Översikt över Azure Storage i HDInsight
Azure Storage är en robust lagringslösning för generell användning som integreras sömlöst med HDInsight. HDInsight kan använda en blobcontainer i Azure Storage som standardfilsystem för klustret. Via ett HDFS-gränssnitt kan den fullständiga uppsättningen komponenter i HDInsight fungera direkt på strukturerade eller ostrukturerade data som lagras som blobar.
Vi rekommenderar att du använder separata lagringscontainrar för din standardklusterlagring och dina affärsdata. Separationen är att isolera HDInsight-loggarna och temporära filer från dina egna affärsdata. Vi rekommenderar också att du tar bort standardblobcontainern, som innehåller program- och systemloggar, efter varje användning för att minska lagringskostnaden. Se till att hämta loggarna innan du tar bort containern.
Om du väljer att skydda ditt lagringskonto med begränsningar för brandväggar och virtuella nätverk i valda nätverk måste du aktivera undantaget Tillåt betrodda Microsoft-tjänster.... Undantaget är så att HDInsight kan komma åt ditt lagringskonto.
Lagringsarkitekturen i HDInsight
Följande diagram innehåller en abstrakt vy över HDInsight-arkitekturen i Azure Storage:
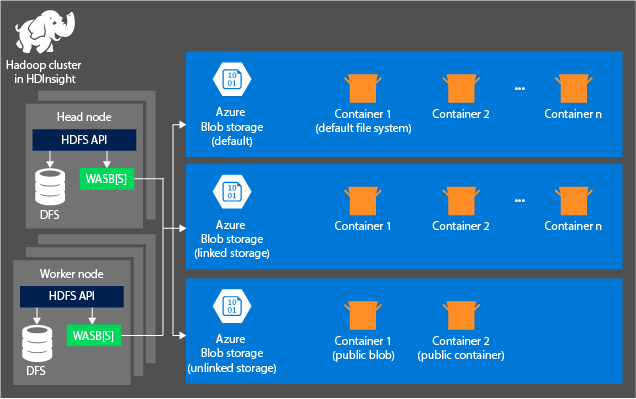
HDInsight ger tillgång till det distribuerade filsystemet som är lokalt anslutet till beräkningsnoderna. Detta filsystem kan nås med hjälp av den fullständigt kvalificerade URI-strängen, till exempel:
hdfs://<namenodehost>/<path>
Via HDInsight kan du också komma åt data i Azure Storage. Syntaxen ser ut så här:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
För konton som har ett hierarkiskt namnområde (Azure Data Lake Storage Gen2) är syntaxen följande:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Tänk på följande principer när du använder ett Azure Storage-konto med HDInsight-kluster:
Containrar på de lagringskonton som är anslutna till ett kluster: Eftersom kontonamnet och nyckeln associeras med klustret när det skapas har du full tillgång till blobarna i dessa containrar.
Offentliga containrar eller offentliga blobar i lagringskonton som inte är anslutna till ett kluster: Du har skrivskyddad behörighet till blobarna i containrarna.
Kommentar
Med offentliga containrar kan du hämta en lista över alla blobar som är tillgängliga i containern och hämta containermetadata. Du kan endast komma åt offentliga blobar om du känner till den exakta webbadressen. Mer information finns i Hantera anonym läsbehörighet till containrar och blobbar.
Privata containrar i lagringskonton som inte är anslutna till ett kluster: Du kan inte komma åt blobarna i containrarna om du inte definierar lagringskontot när du skickar WebHCat-jobben.
De lagringskonton som definieras under skapandeprocessen och deras nycklar lagras i %HADOOP_HOME%/conf/core-site.xml i klusternoderna. Som standard använder HDInsight de lagringskonton som definierats i filen core-site.xml. Du kan ändra den här inställningen med hjälp av Apache Ambari. Mer information om lagringskontoinställningar som kan ändras eller placeras i filen core-site.xml finns i följande artiklar:
Flera WebHCat-jobb, inklusive Apache Hive. Och MapReduce, Apache Hadoop-strömning och Apache Pig har en beskrivning av lagringskonton och metadata. (Den här aspekten gäller för närvarande för Pig med lagringskonton men inte för metadata.) Mer information finns i Använda ett HDInsight-kluster med alternativa lagringskonton och metaarkiv.
Blobar kan användas för strukturerade och ostrukturerade data. Blobcontainrar lagrar data som nyckel/värde-par och har ingen kataloghierarki. Nyckelnamnet kan dock innehålla ett snedstreck ( / ) så att det ser ut som om en fil lagras i en katalogstruktur. En blobnyckel kan till exempel vara input/log1.txt. Det finns ingen faktisk input katalog, men på grund av snedstreckstecknet i nyckelnamnet ser nyckeln ut som en filsökväg.
Fördelar med Azure Storage
Beräkningskluster och lagringsresurser som inte samallokeras har underförstådda prestandakostnader. Dessa kostnader minskas genom att beräkningskluster skapas nära lagringskontoresurserna i Azure-regionen. I den här regionen kan beräkningsnoderna effektivt komma åt data via höghastighetsnätverket i Azure Storage.
När du lagrar data i Azure Storage i stället för HDFS får du flera fördelar:
Återanvändning och delning av data: Data i HDFS lagras inuti beräkningsklustren. Endast de program som har åtkomst till beräkningsklustren kan använda dessa data med hjälp av HDFS-API:er. Data i Azure Storage kan däremot nås via ANTINGEN HDFS-API:er eller REST-API:er för Blob Storage. På grund av det här arrangemanget kan en större uppsättning program (inklusive andra HDInsight-kluster) och verktyg användas för att producera och använda data.
Dataarkivering: När data lagras i Azure Storage kan DE HDInsight-kluster som används för beräkning tas bort på ett säkert sätt utan att användardata förloras.
Datalagringskostnad: Det är dyrare att lagra data i DFS på lång sikt än att lagra data i Azure Storage. Eftersom kostnaden för ett beräkningskluster är högre än kostnaden för Azure Storage. Eftersom data inte behöver läsas in igen för varje beräkningsklustergenerering sparar du även kostnader för datainläsning.
Elastisk utskalning: Även om HDFS ger dig ett utskalat filsystem bestäms skalan av antalet noder som du skapar för klustret. Det kan vara mer komplicerat att ändra skalan än de elastiska skalningsfunktioner som du får automatiskt i Azure Storage.
Geo-replikering: Azure Storage kan geo-replikeras. Även om geo-replikering ger dig geografisk återställning och dataredundans, påverkar en redundans till den geo-replikerade platsen allvarligt dina prestanda, och det kan medföra ytterligare kostnader. Välj därför geo-replikering försiktigt och endast om datavärdet motiverar den extra kostnaden.
Vissa MapReduce-jobb och -paket kan skapa mellanliggande resultat som du inte vill lagra i Azure Storage. I så fall kan du välja att lagra data i den lokala HDFS. HDInsight använder DFS för flera av dessa mellanliggande resultat i Hive-jobb och andra processer.
Kommentar
De flesta HDFS-kommandon (till exempel ls, copyFromLocaloch mkdir) fungerar som förväntat i Azure Storage. Endast de kommandon som är specifika för den interna HDFS-implementeringen (som kallas DFS), till exempel fschk och dfsadmin, visar olika beteenden i Azure Storage.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för