnas i samma virtuella Azure-nätverk. I den här självstudien finns både Kafka- och Apache Spark-klustren i samma virtuella Azure-nätverk.
Följande diagram visar hur kommunikation flödar mellan Apache Spark och Kafka:
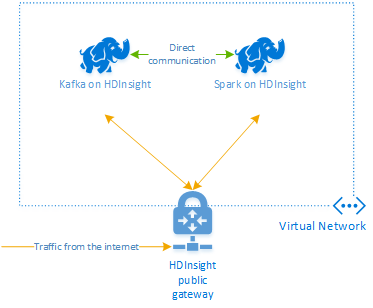
Kommentar
Kafka-tjänsten är begränsad till kommunikation inom det virtuella nätverket. Andra tjänster på klustret, till exempel SSH och Ambari, kan nås via Internet. Mer information om de offentliga portar som är tillgängliga med HDInsight finns i Portar och URI:er som används av HDInsight.
Om du vill skapa ett Azure Virtual Network och sedan skapa Kafka- och Spark-kluster i den, använder du följande steg:
Använd följande knapp för att logga in på Azure och öppna mallen i Azure Portal.

Azure Resource Manager-mallen finns i https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Den här mallen skapar följande resurser:
Ett Kafka på HDInsight 4.0- eller 5.0-kluster.
Ett Spark 2.4- eller 3.1-kluster i HDInsight 4.0 eller 5.0.
Ett virtuellt Azure-nätverk som innehåller HDInsight-klustren.
Viktigt!
Den strukturerade notebook-filen för direktuppspelning som används i den här självstudien kräver Spark 2.4 eller 3.1 på HDInsight 4.0 eller 5.0. Om du använder en tidigare version av Apache Spark i HDInsight får du ett felmeddelande när du använder anteckningsboken.
Använd följande information för att fylla i posterna i avsnittet Anpassad mall:
Inställning Värde Prenumeration Din Azure-prenumeration Resursgrupp Resursgruppen som innehåller resurserna. Plats Azure-regionen som resurserna skapas i. Apache Spark-klusternamn Namnet på Apache Spark-klustret. De första sex tecknen får inte vara samma som Kafka-klusternamnet. Kafka-klusternamn Namnet på Kafka-klustret. De första sex tecknen får inte vara samma som Spark-klusternamnet. Användarnamn för klusterinloggning Ett administratörsanvändarnamn för klustren. Lösenord för klusterinloggning Ett administratörslösenord för klustren. SSH-användarnamn SSH-användare som ska skapas för klustren. SSH-lösenord Lösenord för SSH-användaren. 
Läs villkoren och välj sedan Jag godkänner de villkor som anges ovan.
Välj Köp.
Kommentar
Det kan ta upp till 20 minuter att skapa klustren.
Använda Spark Structured Streaming
Det här exemplet visar hur du använder Spark Structured Streaming med Kafka i HDInsight. Den använder data om taxiresor, som tillhandahålls av New York City. Datauppsättningen som används av den här notebook-filen är från 2016 Green Taxi Trip Data.
Samla in värdinformation. Använd curl- och jq-kommandona nedan för att hämta information om Kafka ZooKeeper- och broker-värdar. Kommandona är utformade för en Windows-kommandotolk, små variationer krävs för andra miljöer. Ersätt
KafkaClustermed namnet på ditt Kafka-kluster ochKafkaPasswordmed lösenordet för klusterinloggning. ErsättC:\HDI\jq-win64.exeockså med den faktiska sökvägen till jq-installationen. Ange kommandona i en Windows-kommandotolk och spara utdata för användning i senare steg.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Från en webbläsare går du till
https://CLUSTERNAME.azurehdinsight.net/jupyter, därCLUSTERNAMEär namnet på klustret. Ange klusterinloggningen (administratör) och det lösenord som användes när du skapade klustret.Välj Ny > Spark för att skapa en notebook-fil.
Spark-strömning har mikrobatching, vilket innebär att data kommer när batchar och utförare körs på batcharna med data. Om kören har en tidsgräns för inaktivitet mindre än den tid det tar att bearbeta batchen, läggs exekutorerna ständigt till och tas bort. Om tidsgränsen för inaktiva körningskörningar är större än batchvaraktigheten tas aldrig körningen bort. Därför rekommenderar vi att du inaktiverar dynamisk allokering genom att ange spark.dynamicAllocation.enabled till false när du kör strömmande program.
Läs in paket som används av notebook-filen genom att ange följande information i en notebook-cell. Kör kommandot med hjälp av CTRL + RETUR.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Skapa Kafka-ämnet. Redigera kommandot nedan genom att
YOUR_ZOOKEEPER_HOSTSersätta med den Zookeeper-värdinformation som extraherades i det första steget. Ange det redigerade kommandot i Jupyter Notebook för att skapa ämnettripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersHämta data om taxiresor. Ange kommandot i nästa cell för att läsa in data om taxiresor i New York City. Data läses in i en dataram och sedan visas dataramen som cellutdata.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Ange information om Kafka-koordinatorvärdar. Ersätt
YOUR_KAFKA_BROKER_HOSTSmed information om broker-värdar som du extraherade i steg 1. Ange det redigerade kommandot i nästa Jupyter Notebook-cell.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Skicka data till Kafka. I följande kommando används fältet
vendoridsom nyckelvärde för Kafka-meddelandet. Nyckeln används av Kafka vid partitionering av data. Alla fält lagras i Kafka-meddelandet som ett JSON-strängvärde. Ange följande kommando i Jupyter för att spara data till Kafka med hjälp av en batchfråga.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Deklarera ett schema. Följande kommando visar hur du använder ett schema när du läser JSON-data från kafka. Ange kommandot i nästa Jupyter-cell.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Välj data och starta strömmen. Följande kommando visar hur du hämtar data från Kafka med hjälp av en batchfråga. Skriv sedan ut resultatet till HDFS i Spark-klustret. I det här exemplet
selecthämtar meddelandet (värdefältet) från Kafka och tillämpar schemat på det. Data skrivs sedan till HDFS (WASB eller ADL) i parquet-format. Ange kommandot i nästa Jupyter-cell.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Du kan kontrollera att filerna har skapats genom att ange kommandot i nästa Jupyter-cell. Den visar filerna i
/example/batchtripdatakatalogen.%%bash hdfs dfs -ls /example/batchtripdataI föregående exempel användes en batchfråga, men följande kommando visar hur du gör samma sak med hjälp av en direktuppspelningsfråga. Ange kommandot i nästa Jupyter-cell.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Kör följande cell för att kontrollera att filerna har skrivits av strömningsfrågan.
%%bash hdfs dfs -ls /example/streamingtripdata
Rensa resurser
Om du vill rensa resurserna som har skapats med den här självstudien kan du ta bort resursgruppen. Om du tar bort resursgruppen tas även det associerade HDInsight-klustret bort. Och andra resurser som är associerade med resursgruppen.
Ta bort en resursgrupp med Azure Portal:
- I Azure-portalen expanderar du menyn till vänster för att öppna menyn med tjänster och väljer sedan Resursgrupper för att visa listan över dina resursgrupper.
- Leta reda på den resursgrupp du vill ta bort och högerklicka på knappen Mer (...) till höger om listan.
- Välj Ta bort resursgrupp och bekräfta.
Varning
Debiteringen för HDInsight-klustret börjar när ett kluster skapas och stoppas när klustret tas bort. Debiteringen görs i förväg per minut, så du ska alltid ta bort ditt kluster när det inte används.
Om du tar bort en Kafka i ett HDInsight-kluster tas alla data som lagrats i Kafka bort.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för