Så här gör du: Ändra en lake-databas
I den här artikeln får du lära dig hur du ändrar en befintlig lake-databas i Azure Synapse med hjälp av databasdesignern. Med databasdesignern kan du enkelt skapa och distribuera en databas utan att skriva någon kod.
Förutsättningar
- Synapse-administratören eller Synapse-deltagarbehörigheter krävs på Synapse-arbetsytan för att skapa en lake-databas.
- Behörigheter för Lagringsblobdatadeltagare krävs på datasjön när du använder alternativet Skapa tabell från datasjö .
Ändra databasegenskaper
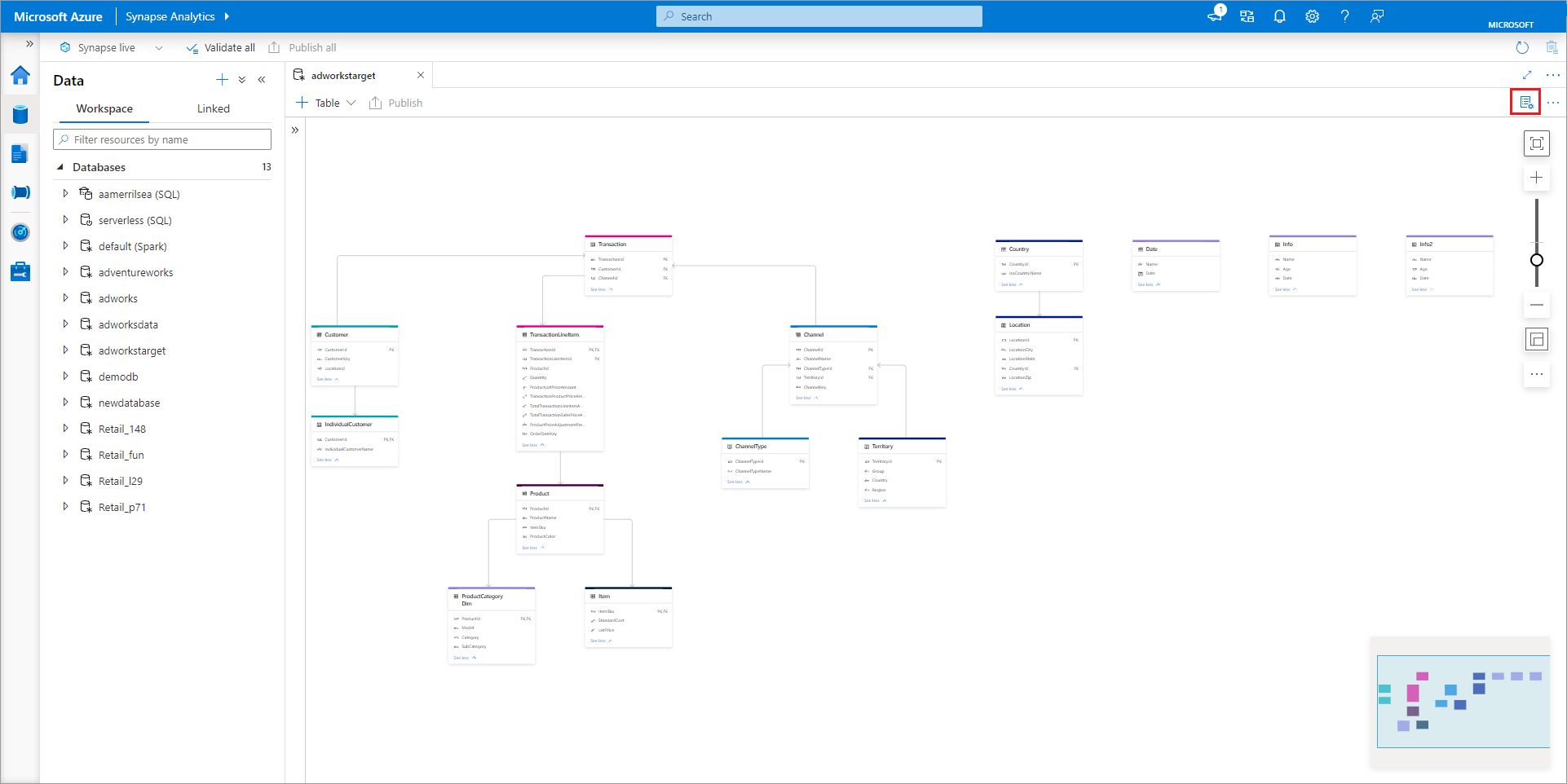
Välj fliken Data till vänster på arbetsytan Start för Azure Synapse Analytics. På fliken Data öppnas listan över databaser som redan finns på din arbetsyta.
Hovra över avsnittet Databaser och välj ellipsen ... bredvid den databas som du vill ändra och välj sedan Öppna.

Fliken Databasdesigner öppnas med den valda databasen inläst på arbetsytan.
Databasdesignern har fönstret Egenskaper som kan öppnas genom att välja ikonen Egenskaper uppe till höger på fliken.
- Namn Namn kan inte redigeras när databasen har publicerats, så kontrollera att namnet du väljer är korrekt.
- Beskrivning Att ge databasen en beskrivning är valfritt, men det gör att användarna kan förstå syftet med databasen.
- Lagringsinställningar för databasen är ett avsnitt som innehåller standardlagringsinformationen för tabeller i databasen. Standardinställningarna tillämpas på varje tabell i databasen om den inte åsidosätts i själva tabellen.
- Länkad tjänst är den länkade standardtjänst som används för att lagra dina data i Azure Data Lake Storage. Den länkade standardtjänsten som är associerad med Synapse-arbetsytan visas, men du kan ändra den länkade tjänsten till vilket ADLS-lagringskonto du vill.
- Indatamapp som används för att ange standardsökvägen för containern och mappen i den länkade tjänsten med hjälp av filwebbläsaren eller manuellt redigera sökvägen med pennikonen.
- Dataformat lake-databaser i Azure Synapse stöder parkett och avgränsad text som lagringsformat för data.
Om du vill lägga till en tabell i databasen väljer du knappen + Tabell .
- Custom lägger till en ny tabell på arbetsytan.
- Från mallen öppnas galleriet och du kan välja en databasmall som ska användas när du lägger till en ny tabell. Mer information finns i Skapa lake-databas från databasmall.
- Med Data Lake kan du importera ett tabellschema med data som redan finns i din sjö.
Välj anpassad. En ny tabell visas på arbetsytan med namnet Table_1.
Du kan sedan anpassa Table_1, inklusive tabellnamn, beskrivning, lagringsinställningar, kolumner och relationer. Se avsnittet Anpassa tabeller i en databas nedan.
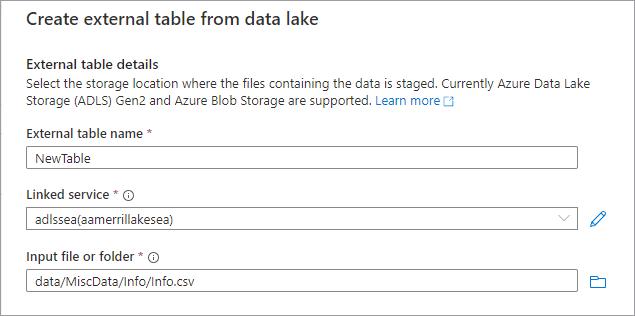
Lägg till en ny tabell från datasjön genom att välja + Tabell och sedan Från datasjö.
Fönstret Skapa extern tabell från Data Lake visas. Fyll i fönstret med informationen nedan och välj Fortsätt.
- Extern tabell namnger det namn som du vill ge den tabell som du skapar.
- Länkad tjänst den länkade tjänsten som innehåller den Azure Data Lake Storage plats där datafilen finns.
- Indatafil eller mapp använder filwebbläsaren för att navigera till och välja en fil på din sjö som du vill skapa en tabell med.
- På nästa skärm förhandsgranskar Azure Synapse filen och identifierar schemat.
- Du hamnar på sidan Ny extern tabell där du kan uppdatera alla inställningar som är relaterade till dataformatet och Förhandsgranska data för att kontrollera om Azure Synapse identifierat filen korrekt.
- När du är nöjd med inställningarna väljer du Skapa.
- En ny tabell med det valda namnet läggs till på arbetsytan och avsnittet Lagringsinställningar för tabell visar den fil som du har angett.
Nu när databasen är anpassad är det dags att publicera den. Om du använder Git-integrering med Synapse-arbetsytan måste du checka in ändringarna och sammanfoga dem i samarbetsgrenen. Läs mer om källkontroll i Azure Synapse. Om du använder Synapse Live-läge kan du välja "publicera".
Databasen verifieras för fel innan den publiceras. Eventuella fel som hittas visas på meddelandefliken med instruktioner om hur du åtgärdar felet.
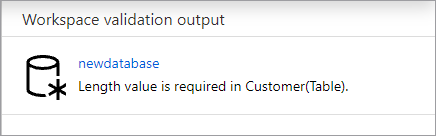
När du publicerar skapas databasschemat i Azure Synapse Metaarkiv. Efter publiceringen kommer databas- och tabellobjekten att vara synliga för andra Azure-tjänster och tillåta att metadata från databasen flödar till appar som Power BI eller Microsoft Purview.
Anpassa tabeller i en databas
Med databasdesignern kan du anpassa alla tabeller i databasen fullständigt. När du väljer en tabell finns det tre flikar tillgängliga, som var och en innehåller inställningar relaterade till tabellens schema eller metadata.
Allmänt
Fliken Allmänt innehåller information som är specifik för själva tabellen.
Namnge namnet på tabellen. Tabellnamnet kan anpassas till valfritt unikt värde i databasen. Flera tabeller med samma namn tillåts inte.
Ärvt från (valfritt) det här värdet finns om tabellen skapades från en databasmall. Det går inte att redigera den och talar om för användaren vilken malltabell den härleddes från.
Beskrivning av tabellen. Om tabellen skapades från en databasmall innehåller den en beskrivning av konceptet som representeras av den här tabellen. Det här fältet kan redigeras och kan ändras så att det matchar den beskrivning som matchar dina affärskrav.
Visningsmappen innehåller namnet på den affärsområdesmapp som den här tabellen grupperades under som en del av databasmallen. För anpassade tabeller blir det här värdet "Annat".
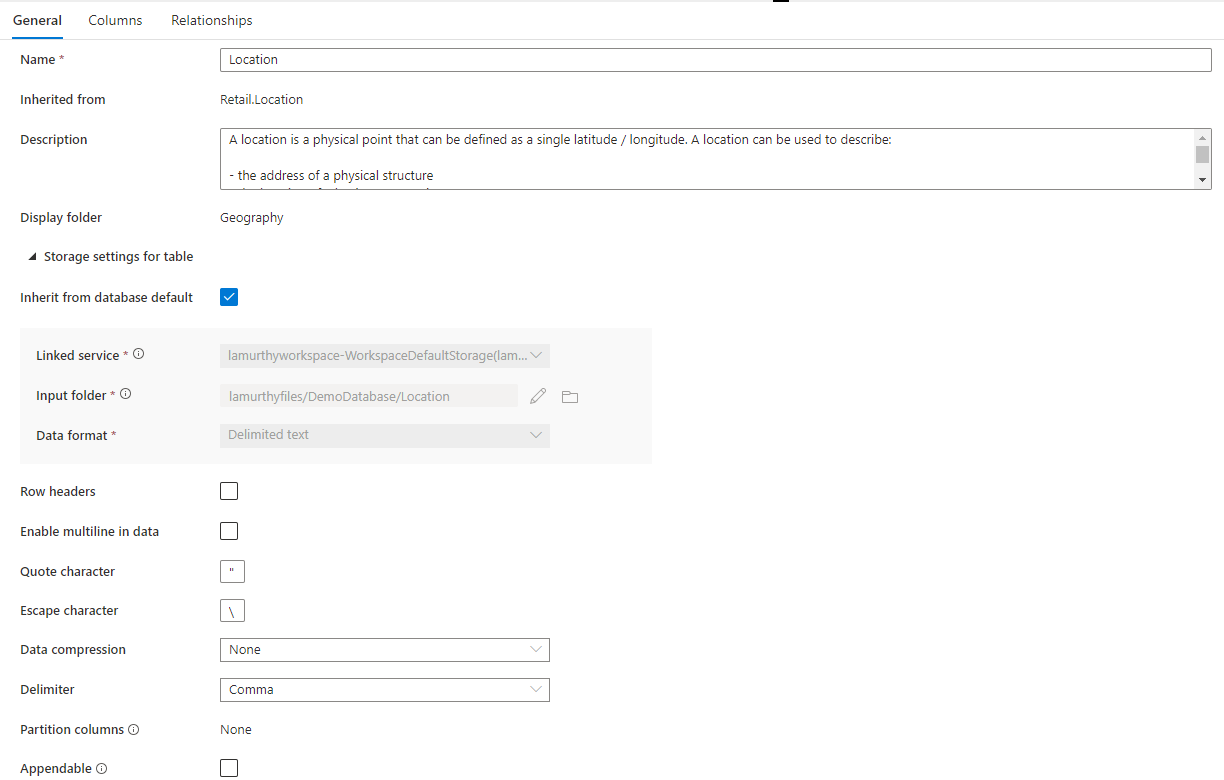
Dessutom finns det ett komprimerbart avsnitt med namnet Lagringsinställningar för tabellen som innehåller inställningar för den underliggande lagringsinformation som används av tabellen.
Ärv från databasen standard en kryssruta som avgör om lagringsinställningarna nedan ärvs från de värden som anges på fliken Databasegenskaper eller anges individuellt. Om du vill anpassa lagringsvärdena avmarkerar du den här rutan.
- Länkad tjänst är den länkade standardtjänst som används för att lagra dina data i Azure Data Lake Storage. Ändra detta för att välja ett annat ADLS-konto.
- Indatamapp mappen i ADLS där data som läses in till den här tabellen kommer att finnas. Du kan antingen bläddra i mappplatsen eller redigera den manuellt med hjälp av pennikonen.
- Dataformaterar dataformatet för data i indatamappen Lake-databaser i Azure Synapse stöder parkett och avgränsad text som lagringsformat för data. Om dataformatet inte matchar data i mappen misslyckas frågor till tabellen.
För ett dataformat med avgränsad text finns det ytterligare inställningar:
- Radrubriker markerar den här rutan om data har radrubriker.
- Aktivera flera rader i data markerar du den här kryssrutan om data har flera rader i en strängkolumn.
- Citattecken anger det anpassade citattecknet för en avgränsad textfil.
- Escape-tecken anger det anpassade escape-tecknet för en avgränsad textfil.
- Komprimering av data den komprimeringstyp som används för data.
- Avgränsa fältgränsaren som används i datafilerna. Värden som stöds är: Kommatecken (,), tabb (\t) och pipe (|).
- Partitionskolumner listan över partitionskolumner visas här.
- Lägg till kryssrutan om du kör frågor mot Dataverse-data från SQL Serverless.
För Parquet-data finns det följande inställning:
- Komprimering av data den komprimeringstyp som används för data.
Kolumner
Fliken Kolumner är den plats där kolumnerna för tabellen visas och kan ändras. På den här fliken finns två listor med kolumner: Standardkolumner och Partitionskolumner. Standardkolumner är alla kolumner som lagrar data, är en primärnyckel och används annars inte för partitionering av data. Partitionskolumner lagrar även data, men används för att partitionera underliggande data i mappar baserat på värdena i kolumnen. Varje kolumn har följande egenskaper.
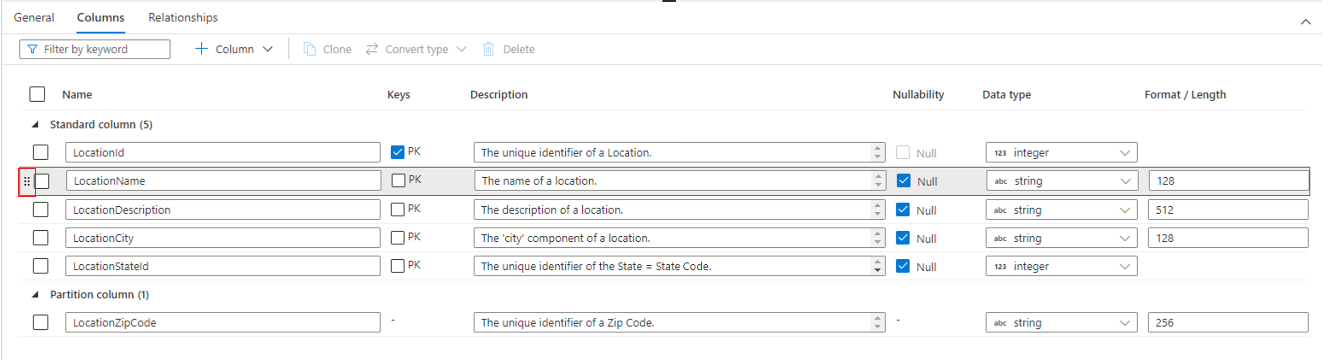
- Namnge namnet på kolumnen. Måste vara unikt i tabellen.
- Nycklar anger om kolumnen är en primärnyckel (PK) och/eller sekundärnyckel (FK) för tabellen. Gäller inte för partitionskolumner.
- Beskrivning av kolumnen. Om kolumnen har skapats från en databasmall visas beskrivningen av begreppet som representeras av den här kolumnen. Det här fältet kan redigeras och kan ändras så att det matchar den beskrivning som matchar dina affärskrav.
- Nullability anger om det kan finnas null-värden i den här kolumnen. Gäller inte för partitionskolumner.
- Datatypen anger datatypen för kolumnen baserat på den tillgängliga listan över Spark-datatyper.
- Format/längd gör det möjligt att anpassa formatet eller den maximala längden för kolumnen, beroende på datatypen. Datatyperna Datum och tidsstämpel har formatlistrutor och andra typer som sträng har ett fält med maximal längd. Alla datatyper har inte ett värde eftersom vissa typer har fast längd. Överst på fliken Kolumner finns ett kommandofält som kan användas för att interagera med kolumnerna.
- Filtrera efter nyckelord filtrerar listan med kolumner till objekt som matchar det angivna nyckelordet.
- Med + Kolumn kan du lägga till en ny kolumn. Det finns tre möjliga alternativ.
- Ny kolumn skapar en ny anpassad standardkolumn.
- Från mallen öppnas utforskningsfönstret och du kan identifiera kolumner från en databasmall som ska ingå i tabellen. Om databasen inte har skapats med en databasmall visas inte det här alternativet.
- Partitionskolumnen lägger till en ny anpassad partitionskolumn.
- Klonen duplicerar den markerade kolumnen. Klonade kolumner är alltid av samma typ som den valda kolumnen.
- Konvertera typ används för att ändra den valda standardkolumnen till en partitionskolumn och tvärtom. Det här alternativet är nedtonat om du har valt flera kolumner av olika typer eller om den valda kolumnen inte kan konverteras på grund av en PK - eller nullability-flagga som angetts i kolumnen.
- Ta bort tar bort de markerade kolumnerna från tabellen. Den här åtgärden går inte att ångra.
Du kan också ordna om ordningen på kolumnerna genom att dra och släppa med de dubbla lodräta ellipserna som visas till vänster om kolumnnamnet när du hovra över eller klickar på kolumnen enligt bilden ovan.
Partitionskolumner
Partitionskolumner används för att partitionera fysiska data i databasen baserat på värden i dessa kolumner. Med partitionskolumner kan du enkelt distribuera data på disk till mer högpresterande segment. Partitionskolumner i Azure Synapse finns alltid i slutet av tabellschemat. Dessutom används de uppifrån och ned när du skapar partitionsmapparna. Om dina partitionskolumner till exempel är Year och Month får du en struktur i ADLS så här:
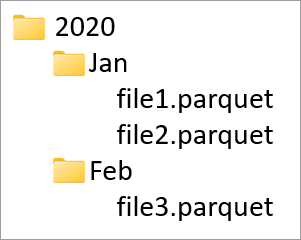
Där file1 och file2 innehöll alla rader där värdena för År respektive Månad var 2020 respektive Jan. När fler partitionskolumner läggs till i en tabell läggs fler filer till i den här hierarkin, vilket gör den övergripande filstorleken för partitionerna mindre.
Azure Synapse tillämpar eller skapar inte den här hierarkin genom att lägga till partitionskolumner i en tabell. Data måste läsas in i tabellen med synapse-pipelines eller en Spark-notebook-fil för att partitionsstrukturen ska kunna skapas.
Relationer
På fliken Relationer kan du ange relationer mellan tabeller i databasen. Relationer i databasdesignern är informationsbaserade och framtvingar inga begränsningar för underliggande data. De läss av andra Microsoft-program kan användas för att påskynda omvandlingar eller ge företagsanvändare insikt i hur tabeller är anslutna. Fönstret Relationer har följande information.
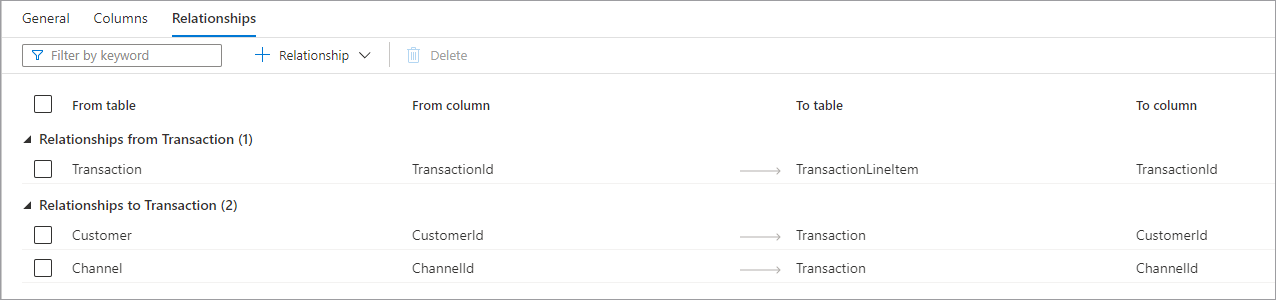
- Relationer från (tabell) är när en eller flera tabeller har sekundärnycklar anslutna till den här tabellen. Detta kallas ibland för en överordnad relation.
- Relationer till (tabell) är när en tabell som har sekundärnyckel och är ansluten till en annan tabell. Detta kallas ibland för en underordnad relation.
- Båda relationstyperna har följande egenskaper.
- Från tabellen den överordnade tabellen i relationen, eller "en"-sidan.
- Från kolumnen i den överordnade tabellen baseras relationen på.
- För att lägga till den underordnade tabellen i relationen, eller "många"-sidan.
- Om du vill kolumnkolumnen i den underordnade tabellen baseras relationen på. Överst på fliken Relationer finns kommandofältet som kan användas för att interagera med relationerna
- Filtrera efter nyckelord filtrerar listan med kolumner till objekt som matchar det angivna nyckelordet.
- + Relation låter dig lägga till en ny relation. Det finns två alternativ.
- Från tabellen skapas en ny relation från den tabell som du arbetar med till en annan tabell.
- I tabellen skapas en ny relation från en annan tabell än den du arbetar med.
- Från mallen öppnas utforskningsfönstret och du kan välja mellan relationer i databasmallen som ska ingå i databasen. Om databasen inte har skapats med en databasmall visas inte det här alternativet.
Nästa steg
Fortsätt att utforska funktionerna i databasdesignern med hjälp av länkarna nedan.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för