Säkerhetsdokument för Azure Synapse Analytics: Introduktion
Sammanfattning: Azure Synapse Analytics är en Microsoft-plattform för obegränsad analys som integrerar lagring av företagsdata och bearbetning av stordata i en enda hanterad miljö utan att systemintegrering krävs. Azure Synapse tillhandahåller verktyg från slutpunkt till slutpunkt för din analyslivscykel med:
- Pipelines för dataintegrering.
- Apache Spark-pool för bearbetning av stordata.
- Datautforskaren för logg- och tidsserieanalys.
- Serverlös SQL-pool för datautforskning över Azure Data Lake.
- Dedikerad SQL-pool (tidigare SQL DW) för lagring av företagsdata.
- Djupgående integrering med Power BI, Azure Cosmos DB och Azure Mašinsko učenje.
Azure Synapse-datasäkerhet och sekretess är inte förhandlingsbara. Syftet med den här vitboken är att ge en omfattande översikt över Säkerhetsfunktioner i Azure Synapse, som är företagsklassade och branschledande. Vitboken består av en serie artiklar som täcker följande fem säkerhetslager:
- Dataskydd
- Åtkomstkontroll
- Autentisering
- Nätverkssäkerhet
- Hotskydd
Det här vitboken riktar sig till alla intressenter inom företagssäkerhet. De omfattar säkerhetsadministratörer, nätverksadministrationer, Azure-administratörer, arbetsyteadministratörer och databasadministratörer.
Författare: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Krishnappa, Mykola Kovalenko, Brad Schacht, Pedro Martinez, Mark Pryce-Maher och Arshad Ali.
Tekniska granskare: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Crawford och Tammy Richter Jones.
Gäller för: Azure Synapse Analytics, dedikerad SQL-pool (tidigare SQL DW), serverlös SQL-pool och Apache Spark-pool.
Viktigt!
Det här vitboken gäller inte för Azure SQL Database, Azure SQL Managed Instance, Azure Mašinsko učenje eller Azure Databricks.
Introduktion
Vanliga rubriker om dataintrång, infektioner av skadlig kod och skadlig kodinmatning finns bland en omfattande lista över säkerhetsproblem för företag som vill modernisera med molnet. Företagskunden kräver en molnleverantör eller tjänstlösning som kan lösa deras problem eftersom de inte har råd att göra fel.
Några vanliga säkerhetsfrågor är:
- Hur kan jag styra vem som kan se vilka data?
- Vilka är alternativen för att verifiera en användares identitet?
- Hur skyddas mina data?
- Vilken nätverkssäkerhetsteknik kan jag använda för att skydda integritet, konfidentialitet och åtkomst för mina nätverk och data?
- Vilka verktyg identifierar och meddelar mig om hot?
Syftet med denna vitbok är att ge svar på dessa vanliga säkerhetsfrågor, och många andra.
Komponentarkitektur
Azure Synapse är en PaaS-analystjänst (Plattform som en tjänst) som samlar flera oberoende komponenter som dedikerade SQL-pooler, serverlösa SQL-pooler, Apache Spark-pooler och dataintegreringspipelines. Dessa komponenter är utformade för att fungera tillsammans för att ge en sömlös analysplattformsupplevelse.
Dedikerade SQL-pooler är etablerade kluster som tillhandahåller informationslagerfunktioner för företag för SQL-arbetsbelastningar. Data matas in i hanterad lagring som drivs av Azure Storage, som också är en PaaS-tjänst. Beräkning isoleras från lagring så att kunderna kan skala beräkning oberoende av sina data. Dedikerade SQL-pooler ger också möjlighet att köra frågor mot datafiler direkt över kundhanterade Azure Storage-konton med hjälp av externa tabeller.
Serverlösa SQL-pooler är kluster på begäran som tillhandahåller ett SQL-gränssnitt för att köra frågor mot och analysera data direkt över kundhanterade Azure Storage-konton. Eftersom de är serverlösa finns det ingen hanterad lagring och beräkningsnoderna skalas automatiskt som svar på frågearbetsbelastningen.
Apache Spark i Azure Synapse är en av Microsofts implementeringar av Apache Spark med öppen källkod i molnet. Spark-instanser etableras på begäran baserat på de metadatakonfigurationer som definieras i Spark-poolerna. Varje användare får en egen dedikerad Spark-instans för att köra sina jobb. De datafiler som bearbetas av Spark-instanserna hanteras av kunden i deras egna Azure Storage-konton.
Pipelines är en logisk gruppering av aktiviteter som utför dataförflyttning och datatransformering i stor skala. Dataflöde är en transformeringsaktivitet i en pipeline som utvecklas med hjälp av ett användargränssnitt med låg kod. Den kan köra datatransformeringar i stor skala. I bakgrunden använder dataflöden Apache Spark-kluster i Azure Synapse för att köra automatiskt genererad kod. Pipelines och dataflöden är endast beräkningstjänster och de har inte någon hanterad lagring som är associerad med dem.
Pipelines använder Integration Runtime (IR) som skalbar beräkningsinfrastruktur för att utföra dataflytt och sändningsaktiviteter. Dataförflyttningsaktiviteter körs på IR medan sändningsaktiviteterna körs på flera andra beräkningsmotorer, inklusive Azure SQL Database, Azure HDInsight, Azure Databricks, Apache Spark-kluster i Azure Synapse och andra. Azure Synapse stöder två typer av IR: Azure Integration Runtime och Lokalt installerad integrationskörning. Azure IR tillhandahåller en fullständigt hanterad, skalbar och på begäran-beräkningsinfrastruktur. Lokalt installerad IR installeras och konfigureras av kunden i sitt eget nätverk, antingen på lokala datorer eller i virtuella Azure-molndatorer.
Kunder kan välja att associera sin Synapse-arbetsyta med ett virtuellt nätverk för hanterade arbetsytor. När de är associerade med ett virtuellt nätverk för hanterade arbetsytor distribueras Azure IR och Apache Spark-kluster som används av pipelines, dataflöden och Apache Spark-pooler i det virtuella nätverket för den hanterade arbetsytan. Den här konfigurationen säkerställer nätverksisolering mellan arbetsytorna för pipelines och Apache Spark-arbetsbelastningar.
Följande diagram visar de olika komponenterna i Azure Synapse.
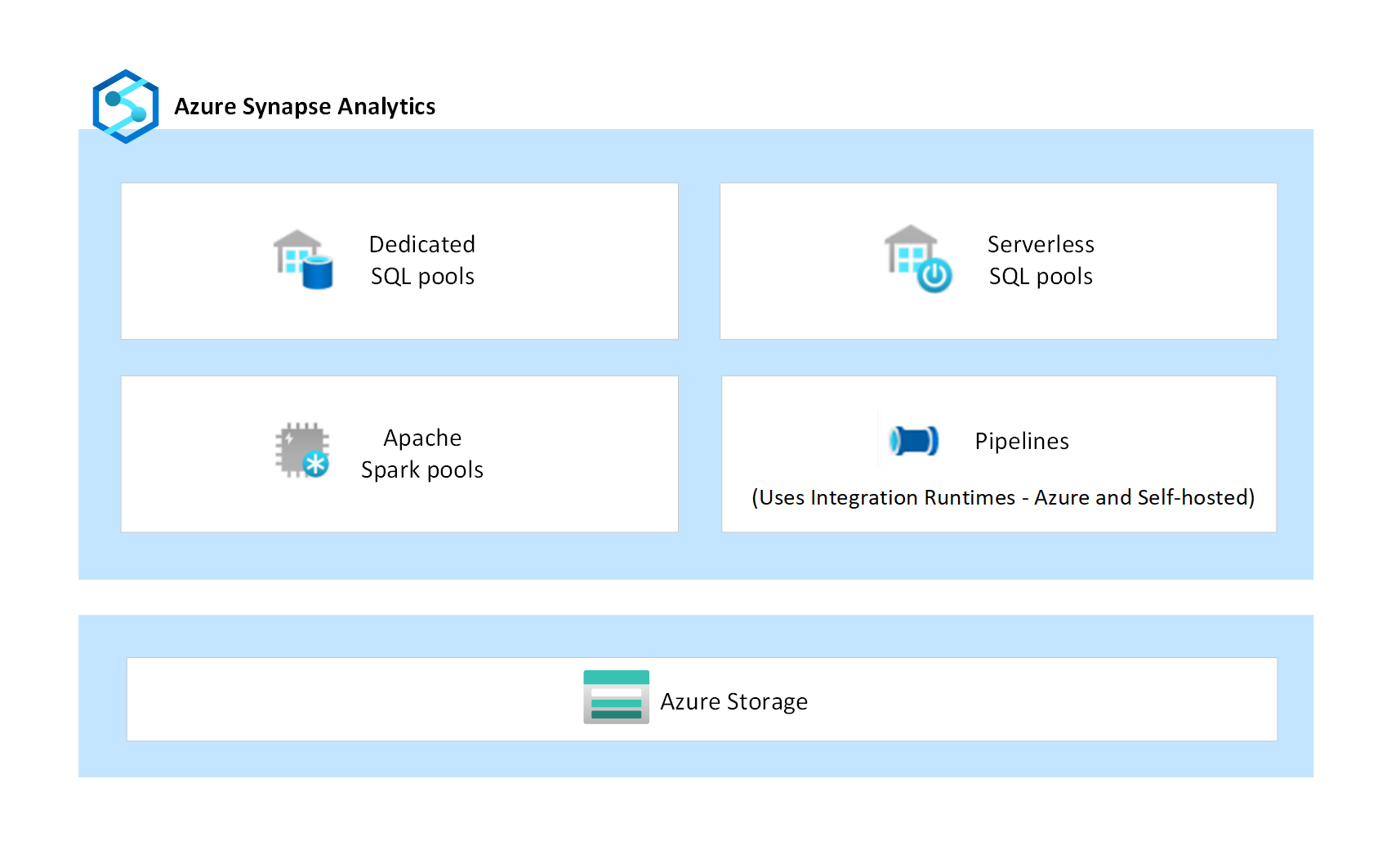
Komponentisolering
Varje enskild komponent i Azure Synapse som visas i diagrammet innehåller sina egna säkerhetsfunktioner. Säkerhetsfunktioner ger dataskydd, åtkomstkontroll, autentisering, nätverkssäkerhet och skydd mot hot för att skydda beräkningen och tillhörande data som bearbetas. Dessutom ger Azure Storage, som är en PaaS-tjänst, ytterligare säkerhet som konfigureras och hanteras av kunden i deras egna lagringskonton. Den här nivån av komponentisolering begränsar och minimerar exponeringen om det finns en säkerhetsrisk i någon av dess komponenter.
Säkerhetsnivåer
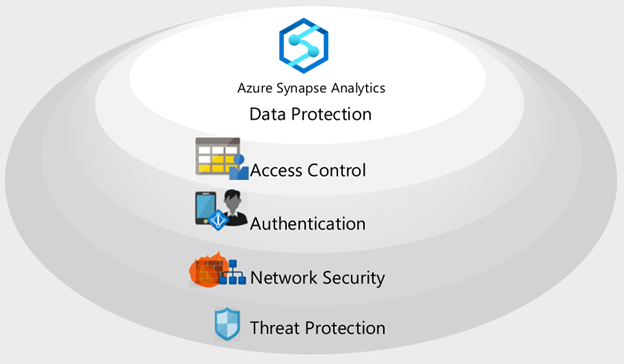
Azure Synapse implementerar en säkerhetsarkitektur med flera lager för att skydda dina data från slutpunkt till slutpunkt. Det finns fem lager:
- Dataskydd för att identifiera och klassificera känsliga data och kryptera data i vila och i rörelse.
- Åtkomstkontroll för att fastställa en användares rätt att interagera med data.
- Autentisering för att bevisa identiteten för användare och program.
- Nätverkssäkerhet för att isolera nätverkstrafik med privata slutpunkter och virtuella privata nätverk.
- Skydd mot hot för att identifiera potentiella säkerhetshot, till exempel ovanliga åtkomstplatser, SQL-inmatningsattacker, autentiseringsattacker med mera.
Nästa steg
I nästa artikel i den här white paper-serien får du lära dig mer om dataskydd.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för