Snabbstart: Analysera med Data Explorer (förhandsversion)
I den här artikeln får du lära dig de grundläggande stegen för att läsa in och analysera data med Data Explorer för Azure Synapse.
Skapa en Data Explorer pool
I Synapse Studio går du till fönstret till vänster och väljer Hantera>Data Explorer pooler.
Välj Nytt och ange sedan följande information på fliken Grundläggande inställningar:
Inställning Föreslaget värde Beskrivning Data Explorer poolnamn contosodataexplorer Det här är det namn som Data Explorer poolen kommer att ha. Arbetsbelastning Beräkningsoptimerad Den här arbetsbelastningen ger ett högre förhållande mellan PROCESSOR och SSD-lagring. Nodstorlek Små (4 kärnor) Ange den minsta storleken för att minska kostnaderna för den här snabbstarten Viktigt
Observera att det finns specifika begränsningar för de namn som Data Explorer pooler kan använda. Namn får endast innehålla gemener och siffror, måste vara mellan 4 och 15 tecken och måste börja med en bokstav.
Välj Granska + skapa>Skapa. Din Data Explorer-pool startar etableringsprocessen.
Skapa en Data Explorer databas
I Synapse Studio väljer du Data i fönstret till vänster.
Välj + (Lägg till ny resurs) >Data Explorer databas och klistra in följande information:
Inställning Föreslaget värde Beskrivning Poolnamn contosodataexplorer Namnet på den Data Explorer pool som ska användas Name TestDatabase Databasnamnet måste vara unikt inom klustret. Standardkvarhållningsperiod 365 Det tidsintervall (i dagar) då det är garanterat att data förblir tillgängliga för frågor. Tidsintervallet mäts från det att data matas in. Standardcacheperiod 31 Det tidsintervall (i dagar) då data som frågor körs mot ofta ska vara tillgängliga i SSD-lagring eller RAM i stället för i långsiktig lagring. Välj Skapa för att skapa databasen. Det brukar ta mindre än en minut att skapa en databas.
Mata in exempeldata och analysera med en enkel fråga
I Synapse Studio väljer du Utveckla i fönstret till vänster.
Under KQL-skript väljer du + (Lägg till ny resurs) >KQL-skript. I den högra rutan kan du namnge skriptet.
På menyn Anslut till väljer du contosodataexplorer.
På menyn Använd databas väljer du TestDatabase.
Klistra in följande kommando och välj Kör för att skapa en StormEvents-tabell.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tips
Kontrollera att tabellen har skapats. I den vänstra rutan väljer du Data, väljer menyn contosodataexplorer more och väljer sedan Uppdatera. Under contosodataexplorer expanderar du Tabeller och kontrollerar att tabellen StormEvents visas i listan.
Klistra in följande kommando och välj Kör för att mata in data i StormEvents-tabellen.
.ingest into table StormEvents 'https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv' with (ignoreFirstRecord=true)När inmatningen är klar klistrar du in följande fråga, väljer frågan i fönstret och väljer Kör.
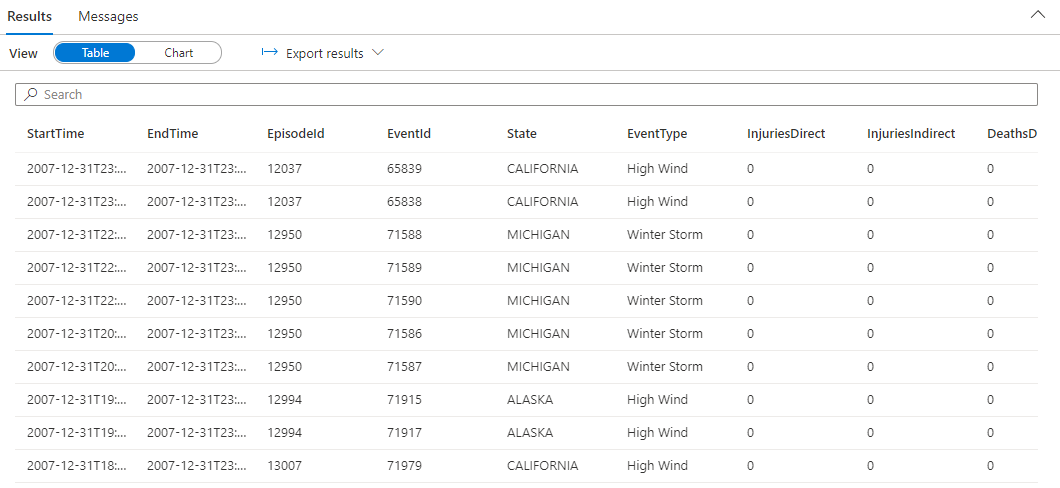
StormEvents | sort by StartTime desc | take 10Frågan returnerar följande resultat från inmatade exempeldata.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för