Självstudie: Träna en maskininlärningsmodell utan kod (inaktuell)
Du kan utöka dina data i Spark-tabeller med nya maskininlärningsmodeller som du tränar med hjälp av automatiserad maskininlärning. I Azure Synapse Analytics kan du välja en Spark-tabell på arbetsytan som ska användas som en träningsdatauppsättning för att skapa maskininlärningsmodeller, och du kan göra det i en kodfri upplevelse.
I den här självstudien lär du dig hur du tränar maskininlärningsmodeller med hjälp av en kodfri upplevelse i Synapse Studio. Synapse Studio är en funktion i Azure Synapse Analytics.
Du använder automatiserad maskininlärning i Azure Machine Learning i stället för att koda upplevelsen manuellt. Vilken typ av modell du tränar beror på vilket problem du försöker lösa. I den här självstudien använder du en regressionsmodell för att förutsäga taxipriser från datamängden för Taxi i New York City.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Varning
- Från och med den 29 september 2023 upphör Azure Synapse med det officiella stödet för Spark 2.4 Runtimes. Efter den 29 september 2023 kommer vi inte att ta upp några supportärenden relaterade till Spark 2.4. Det finns ingen versionspipeline för buggar eller säkerhetskorrigeringar för Spark 2.4. Användning av Spark 2.4 efter supportavstängningen sker på egen risk. Vi avråder starkt från fortsatt användning på grund av potentiella säkerhets- och funktionsproblem.
- Som en del av utfasningsprocessen för Apache Spark 2.4 vill vi meddela dig att AutoML i Azure Synapse Analytics också kommer att bli inaktuellt. Detta omfattar både gränssnittet med låg kod och de API:er som används för att skapa AutoML-utvärderingsversioner via kod.
- Observera att AutoML-funktionen var exklusivt tillgänglig via Spark 2.4-körningen.
- För kunder som vill fortsätta använda AutoML-funktioner rekommenderar vi att du sparar dina data i ditt Azure Data Lake Storage Gen2-konto (ADLSg2). Därifrån kan du sömlöst komma åt AutoML-upplevelsen via Azure Machine Learning (AzureML). Mer information om den här lösningen finns här.
Förutsättningar
- En Azure Synapse Analytics-arbetsyta. Kontrollera att det har ett Azure Data Lake Storage Gen2-lagringskonto konfigurerat som standardlagring. För Data Lake Storage Gen2-filsystemet som du arbetar med kontrollerar du att du är Storage Blob Data-deltagare.
- En Apache Spark-pool (version 2.4) på din Azure Synapse Analytics-arbetsyta. Mer information finns i Snabbstart: Skapa en serverlös Apache Spark-pool med Synapse Studio.
- En länkad Azure Machine Learning-tjänst på din Azure Synapse Analytics-arbetsyta. Mer information finns i Snabbstart: Skapa en ny länkad Azure Machine Learning-tjänst i Azure Synapse Analytics.
Logga in på Azure-portalen
Logga in på Azure-portalen.
Skapa en Spark-tabell för träningsdatauppsättningen
I den här självstudien behöver du en Spark-tabell. Följande notebook-fil skapar en:
Ladda ned notebook-filen Create-Spark-Table-NYCTaxi- Data.ipynb.
Importera anteckningsboken till Synapse Studio.
Välj den Spark-pool som du vill använda och välj sedan Kör alla. Det här steget hämtar New York-taxidata från den öppna datamängden och sparar data till din standard-Spark-databas.

När notebook-körningen har slutförts visas en ny Spark-tabell under Standard-Spark-databasen. Leta reda på tabellen med namnet nyc_taxi från Data.
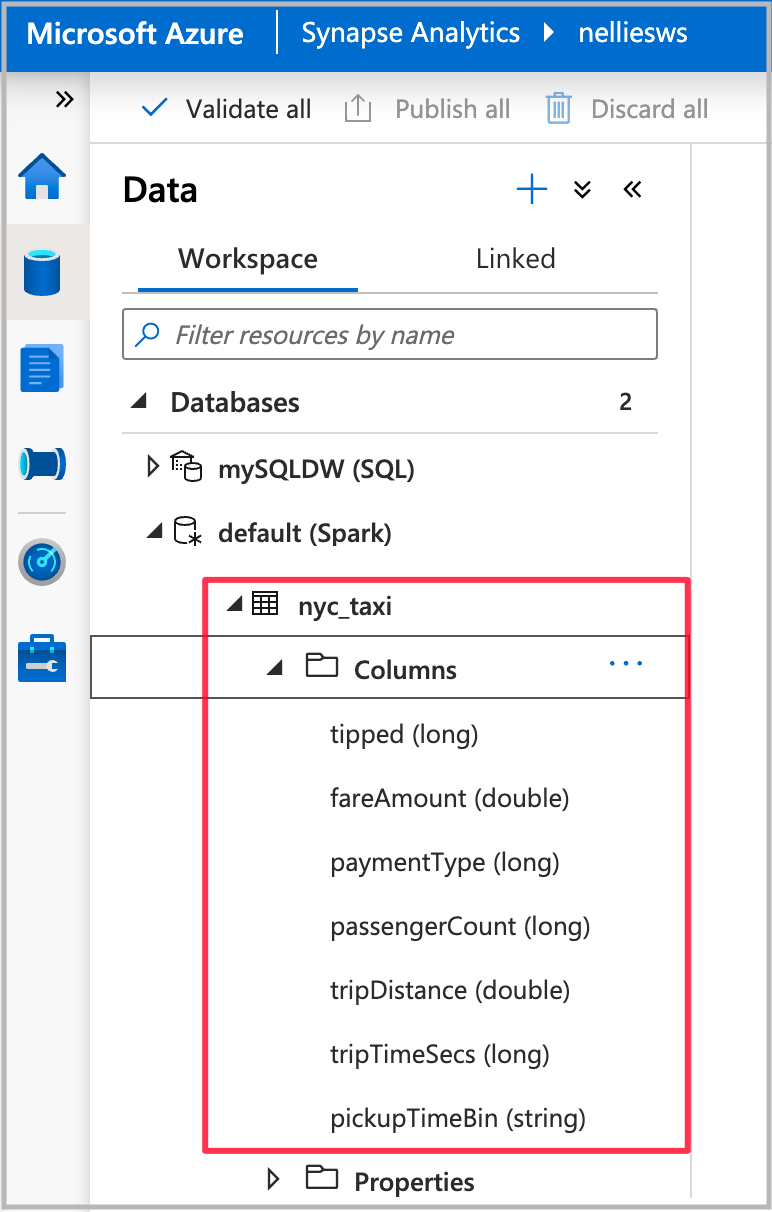
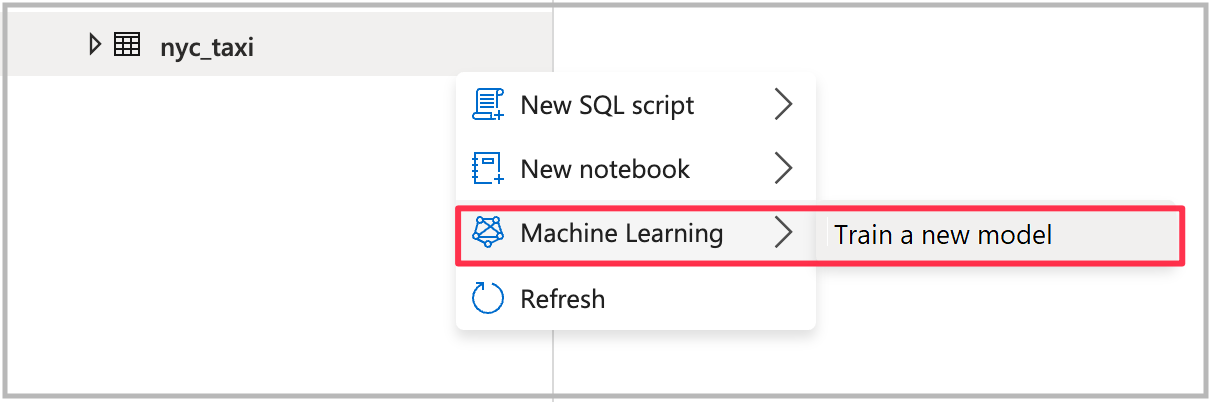
Öppna guiden automatiserad maskininlärning
Öppna guiden genom att högerklicka på den Spark-tabell som du skapade i föregående steg. Välj sedan Machine Learning>Träna en ny modell.
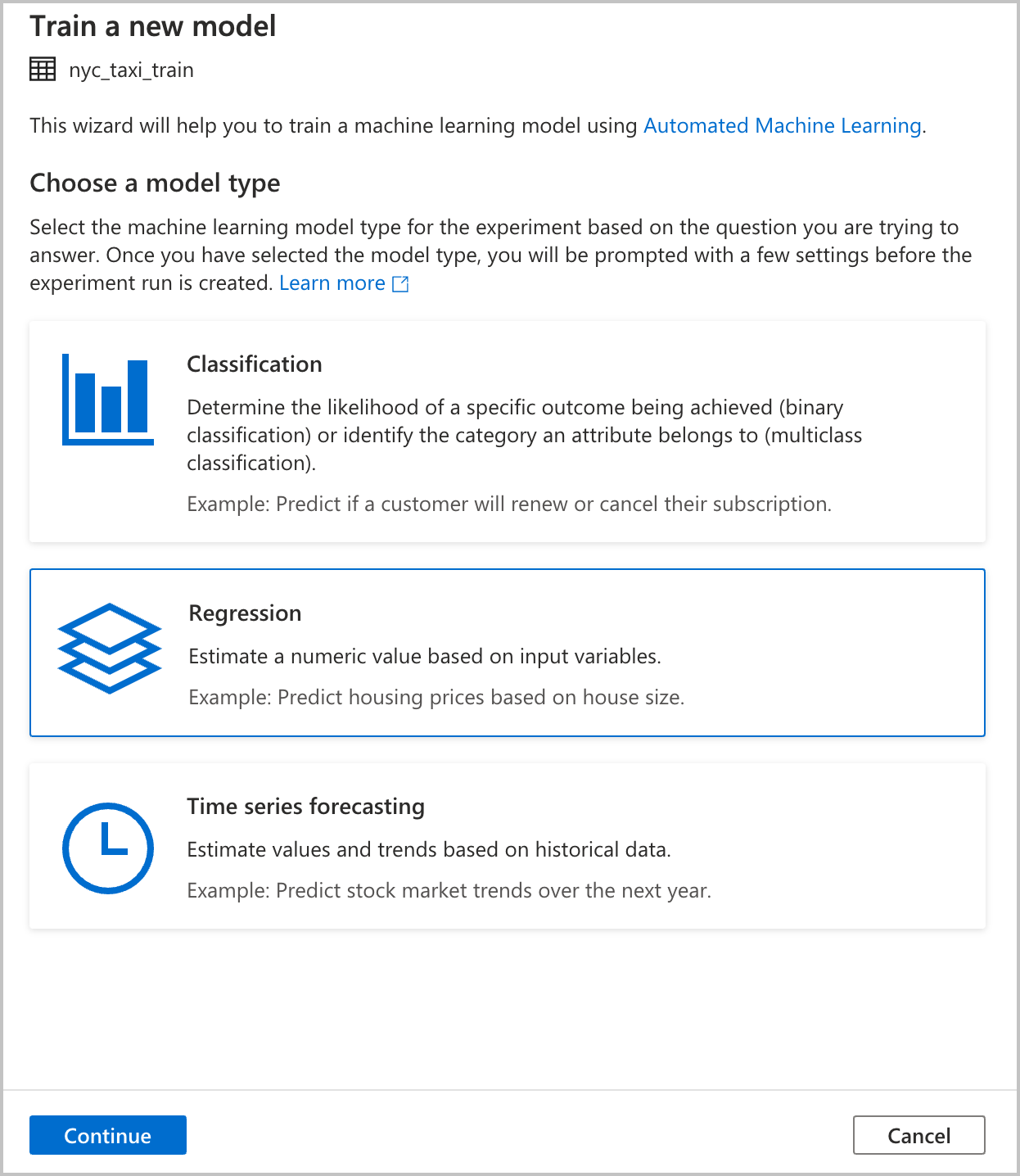
Välj en modelltyp
Välj typ av maskininlärningsmodell för experimentet baserat på den fråga som du försöker besvara. Eftersom värdet du försöker förutsäga är numeriskt (taxipriser) väljer du Regression här. Välj sedan Fortsätt.
Konfigurera experimentet
Ange konfigurationsinformation för att skapa ett automatiserat maskininlärningsexperiment som körs i Azure Machine Learning. Den här körningen tränar flera modeller. Den bästa modellen från en lyckad körning registreras i Azure Machine Learning-modellregistret.
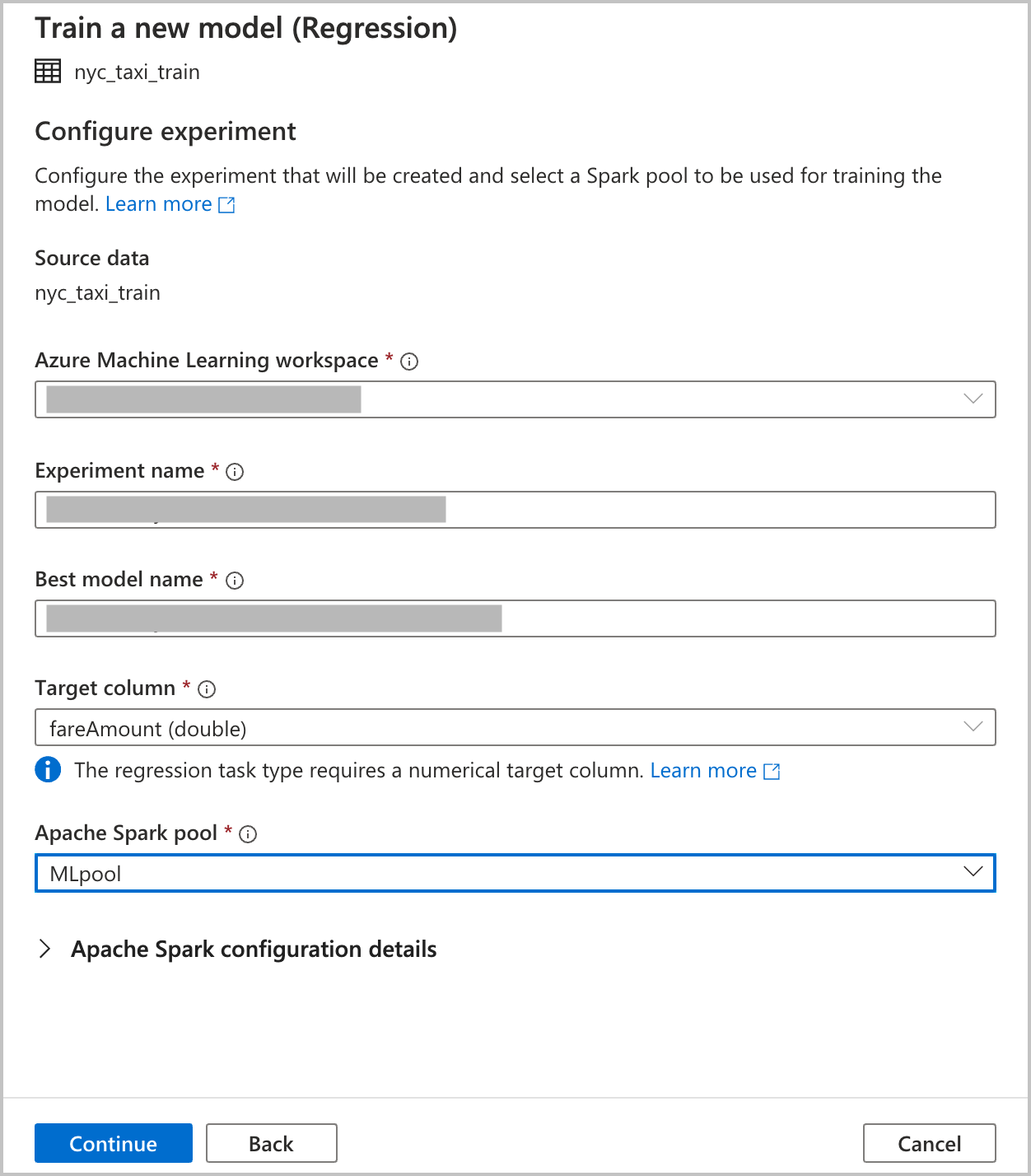
Azure Machine Learning-arbetsyta: En Azure Machine Learning-arbetsyta krävs för att skapa en automatiserad maskininlärningsexperimentkörning. Du måste också länka din Azure Synapse Analytics-arbetsyta till Azure Machine Learning-arbetsytan med hjälp av en länkad tjänst. När du har uppfyllt alla förutsättningar kan du ange den Azure Machine Learning-arbetsyta som du vill använda för den här automatiserade körningen.
Experimentnamn: Ange experimentnamnet. När du skickar en automatiserad maskininlärningskörning anger du ett experimentnamn. Information om körningen lagras under experimentet på Azure Machine Learning-arbetsytan. Den här upplevelsen skapar ett nytt experiment som standard och genererar ett föreslaget namn, men du kan också ange namnet på ett befintligt experiment.
Bästa modellnamn: Ange namnet på den bästa modellen från den automatiserade körningen. Den bästa modellen får det här namnet och sparas automatiskt i Azure Machine Learning-modellregistret efter den här körningen. En automatiserad maskininlärningskörning skapar många maskininlärningsmodeller. Baserat på det primära mått som du väljer i ett senare steg kan dessa modeller jämföras och den bästa modellen kan väljas.
Målkolumn: Det här är vad modellen tränas att förutsäga. Välj kolumnen i datamängden som innehåller de data som du vill förutsäga. I den här självstudien väljer du den numeriska kolumnen
fareAmountsom målkolumn.Spark-pool: Ange den Spark-pool som du vill använda för den automatiserade experimentkörningen. Beräkningarna körs i den pool som du anger.
Spark-konfigurationsinformation: Förutom Spark-poolen har du möjlighet att ange sessionskonfigurationsinformation.
Välj Fortsätt.
Konfigurera modellen
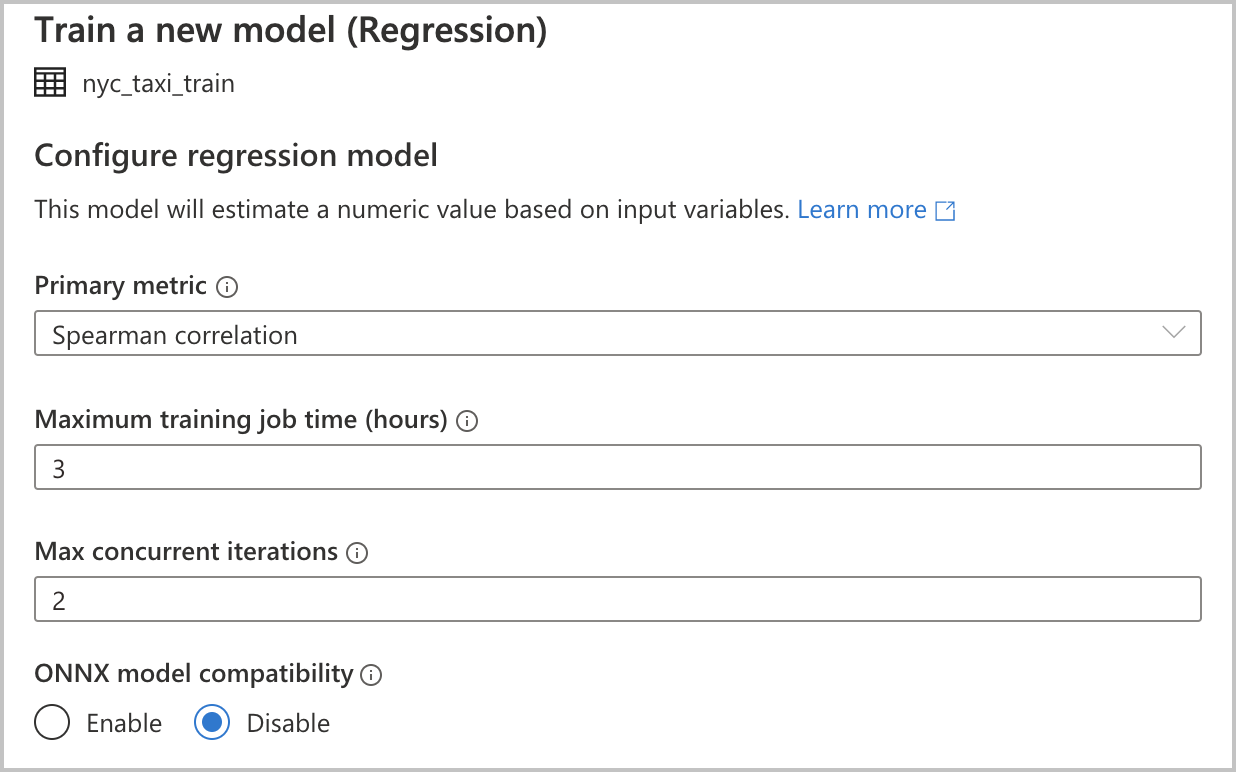
Eftersom du valde Regression som modelltyp i föregående avsnitt är följande konfigurationer tillgängliga (dessa är också tillgängliga för typ av klassificeringsmodell ):
Primärt mått: Ange måttet som mäter hur bra modellen mår. Du använder det här måttet för att jämföra olika modeller som skapats i den automatiserade körningen och avgöra vilken modell som presterat bäst.
Träningstid (timmar): Ange den maximala tiden, i timmar, för ett experiment som ska köras och träna modeller. Observera att du också kan ange värden som är mindre än 1 (till exempel 0,5).
Maximalt antal samtidiga iterationer: Välj det maximala antalet iterationer som körs parallellt.
ONNX-modellkompatibilitet: Om du aktiverar det här alternativet konverteras de modeller som tränas av automatiserad maskininlärning till ONNX-formatet. Detta är särskilt relevant om du vill använda modellen för bedömning i Azure Synapse Analytics SQL-pooler.
De här inställningarna har alla ett standardvärde som du kan anpassa.
Starta en körning
När alla nödvändiga konfigurationer är klara kan du starta den automatiserade körningen. Du kan välja att skapa en körning direkt genom att välja Skapa körning – detta startar körningen utan kod. Om du föredrar kod kan du också välja Öppna i anteckningsbok – då öppnas en notebook-fil som innehåller koden som skapar körningen så att du kan visa koden och starta körningen själv.

Kommentar
Om du valde Prognostisering av tidsserier som modelltyp i föregående avsnitt måste du göra ytterligare konfigurationer. Prognostisering stöder inte heller ONNX-modellkompatibilitet.
Skapa en körning direkt
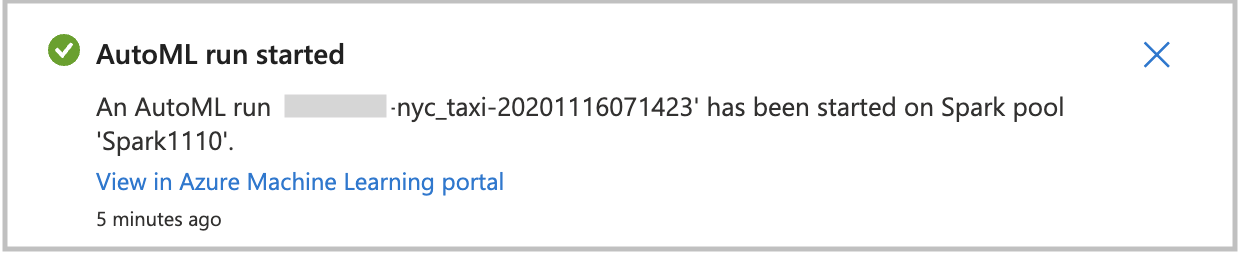
Om du vill starta den automatiserade maskininlärningskörningen direkt väljer du Skapa körning. Du ser ett meddelande som anger att körningen startar. Sedan visas ett annat meddelande som anger att det har lyckats. Du kan också kontrollera statusen i Azure Machine Learning genom att välja länken i meddelandet.
Skapa en körning med en notebook-fil
Om du vill generera en notebook-fil väljer du Öppna i notebook-fil. Detta ger dig möjlighet att lägga till inställningar eller på annat sätt ändra koden för din automatiserade maskininlärningskörning. När du är redo att köra koden väljer du Kör alla.

Övervaka körningen
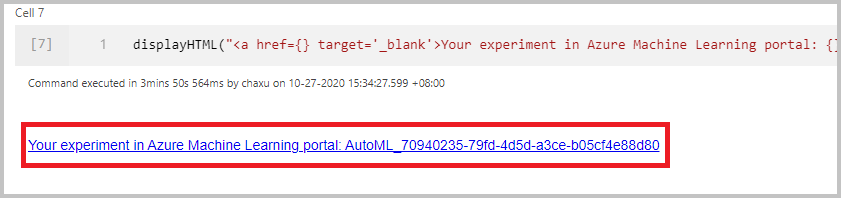
När du har skickat körningen visas en länk till experimentkörningen på Azure Machine Learning-arbetsytan i notebook-utdata. Välj länken för att övervaka din automatiserade körning i Azure Machine Learning.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för