Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Azure Stream Analytics stöder partitionering av anpassade blobutdata med anpassade fält eller attribut och anpassade DateTime sökvägsmönster.
Anpassat fält eller attribut
Anpassade fält- eller indataattribut förbättrar arbetsflöden för nedströms databearbetning och rapportering genom att ge mer kontroll över utdata.
Alternativ för partitionsnyckel
Partitionsnyckeln eller kolumnnamnet som används för att partitionera indata kan innehålla alla tecken som accepteras för blobnamn. Det går inte att använda kapslade fält som en partitionsnyckel om de inte används tillsammans med alias. Du kan dock använda vissa tecken för att skapa en hierarki med filer. Om du till exempel vill skapa en kolumn som kombinerar data från två andra kolumner för att skapa en unik partitionsnyckel kan du använda följande fråga:
SELECT name, id, CONCAT(name, "/", id) AS nameid
Partitionsnyckeln måste vara NVARCHAR(MAX), BIGINT, FLOATeller BIT (1.2-kompatibilitetsnivå eller högre). Typerna DateTime, Arrayoch Records stöds inte, men de kan användas som partitionsnycklar om de konverteras till strängar. Mer information finns i Azure Stream Analytics-datatyper.
Exempel
Anta att ett jobb tar indata från liveanvändarsessioner som är anslutna till en extern videospeltjänst där inmatade data innehåller en kolumn client_id för att identifiera sessionerna. Om du vill partitioneras data efter client_idanger du fältet blobsökvägsmönster så att det innehåller en partitionstoken {client_id} i blobutdataegenskaperna när du skapar ett jobb. När data med olika client_id värden flödar genom Stream Analytics-jobbet sparas utdata i separata mappar baserat på ett enda client_id värde per mapp.

På samma sätt, om jobbinmatningen var sensordata från miljontals sensorer där varje sensor hade en sensor_id, skulle sökvägsmönstret vara {sensor_id} att partitioneras varje sensordata till olika mappar.
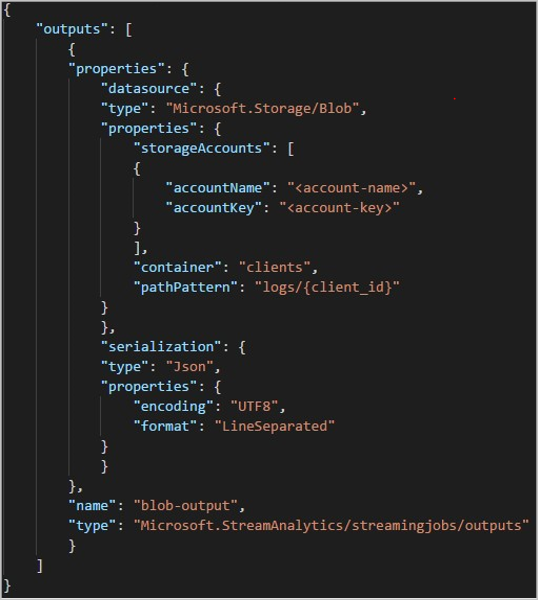
När du använder REST-API:et kan utdataavsnittet i en JSON-fil som används för den begäran se ut som följande bild:
När jobbet börjar köras kan containern clients se ut som följande bild:
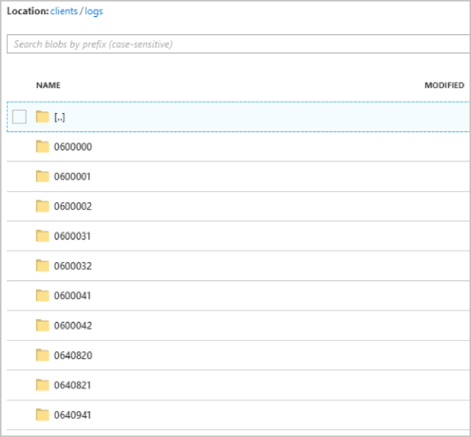
Varje mapp kan innehålla flera blobar där varje blob innehåller en eller flera poster. I föregående exempel finns det en enda blob i en mapp märkt "06000000" med följande innehåll:
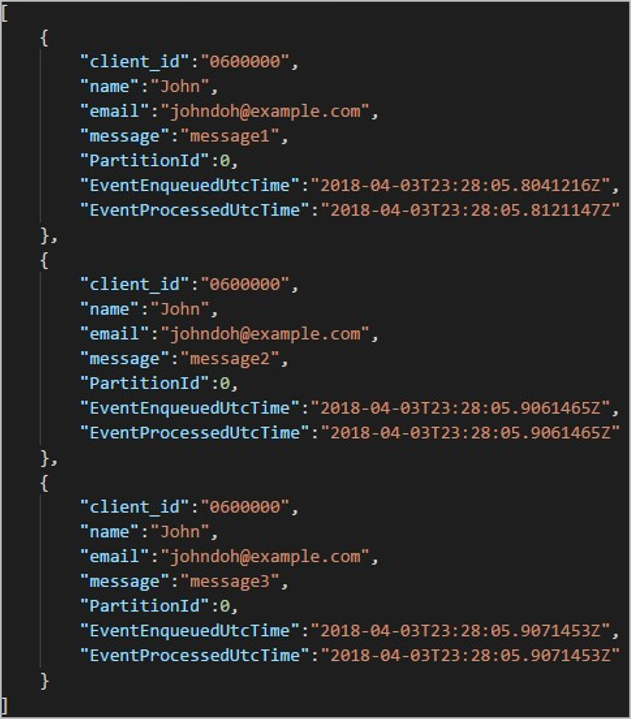
Observera att varje post i bloben har en client_id kolumn som matchar mappnamnet eftersom kolumnen som användes för att partitionera utdata i utdatasökvägen var client_id.
Begränsningar
Endast en anpassad partitionsnyckel tillåts i utdataegenskapen för sökvägsmönstret. Alla följande sökvägsmönster är giltiga:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Om kunderna vill använda mer än ett indatafält kan de skapa en sammansatt nyckel i frågan för anpassad sökvägspartition i blobutdata med hjälp
CONCATav . Ett exempel ärselect concat (col1, col2) as compositeColumn into blobOutput from input. Sedan kan de angecompositeColumnsom den anpassade sökvägen i Azure Blob Storage.Partitionsnycklar är skiftlägesokänsliga, så partitionsnycklar som
Johnochjohnär likvärdiga. Uttryck kan inte heller användas som partitionsnycklar. Till exempel{columnA + columnB}fungerar inte.När en indataström består av poster med en kardinalitet för partitionsnycklar under 8 000 läggs posterna till i befintliga blobar. De skapar bara nya blobar när det behövs. Om kardinaliteten är över 8 000 finns det ingen garanti för att befintliga blobar skrivs till. Nya blobar skapas inte för ett godtyckligt antal poster med samma partitionsnyckel.
Om blobutdata konfigureras som oföränderliga skapar Stream Analytics en ny blob varje gång data skickas.
Anpassade DateTime-sökvägsmönster
Med anpassade DateTime sökvägsmönster kan du ange ett utdataformat som överensstämmer med Hive Streaming-konventioner, vilket ger Stream Analytics möjlighet att skicka data till Azure HDInsight och Azure Databricks för nedströmsbearbetning. Anpassade DateTime sökvägsmönster implementeras enkelt med hjälp av nyckelordet datetime i fältet Sökvägsprefix i blobutdata, tillsammans med formatspecificeraren. Ett exempel är {datetime:yyyy}.
Token som stöds
Följande formatspecificeraretoken kan användas ensamt eller i kombination för att uppnå anpassade DateTime format.
| Formatspecificerare | beskrivning | Resultat vid exempeltid 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Året som ett fyrsiffrigt tal | 2018 |
| {datetime:MM} | Månad från 01 till 12 | 01 |
| {datetime:M} | Månad från 1 till 12 | 1 |
| {datetime:dd} | Dag från 01 till 31 | 02 |
| {datetime:d} | Dag från 1 till 31 | 2 |
| {datetime:HH} | Timme med 24-timmarsformat, från 00 till 23 | 10 |
| {datetime:mm} | Minuter från 00 till 60 | 06 |
| {datetime:m} | Minuter från 0 till 60 | 6 |
| {datetime:ss} | Sekunder från 00 till 60 | 08 |
Om du inte vill använda anpassade DateTime mönster kan du lägga till {date} och/eller {time} token i fältet Sökvägsprefix för att generera en listruta med inbyggda DateTime format.
Utökningsbarhet och begränsningar
Du kan använda så många token ({datetime:<specifier>}) som du vill i sökvägsmönstret tills du når sökvägsprefixets teckengräns. Formatspecificerare kan inte kombineras inom en enda token utöver de kombinationer som redan anges av listrutorna datum och tid.
För en sökvägspartition av logs/MM/dd:
| Giltigt uttryck | Ogiltigt uttryck |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Du kan använda samma formatspecificerare flera gånger i sökvägsprefixet. Token måste upprepas varje gång.
Hive Streaming-konventioner
Anpassade sökvägsmönster för Blob Storage kan användas med Hive Streaming-konventionen, som förväntar sig att mappar ska märkas med column= i mappnamnet.
Ett exempel är year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Anpassade utdata eliminerar besväret med att ändra tabeller och manuellt lägga till partitioner i portdata mellan Stream Analytics och Hive. I stället kan många mappar läggas till automatiskt med hjälp av:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Exempel
Skapa ett lagringskonto, en resursgrupp, ett Stream Analytics-jobb och en indatakälla enligt Stream Analytics-Azure Portal snabbstart. Använd samma exempeldata som används i snabbstarten. Exempeldata är också tillgängliga i GitHub.
Skapa en blobutdatamottagare med följande konfiguration:
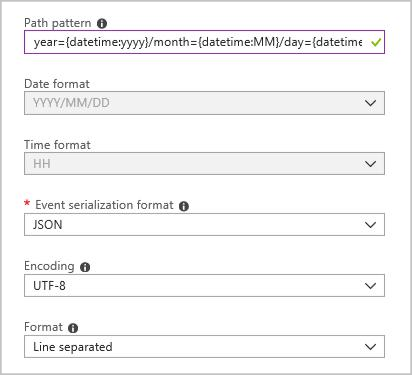
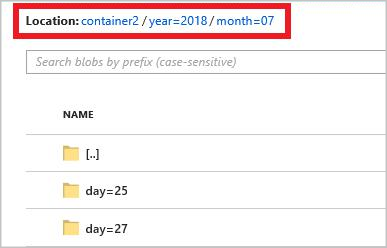
Det fullständiga sökvägsmönstret är:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
När du startar jobbet skapas en mappstruktur baserat på sökvägsmönstret i blobcontainern. Du kan öka detaljnivån till dagsnivån.