Självstudie: Dokumentinformation med Azure AI-tjänster
Azure AI Document Intelligence är en Azure AI-tjänst som gör att du kan skapa automatiserade databehandlingsprogram med hjälp av maskininlärningsteknik. I den här självstudien lär du dig att enkelt utöka dina data i Azure Synapse Analytics. Du använder Dokumentinformation för att analysera formulär och dokument, extraherar text och data och returnerar strukturerade JSON-utdata. Du får snabbt korrekta resultat som är skräddarsydda för ditt specifika innehåll utan överdriven manuell inblandning eller omfattande datavetenskaplig expertis.
Den här självstudien visar hur du använder Dokumentinformation med SynapseML för att:
- Extrahera text och layout från ett visst dokument
- Identifiera och extrahera data från kvitton
- Identifiera och extrahera data från visitkort
- Identifiera och extrahera data från fakturor
- Identifiera och extrahera data från identifieringsdokument
Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Azure Synapse Analytics-arbetsyta med ett Azure Data Lake Storage Gen2 lagringskonto konfigurerat som standardlagring. Du måste vara Storage Blob Data-deltagare för det Data Lake Storage Gen2 filsystem som du arbetar med.
- Spark-pool på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en Spark-pool i Azure Synapse.
- Förkonfigurationssteg som beskrivs i självstudien Konfigurera Azure AI-tjänster i Azure Synapse.
Kom igång
Öppna Synapse Studio och skapa en ny notebook-fil. Kom igång genom att importera SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Konfigurera dokumentinformation
Använd den länkade dokumentinformation som du konfigurerade i förkonfigurationsstegen .
ai_service_name = "<Your linked service for Document Intelligence>"
Analysera layout
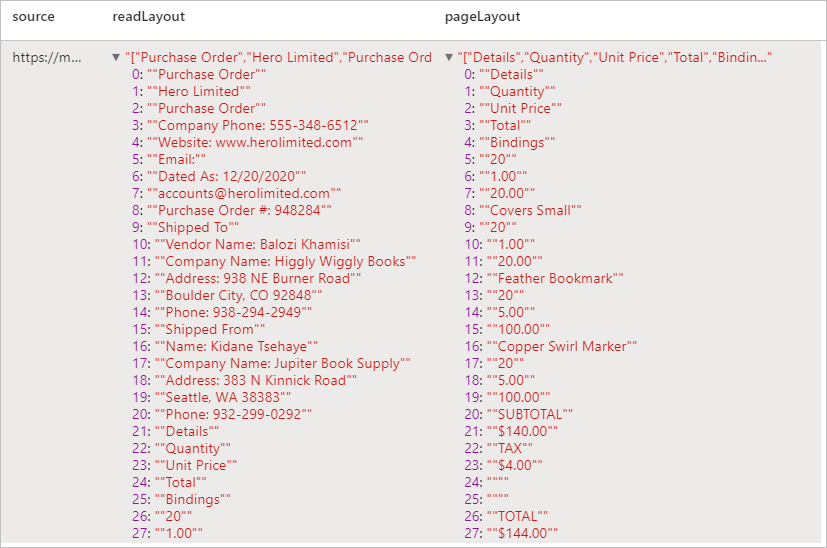
Extrahera text- och layoutinformation från ett visst dokument. Indatadokumentet måste vara av någon av de innehållstyper som stöds – "application/pdf", "image/jpeg", "image/png" eller "image/tiff".
Exempel på indata

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Förväntat resultat
Analysera kvitton
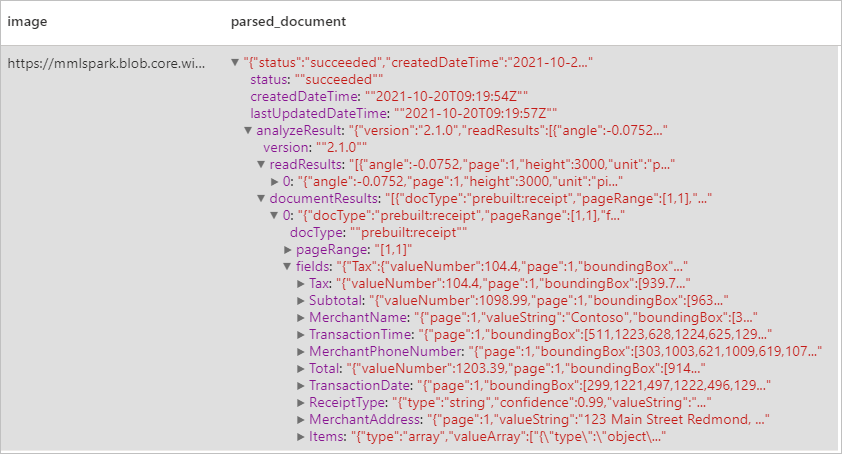
Identifierar och extraherar data från kvitton med hjälp av optisk teckenläsning (OCR) och vår kvittomodell, så att du enkelt kan extrahera strukturerade data från kvitton, till exempel försäljningsnamn, handelstelefonnummer, transaktionsdatum, transaktionssumma med mera.
Exempel på indata

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Förväntat resultat
Analysera visitkort
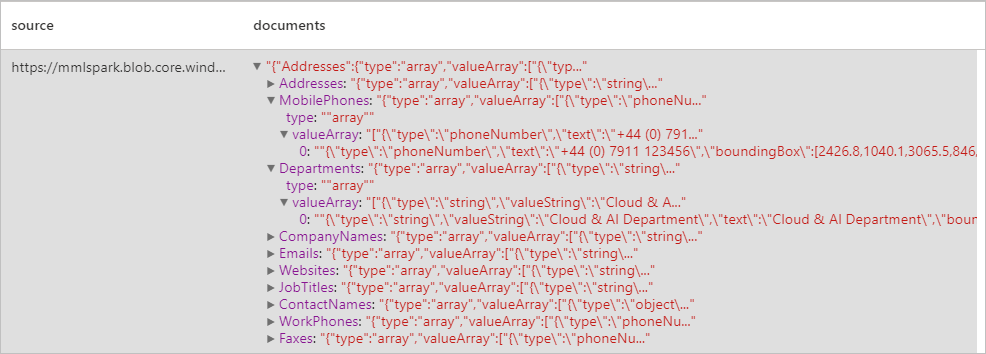
Identifierar och extraherar data från visitkort med hjälp av optisk teckenläsning (OCR) och vår visitkortsmodell, så att du enkelt kan extrahera strukturerade data från visitkort som kontaktnamn, företagsnamn, telefonnummer, e-postmeddelanden med mera.
Exempel på indata

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Förväntat resultat
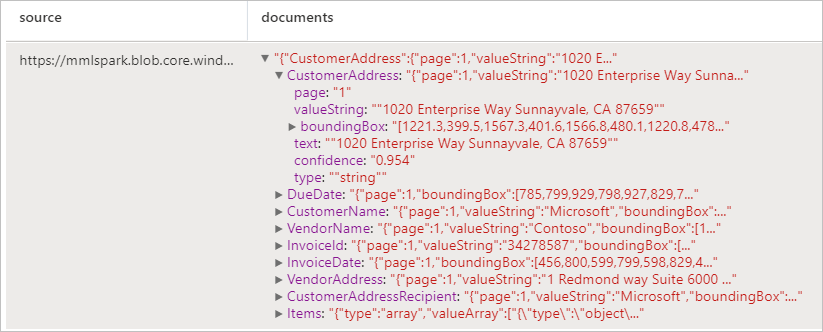
Analysera fakturor
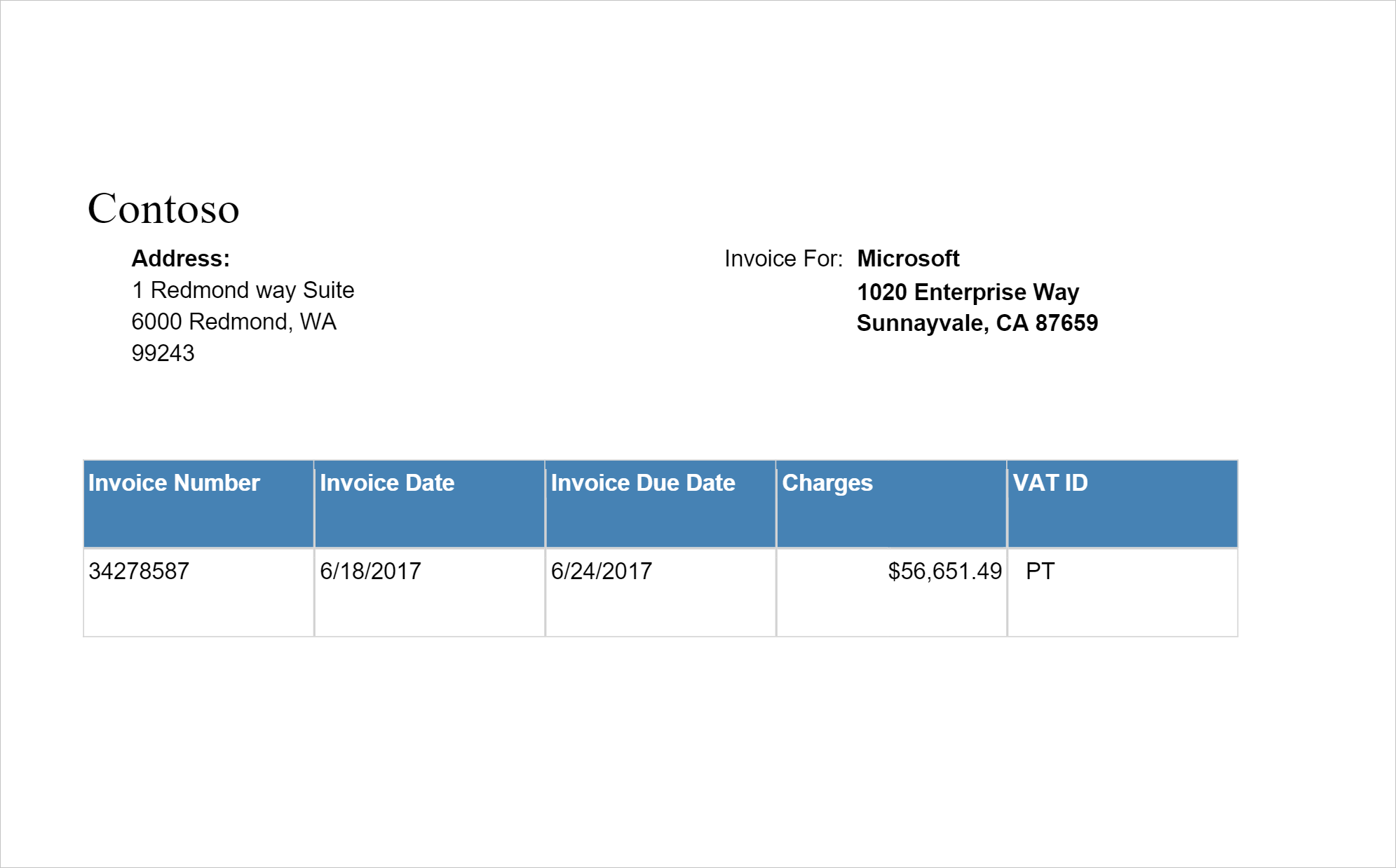
Identifierar och extraherar data från fakturor med hjälp av optisk teckenläsning (OCR) och vår djupinlärningsmodeller för faktura, så att du enkelt kan extrahera strukturerade data från fakturor som kund, leverantör, faktura-ID, fakturaförfallodatum, totalsumma, fakturabelopp, skattebelopp, transport till, faktura till, radobjekt med mera.
Exempel på indata
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Förväntat resultat
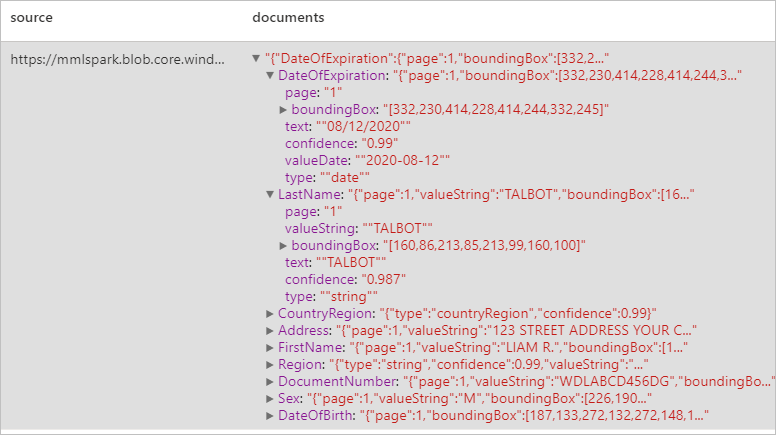
Analysera ID-dokument
Identifierar och extraherar data från identifieringsdokument med hjälp av optisk teckenläsning (OCR) och vår ID-dokumentmodell, så att du enkelt kan extrahera strukturerade data från ID-dokument som förnamn, efternamn, födelsedatum, dokumentnummer med mera.
Exempel på indata

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Förväntat resultat
Rensa resurser
För att säkerställa att Spark-instansen stängs av avslutar du alla anslutna sessioner (notebook-filer). Poolen stängs av när den inaktivitetstid som anges i Apache Spark-poolen nås. Du kan också välja stoppa session från statusfältet längst upp till höger i anteckningsboken.

Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för