Minimera SQL-problem för Oracle-migreringar
Den här artikeln är del fem i en serie i sju delar som ger vägledning om hur du migrerar från Oracle till Azure Synapse Analytics. Fokus i den här artikeln är metodtips för att minimera SQL-problem.
Översikt
Egenskaper för Oracle-miljöer
Oracles första databasprodukt, som släpptes 1979, var en kommersiell SQL-relationsdatabas för onlinetransaktionsbearbetningsprogram (OLTP), med mycket lägre transaktionshastigheter än i dag. Sedan den första versionen har Oracle-miljön utvecklats till att bli mycket mer komplex och omfattar många funktioner. Funktionerna omfattar klient-server-arkitekturer, distribuerade databaser, parallell bearbetning, dataanalys, hög tillgänglighet, informationslager, tekniker för minnesintern data och stöd för molnbaserade instanser.
Dricks
Oracle banade väg för konceptet "informationslagerinstallation" i början av 2000-talet.
På grund av kostnaden och komplexiteten med att underhålla och uppgradera äldre lokala Oracle-miljöer vill många befintliga Oracle-användare dra nytta av de innovationer som tillhandahålls av molnmiljöer. Med moderna molnmiljöer, till exempel molnet, IaaS och PaaS, kan du delegera uppgifter som infrastrukturunderhåll och plattformsutveckling till molnleverantören.
Många informationslager som stöder komplexa analytiska SQL-frågor på stora datavolymer använder Oracle-tekniker. Dessa informationslager har ofta en dimensionsdatamodell, till exempel star- eller snowflake-scheman, och använder data marts för enskilda avdelningar.
Dricks
Många befintliga Oracle-installationer är informationslager som använder en dimensionsdatamodell.
Kombinationen av SQL- och dimensionsdatamodeller i Oracle förenklar migreringen till Azure Synapse eftersom begreppen SQL och grundläggande datamodeller kan överföras. Microsoft rekommenderar att du flyttar din befintliga datamodell i befintligt fall till Azure för att minska risken, ansträngningen och migreringstiden. Även om din migreringsplan kan innehålla en ändring i den underliggande datamodellen, till exempel en flytt från en Inmon-modell till ett datavalv, är det klokt att först utföra en migrering i befintligt fall. Efter den första migreringen kan du sedan göra ändringar i Azure-molnmiljön för att dra nytta av dess prestanda, elastisk skalbarhet, inbyggda funktioner och kostnadsfördelar.
Även om SQL-språket är standardiserat implementerar enskilda leverantörer ibland egna tillägg. Därför kan du hitta SQL-skillnader under migreringen som kräver lösningar i Azure Synapse.
Använda Azure-anläggningar för att implementera en metadatadriven migrering
Du kan automatisera och samordna migreringsprocessen med hjälp av funktionerna i Azure-miljön. Den här metoden minimerar prestandaträffen för den befintliga Oracle-miljön, som kanske redan körs nära kapaciteten.
Azure Data Factory är en molnbaserad dataintegreringstjänst som har stöd för att skapa datadrivna arbetsflöden i molnet för att samordna och automatisera dataflytt och datatransformering. Du kan använda Data Factory för att skapa och schemalägga datadrivna arbetsflöden (pipelines) som matar in data från olika datalager. Data Factory kan bearbeta och transformera data med hjälp av beräkningstjänster som Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics och Azure Mašinsko učenje.
Azure innehåller även Azure Database Migration Services som hjälper dig att planera och utföra en migrering från miljöer som Oracle. SQL Server Migration Assistant (SSMA) för Oracle kan automatisera migreringen av Oracle-databaser, inklusive i vissa fall funktioner och procedurkod.
Dricks
Automatisera migreringsprocessen med hjälp av Azure Data Factory-funktioner.
När du planerar att använda Azure-anläggningar, till exempel Data Factory, för att hantera migreringsprocessen skapar du först metadata som visar alla datatabeller som behöver migreras och deras plats.
SQL DDL-skillnader mellan Oracle och Azure Synapse
ANSI SQL-standarden definierar den grundläggande syntaxen för DDL-kommandon (Data Definition Language). Vissa DDL-kommandon, som CREATE TABLE och CREATE VIEW, är gemensamma för både Oracle och Azure Synapse, men har utökats för att tillhandahålla implementeringsspecifika funktioner som indexering, tabelldistribution och partitioneringsalternativ.
Dricks
SQL DDL-kommandon CREATE TABLE och CREATE VIEW har standardelement men används också för att definiera implementeringsspecifika alternativ.
I följande avsnitt beskrivs de Oracle-specifika alternativ som måste beaktas under en migrering till Azure Synapse.
Tabell-/vyöverväganden
När du migrerar tabeller mellan olika miljöer är det vanligtvis bara rådata och metadata som beskriver dem fysiskt migrera. Andra databaselement från källsystemet, till exempel index och loggfiler, migreras vanligtvis inte eftersom de kan vara onödiga eller implementerade på olika sätt i den nya miljön. Alternativet i Oracles CREATE TABLE syntax motsvarar till exempel TEMPORARY prefixet ett tabellnamn med # tecknet i Azure Synapse.
Prestandaoptimeringar i källmiljön, till exempel index, anger var du kan lägga till prestandaoptimering i den nya målmiljön. Om bitmappade index till exempel används ofta i frågor i Oracle-källmiljön, föreslår det att ett icke-grupperat index ska skapas i Azure Synapse. Andra inbyggda tekniker för prestandaoptimering, till exempel tabellreplikering, kan vara mer tillämpliga än att skapa raka liknande index. SSMA för Oracle kan ge migreringsrekommendationer för tabelldistribution och indexering.
Dricks
Befintliga index anger kandidater för indexering i det migrerade lagret.
SQL-vydefinitioner innehåller SQL Data Manipulation Language-instruktioner (DML) som definierar vyn, vanligtvis med en eller flera SELECT instruktioner. När du migrerar CREATE VIEW instruktioner bör du ta hänsyn till DML-skillnaderna mellan Oracle och Azure Synapse.
Oracle-databasobjekttyper som inte stöds
Oracle-specifika funktioner kan ofta ersättas av Azure Synapse-funktioner. Vissa Oracle-databasobjekt stöds dock inte direkt i Azure Synapse. I följande lista över Oracle-databasobjekt som inte stöds beskrivs hur du kan uppnå motsvarande funktioner i Azure Synapse:
Indexeringsalternativ: I Oracle har flera indexeringsalternativ, till exempel bitmappade index, funktionsbaserade index och domänindex, ingen direkt motsvarighet i Azure Synapse. Även om Azure Synapse inte stöder dessa indextyper kan du uppnå en liknande minskning av disk-I/O genom att använda användardefinierade indextyper och/eller partitionering Minska disk-I/O förbättrar frågeprestanda.
Du kan ta reda på vilka kolumner som indexeras och deras indextyp genom att fråga systemkatalogtabeller och vyer, till exempel
ALL_INDEXES,DBA_INDEXES,USER_INDEXESochDBA_IND_COL. Eller så kan du fråga vyernadba_index_usageellerv$object_usagenär övervakning är aktiverat.Azure Synapse-funktioner, till exempel parallell frågebearbetning och minnesintern cachelagring av data och resultat, gör det troligt att färre index krävs för att datalagerprogram ska uppnå utmärkta prestandamål.
Grupperade tabeller: Oracle-tabeller kan ordnas så att tabellrader som används ofta tillsammans (baserat på ett gemensamt värde) lagras fysiskt tillsammans. Den här strategin minskar disk-I/O när data hämtas. Oracle har också ett hash-klusteralternativ för enskilda tabeller, som tillämpar ett hash-värde på klusternyckeln och fysiskt lagrar rader med samma hash-värde tillsammans.
I Azure Synapse kan du uppnå ett liknande resultat genom att partitionera och/eller använda andra index.
Materialiserade vyer: Oracle stöder materialiserade vyer och rekommenderar en eller flera av dem för stora tabeller med många kolumner där endast ett fåtal kolumner används regelbundet i frågor. Materialiserade vyer uppdateras automatiskt av systemet när data i bastabellen uppdateras.
Under 2019 meddelade Microsoft att Azure Synapse kommer att stödja materialiserade vyer med samma funktioner som i Oracle. Materialiserade vyer är nu en förhandsversionsfunktion i Azure Synapse.
Utlösare i databasen: i Oracle kan en utlösare konfigureras så att den körs automatiskt när en utlösande händelse inträffar. Utlösande händelser kan vara:
En DML-instruktion, till exempel
INSERT,UPDATEellerDELETE, körs. Om du har definierat en utlösare som utlöses före enINSERTinstruktion i en kundtabell utlöses utlösaren en gång innan en ny rad infogas i kundtabellen.En DDL-instruktion, till exempel
CREATEellerALTER, körs. Den här utlösande händelsen används ofta för att registrera schemaändringar i granskningssyfte.En systemhändelse som start eller avstängning av Oracle-databasen.
En användarhändelse som inloggning eller utloggning.
Azure Synapse stöder inte Oracle-databasutlösare. Du kan dock uppnå motsvarande funktioner med hjälp av Data Factory, men om du gör det måste du omstrukturera de processer som använder utlösare.
Synonymer: Oracle har stöd för att definiera synonymer som alternativa namn för flera databasobjekttyper. Dessa typer omfattar tabeller, vyer, sekvenser, procedurer, lagrade funktioner, paket, materialiserade vyer, Java-klassschemaobjekt, användardefinierade objekt eller andra synonymer.
Azure Synapse stöder för närvarande inte definition av synonymer, men om en synonym i Oracle refererar till en tabell eller vy kan du definiera en vy i Azure Synapse som matchar det alternativa namnet. Om en synonym i Oracle refererar till en funktion eller lagrad procedur kan du ersätta synonymen i Azure Synapse med en annan funktion eller lagrad procedur som anropar målet.
Användardefinierade typer: Oracle stöder användardefinierade objekt som kan innehålla en serie enskilda fält, var och en med sina egna definitions- och standardvärden. Dessa objekt kan sedan refereras i en tabelldefinition på samma sätt som inbyggda datatyper som
NUMBERellerVARCHAR.Azure Synapse stöder för närvarande inte användardefinierade typer. Om de data som du behöver migrera innehåller användardefinierade datatyper kan du antingen "platta ut" dem till en konventionell tabelldefinition, eller om de är matriser med data, normalisera dem i en separat tabell.
SQL DDL-generering
Du kan redigera befintliga Oracle CREATE TABLE och CREATE VIEW skript för att uppnå motsvarande definitioner i Azure Synapse. För att göra det kan du behöva använda ändrade datatyper och ta bort eller ändra Oracle-specifika satser, till exempel TABLESPACE.
Dricks
Använd befintliga Oracle-metadata för att automatisera genereringen av CREATE TABLE och CREATE VIEW DDL för Azure Synapse.
I Oracle-miljön anger systemkatalogtabeller den aktuella tabell-/vydefinitionen. Till skillnad från användarunderhållen dokumentation är systemkataloginformationen alltid fullständig och synkroniserad med aktuella tabelldefinitioner. Du kan komma åt systemkataloginformation med hjälp av verktyg som Oracle SQL Developer. Oracle SQL Developer kan generera CREATE TABLE DDL-instruktioner som du kan redigera för att tillämpa på motsvarande tabeller i Azure Synapse, som du ser i nästa skärmbild.

Oracle SQL Developer matar ut följande CREATE TABLE instruktion, som innehåller Oracle-specifika satser som du bör ta bort. Mappa datatyper som inte stöds innan du kör den ändrade CREATE TABLE instruktionen i Azure Synapse.
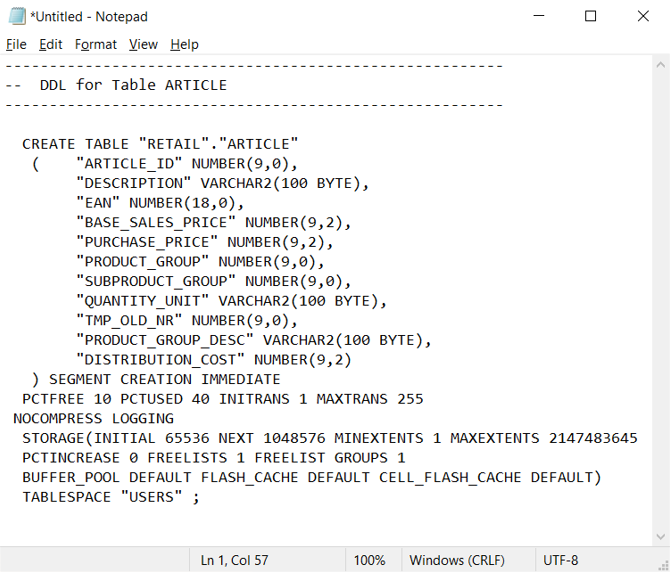
Du kan också automatiskt generera CREATE TABLE instruktioner från informationen i Oracle-katalogtabeller med hjälp av SQL-frågor, SSMA eller migreringsverktyg från tredje part . Den här metoden är det snabbaste och mest konsekventa sättet att generera CREATE TABLE instruktioner för många tabeller.
Dricks
Verktyg och tjänster från tredje part kan automatisera datamappningsuppgifter.
Tredjepartsleverantörer erbjuder verktyg och tjänster för att automatisera migreringen, inklusive mappning av datatyper. Om ett ETL-verktyg från tredje part redan används i Oracle-miljön använder du verktyget för att implementera nödvändiga datatransformeringar.
SQL DML-skillnader mellan Oracle och Azure Synapse
ANSI SQL-standarden definierar den grundläggande syntaxen för DML-kommandon, till exempel SELECT, INSERT, UPDATEoch DELETE. Oracle och Azure Synapse har båda stöd för DDL-kommandon, men i vissa fall implementerar de samma kommando på olika sätt.
Dricks
Sql DML-standardkommandona SELECT, INSERToch UPDATE kan ha ytterligare syntaxalternativ i olika databasmiljöer.
I följande avsnitt beskrivs de Oracle-specifika DML-kommandon som måste beaktas under en migrering till Azure Synapse.
Skillnader i SQL DML-syntax
Det finns några skillnader i SQL DML-syntax mellan Oracle SQL och Azure Synapse T-SQL:
DUALtabell: Oracle har en systemtabell med namnetDUALsom består av exakt en kolumn med namnetdummyoch en post med värdetX. SystemtabellenDUALanvänds när en fråga kräver ett tabellnamn av syntaxskäl, men tabellinnehållet behövs inte.Ett exempel på
DUALen Oracle-fråga som använder tabellen ärSELECT sysdate from dual;. Motsvarigheten till Azure Synapse ärSELECT GETDATE();. För att förenkla migreringen av DML kan du skapa en motsvarandeDUALtabell i Azure Synapse med hjälp av följande DDL.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GONULLvärden: ettNULLvärde i Oracle är en tom sträng som representeras av enCHARsträngtypVARCHARav längd0. I Azure Synapse och de flesta andra databaserNULLbetyder något annat. Var försiktig när du migrerar data, eller när du migrerar processer som hanterar eller lagrar data, för att säkerställa attNULLvärdena hanteras konsekvent.Oracles yttre kopplingssyntax: Även om nyare versioner av Oracle stöder ANSI-syntax för yttre koppling använder äldre Oracle-system en egen syntax för yttre kopplingar som använder ett plustecken (
+) i SQL-instruktionen. Om du migrerar en äldre Oracle-miljö kan du stöta på den äldre syntaxen. Till exempel:SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;Motsvarande ANSI-standardsyntax är:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;DATEdata: i OracleDATEkan datatypen lagra både datum och tid. Azure Synapse lagrar datum och tid i separataDATE,TIMEochDATETIMEdatatyper. När du migrerar Oracle-kolumnerDATEkontrollerar du om de lagrar både datum och tid eller bara ett datum. Om de bara lagrar ett datum mappar du kolumnen tillDATE, annars tillDATETIME.DATEaritmetik: Oracle har stöd för att subtrahera ett datum från ett annat, till exempelSELECT date '2018-12-31' - date '2018-1201' from dual;. I Azure Synapse kan du subtrahera datum med hjälpDATEDIFF()av funktionen, till exempelSELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle kan subtrahera heltal från datum, till exempel
SELECT hire_date, (hire_date-1) FROM employees;. I Azure Synapse kan du lägga till eller subtrahera heltal från datum med hjälpDATEADD()av funktionen .Uppdateringar via vyer: i Oracle kan du köra åtgärder för att infoga, uppdatera och ta bort mot en vy för att uppdatera den underliggande tabellen. I Azure Synapse kör du dessa åtgärder mot en bastabell – inte en vy. Du kan behöva återskapa ETL-bearbetning om en Oracle-tabell uppdateras via en vy.
Inbyggda funktioner: I följande tabell visas skillnaderna i syntax och användning av vissa inbyggda funktioner.
| Oracle-funktion | beskrivning | Motsvarande Synapse |
|---|---|---|
| ADD_MONTHS | Lägg till ett angivet antal månader | DATEADD |
| CAST | Konvertera en inbyggd datatyp till en annan | CAST |
| AVKODA | Utvärdera en lista över villkor | CASE-uttryck |
| EMPTY_BLOB | Skapa ett tomt BLOB-värde | 0x konstant (tom binär sträng) |
| EMPTY_CLOB | Skapa ett tomt CLOB- eller NCLOB-värde | '' (tom sträng) |
| INITCAP | Versalisera den första bokstaven i varje ord | Användardefinierad funktion |
| INSTR | Hitta positionen för en delsträng i en sträng | CHARINDEX |
| LAST_DAY | Hämta det sista datumet i månaden | EOMONTH |
| LENGTH | Hämta stränglängd i tecken | LEN |
| LPAD | Vänster-pad sträng till den angivna längden | Uttryck med replikering, HÖGER och VÄNSTER |
| MOD | Hämta resten av en division av ett tal efter ett annat | % operatör |
| MONTHS_BETWEEN | Hämta antalet månader mellan två datum | DATEDIFF |
| NVL | Ersätt NULL med uttryck |
ISNULL |
| SUBSTR | Returnera en delsträng från en sträng | SUBSTRING |
| TO_CHAR för datetime | Konvertera datetime till sträng | KONVERTERA |
| TO_DATE | Konvertera en sträng till datetime | KONVERTERA |
| ÖVERSÄTTA | En-till-en-ersättning med ett tecken | Uttryck som använder REPLACE eller en användardefinierad funktion |
| TRIM | Trimma inledande eller avslutande tecken | LTRIM och RTRIM |
| TRUNC för datetime | Trunkera datetime | Uttryck som använder KONVERTERA |
| UNISTR | Konvertera Unicode-kodpunkter till tecken | Uttryck med NCHAR |
Funktioner, lagrade procedurer och sekvenser
När du migrerar ett informationslager från en mogen miljö som Oracle måste du förmodligen migrera andra element än enkla tabeller och vyer. För funktioner, lagrade procedurer och sekvenser kontrollerar du om verktyg i Azure-miljön kan ersätta deras funktioner eftersom det vanligtvis är mer effektivt att använda inbyggda Azure-verktyg än att koda om Oracle-funktionerna.
Som en del av förberedelsefasen skapar du en inventering av objekt som behöver migreras, definierar en metod för att hantera dem och allokerar lämpliga resurser i migreringsplanen.
Microsoft-verktyg som SSMA för Oracle och Azure Database Migration Services, eller produkter och tjänster från tredje part för migrering, kan automatisera migreringen av funktioner, lagrade procedurer och sekvenser.
Dricks
Produkter och tjänster från tredje part kan automatisera migreringen av icke-dataelement.
I följande avsnitt beskrivs migrering av funktioner, lagrade procedurer och sekvenser.
Functions
Precis som med de flesta databasprodukter har Oracle stöd för system- och användardefinierade funktioner i en SQL-implementering. När du migrerar en äldre databasplattform till Azure Synapse kan du vanligtvis migrera vanliga systemfunktioner utan ändringar. Vissa systemfunktioner kan ha en något annorlunda syntax, men du kan automatisera alla nödvändiga ändringar.
För Oracle-systemfunktioner eller godtyckliga användardefinierade funktioner som inte har någon motsvarighet i Azure Synapse ska du koda om dessa funktioner med målmiljöspråket. Användardefinierade Oracle-funktioner kodas i PL/SQL, Java eller C. Azure Synapse använder transact-SQL-språket för att implementera användardefinierade funktioner.
Lagrade procedurer
De flesta moderna databasprodukter stöder lagring av procedurer i databasen. Oracle tillhandahåller PL/SQL-språket för detta ändamål. En lagrad procedur innehåller vanligtvis både SQL-instruktioner och procedurlogik och returnerar data eller status.
Azure Synapse stöder lagrade procedurer med T-SQL, så du måste koda om alla migrerade lagrade procedurer i T-SQL.
Sekvenser
I Oracle är en sekvens ett namngivet databasobjekt som skapats med hjälp av CREATE SEQUENCE. En sekvens ger unika numeriska värden via CURRVAL metoderna och NEXTVAL . Du kan använda de genererade unika talen som surrogatnyckelvärden för primära nycklar. Azure Synapse implementerar CREATE SEQUENCEinte , men du kan implementera sekvenser med hjälp av IDENTITY kolumner eller SQL-kod som genererar nästa sekvensnummer i en serie.
Använda EXPLAIN för att verifiera äldre SQL
Dricks
Använd verkliga frågor från befintliga systemfrågeloggar för att hitta potentiella migreringsproblem.
Om vi antar en liknande migrerad datamodell i Azure Synapse med samma tabell- och kolumnnamn är ett sätt att testa äldre Oracle SQL för kompatibilitet med Azure Synapse:
- Samla in några representativa SQL-instruktioner från de äldre systemfrågehistorikloggarna.
- Prefix dessa frågor med -instruktionen
EXPLAIN. EXPLAINKör instruktionerna i Azure Synapse.
Alla inkompatibla SQL genererar ett fel och felinformationen kan användas för att fastställa omoderingsaktivitetens skala. Den här metoden kräver inte att du läser in data i Azure-miljön. Du behöver bara skapa relevanta tabeller och vyer.
Sammanfattning
Befintliga äldre Oracle-installationer implementeras vanligtvis på ett sätt som gör migreringen till Azure Synapse relativt enkel. Båda miljöerna använder SQL för analysfrågor på stora datavolymer och använder vanligtvis någon form av dimensionsdatamodell. Dessa faktorer gör Oracle-installationer till en bra kandidat för migrering till Azure Synapse.
För att sammanfatta är våra rekommendationer för att minimera uppgiften att migrera SQL-kod från Oracle till Azure Synapse:
Migrera din befintliga datamodell i befintligt fall för att minimera risken, ansträngningen och migreringstiden, även om en annan datamodell planeras, till exempel ett datavalv.
Förstå skillnaderna mellan Oracle SQL-implementeringen och Azure Synapse-implementeringen.
Använd metadata- och frågeloggarna från den befintliga Oracle-implementeringen för att utvärdera effekten av att ändra miljön. Planera en metod för att minska skillnaderna.
Automatisera migreringsprocessen för att minimera risken, ansträngningen och migreringstiden. Du kan använda Microsoft-verktyg som Azure Database Migration Services och SSMA.
Överväg att använda specialiserade verktyg och tjänster från tredje part för att effektivisera migreringen.
Nästa steg
Mer information om Microsoft- och tredjepartsverktyg finns i nästa artikel i den här serien: Verktyg för Oracle-informationslagermigrering till Azure Synapse Analytics.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för